LoopMoE: Unifying Iterative Computation with Mixture-of-Experts for Language Modeling
Pith reviewed 2026-06-28 07:17 UTC · model grok-4.3
The pith
LoopMoE adds iterative computation to mixture-of-experts models and outperforms vanilla MoE at matched total parameters and per-token FLOPs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
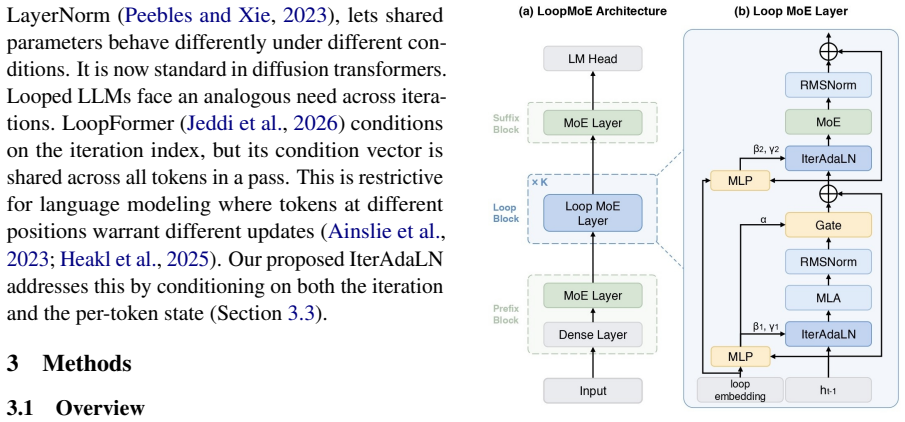
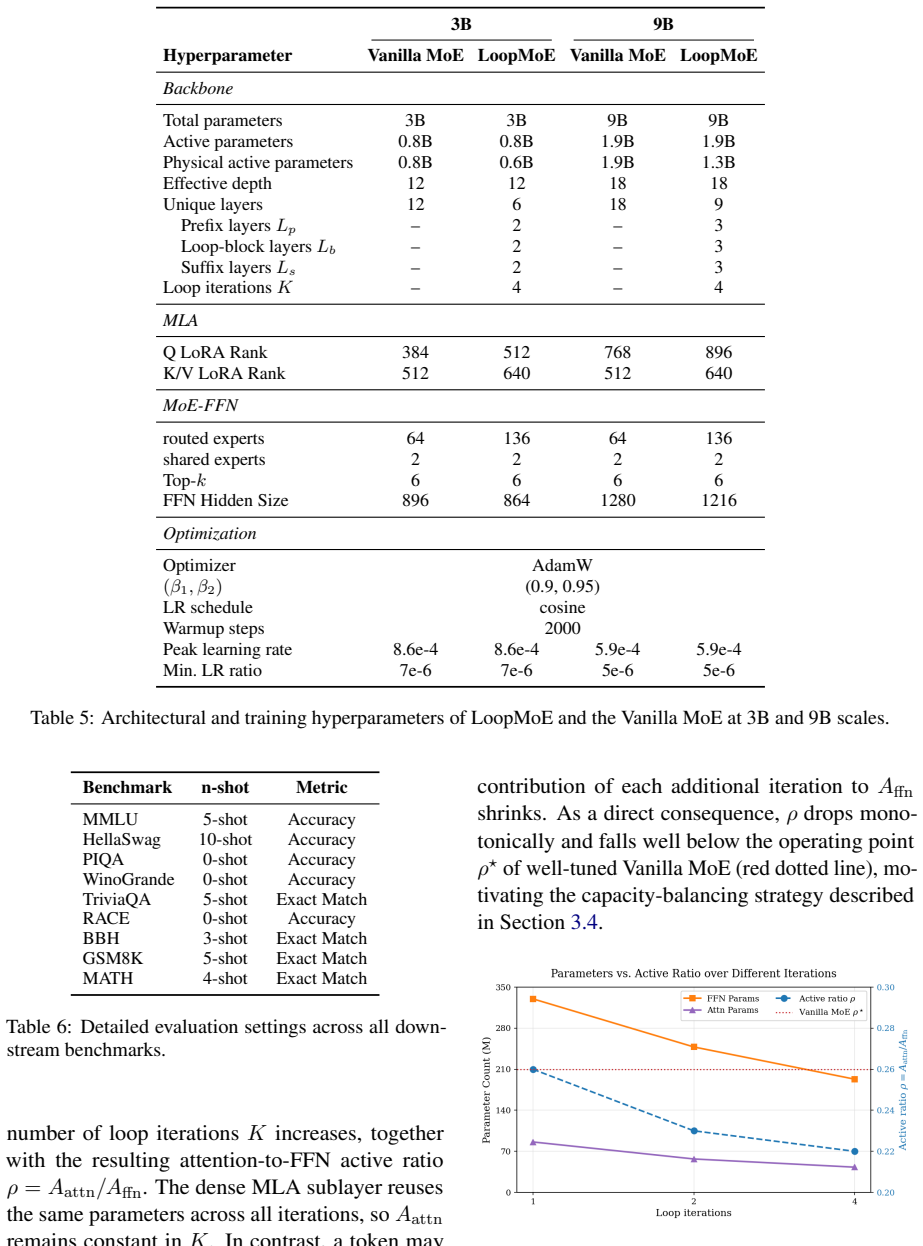
LoopMoE integrates sparse routing with iterative weight-shared computation through IterAdaLN, which supplies a modulation signal conditioned on both iteration index and per-token hidden state, plus a capacity-balancing strategy that restores the attention-to-FFN active parameter ratio of non-looped references. These two elements together permit the first strictly controlled head-to-head test of a looped MoE against a vanilla MoE under identical total parameters, per-token FLOPs, and active sublayer ratios. The looped version records higher scores on eight of nine downstream tasks at the 3B scale, with an average lift above one point, and retains the advantage at the 9B scale.
