Can I Take Another Dose? Evaluating LLM Decision-Making Under Temporal Uncertainty in OTC Dosing QA
Pith reviewed 2026-06-28 09:45 UTC · model grok-4.3
The pith
LLMs frequently violate safe dosing rules in OTC medication questions even when their answers look stable and confident.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
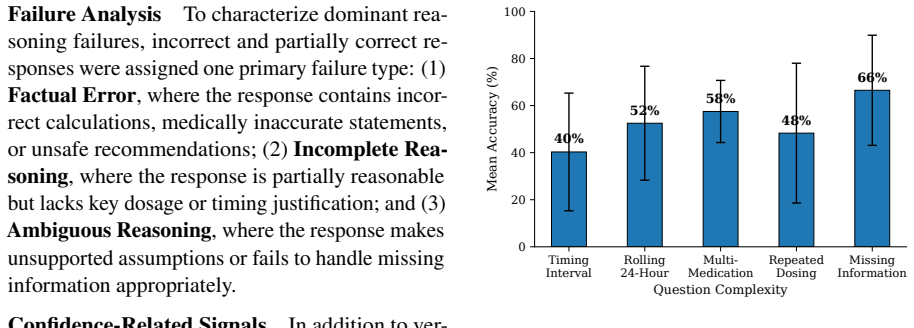
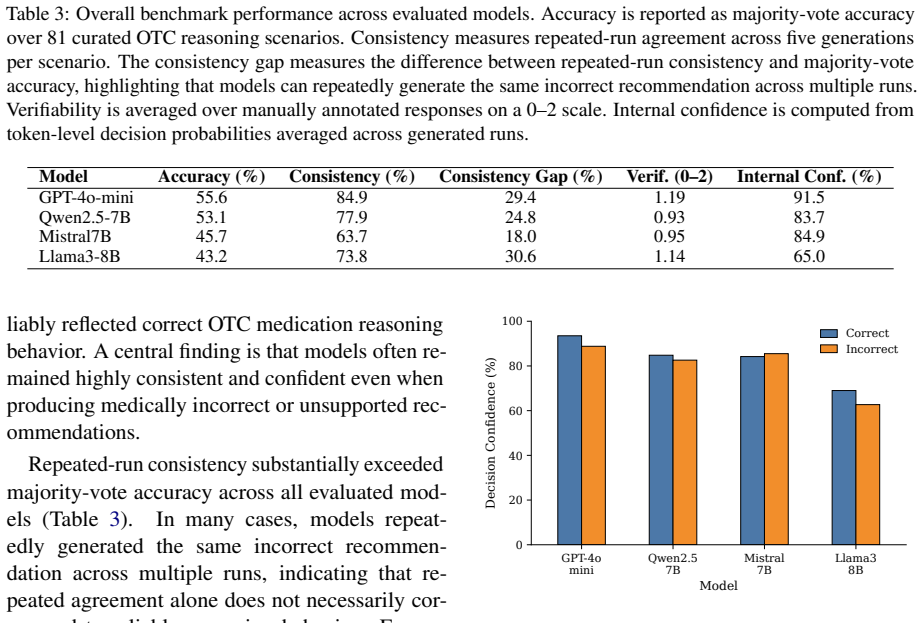
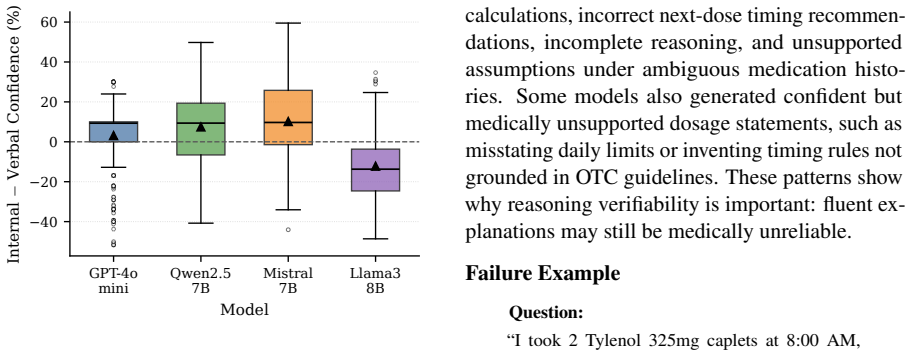
The paper establishes that current LLMs struggle with the temporal and constraint-following demands of OTC dosing queries, as shown by their performance on DOSEBENCH: models often fail to maintain accurate rolling 24-hour intake tracking and to handle ambiguity in medication histories, while stable or high-confidence outputs can still produce decisions that violate label constraints.
