ANN Search: Recall What Matters
Pith reviewed 2026-06-28 04:26 UTC · model grok-4.3
The pith
Replacing Recall@k with 1/Ratio@k lets ANN search reach quality thresholds at lower cost while tracking downstream utility more closely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
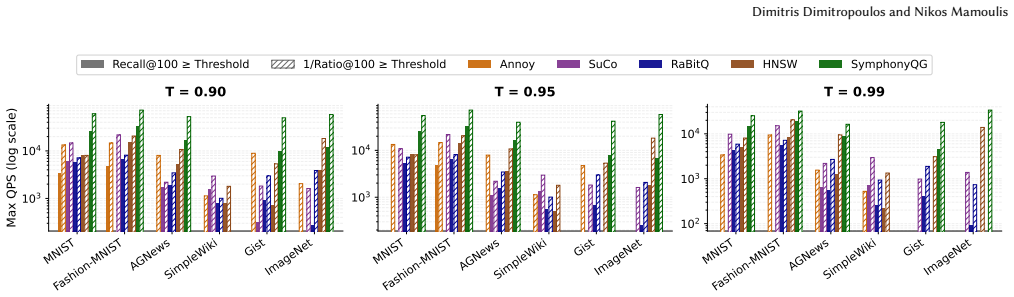
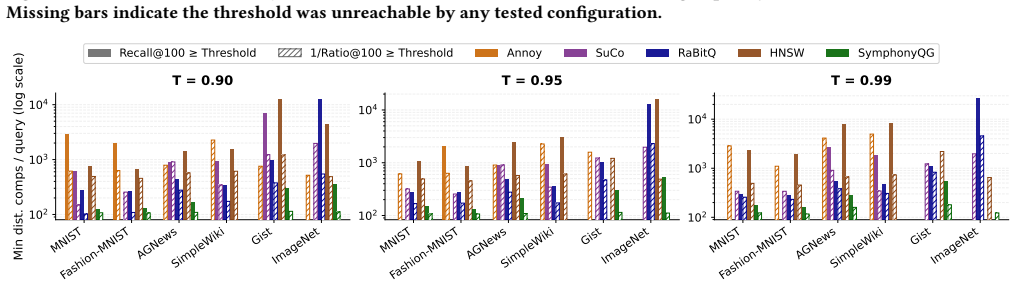
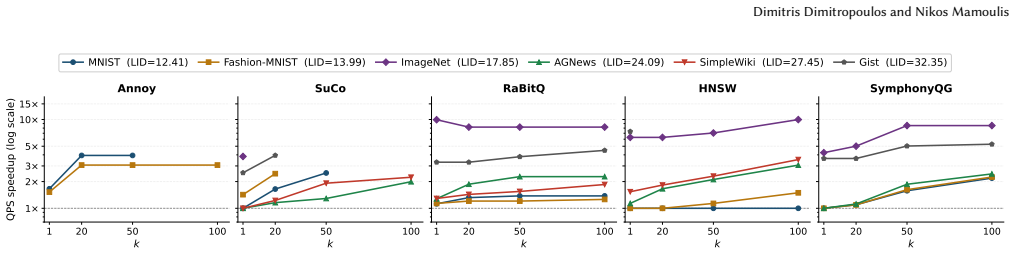
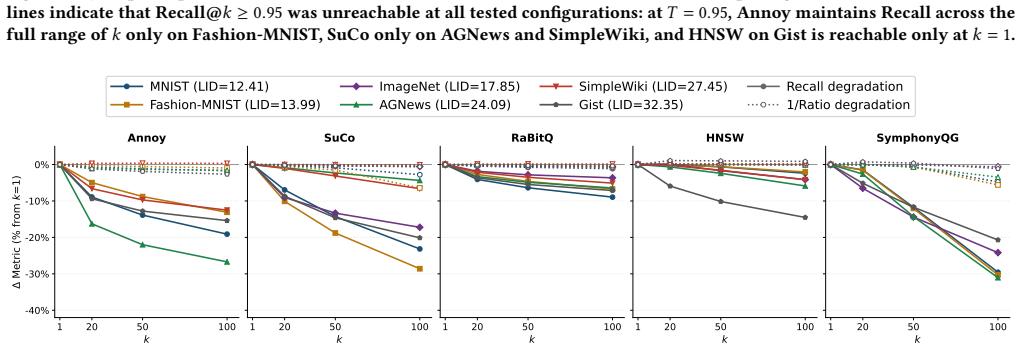
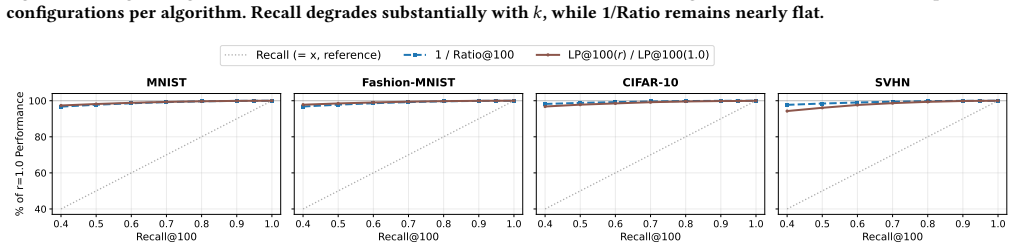
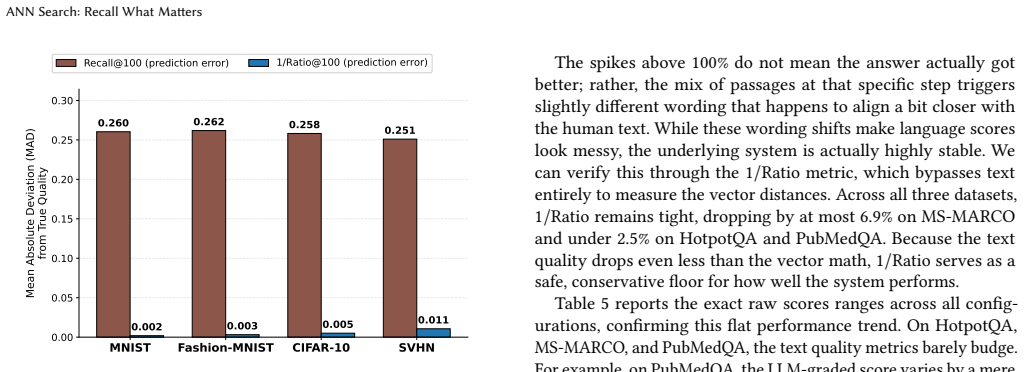
