Recognition: unknown
Unified 4D World Action Modeling from Video Priors with Asynchronous Denoising
Pith reviewed 2026-05-08 03:14 UTC · model grok-4.3
The pith
X-WAM unifies robotic action execution and high-fidelity 4D world synthesis from video priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
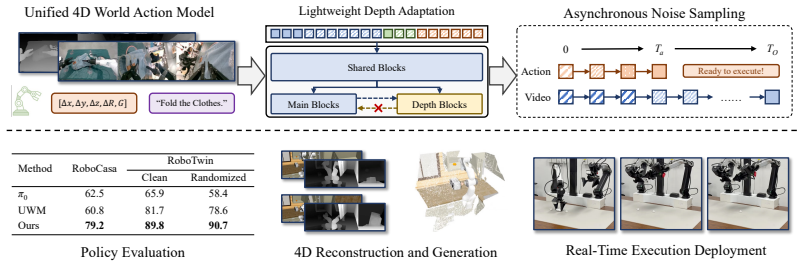
X-WAM is a unified 4D world model that imagines future scenes by predicting multi-view RGB-D videos from a pretrained Diffusion Transformer, replicates its final blocks into a dedicated depth branch for efficient spatial reconstruction, and applies Asynchronous Noise Sampling that trains on the joint timestep distribution so that inference can decode actions rapidly while still producing full-fidelity video and 3D output.
What carries the argument
Asynchronous Noise Sampling (ANS) paired with a replicated depth branch in the Diffusion Transformer: ANS aligns training and inference distributions so actions decode in few steps while video uses the complete sequence, and the depth branch extracts 3D information without retraining the full model.
If this is right
- Robots can execute actions based on predicted future 3D geometry rather than 2D pixels alone.
- A single pretrained video model can support both real-time control and detailed world synthesis without separate pipelines.
- High-fidelity 4D outputs improve geometric accuracy over prior 2D unified world models on the same benchmarks.
- Action success reaches 79.2 percent on RoboCasa and 90.7 percent on RoboTwin 2.0 after pretraining on thousands of hours of robot data.
Where Pith is reading between the lines
- The approach implies that many existing video diffusion models can be cheaply extended to 3D reconstruction tasks by copying only a few blocks.
- ANS may generalize to other diffusion applications where speed and quality must be traded off during inference.
- Consistent 4D predictions could tighten the loop between perception, prediction, and control in long-horizon robot tasks.
Load-bearing premise
The lightweight replication of final diffusion blocks into a depth branch plus the asynchronous schedule can deliver both fast action decoding and high-fidelity 4D output without major quality loss or extra validation.
What would settle it
A controlled ablation in which synchronous full-step denoising for actions or removal of the depth branch produces lower success rates on RoboCasa and RoboTwin while video quality remains comparable or better.
Figures



read the original abstract
We propose X-WAM, a Unified 4D World Model that unifies real-time robotic action execution and high-fidelity 4D world synthesis (video + 3D reconstruction) in a single framework, addressing the critical limitations of prior unified world models (e.g., UWM) that only model 2D pixel-space and fail to balance action efficiency and world modeling quality. To leverage the strong visual priors of pretrained video diffusion models, X-WAM imagines the future world by predicting multi-view RGB-D videos, and obtains spatial information efficiently through a lightweight structural adaptation: replicating the final few blocks of the pretrained Diffusion Transformer into a dedicated depth prediction branch for the reconstruction of future spatial information. Moreover, we propose Asynchronous Noise Sampling (ANS) to jointly optimize generation quality and action decoding efficiency. ANS applies a specialized asynchronous denoising schedule during inference, which rapidly decodes actions with fewer steps to enable efficient real-time execution, while dedicating the full sequence of steps to generate high-fidelity video. Rather than entirely decoupling the timesteps during training, ANS samples from their joint distribution to align with the inference distribution. Pretrained on over 5,800 hours of robotic data, X-WAM achieves 79.2% and 90.7% average success rate on RoboCasa and RoboTwin 2.0 benchmarks, while producing high-fidelity 4D reconstruction and generation surpassing existing methods in both visual and geometric metrics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes X-WAM, a unified 4D world model for robotics that combines real-time action execution with high-fidelity video and 3D reconstruction. It leverages pretrained video diffusion models by predicting multi-view RGB-D videos, using a lightweight adaptation that replicates the final blocks of the Diffusion Transformer into a dedicated depth branch, and introduces Asynchronous Noise Sampling (ANS) that applies an asynchronous denoising schedule at inference (fewer steps for actions, full steps for video) while sampling from the joint timestep distribution during training. Pretrained on over 5,800 hours of robotic data, the method reports 79.2% and 90.7% average success rates on RoboCasa and RoboTwin 2.0 benchmarks along with superior visual and geometric metrics over prior methods.