What carries the argument
DOSEBENCH, a benchmark of 81 manually annotated OTC dosing scenarios focused on acetaminophen and ibuprofen that requires rolling-window timing, constraint application, and uncertainty handling.
If this is right
- OTC dosing questions expose a gap between surface-level consistency and actual constraint satisfaction that standard medical QA benchmarks miss.
- Safety-relevant decisions in this domain require explicit mechanisms for maintaining temporal state across conversation turns.
- High model confidence or response stability does not reliably indicate compliance with dosing rules.
- The narrow task of OTC dosing QA can serve as a repeatable testbed for measuring progress on temporal reasoning and uncertainty handling.
Where Pith is reading between the lines
- Deployment of LLMs for consumer health advice may need external guardrails that verify timing calculations independently of the model's text output.
- Similar temporal-tracking failures could appear in other recurring health tasks such as blood-pressure logging or prescription refill reminders.
- Expanding the benchmark with multi-turn conversations would test whether models can update internal dose tallies when users supply new information mid-dialogue.
Load-bearing premise
The 81 manually curated scenarios and their gold references accurately represent the full space of real-world OTC dosing queries and safety constraints that users actually pose.
What would settle it
A follow-up evaluation on several hundred real user queries drawn from public medical forums or poison-control logs that shows models achieving near-perfect accuracy on rolling-window and constraint checks would falsify the reported pattern of frequent failures.
Figures

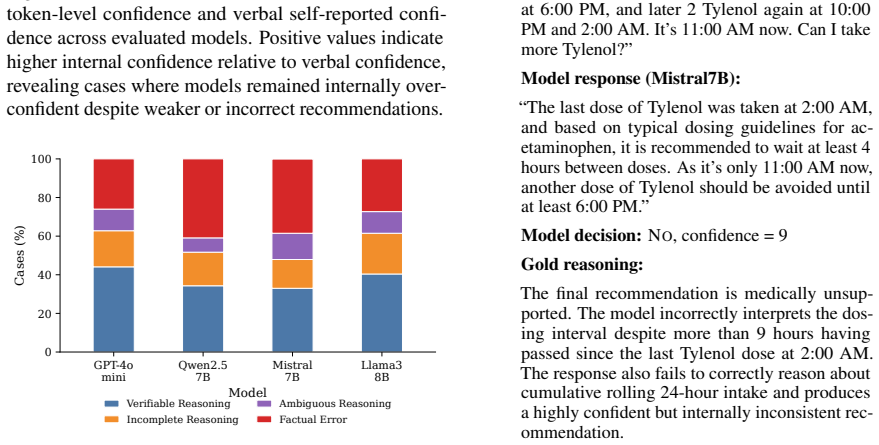
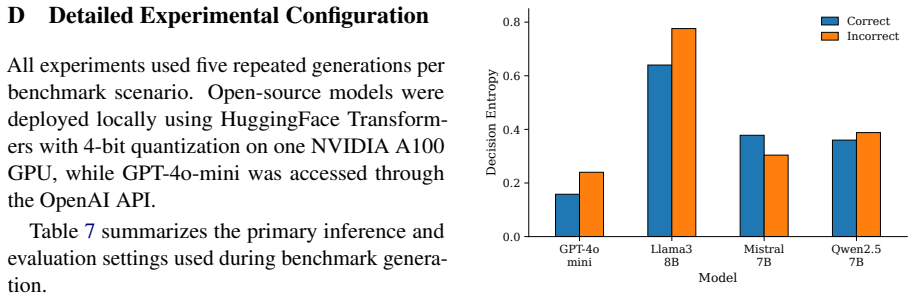
read the original abstract
Large language models (LLMs) are increasingly used for everyday health questions, including whether a user can safely take another dose of an over-the-counter (OTC) medication. Yet this common safety-relevant setting remains underexplored in existing medical QA evaluations, where correct answers require tracking dose timing, computing rolling 24-hour intake, following product-label constraints, and handling incomplete medication histories. We introduce DOSEBENCH, a focused benchmark of 81 curated OTC dosing scenarios focused on adult acetaminophen and ibuprofen use, with manually annotated gold references. We evaluate four LLMs across repeated runs using metrics for decision correctness, consistency, explanation verifiability, failure types, and confidence-related signals, resulting in 1,620 model responses. Our results show that models frequently struggle with rolling-window reasoning and ambiguity-sensitive cases and that stable or confident-looking responses can still violate dosing constraints. These findings suggest that OTC dosing QA provides a narrow yet practical testbed for evaluating temporal reasoning, constraint following, and safety-relevant uncertainty handling in medical QA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DOSEBENCH, a benchmark of 81 manually curated adult acetaminophen/ibuprofen dosing scenarios with gold references. It evaluates four LLMs across 1,620 repeated-run responses using metrics for decision correctness, consistency, explanation verifiability, failure types, and confidence signals. The central claim is that models frequently struggle with rolling-window reasoning and ambiguity-sensitive cases, and that stable or confident responses can still violate dosing constraints, positioning OTC dosing QA as a practical testbed for temporal reasoning and safety in medical QA.