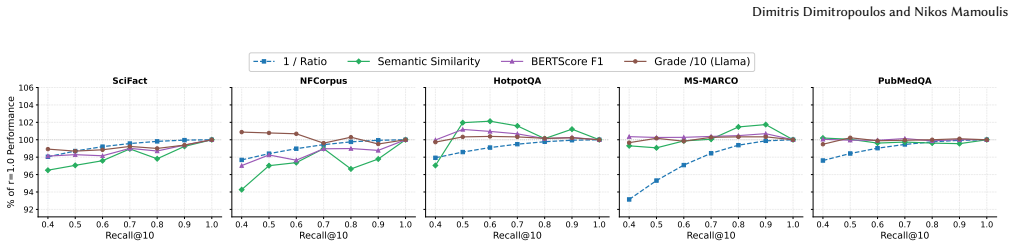
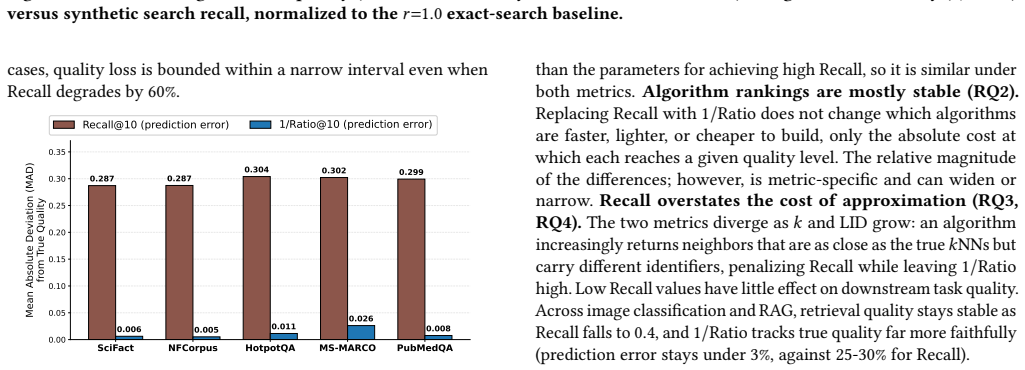
The paper establishes that 1/Ratio@k is a more accurate proxy for ANN quality than Recall@k because it measures distance approximation directly rather than set overlap. Across diverse datasets, optimizing for 1/Ratio@k reaches usable quality thresholds at lower computational cost, and downstream task performance remains stable even as Recall@k declines, with 1/Ratio@k tracking true utility more reliably.