Significance. If the empirical claims hold after proper validation, the work could meaningfully advance unified world models in robotics by showing how video priors can be adapted for efficient 4D (RGB-D) synthesis and action decoding without full decoupling of modalities. The ANS mechanism for aligning training and inference distributions, together with the structural reuse of DiT blocks, offers a concrete route to balancing real-time constraints and reconstruction quality; credit is due for the scale of pretraining data and the attempt to produce falsifiable benchmark numbers.
major comments (3)
- [§4 and §3.2] §4 (Experiments) and §3.2 (ANS): the central unification claim—that replicating final DiT blocks plus joint-distribution ANS training delivers both efficient action decoding and high-fidelity 4D output without quality trade-offs—rests on an unverified assumption. No ablation isolates the depth branch contribution (e.g., full model vs. depth-branch-removed), no comparison of full vs. truncated denoising trajectories on identical samples is reported, and no analysis shows that the replicated blocks receive sufficient gradient signal to learn consistent depth without auxiliary losses. These omissions make it impossible to confirm that the reported 79.2%/90.7% success rates and metric gains are attributable to the proposed mechanisms rather than to the base video model or training scale.
- [§4.1] §4.1 (Benchmarks): the abstract and results claim superiority on RoboCasa and RoboTwin 2.0, yet the manuscript provides no details on baseline implementations, statistical significance testing, error bars across seeds, or number of evaluation episodes. Without these, the quantitative superiority cannot be assessed as load-bearing evidence for the method.
- [§3.1] §3.1 (Architecture): the claim that the lightweight replication of final blocks 'preserves the video model's visual priors' for accurate future RGB-D prediction is stated without supporting analysis (e.g., feature similarity metrics between original and replicated blocks, or depth consistency checks across views). If the replicated blocks largely copy features rather than learn new spatial reasoning, the 4D reconstruction advantage would not follow.
minor comments (2)
- [§3.2] Notation for the asynchronous schedule (timestep indices, joint vs. marginal distributions) is introduced in §3.2 but never formalized with equations; adding a compact definition of the sampling distribution would improve clarity.
- [Figures 3-5] Figure captions for qualitative 4D results should explicitly state the number of denoising steps used for the action vs. video outputs to allow readers to verify the efficiency claim visually.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications from the manuscript and commit to revisions that strengthen the evidence for our claims without misrepresenting the current results.
read point-by-point responses
-
Referee: [§4 and §3.2] the central unification claim—that replicating final DiT blocks plus joint-distribution ANS training delivers both efficient action decoding and high-fidelity 4D output without quality trade-offs—rests on an unverified assumption. No ablation isolates the depth branch contribution (e.g., full model vs. depth-branch-removed), no comparison of full vs. truncated denoising trajectories on identical samples is reported, and no analysis shows that the replicated blocks receive sufficient gradient signal to learn consistent depth without auxiliary losses.
Authors: We agree that the current experiments do not fully isolate the depth branch and ANS contributions, which limits attribution of the 79.2%/90.7% success rates and metric improvements. In the revised manuscript we will add: (i) an ablation removing the depth branch while keeping the video backbone and ANS, reporting changes in both action success and geometric metrics; (ii) side-by-side denoising trajectory comparisons (full vs. asynchronous schedules) on identical held-out samples with visual and quantitative quality metrics; and (iii) training dynamics analysis (gradient norms or loss curves per block) plus cross-view depth consistency checks to confirm the replicated blocks receive adequate signal. These additions will directly test whether the reported gains stem from the proposed mechanisms. revision: yes
-
Referee: [§4.1] the abstract and results claim superiority on RoboCasa and RoboTwin 2.0, yet the manuscript provides no details on baseline implementations, statistical significance testing, error bars across seeds, or number of evaluation episodes.