Significance. If the benchmark is representative, the work supplies a narrow, reproducible empirical testbed that isolates temporal uncertainty and constraint-following failures in a safety-relevant domain. The use of repeated runs, multiple metrics, and explicit failure categorization is a methodological strength that enables targeted follow-up. The findings, if robust, would usefully complement broader medical QA benchmarks by focusing on rolling 24-hour intake calculations and incomplete histories.
major comments (3)
- [Benchmark Construction] Benchmark Construction section: The 81 scenarios rely on manual gold annotation, yet no inter-annotator agreement statistics, curation protocol, or explicit failure taxonomy are reported. This directly affects the reliability of the correctness and failure-type metrics that support the claim of frequent struggles.
- [Evaluation] Evaluation section: No quantitative comparison (e.g., overlap statistics or coverage metrics) to real user query logs, search data, or clinical records is provided to establish that the scenarios capture phrasing variation, multi-drug histories, pediatric edge cases, or label ambiguities. Without such grounding, the reported failure rates cannot underwrite the generalization to 'OTC dosing QA' as a practical setting.
- [Results] Results section: The paper states that models 'frequently struggle' and reports consistency and confidence signals, but no statistical tests, confidence intervals, or effect-size measures accompany the failure rates or cross-model comparisons. This leaves the strength of the central empirical claim difficult to assess.
minor comments (2)
- [Abstract] Abstract: The four evaluated LLMs are not named; adding their identities would improve immediate readability.
- The description of the 1,620 responses could explicitly state the number of runs per scenario per model to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on benchmark construction, evaluation grounding, and statistical reporting. We address each major comment below with plans for revision where feasible.
read point-by-point responses
-
Referee: [Benchmark Construction] Benchmark Construction section: The 81 scenarios rely on manual gold annotation, yet no inter-annotator agreement statistics, curation protocol, or explicit failure taxonomy are reported. This directly affects the reliability of the correctness and failure-type metrics that support the claim of frequent struggles.
Authors: We agree the lack of reported details weakens perceived reliability. Curation followed a single-expert protocol based on FDA OTC labels for adult acetaminophen/ibuprofen (dosing intervals, 24h maxima, contraindications), with an internal failure taxonomy for categories like rolling-window errors and ambiguity handling. We will add the full curation protocol and explicit failure taxonomy to the revised Benchmark Construction section. IAA is not applicable due to single-annotator design; we will explicitly note this limitation. revision: yes
-
Referee: [Evaluation] Evaluation section: No quantitative comparison (e.g., overlap statistics or coverage metrics) to real user query logs, search data, or clinical records is provided to establish that the scenarios capture phrasing variation, multi-drug histories, pediatric edge cases, or label ambiguities. Without such grounding, the reported failure rates cannot underwrite the generalization to 'OTC dosing QA' as a practical setting.