What carries the argument
The inverse approximation ratio 1/Ratio@k, the reciprocal of the mean ratio of distances to the k retrieved neighbors versus the k true neighbors.
If this is right
- ANN algorithms can be tuned to lower computational budgets while still meeting operational quality thresholds.
- Downstream performance in classification and retrieval-augmented generation remains stable despite reduced exact neighbor overlap.
- 1/Ratio@k correlates more closely with task-specific quality signals than Recall@k across efficiency and utility axes.
- Standard ANN benchmarks can adopt 1/Ratio@k to avoid overstating the cost of approximation.
Where Pith is reading between the lines
- Production ANN deployments could reduce compute by monitoring 1/Ratio@k directly instead of targeting high Recall@k.
- Index designs might shift toward tolerating set mismatches when distances remain accurate.
- The metric could extend to other approximate retrieval settings where fidelity of results matters more than exact matches.
- Evaluation pipelines could become more parameter-free by relying on 1/Ratio@k computed from existing benchmark data.
Load-bearing premise
The approximation ratio between retrieved and true neighbor distances predicts downstream task quality more reliably than exact neighbor overlap across the tested datasets and tasks.
What would settle it
A dataset or downstream task in which 1/Ratio@k stays high yet classification accuracy, semantic similarity, or LLM-graded quality drops sharply while Recall@k is low.
Figures


read the original abstract
Approximate nearest neighbor (ANN) search has become a core primitive in information retrieval and modern machine learning tasks, from classification to retrieval-augmented generation. The community evaluates and tunes ANN algorithms primarily on their throughput at a given Recall@k, the fraction of true exact neighbors retrieved. We argue that what really matters in ANN search is the quality of the retrieved results and not their overlap with the true kNN set. We show that using Recall@k to assess retrieval quality forces unnecessary computational overhead and investigate replacing it by 1/Ratio@k, the inverse approximation ratio. 1/Ratio@k evaluates the differences between the distances of the retrieved and true neighbors. It is judge-free, hyperparameter-free, and computable from standard ANN benchmark inputs alone. We benchmark state-of-the-art ANN algorithms across diverse datasets spanning a wide range of intrinsic dimensionalities, evaluating the two metrics comprehensively across efficiency, downstream classification, and retrieval-augmented generation. On the efficiency axis, optimizing for 1/Ratio@k reaches operational quality thresholds at a substantially lower computational cost than Recall@k. In downstream tasks, performance indicators (label precision, semantic similarity, BERTScore, and LLM-graded quality) remain highly stable even when Recall@k drops significantly. The inverse approximation ratio, on the other hand, closely mirrors this stability, tracking true utility much better than Recall@k. Ultimately, while Recall@k overstates the true cost of approximation, 1/Ratio@k offers a more accurate, deployable proxy for actual ANN quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that Recall@k, the standard metric for ANN search quality, overstates the computational cost of approximation by focusing on exact neighbor overlap rather than result quality. It proposes replacing it with 1/Ratio@k (the inverse approximation ratio based on distances to true vs. retrieved neighbors), which is judge-free, hyperparameter-free, and computable from standard ANN benchmark inputs. Through benchmarks on diverse datasets spanning intrinsic dimensionalities, the authors show that optimizing for 1/Ratio@k achieves operational quality at lower cost than Recall@k, while downstream task metrics (classification precision, semantic similarity, BERTScore, LLM judgments) remain stable even as Recall@k drops, with 1/Ratio@k tracking utility more closely.