What carries the argument
IterAdaLN, a modulation signal jointly conditioned on iteration index and per-token hidden state, together with the capacity-balancing strategy that restores the attention-to-FFN active parameter ratio.
If this is right
- The performance edge appears at both 3B and 9B scales under identical budgets.
- The design unifies sparsity and recurrence without raising total parameters or per-token compute.
- Iterative depth can be added to sparse experts while preserving the same active sublayer ratios.
- Controlled head-to-head tests of looped versus non-looped sparse models become feasible for the first time.
Where Pith is reading between the lines
- The same modulation and balancing ideas could be tested on other sparse architectures such as switch transformers or product-of-experts variants.
- If the gain continues at still larger scales, the approach would offer an orthogonal axis for increasing effective depth without proportional compute growth.
- One could measure whether the iteration benefit concentrates on particular task types such as long-context reasoning or multi-step arithmetic.
- Removing IterAdaLN alone while keeping balancing would isolate how much of the reported lift comes from symmetry breaking versus the loop itself.
Load-bearing premise
The capacity-balancing strategy recovers the attention-to-FFN active parameter ratio of well-tuned non-looped models so that comparisons remain fair on active parameters and ratios.
What would settle it
A measurement that the active parameter counts or per-token FLOPs actually differ between LoopMoE and the vanilla baseline after balancing would falsify the claim of a controlled comparison.
Figures
read the original abstract
Mixture-of-Experts (MoE) and looped architectures scale models along two orthogonal axes, namely parameter capacity and effective depth. However, mainstream looped architectures rely on dense backbones that couple parameter count with per-token FLOPs, which makes it impossible to isolate the effect of iterative computation under matched budgets. To this end, we present LoopMoE, a looped MoE language model that integrates sparse routing with iterative weight-shared computation through two designs. The first is IterAdaLN, which resolves weight-sharing symmetry via a modulation signal jointly conditioned on the iteration index and the per-token hidden state. The second is a capacity-balancing strategy that recovers the attention-to-FFN active parameter ratio of well-tuned non-looped references. Together, these designs enable the first strictly controlled, head-to-head evaluation of a looped MoE against a Vanilla MoE under identical total parameters, per-token FLOPs, and active sublayer ratios. At the 3B scale, LoopMoE outperforms the Vanilla MoE on 8 of 9 downstream benchmarks with an average improvement exceeding 1 point. At the 9B scale, LoopMoE continues to outperform the matched Vanilla MoE, indicating that the architectural gain persists at larger scale. Our work establishes a controlled synthesis of sparsity and recurrence, and suggests a promising direction for looped language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoopMoE, a looped MoE architecture for language modeling that combines iterative weight-shared computation with sparse expert routing. It proposes IterAdaLN to break weight-sharing symmetry via iteration- and token-conditioned modulation, plus a capacity-balancing strategy to recover the attention-to-FFN active-parameter ratio of non-looped baselines. This is claimed to enable the first strictly controlled head-to-head comparison under matched total parameters, per-token FLOPs, and active sublayer ratios. Empirical results show LoopMoE outperforming a matched Vanilla MoE on 8/9 downstream tasks at 3B scale (average gain >1 point) with gains persisting at 9B scale.