Authors: The benchmark is intentionally narrow to isolate temporal uncertainty and constraint failures rather than represent all OTC queries. Scenarios were manually selected to cover phrasing variation, incomplete histories, and label ambiguities drawn from common clinical patterns. We lack access to proprietary logs for quantitative overlap metrics and cannot provide them. We will expand the Evaluation section with detailed selection criteria and coverage of key dimensions to better justify the testbed framing without overclaiming representativeness. revision: partial
-
Referee: [Results] Results section: The paper states that models 'frequently struggle' and reports consistency and confidence signals, but no statistical tests, confidence intervals, or effect-size measures accompany the failure rates or cross-model comparisons. This leaves the strength of the central empirical claim difficult to assess.
Authors: We acknowledge this gap in rigor. The revised Results section will incorporate chi-square tests for cross-model correctness differences, bootstrap confidence intervals on failure rates, and effect sizes (e.g., Cohen's h) for proportion comparisons. This will allow quantitative assessment of the 'frequent struggles' claim. revision: yes
Circularity Check
No circularity: empirical benchmark evaluation with no derivations or self-referential reductions
full rationale
The paper introduces DOSEBENCH as a manually curated set of 81 OTC dosing scenarios with gold labels, then reports empirical LLM performance metrics across 1620 responses. No equations, fitted parameters, predictions, or uniqueness theorems appear in the provided text. Claims about model struggles with rolling-window reasoning rest directly on observed outputs versus the external gold references, with no reduction to self-citation chains or ansatzes. This matches the default case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Manually annotated gold references correctly encode product-label constraints and rolling 24-hour intake rules for the chosen medications.
Reference graph
Works this paper leans on
-
[1]
Nature Medicine , volume=
Toward Expert-Level Medical Question Answering with Large Language Models , author=. Nature Medicine , volume=. 2025 , doi=
2025
-
[2]
MEDINFO 2019: Health and Wellbeing e-Networks for All , publisher=
Bridging the Gap Between Consumers' Medication Questions and Trusted Answers , author=. MEDINFO 2019: Health and Wellbeing e-Networks for All , publisher=. 2019 , doi=
2019
-
[4]
Nature , volume=
Large Language Models Encode Clinical Knowledge , author=. Nature , volume=. 2023 , doi=
2023
-
[5]
PLOS Digital Health , volume=
Performance of ChatGPT on USMLE: Potential for AI-Assisted Medical Education Using Large Language Models , author=. PLOS Digital Health , volume=. 2023 , doi=
2023
-
[7]
Artificial Intelligence in Medicine , volume=
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering , author=. Artificial Intelligence in Medicine , volume=. 2024 , doi=
2024
-
[8]
Proceedings of the ACM Web Conference 2024 , pages=
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries , author=. Proceedings of the ACM Web Conference 2024 , pages=. 2024 , publisher=
2024
-
[9]
AMIA Annual Symposium Proceedings , volume=
RealMedQA: A Pilot Biomedical Question Answering Dataset Containing Realistic Clinical Questions , author=. AMIA Annual Symposium Proceedings , volume=
-
[10]
The World Wide Web Conference , pages=
A Hierarchical Attention Retrieval Model for Healthcare Question Answering , author=. The World Wide Web Conference , pages=. 2019 , publisher=
2019
-
[12]
Transactions on Machine Learning Research , year=
Teaching Models to Express Their Uncertainty in Words , author=. Transactions on Machine Learning Research , year=
-
[13]
International Conference on Learning Representations , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. International Conference on Learning Representations , year=
-
[16]
Journal of Medical Internet Research , volume=
Token Probabilities to Mitigate Large Language Models Overconfidence in Answering Medical Questions: Quantitative Study , author=. Journal of Medical Internet Research , volume=. 2025 , doi=
2025
-
[17]
2025 , url=
DailyMed , author=. 2025 , url=
2025
-
[19]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[22]
Journal of Medical Systems , volume=
Evaluating the Feasibility of ChatGPT in Healthcare: An Analysis of Multiple Clinical and Research Scenarios , author=. Journal of Medical Systems , volume=. 2023 , doi=