Significance. If the empirical correlations hold, this work could shift ANN evaluation practices away from overlap-based metrics toward distance-ratio proxies that better reflect real utility in IR and ML pipelines, enabling more efficient algorithm tuning without sacrificing downstream performance. Strengths include the metric's direct computability from existing benchmark data, comprehensive evaluation across efficiency and multiple downstream tasks, and absence of post-hoc parameter tuning or invented entities in the core argument.
major comments (2)
- [§4] §4 (efficiency benchmarks): the claim that 1/Ratio@k reaches 'operational quality thresholds' at substantially lower cost requires explicit definition of those thresholds (e.g., specific downstream metric cutoffs) and confirmation that they were fixed a priori rather than chosen to favor the new metric; without this, the cost comparison risks being circular with the stability results.
- [Table 2] Table 2 / downstream task results: the reported stability of label precision and BERTScore when Recall@k varies but 1/Ratio@k is controlled needs per-dataset statistical tests (e.g., correlation coefficients with p-values) to establish that the tracking advantage is not driven by a subset of low-dimensionality datasets.
minor comments (3)
- [Abstract / §2] The abstract states the metric is 'hyperparameter-free,' but the definition of Ratio@k should include an explicit equation (likely in §2) showing it uses only the distances already present in standard ANN inputs with no tunable parameters.
- [Figures] Figure captions for efficiency curves should clarify the exact k values and dataset intrinsic dimensionalities used, to allow direct reproduction from the reported numbers.
- [§1] A brief related-work paragraph contrasting 1/Ratio@k with existing approximation-ratio measures in ANN literature (e.g., those in the original ANN benchmarks) would strengthen the novelty claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for minor revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (efficiency benchmarks): the claim that 1/Ratio@k reaches 'operational quality thresholds' at substantially lower cost requires explicit definition of those thresholds (e.g., specific downstream metric cutoffs) and confirmation that they were fixed a priori rather than chosen to favor the new metric; without this, the cost comparison risks being circular with the stability results.
Authors: We agree that the operational quality thresholds must be defined explicitly. In the revised manuscript we will add a precise definition in §4: operational quality is reached when a downstream metric attains at least 90 % of its exact-search value, with the 90 % cutoff selected from prior IR literature on acceptable approximation loss before any efficiency curves were examined. We will also state that the cost comparisons were performed after fixing this cutoff, thereby removing any circular dependence on the stability plots. revision: yes
-
Referee: [Table 2] Table 2 / downstream task results: the reported stability of label precision and BERTScore when Recall@k varies but 1/Ratio@k is controlled needs per-dataset statistical tests (e.g., correlation coefficients with p-values) to establish that the tracking advantage is not driven by a subset of low-dimensionality datasets.