Authors: We acknowledge that the current §4.1 lacks the reporting details needed to make the quantitative superiority load-bearing. In revision we will expand the section to specify: exact baseline implementations (including any re-implementation choices or hyper-parameter adaptations for fair comparison), statistical tests (e.g., paired t-tests or Wilcoxon signed-rank with p-values), error bars or standard deviations computed over at least three random seeds, and the precise number of evaluation episodes per task (e.g., 50–100 episodes). This will allow readers to assess the reliability of the reported success rates and metric gains. revision: yes
-
Referee: [§3.1] the claim that the lightweight replication of final blocks 'preserves the video model's visual priors' for accurate future RGB-D prediction is stated without supporting analysis (e.g., feature similarity metrics between original and replicated blocks, or depth consistency checks across views).
Authors: The architectural choice replicates the final DiT blocks to reuse pretrained visual features while adding a lightweight depth head. We recognize that the manuscript currently offers no quantitative verification of prior preservation. In the revised §3.1 we will add: cosine similarity (or equivalent) between activations of the original and replicated blocks on validation data, and cross-view depth consistency metrics (e.g., reprojection error or multi-view agreement scores). If the analysis indicates the blocks largely copy rather than adapt features, we will discuss the implications for the 4D reconstruction advantage and note any required auxiliary losses. revision: yes
Circularity Check
No significant circularity; derivation relies on external pretrained priors and independent benchmarks
full rationale
The paper's core claims rest on a described architectural adaptation (replicating DiT blocks for a depth branch) and a training schedule (ANS sampling from joint timestep distributions) applied to external video diffusion models, followed by empirical reporting of success rates on RoboCasa and RoboTwin 2.0. No equations or steps reduce by construction to fitted parameters renamed as predictions, no self-citations form load-bearing uniqueness arguments, and no ansatz is smuggled via prior author work. The chain is self-contained against external data and benchmarks.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of replicated diffusion blocks
- asynchronous denoising step counts
axioms (1)
- domain assumption Pretrained video diffusion models contain sufficiently strong visual priors that can be adapted for future 4D world prediction with minimal additional structure.
Forward citations
Cited by 1 Pith paper
-
World Action Models: The Next Frontier in Embodied AI
The paper introduces World Action Models as a new paradigm unifying predictive world modeling with action generation in embodied foundation models and provides a taxonomy of existing approaches.
Reference graph
Works this paper leans on
-
[1]
Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R
Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, Paul Wohlhart, Stefan Welker, Ayzaan Wahid, Quan Vuong, Vincent Vanhoucke, Huong T. Tran, Radu Soricut, Anikait Singh, Jaspiar Singh, Pierre Sermanet, Pannag R. Sanketi, Grecia Salazar, Michael S. Ryoo, Krista Reymann, Kanishka Rao, Karl Pertsch, Igor Mordatch, Henryk Michalew...
2023
-
[2]
Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine
Dibya Ghosh, Homer Rich Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, Jianlan Luo, You Liang Tan, Lawrence Yunliang Chen, Quan Vuong, Ted Xiao, Pannag R. Sanketi, Dorsa Sadigh, Chelsea Finn, and Sergey Levine. Octo: An open-source generalist robot policy. InRobotics: Science and Systems, 2024
2024
-
[3]
Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Paul Foster, Pannag R. Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model. InConference on Robot Learning, page...
2024
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. π0: A visi...
work page internal anchor Pith review arXiv 2024
-
[5]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
work page internal anchor Pith review arXiv 2025
-
[6]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith LLontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed, You Liang Tan, Gua...
work page internal anchor Pith review arXiv 2025
-
[7]
Unleashing large-scale video generative pre-training for visual robot manipulation
Hongtao Wu, Ya Jing, Chilam Cheang, Guangzeng Chen, Jiafeng Xu, Xinghang Li, Minghuan Liu, Hang Li, and Tao Kong. Unleashing large-scale video generative pre-training for visual robot manipulation. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[8]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control. CoRR, abs/2601.21998, 2026
work page internal anchor Pith review arXiv 2026
-
[9]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, 10 Jimmy Wu, ...
work page internal anchor Pith review arXiv 2026
-
[10]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?CoRR, abs/2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[11]
Cosmos Policy: Fine-Tuning Video Models for Visuomotor Control and Planning
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos policy: Fine-tuning video models for visuomotor control and planning.CoRR, abs/2601.16163, 2026
work page internal anchor Pith review arXiv 2026
-
[12]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, Min Cao, Peng Li, Qiuping Deng, Wenjun Mei, Xiaofeng Wang, Xinze Chen, Xinyu Zhou, Yang Wang, Yifan Chang, Yifan Li, Yukun Zhou, Yun Ye, Zhichao Liu, and Zheng Zhu. Gigaworld-policy: An efficient action-centered world-action model.CoRR, abs/2603...