2023
-
[23]
Findings of the Association for Computational Linguistics: EACL 2024 , pages=
Exploring the Potential of ChatGPT on Sentence Level Relations: A Focus on Temporal, Causal, and Discourse Relations , author=. Findings of the Association for Computational Linguistics: EACL 2024 , pages=. 2024 , address=. doi:10.18653/v1/2024.findings-eacl.47 , url=
-
[24]
arXiv preprint arXiv:2304.08247 , year=
MedAlpaca--An Open-Source Collection of Medical Conversational AI Models and Training Data , author=. arXiv preprint arXiv:2304.08247 , year=. 2304.08247 , archivePrefix=
-
[25]
arXiv preprint arXiv:2308.07308 , year=
LLM Self Defense: By Self Examination, LLMs Know They Are Being Tricked , author=. arXiv preprint arXiv:2308.07308 , year=. 2308.07308 , archivePrefix=
-
[26]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Consistency Analysis of ChatGPT , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=. 2023 , address=. doi:10.18653/v1/2023.emnlp-main.991 , url=
-
[27]
Learning and Individual Differences , volume=
ChatGPT for Good? On Opportunities and Challenges of Large Language Models for Education , author=. Learning and Individual Differences , volume=. 2023 , doi=
2023
-
[28]
Applied Sciences , volume=
What Disease Does This Patient Have? A Large-Scale Open Domain Question Answering Dataset from Medical Exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[29]
Proceedings of the Conference on Health, Inference, and Learning , pages =
MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering , author =. Proceedings of the Conference on Health, Inference, and Learning , pages =. 2022 , editor =
2022
-
[30]
Advances in AI for Safety, Equity, and Well-Being on Web and Social Media: Detection, Robustness, Attribution, and Mitigation , author=. Proceedings of the Thirty-Seventh AAAI Conference on Artificial Intelligence and Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence and Thirteenth Symposium on Educational Advances in Artificia...
-
[31]
Patterns , volume=
Can Large Language Models Reason About Medical Questions? , author=. Patterns , volume=. 2024 , doi=
2024
-
[32]
arXiv preprint arXiv:2303.13375 , year=
Capabilities of GPT-4 on Medical Challenge Problems , author=. arXiv preprint arXiv:2303.13375 , year=. 2303.13375 , archivePrefix=
-
[33]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
ReadMe++: Benchmarking Multilingual Language Models for Multi-Domain Readability Assessment , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , address=. doi:10.18653/v1/2024.emnlp-main.682 , url=
-
[34]
2023 , url=
Large Language Models: What Is Driving the Hype Behind LLM's in Healthcare? , author=. 2023 , url=
2023
-
[35]
International Conference on Learning Representations , year=
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning , author=. International Conference on Learning Representations , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Benchmarking Foundation Models with Language-Model-as-an-Examiner , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
Uncertainty-aware reliable text classification , author=. Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining , pages=
-
[38]
Asma Ben Abacha, Yassine Mrabet, Mark Sharp, Travis R. Goodwin, Sonya E. Shooshan, and Dina Demner-Fushman. 2019. https://doi.org/10.3233/SHTI190176 Bridging the gap between consumers' medication questions and trusted answers . In MEDINFO 2019: Health and Wellbeing e-Networks for All, pages 25--29. IOS Press
-
[39]
AI@Meta . 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . Preprint, arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[40]
I \ n igo Alonso, Maite Oronoz, and Rodrigo Agerri. 2024. https://doi.org/10.1016/j.artmed.2024.102938 Medexpqa: Multilingual benchmarking of large language models for medical question answering . Artificial Intelligence in Medicine, 155:102938
-
[41]
Rapha \"e l Bentegeac, Bastien Le Guellec, Gr \'e gory Kuchcinski, Philippe Amouyel, and Aghiles Hamroun. 2025. https://doi.org/10.2196/64348 Token probabilities to mitigate large language models overconfidence in answering medical questions: Quantitative study . Journal of Medical Internet Research, 27:e64348
-
[42]
Jiahui Geng, Fengyu Cai, Yuxia Wang, Heinz Koeppl, Preslav Nakov, and Iryna Gurevych. 2024. https://doi.org/10.18653/v1/2024.naacl-long.366 A survey of confidence estimation and calibration in large language models . In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technol...