Authors: We accept the request for statistical support. The revision will augment the Table 2 analysis with per-dataset Pearson correlation coefficients and p-values between each candidate metric (Recall@k and 1/Ratio@k) and every downstream indicator. These tests will be reported for all datasets, confirming that the tracking advantage of 1/Ratio@k is not confined to low-dimensionality subsets. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core argument defines 1/Ratio@k explicitly from distances already present in standard ANN benchmark inputs and validates its superiority over Recall@k via direct empirical comparisons on efficiency and downstream task stability (classification precision, BERTScore, LLM judgments) across multiple datasets. No load-bearing step reduces by construction to a self-definition, a fitted parameter renamed as a prediction, or a self-citation chain; the metric is computable without hyperparameters and the claims rest on external task metrics independent of the ratio definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Laurent Amsaleg and Hervé Jégou. 2026. Datasets for approximate nearest neighbor search. http://corpus-texmex.irisa.fr/. (Accessed: February, 2026)
2026
-
[2]
Sunil Arya, David M. Mount, Nathan S. Netanyahu, Ruth Silverman, and Angela Y. Wu. 1998. An optimal algorithm for approximate nearest neighbor searching fixed dimensions.J. ACM45, 6 (Nov. 1998), 891–923. doi:10.1145/293347.293348
-
[3]
Martin Aumüller, Erik Bernhardsson, and Alexander John Faithfull. 2020. ANN- Benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. Inf. Syst.87 (2020). doi:10.1016/J.IS.2019.02.006
-
[4]
Martin Aumüller and Matteo Ceccarello. 2019. The Role of Local Intrinsic Dimensionality in Benchmarking Nearest Neighbor Search. InSimilarity Search and Applications - 12th International Conference, SISAP 2019, Newark, NJ, USA, October 2-4, 2019, Proceedings (Lecture Notes in Computer Science), Giuseppe Amato, Claudio Gennaro, Vincent Oria, and Milos Rado...
-
[5]
Artem Babenko and Victor S. Lempitsky. 2012. The inverted multi-index. In2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, June 16-21, 2012. IEEE Computer Society, 3069–3076. doi:10.1109/CVPR.2012. 6248038
-
[6]
Jon Louis Bentley. 1975. Multidimensional Binary Search Trees Used for Associa- tive Searching.Commun. ACM18, 9 (1975), 509–517. doi:10.1145/361002.361007
-
[7]
Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft
Kevin S. Beyer, Jonathan Goldstein, Raghu Ramakrishnan, and Uri Shaft. 1999. When Is ”Nearest Neighbor” Meaningful?. InDatabase Theory - ICDT ’99, 7th In- ternational Conference, Jerusalem, Israel, January 10-12, 1999, Proceedings (Lecture Notes in Computer Science), Catriel Beeri and Peter Buneman (Eds.). Springer, 217–235. doi:10.1007/3-540-49257-7_15
-
[8]
Manos Chatzakis, Yannis Papakonstantinou, and Themis Palpanas. 2025. DARTH: Declarative Recall Through Early Termination for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 4 (2025), 242:1–242:26. doi:10.1145/3749160
- [9]
-
[10]
Tingyang Chen, Cong Fu, Jiahua Wu, Haotian Wu, Hua Fan, Xiangyu Ke, Yunjun Gao, Yabo Ni, and Anxiang Zeng. 2025. Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views.CoRR abs/2512.12980 (2025). arXiv:2512.12980 doi:10.48550/ARXIV.2512.12980
-
[11]
Sanjoy Dasgupta and Yoav Freund. 2008. Random projection trees and low dimensional manifolds. InProceedings of the 40th Annual ACM Symposium on Theory of Computing, Victoria, British Columbia, Canada, May 17-20, 2008, Cynthia Dwork (Ed.). ACM, 537–546. doi:10.1145/1374376.1374452
-
[12]
Mayur Datar, Nicole Immorlica, Piotr Indyk, and Vahab S. Mirrokni. 2004. Locality-sensitive hashing scheme based on p-stable distributions. InProceedings of the 20th ACM Symposium on Computational Geometry, Brooklyn, New York, USA, June 8-11, 2004, Jack Snoeyink and Jean-Daniel Boissonnat (Eds.). ACM, 253–262. doi:10.1145/997817.997857