Significance. If the capacity-balancing strategy indeed produces precisely matched active ratios and the evaluation is fully controlled, the result would demonstrate that sparsity and recurrence can be combined without trading off per-token compute, providing a new axis for scaling language models. The work ships concrete architectural components (IterAdaLN) and reports scale-consistent gains, which would be a useful empirical contribution if the controls hold.
major comments (2)
- [Methods (capacity-balancing strategy description)] The headline claim of a 'strictly controlled' comparison (abstract) rests on the capacity-balancing strategy recovering the exact attention-to-FFN active parameter ratio of well-tuned non-looped references. The manuscript provides no explicit verification—such as measured active-parameter counts, routing statistics, or a table comparing pre- and post-iteration ratios—that this recovery holds after weight-sharing alters token allocation and expert utilization.
- [Experiments] §5 (or equivalent experiments section): the 3B and 9B results are presented as evidence for architectural gain under identical total parameters, per-token FLOPs, and active sublayer ratios, yet no ablation or supplementary table confirms that the balancing rule was not tuned post-hoc or that the Vanilla MoE baseline received identical hyperparameter search effort.
minor comments (2)
- [Architecture] The definition and conditioning of IterAdaLN would benefit from an explicit equation showing how the modulation signal is computed from iteration index and hidden state.
- [Experiments] Dataset details, training hyperparameters, and exact benchmark list are referenced only at high level; a table or appendix entry would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns regarding verification of the capacity-balancing strategy and experimental controls. We commit to revisions that add explicit measurements and ablations while defending the controls as implemented.
read point-by-point responses
-
Referee: [Methods (capacity-balancing strategy description)] The headline claim of a 'strictly controlled' comparison (abstract) rests on the capacity-balancing strategy recovering the exact attention-to-FFN active parameter ratio of well-tuned non-looped references. The manuscript provides no explicit verification—such as measured active-parameter counts, routing statistics, or a table comparing pre- and post-iteration ratios—that this recovery holds after weight-sharing alters token allocation and expert utilization.
Authors: We agree that an explicit post-training verification table would strengthen the claim of matched active ratios. Section 4.2 describes the capacity-balancing rule, which sets the expert capacity factor per iteration to restore the attention-to-FFN active-parameter ratio observed in the Vanilla MoE baseline. While the rule itself is deterministic and pre-computed from the non-looped reference, the manuscript does not report measured utilization after training. In the revision we will add an appendix table with measured active-parameter counts, average routing statistics, and pre-/post-balancing ratio comparisons for both 3B and 9B models, confirming the ratios match within measurement noise. revision: yes
-
Referee: [Experiments] §5 (or equivalent experiments section): the 3B and 9B results are presented as evidence for architectural gain under identical total parameters, per-token FLOPs, and active sublayer ratios, yet no ablation or supplementary table confirms that the balancing rule was not tuned post-hoc or that the Vanilla MoE baseline received identical hyperparameter search effort.
Authors: The balancing rule is fixed before any LoopMoE training: it is computed once from the active FFN ratio of the already-tuned Vanilla MoE baseline and applied unchanged. Appendix B documents that both models used the identical hyperparameter search protocol (learning-rate sweep, batch size, training tokens, and optimizer settings). We therefore did not tune the rule post-hoc on LoopMoE results. To address the request for further evidence, the revision will include a sensitivity ablation varying the balancing factor around the nominal value and reporting downstream performance. The search effort was matched by design; no additional search budget was allocated to either model. revision: partial
Circularity Check
No significant circularity; results are empirical comparisons
full rationale
The paper proposes LoopMoE via IterAdaLN and a capacity-balancing strategy, then reports benchmark outperformance versus Vanilla MoE at 3B and 9B scales. These are direct experimental measurements under asserted matched budgets, not a derivation chain that reduces by construction to fitted parameters, self-defined quantities, or load-bearing self-citations. The capacity-balancing is a design choice to control active ratios, but the performance deltas are independently observed and not forced by the matching procedure itself. No equations or uniqueness theorems are invoked that loop back to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard downstream benchmarks are valid proxies for general language modeling capability.