-
[13]
Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 640(8059):647–653, 2025
2025
-
[14]
Irasim: A fine-grained world model for robot manipulation
Fangqi Zhu, Hongtao Wu, Song Guo, Yuxiao Liu, Chilam Cheang, and Tao Kong. Irasim: A fine-grained world model for robot manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9834–9844, 2025
2025
-
[15]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[16]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
work page internal anchor Pith review arXiv 2025
-
[17]
Gigaworld-0: World models as data engine to empower embodied ai,
GigaWorld Team, Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Haoyun Li, Jiagang Zhu, Kerui Li, Mengyuan Xu, et al. Gigaworld-0: World models as data engine to empower embodied ai.arXiv preprint arXiv:2511.19861, 2025
- [18]
-
[19]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.CoRR, abs/2504.02792, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, Hongyan Zhao, Hanyu Liu, Zhizhong Su, Lei Ma, Hang Su, and Jun Zhu. Motus: A unified latent action world model.CoRR, abs/2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[21]
Yichao Shen, Fangyun Wei, Zhiying Du, Yaobo Liang, Yan Lu, Jiaolong Yang, Nanning Zheng, and Baining Guo. Videovla: Video generators can be generalizable robot manipulators.CoRR, abs/2512.06963, 2025
-
[22]
Yue Liao, Pengfei Zhou, Siyuan Huang, Donglin Yang, Shengcong Chen, Yuxin Jiang, Hu Yue, Jingbin Cai, Si Liu, Jianlan Luo, Liliang Chen, Shuicheng Yan, Maoqing Yao, and Guanghui Ren. Genie envisioner: A unified world foundation platform for robotic manipulation.CoRR, abs/2508.05635, 2025
-
[23]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[24]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021. 11
2021
-
[25]
Elucidating the design space of diffusion-based generative models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. InAdvances in neural information processing systems, volume 35, pages 26565–26577, 2022
2022
-
[26]
Diffusion policy: Visuomotor policy learning via action diffusion
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[27]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic-video: Video-action models for generalizable robot control beyond vlas.CoRR, abs/2512.15692, 2025
-
[28]
Teli Ma, Jia Zheng, Zifan Wang, Chunli Jiang, Andy Cui, Junwei Liang, and Shuo Yang. Dit4dit: Jointly modeling video dynamics and actions for generalizable robot control.CoRR, abs/2603.10448, 2026
-
[29]
Vision-language foundation models as effective robot imitators
Xinghang Li, Minghuan Liu, Hanbo Zhang, Cunjun Yu, Jie Xu, Hongtao Wu, Chilam Cheang, Ya Jing, Weinan Zhang, Huaping Liu, Hang Li, and Tao Kong. Vision-language foundation models as effective robot imitators. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[30]
RDT-1B: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[31]
Rui Cai, Jun Guo, Xinze He, Piaopiao Jin, Jie Li, Bingxuan Lin, Futeng Liu, Wei Liu, Fei Ma, Kun Ma, Feng Qiu, Heng Qu, Yifei Su, Qiao Sun, Dong Wang, Donghao Wang, Yunhong Wang, Rujie Wu, Diyun Xiang, Yu Yang, Hangjun Ye, Yuan Zhang, and Quanyun Zhou. Xiaomi- robotics-0: An open-sourced vision-language-action model with real-time execution.CoRR, abs/2602...