-
[13]
Laxman Dhulipala, Majid Hadian, Rajesh Jayaram, Jason Lee, and Vahab Mirrokni
-
[14]
MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings
MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings.CoRR abs/2405.19504 (2024). arXiv:2405.19504 doi:10.48550/ARXIV.2405.19504
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.19504 2024
-
[16]
Elena Facco, Maria d’Errico, Alex Rodriguez, and Alessandro Laio. 2018. Estimat- ing the intrinsic dimension of datasets by a minimal neighborhood information. CoRRabs/1803.06992 (2018). arXiv:1803.06992 http://arxiv.org/abs/1803.06992
Pith/arXiv arXiv 2018
-
[17]
Cong Fu, Changxu Wang, and Deng Cai. 2022. High Dimensional Similarity Search With Satellite System Graph: Efficiency, Scalability, and Unindexed Query Compatibility.IEEE Trans. Pattern Anal. Mach. Intell.44, 8 (2022), 4139–4150. doi:10.1109/TPAMI.2021.3067706
-
[18]
Cong Fu, Chao Xiang, Changxu Wang, and Deng Cai. 2019. Fast Approximate Nearest Neighbor Search With The Navigating Spreading-out Graph.Proc. VLDB Endow.12, 5 (2019), 461–474. doi:10.14778/3303753.3303754
-
[19]
Jianyang Gao, Yutong Gou, Yuexuan Xu, Yongyi Yang, Cheng Long, and Ray- mond Chi-Wing Wong. 2025. Practical and Asymptotically Optimal Quantization of High-Dimensional Vectors in Euclidean Space for Approximate Nearest Neigh- bor Search.Proc. ACM Manag. Data3, 3 (2025), 202:1–202:26. doi:10.1145/3725413
-
[20]
Jianyang Gao and Cheng Long. 2023. High-Dimensional Approximate Nearest Neighbor Search: with Reliable and Efficient Distance Comparison Operations. Proc. ACM Manag. Data1, 2 (2023), 137:1–137:27. doi:10.1145/3589282
-
[21]
Jianyang Gao and Cheng Long. 2024. RaBitQ: Quantizing High-Dimensional Vectors with a Theoretical Error Bound for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data2, 3 (2024), 167. doi:10.1145/3654970
-
[22]
Tiezheng Ge, Kaiming He, Qifa Ke, and Jian Sun. 2014. Optimized Product Quantization.IEEE Trans. Pattern Anal. Mach. Intell.36, 4 (2014), 744–755. doi:10. 1109/TPAMI.2013.240
2014
-
[23]
Yutong Gou, Jianyang Gao, Yuexuan Xu, and Cheng Long. 2025. SymphonyQG: Towards Symphonious Integration of Quantization and Graph for Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1 (2025), 80:1–80:26. doi:10. 1145/3709730
2025
-
[24]
Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. InProceedings of the 37th International Conference on Machine Learning, ICML 2020, 13-18 July 2020, Virtual Event (Proceedings of Machine Learning Research). PMLR, 3887–3896. http://pr...
2020
-
[25]
Piotr Indyk and Rajeev Motwani. 1998. Approximate Nearest Neighbors: Towards Removing the Curse of Dimensionality. InProceedings of the Thirtieth Annual ACM Symposium on the Theory of Computing, Dallas, Texas, USA, May 23-26, 1998, Jeffrey Scott Vitter (Ed.). ACM, 604–613. doi:10.1145/276698.276876
-
[26]
Elias Jääsaari, Ville Hyvönen, Matteo Ceccarello, Teemu Roos, and Martin Aumüller. 2025. VIBE: Vector Index Benchmark for Embeddings.CoRR abs/2505.17810 (2025). arXiv:2505.17810 doi:10.48550/ARXIV.2505.17810
-
[27]
Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Processing Systems, H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett (Eds.), Vol. 32. Curran Asso...
2019
-
[28]
Hervé Jégou, Matthijs Douze, and Cordelia Schmid. 2011. Product Quantization for Nearest Neighbor Search.IEEE Trans. Pattern Anal. Mach. Intell.33, 1 (2011), 117–128. doi:10.1109/TPAMI.2010.57
-
[29]
Cohen, and Xinghua Lu
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William W. Cohen, and Xinghua Lu
-
[30]
PubMedQA: A Dataset for Biomedical Research Question Answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Process- ing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan (Eds.). Associa...