invented entities (1)
-
IterAdaLN
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models , author=. arXiv preprint arXiv:2508.06471 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Universal transformers , author=. arXiv preprint arXiv:1807.03819 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Albert: A lite bert for self-supervised learning of language representations , author=. arXiv preprint arXiv:1909.11942 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[6]
Advances in Neural Information Processing Systems , volume=
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation , author=. Advances in Neural Information Processing Systems , volume=
-
[7]
International Conference on Learning Representations , volume=
Relaxed recursive transformers: Effective parameter sharing with layer-wise lora , author=. International Conference on Learning Representations , volume=
-
[8]
International Conference on Learning Representations , volume=
CoTFormer: A chain of thought driven architecture with budget-adaptive computation cost at inference , author=. International Conference on Learning Representations , volume=
-
[9]
Hyperloop transformers , author=. arXiv preprint arXiv:2604.21254 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
International Conference on Learning Representations (ICLR) , year =
LoopFormer: Elastic-Depth Looped Transformers for Latent Reasoning via Shortcut Modulation , author =. International Conference on Learning Representations (ICLR) , year =
-
[11]
Scaling Latent Reasoning via Looped Language Models
Scaling latent reasoning via looped language models , author=. arXiv preprint arXiv:2510.25741 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
IEEE Transactions on Knowledge and Data Engineering , year=
A survey on mixture of experts in large language models , author=. IEEE Transactions on Knowledge and Data Engineering , year=
-
[13]
Advances in neural information processing systems , volume=
Root mean square layer normalization , author=. Advances in neural information processing systems , volume=
-
[14]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Scalable Diffusion Models with Transformers , author=. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) , pages=. 2023 , organization=
2023
-
[15]
arXiv preprint arXiv:2602.08019 , year=
The Rise of Sparse Mixture-of-Experts: A Survey from Algorithmic Foundations to Decentralized Architectures and Vertical Domain Applications , author=. arXiv preprint arXiv:2602.08019 , year=
-
[16]
GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
Gshard: Scaling giant models with conditional computation and automatic sharding , author=. arXiv preprint arXiv:2006.16668 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[17]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[18]
Advances in neural information processing systems , volume=
Block-recurrent transformers , author=. Advances in neural information processing systems , volume=
-
[19]
Advances in Neural Information Processing Systems , volume=
Scaling up test-time compute with latent reasoning: A recurrent depth approach , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
arXiv preprint arXiv:2511.07384 , year=
Teaching Pretrained Language Models to Think Deeper with Retrofitted Recurrence , author=. arXiv preprint arXiv:2511.07384 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
Moeut: Mixture-of-experts universal transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[23]
Proceedings of the IEEE international conference on computer vision , pages=
Arbitrary style transfer in real-time with adaptive instance normalization , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[24]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Exploring multimodal diffusion transformers for enhanced prompt-based image editing , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[25]
Olmo 3 , author=. arXiv preprint arXiv:2512.13961 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
International Conference on Learning Representations , year=
SGDR: Stochastic Gradient Descent with Warm Restarts , author=. International Conference on Learning Representations , year=
-
[28]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[29]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
Hellaswag: Can a machine really finish your sentence? , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[30]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[31]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[32]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
Proceedings of the 2017 conference on empirical methods in natural language processing , pages=
Race: Large-scale reading comprehension dataset from examinations , author=. Proceedings of the 2017 conference on empirical methods in natural language processing , pages=
2017
-
[34]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Big-bench extra hard , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[35]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
NeurIPS , year=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. NeurIPS , year=
-
[37]
doi:10.5281/zenodo.12608602 , url =
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
International Conference on Machine Learning , pages=
Pythia: A suite for analyzing large language models across training and scaling , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[40]
2 OLMo 2 Furious , author=. arXiv preprint arXiv:2501.00656 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
International Conference on Learning Representations , volume=
Olmoe: Open mixture-of-experts language models , author=. International Conference on Learning Representations , volume=
-
[42]
Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
Griffin: Mixing gated linear recurrences with local attention for efficient language models , author=. arXiv preprint arXiv:2402.19427 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
arXiv preprint arXiv:2408.13359 , year=
Power scheduler: A batch size and token number agnostic learning rate scheduler , author=. arXiv preprint arXiv:2408.13359 , year=
-
[44]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
Transformer feed-forward layers are key-value memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[45]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Disentangling memory and reasoning ability in large language models , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[46]
A Mechanistic Analysis of Looped Reasoning Language Models
A mechanistic analysis of looped reasoning language models , author=. arXiv preprint arXiv:2604.11791 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[48]
Training Large Language Models to Reason in a Continuous Latent Space
Training large language models to reason in a continuous latent space , author=. arXiv preprint arXiv:2412.06769 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
International Conference on Learning Representations , volume=
Reasoning with latent thoughts: On the power of looped transformers , author=. International Conference on Learning Representations , volume=
-
[50]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Colt5: Faster long-range transformers with conditional computation , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[51]
Dr.LLM: Dynamic Layer Routing in LLMs
Dr.LLM: Dynamic Layer Routing in LLMs , author=. arXiv preprint arXiv:2510.12773 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
arXiv preprint arXiv:2402.01739 , year=
OpenMoE: An Early Effort on Open Mixture-of-Experts Language Models , author=. arXiv preprint arXiv:2402.01739 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.