-
[32]
Learning universal policies via text-guided video generation
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation. InAdvances in Neural Information Processing Systems, 2023
2023
-
[33]
Video prediction policy: A generalist robot policy with predictive visual representations
Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, and Jianyu Chen. Video prediction policy: A generalist robot policy with predictive visual representations. InForty-second International Conference on Machine Learning, 2025
2025
-
[34]
Scaling world model for hierarchical manipula- tion policies.CoRR, abs/2602.10983, 2026
Qian Long, Yueze Wang, Jiaxi Song, Junbo Zhang, Peiyan Li, Wenxuan Wang, Yuqi Wang, Haoyang Li, Shaoxuan Xie, Guocai Yao, Hanbo Zhang, Xinlong Wang, Zhongyuan Wang, Xuguang Lan, Huaping Liu, and Xinghang Li. Scaling world model for hierarchical manipula- tion policies.CoRR, abs/2602.10983, 2026
-
[35]
Harizanov, and Jeffrey B
Douglas Cenzer, Valentina S. Harizanov, and Jeffrey B. Remmel.Σ01 and Π01 equivalence structures.Ann. Pure Appl. Log., 162(7):490–503, 2011
2011
-
[36]
Yi Chen, Yuying Ge, Yizhuo Li, Yixiao Ge, Mingyu Ding, Ying Shan, and Xihui Liu. Moto: Latent motion token as the bridging language for robot manipulation.CoRR, abs/2412.04445, 2024
-
[37]
WorldVLA: Towards Autoregressive Action World Model
Jun Cen, Chaohui Yu, Hangjie Yuan, Yuming Jiang, Siteng Huang, Jiayan Guo, Xin Li, Yibing Song, Hao Luo, Fan Wang, Deli Zhao, and Hao Chen. Worldvla: Towards autoregressive action world model.CoRR, abs/2506.21539, 2025
work page internal anchor Pith review arXiv 2025
-
[38]
Wenyao Zhang, Hongsi Liu, Zekun Qi, Yunnan Wang, Xinqiang Yu, Jiazhao Zhang, Runpei Dong, Jiawei He, He Wang, Zhizheng Zhang, Li Yi, Wenjun Zeng, and Xin Jin. Dreamvla: A vision-language-action model dreamed with comprehensive world knowledge.CoRR, abs/2507.04447, 2025
-
[39]
Unifiedvision-language-action model.arXiv preprint arXiv:2506.19850,
Yuqi Wang, Xinghang Li, Wenxuan Wang, Junbo Zhang, Yingyan Li, Yuntao Chen, Xinlong Wang, and Zhaoxiang Zhang. Unified vision-language-action model.CoRR, abs/2506.19850, 2025. 12
-
[40]
Jingwen Sun, Wenyao Zhang, Zekun Qi, Shaojie Ren, Zezhi Liu, Hanxin Zhu, Guangzhong Sun, Xin Jin, and Zhibo Chen. VLA-JEPA: enhancing vision-language-action model with latent world model.CoRR, abs/2602.10098, 2026
-
[41]
Yucheng Hu, Jianke Zhang, Yuanfei Luo, Yanjiang Guo, Xiaoyu Chen, Xinshu Sun, Kun Feng, Qingzhou Lu, Sheng Chen, Yangang Zhang, Wei Li, and Jianyu Chen. Bagelvla: Enhancing long-horizon manipulation via interleaved vision-language-action generation.CoRR, abs/2602.09849, 2026
-
[42]
Do World Action Models Generalize Better than VLAs? A Robustness Study
Zhanguang Zhang, Zhiyuan Li, Behnam Rahmati, Rui Heng Yang, Yintao Ma, Amir Rasouli, Sajjad Pakdamansavoji, Yangzheng Wu, Lingfeng Zhang, Tongtong Cao, Feng Wen, Xinyu Wang, Xingyue Quan, and Yingxue Zhang. Do world action models generalize better than vlas? A robustness study.CoRR, abs/2603.22078, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
3d-vla: A 3d vision-language-action generative world model
Haoyu Zhen, Xiaowen Qiu, Peihao Chen, Jincheng Yang, Xin Yan, Yilun Du, Yining Hong, and Chuang Gan. 3d-vla: A 3d vision-language-action generative world model. InForty-first International Conference on Machine Learning, pages 61229–61245, 2024
2024
-
[44]
SpatialVLA: Exploring Spatial Representations for Visual-Language-Action Model
Delin Qu, Haoming Song, Qizhi Chen, Yuanqi Yao, Xinyi Ye, Yan Ding, Zhigang Wang, JiaYuan Gu, Bin Zhao, Dong Wang, and Xuelong Li. Spatialvla: Exploring spatial representations for visual-language-action model.CoRR, abs/2501.15830, 2025
work page internal anchor Pith review arXiv 2025
-
[45]
Tao Lin, Gen Li, Yilei Zhong, Yanwen Zou, and Bo Zhao. Evo-0: Vision-language-action model with implicit spatial understanding.CoRR, abs/2507.00416, 2025
-
[46]