-
[31]
Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2021. Billion-Scale Similarity Search with GPUs.IEEE Trans. Big Data7, 3 (2021), 535–547. doi:10.1109/ TBDATA.2019.2921572
arXiv 2021
-
[32]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020, Bonnie Webber, Trevor Cohn, Yulan He, and Ya...
-
[33]
Alex Krizhevsky. 2009. Learning Multiple Layers of Features from Tiny Images. https://api.semanticscholar.org/CorpusID:18268744
2009
-
[34]
Leonardo Kuffó, Elena Krippner, and Peter Boncz. 2025. PDX: A Data Layout for Vector Similarity Search.Proc. ACM Manag. Data3, 3 (2025), 196:1–196:26. doi:10.1145/3725333
-
[35]
Leonardo Kuffo, Ioanna Tsakalidou, Roberta Viti, Albert Angel, Jiří Iša, and Rastislav Lenhardt. 2026. Semantic Recall for Vector Search. doi:10.48550/arXiv. 2604.20417
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2026
-
[36]
Yann LeCun, Corinna Cortes, and CJ Burges. 2010. MNIST handwritten digit database.ATT Labs [Online]. A vailable: http://yann.lecun.com/exdb/mnist2 (2010)
2010
-
[37]
Leonardo Kuffo, Elena Krippner, Peter Boncz. 2026. PDX: Public Data. https:// drive.google.com/drive/u/1/folders/1f76UCrU52N2wToGMFg9ir1MY8ZocrN34. (Accessed: February, 2026)
2026
-
[38]
Alexandria Leto, Cecilia Aguerrebere, Ishwar Singh Bhati, Ted Willke, Mariano Tepper, and Vy Ai Vo. 2024. Toward Optimal Search and Retrieval for RAG.CoRR abs/2411.07396 (2024). arXiv:2411.07396 doi:10.48550/ARXIV.2411.07396
-
[39]
Mocheng Li, Xiao Yan, Baotong Lu, Yue Zhang, James Cheng, and Chenhao Ma
-
[40]
ACM Manag
Attribute Filtering in Approximate Nearest Neighbor Search: An In-depth Experimental Study.Proc. ACM Manag. Data3, 6 (2025), 1–26. doi:10.1145/ 3769763
2025
-
[41]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2020. Approximate Nearest Neighbor Search on High Dimensional Data - Experiments, Analyses, and Improvement.IEEE Trans. Knowl. Data Eng. 32, 8 (2020), 1475–1488. doi:10.1109/TKDE.2019.2909204
-
[42]
Xiangci Li and Jessica Ouyang. 2025. How Does Knowledge Selection Help Retrieval Augmented Generation?. InFindings of the Association for Compu- tational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, 4104–4121. ht...
2025
-
[43]
Jiahao Lou, Quan Yu, Shufeng Gong, Song Yu, Yanfeng Zhang, and Ge Yu. 2025. DGAI: Decoupled On-Disk Graph-Based ANN Index for Efficient Updates and Queries.CoRRabs/2510.25401 (2025). arXiv:2510.25401 doi:10.48550/ARXIV.2510. 25401
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510 2025
-
[44]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[45]
Approximate nearest neighbor algorithm based on navigable small world Dimitris Dimitropoulos and Nikos Mamoulis graphs.Inf. Syst.45 (2014), 61–68. doi:10.1016/J.IS.2013.10.006
-
[46]
Yury A. Malkov and Dmitry A. Yashunin. 2020. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs.IEEE Trans. Pattern Anal. Mach. Intell.42, 4 (2020), 824–836. doi:10.1109/TPAMI.2018. 2889473
-
[47]
Yuval Netzer, Tao Wang, Adam Coates, Alessandro Bissacco, Bo Wu, and An- drew Y Ng. 2011. Reading digits in natural images with unsupervised feature learning. (2011)
2011
-
[48]
Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A Human Generated MAchine Reading COmprehension Dataset. InProceedings of the Workshop on Cognitive Computation: Integrating neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Information Processing Systems...