-
[43]
Yibo Hu and Latifur Khan. 2021. Uncertainty-aware reliable text classification. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 628--636
2021
-
[44]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. 2023. https://arxiv.org/ab...
Pith/arXiv arXiv 2023
-
[45]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. https://doi.org/10.3390/app11146421 What disease does this patient have? a large-scale open domain question answering dataset from medical exams . Applied Sciences, 11(14):6421
-
[46]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, and 17 others. 2022. https://arxiv.org/abs/2207.05221 Language models (mostly...
Pith/arXiv arXiv 2022
-
[47]
Marshall
Gregory Kell, Angus Roberts, Serge Umansky, Yuti Khare, Najma Ahmed, Nikhil Patel, Chloe Simela, Jack Coumbe, Julian Rozario, Ryan-Rhys Griffiths, and Iain J. Marshall. 2025. Realmedqa: A pilot biomedical question answering dataset containing realistic clinical questions. In AMIA Annual Symposium Proceedings, volume 2024, pages 590--598
2025
-
[48]
Yunsoo Kim, Jinge Wu, Yusuf Abdulle, and Honghan Wu. 2024. https://doi.org/10.18653/v1/2024.bionlp-1.14 Medexqa: Medical question answering benchmark with multiple explanations . In Proceedings of the 23rd Workshop on Biomedical Natural Language Processing, pages 167--181, Bangkok, Thailand. Association for Computational Linguistics
-
[49]
Tiffany H. Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepa \ n o, Maria Madriaga, Rimel Aggabao, Giezel Diaz-Candido, James Maningo, and Victor Tseng. 2023. https://doi.org/10.1371/journal.pdig.0000198 Performance of chatgpt on usmle: Potential for ai-assisted medical education using large language models . PLOS Digi...
-
[50]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. https://openreview.net/forum?id=8s8K2UZGTZ Teaching models to express their uncertainty in words . Transactions on Machine Learning Research
2022
-
[51]
Potsawee Manakul, Adian Liusie, and Mark Gales. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.557 Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004--9017, Singapore. Association for Computational Linguistics
-
[52]
OpenAI . 2024. https://arxiv.org/abs/2410.21276 Gpt-4o system card . arXiv preprint arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[53]
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. 2022. https://proceedings.mlr.press/v174/pal22a.html Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering . In Proceedings of the Conference on Health, Inference, and Learning, volume 174 of Proceedings of Machine Learning Research, pages 248--260. PMLR
2022
-
[54]
Qwen Team . 2024. https://arxiv.org/abs/2412.15115 Qwen2.5 technical report . arXiv preprint arXiv:2412.15115
Pith/arXiv arXiv 2024
-
[55]
Karan Singhal, Tao Tu, Juraj Gottweis, Rory Sayres, Ellery Wulczyn, Mohamed Amin, Le Hou, Kevin Clark, Stephen R. Pfohl, Heather Cole-Lewis, Darlene Neal, Qazi Mamunur Rashid, Mike Schaekermann, Amy Wang, Dev Dash, Jonathan H. Chen, Nigam H. Shah, Sami Lachgar, Philip Andrew Mansfield, and 16 others. 2025. https://doi.org/10.1038/s41591-024-03423-7 Toward...
-
[56]
Huqun Suri, Qi Zhang, Wenhua Huo, Yan Liu, and Chunsheng Guan. 2021. https://arxiv.org/abs/2108.08074 Mediaqa: A question answering dataset on medical dialogues . arXiv preprint arXiv:2108.08074
arXiv 2021
-
[57]
National Library of Medicine
U.S. National Library of Medicine . 2025. https://dailymed.nlm.nih.gov/dailymed/ Dailymed
2025
-
[58]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. https://openreview.net/forum?id=1PL1NIMMrw Self-consistency improves chain of thought reasoning in language models . In International Conference on Learning Representations
2023
-
[59]
Ming Zhu, Aman Ahuja, Wei Wei, and Chandan K. Reddy. 2019. https://doi.org/10.1145/3308558.3313699 A hierarchical attention retrieval model for healthcare question answering . In The World Wide Web Conference, pages 2472--2482. Association for Computing Machinery
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.