Fuhao Li, Wenxuan Song, Han Zhao, Jingbo Wang, Pengxiang Ding, Donglin Wang, Long Zeng, and Haoang Li. Spatial forcing: Implicit spatial representation alignment for vision- language-action model.CoRR, abs/2510.12276, 2025
-
[47]
Zhengshen Zhang, Hao Li, Yalun Dai, Zhengbang Zhu, Lei Zhou, Chenchen Liu, Dong Wang, Francis E. H. Tay, Sijin Chen, Ziwei Liu, Yuxiao Liu, Xinghang Li, and Pan Zhou. From spatial to actions: Grounding vision-language-action model in spatial foundation priors.CoRR, abs/2510.17439, 2025
-
[48]
Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics Autom
Chengmeng Li, Junjie Wen, Yaxin Peng, Yan Peng, and Yichen Zhu. Pointvla: Injecting the 3d world into vision-language-action models.IEEE Robotics Autom. Lett., 11(3):2506–2513, 2026
2026
-
[49]
Geovla: Em- powering 3d representations in vision-language-action models,
Lin Sun, Bin Xie, Yingfei Liu, Hao Shi, Tiancai Wang, and Jiale Cao. Geovla: Empowering 3d representations in vision-language-action models.CoRR, abs/2508.09071, 2025
-
[50]
Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models
Peiyan Li, Yixiang Chen, Hongtao Wu, Xiao Ma, Xiangnan Wu, Yan Huang, Liang Wang, Tao Kong, and Tieniu Tan. Bridgevla: Input-output alignment for efficient 3d manipulation learning with vision-language models.CoRR, abs/2506.07961, 2025
-
[51]
Tesseract: Learning 4d embodied world models, 2025
Haoyu Zhen, Qiao Sun, Hongxin Zhang, Junyan Li, Siyuan Zhou, Yilun Du, and Chuang Gan. Tesseract: Learning 4d embodied world models.CoRR, abs/2504.20995, 2025
-
[52]
Flowdreamer: A RGB-D world model with flow-based motion representations for robot manipulation.IEEE Robotics Automation Letters, 11(3):2466–2473, 2026
Jun Guo, Xiaojian Ma, Yikai Wang, Min Yang, Huaping Liu, and Qing Li. Flowdreamer: A RGB-D world model with flow-based motion representations for robot manipulation.IEEE Robotics Automation Letters, 11(3):2466–2473, 2026
2026
-
[53]
Enerverse: Envisioning embodied future space for robotics manipu- lation, 2025
Siyuan Huang, Liliang Chen, Pengfei Zhou, Shengcong Chen, Zhengkai Jiang, Yutao Hu, Peng Gao, Hongsheng Li, Maoqing Yao, and Guanghui Ren. Enerverse: Envisioning embodied future space for robotics manipulation.CoRR, abs/2501.01895, 2025
-
[54]
Geometry-aware 4d video generation for robot manipulation.CoRR, abs/2507.01099, 2025
Zeyi Liu, Shuang Li, Eric Cousineau, Siyuan Feng, Benjamin Burchfiel, and Shuran Song. Geometry-aware 4d video generation for robot manipulation.CoRR, abs/2507.01099, 2025
-
[55]
Wenbing Huang, Yu-Wei Chao, Arsalan Mousavian, Ming-Yu Liu, Dieter Fox, Kaichun Mo, and Li Fei-Fei. Pointworld: Scaling 3d world models for in-the-wild robotic manipulation. CoRR, abs/2601.03782, 2026
-
[56]
Zezhong Qian, Xiaowei Chi, Yuming Li, Shizun Wang, Zhiyuan Qin, Xiaozhu Ju, Sirui Han, and Shanghang Zhang. Wristworld: Generating wrist-views via 4d world models for robotic manipulation.CoRR, abs/2510.07313, 2025. 13
-
[57]
MVISTA-4D: View-consistent 4d world model with test-time action inference for robotic manip- ulation
Jiaxu Wang, Yicheng Jiang, Tianlun He, Jingkai Sun, Qiang Zhang, Junhao He, Jiahang Cao, Zesen Gan, Mingyuan Sun, Qiming Shao, and Xiangyu Yue. MVISTA-4D: view-consistent 4d world model with test-time action inference for robotic manipulation.CoRR, abs/2602.09878, 2026
-
[58]
Mani- gaussian: Dynamic gaussian splatting for multi-task robotic manipulation
Guanxing Lu, Shiyi Zhang, Ziwei Wang, Changliu Liu, Jiwen Lu, and Yansong Tang. Mani- gaussian: Dynamic gaussian splatting for multi-task robotic manipulation. In18th European Conference on Computer Vision, pages 349–366, 2024
2024
-
[59]
GWM: towards scalable gaussian world models for robotic manipulation.CoRR, abs/2508.17600, 2025
Guanxing Lu, Baoxiong Jia, Puhao Li, Yixin Chen, Ziwei Wang, Yansong Tang, and Siyuan Huang. GWM: towards scalable gaussian world models for robotic manipulation.CoRR, abs/2508.17600, 2025
-
[60]
3d gaussian splatting for real-time radiance field rendering.ACM Trans
Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Trans. Graph., 42(4):139:1–139:14, 2023
2023
-
[61]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jérôme Revaud. Dust3r: Geometric 3d vision made easy. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20697–20709, 2024
2024
-
[62]
VGGT: visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotný. VGGT: visual geometry grounded transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5294–5306, 2025
2025
-
[63]
Video depth anything: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, and Bingyi Kang. Video depth anything: Consistent depth estimation for super-long videos. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22831–22840, 2025
2025
-
[64]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y . Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.CoRR, abs/2511.10647, 2025
work page internal anchor Pith review arXiv 2025
-
[65]
Multi-View Video Diffusion Policy: A 3D Spatio-Temporal-Aware Video Action Model
Peiyan Li, Yixiang Chen, Yuan Xu, Jiabing Yang, Xiangnan Wu, Jun Guo, Nan Sun, Long Qian, Xinghang Li, Xin Xiao, Jing Liu, Nianfeng Liu, Tao Kong, Yan Huang, Liang Wang, and Tieniu Tan. Multi-view video diffusion policy: A 3d spatio-temporal-aware video action model.CoRR, abs/2604.03181, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[66]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review arXiv 2025
-
[67]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[68]
Flow matching for generative modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[69]
Unipc: A unified predictor- corrector framework for fast sampling of diffusion models
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor- corrector framework for fast sampling of diffusion models. InAdvances in Neural Information Processing Systems, volume 36, pages 49842–49869, 2023
2023
-
[70]
Robocasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots. InRSS Workshop: Data Generation for Robotics, 2024
2024
-
[71]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review arXiv 2025
-
[72]
Qingwen Bu, Jisong Cai, Li Chen, Xiuqi Cui, Yan Ding, Siyuan Feng, Shenyuan Gao, Xindong He, Xuan Hu, Xu Huang, et al. Agibot world colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669, 2025. 14
work page internal anchor Pith review arXiv 2025
-
[73]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review arXiv 2024
-
[74]
Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, et al. Interndata-a1: Pioneering high-fidelity synthetic data for pre-training generalist policy.arXiv preprint arXiv:2511.16651, 2025
-
[75]
Mimicgen: A data generation system for scalable robot learning using human demonstrations, 2023
Ajay Mandlekar, Soroush Nasiriany, Bowen Wen, Iretiayo Akinola, Yashraj Narang, Linxi Fan, Yuke Zhu, and Dieter Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations.arXiv preprint arXiv:2310.17596, 2023
-
[76]
Real-time execution of action chunking flow policies.arXiv preprint arXiv:2506.07339, 2025
Kevin Black, Manuel Y Galliker, and Sergey Levine. Real-time execution of action chunking flow policies.arXiv preprint arXiv:2506.07339, 2025. 15 A Detailed Algorithms We provide the complete algorithmic procedures for X-W AM. Algorithm 1 details the single denoising step, which jointly processes the multi-modal sequence through the shared DiT trunk and t...
-
[77]
Grasp the empty earphone case and open the lid
-
[78]
Pick up one earphone and correctly place it into the case
-
[79]
Pick up the other earphone and correctly place it into the case
-
[80]
19 (a) Scalability Settings(b) Generalization Settings Figure 3: Real-world experimental setup
Close the lid and return the case to the table. 19 (a) Scalability Settings(b) Generalization Settings Figure 3: Real-world experimental setup. The AC One dual-arm platform is equipped with one main camera providing a global view and two wrist-mounted cameras for close-up observations. The earphone packing task requires precise bimanual coordination and r...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.