2016
-
[49]
John Paparrizos, Ikraduya Edian, Chunwei Liu, Aaron J. Elmore, and Michael J. Franklin. 2022. Fast Adaptive Similarity Search through Variance-Aware Quantization. In38th IEEE International Conference on Data Engineering, ICDE 2022, Kuala Lumpur, Malaysia, May 9-12, 2022. IEEE, 2969–2983. doi:10.1109/ ICDE53745.2022.00268
arXiv 2022
-
[50]
Spotify AB. 2025. spotify/annoy: Approximate Nearest Neighbors in C++/Python optimized for memory usage and loading/saving to disk. https://github.com/ spotify/annoy. commit on main branch accessed on 2025-11-29
2025
-
[51]
Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, and Iryna Gurevych. 2021. BEIR: A Heterogeneous Benchmark for Zero-shot Evaluation of Information Retrieval Models. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, Joaquin Vanschoren...
2021
-
[52]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, Kun Yu, Yuxing Yuan, Yinghao Zou, Jiquan Long, Yudong Cai, Zhenxiang Li, Zhifeng Zhang, Yihua Mo, Jun Gu, Ruiyi Jiang, Yi Wei, and Charles Xie. 2021. Milvus: A Purpose-Built Vector Data Management System. InSIGMOD ’21: Internatio...
-
[53]
Jingdong Wang, Ting Zhang, Jingkuan Song, Nicu Sebe, and Heng Tao Shen
-
[54]
A Survey on Learning to Hash.IEEE Trans. Pattern Anal. Mach. Intell.40, 4 (2018), 769–790. doi:10.1109/TPAMI.2017.2699960
-
[55]
Mengzhao Wang, Haotian Wu, Xiangyu Ke, Yunjun Gao, Yifan Zhu, and Wenchao Zhou. 2025. Accelerating Graph Indexing for ANNS on Modern CPUs.Proc. ACM Manag. Data3, 3 (2025), 123:1–123:29. doi:10.1145/3725260
-
[56]
Mengzhao Wang, Xiaoliang Xu, Qiang Yue, and Yuxiang Wang. 2021. A Com- prehensive Survey and Experimental Comparison of Graph-Based Approxi- mate Nearest Neighbor Search.Proc. VLDB Endow.14, 11 (2021), 1964–1978. doi:10.14778/3476249.3476255
-
[57]
Ziqi Wang, Jingzhe Zhang, and Wei Hu. 2025. WoW: A Window-to-Window Incremental Index for Range-Filtering Approximate Nearest Neighbor Search. Proc. ACM Manag. Data3, 6 (2025), 1–27. doi:10.1145/3769843
-
[58]
Zikai Wang, Qianxi Zhang, Baotong Lu, Qi Chen, and Cheng Tan. 2025. To- wards Robustness: A Critique of Current Vector Database Assessments.CoRR abs/2507.00379 (2025). arXiv:2507.00379 doi:10.48550/ARXIV.2507.00379
-
[59]
Roger Weber, Hans-Jörg Schek, and Stephen Blott. 1998. A Quantitative Analysis and Performance Study for Similarity-Search Methods in High-Dimensional Spaces. InVLDB’98, Proceedings of 24rd International Conference on Very Large Data Bases, August 24-27, 1998, New York City, New York, USA, Ashish Gupta, Oded Shmueli, and Jennifer Widom (Eds.). Morgan Kauf...
1998
-
[60]
Jiuqi Wei, Xiaodong Lee, Zhenyu Liao, Themis Palpanas, and Botao Peng. 2025. Subspace Collision: An Efficient and Accurate Framework for High-dimensional Approximate Nearest Neighbor Search.Proc. ACM Manag. Data3, 1 (2025), 79:1–79:29. doi:10.1145/3709729
-
[61]
Jiuqi Wei, Botao Peng, Xiaodong Lee, and Themis Palpanas. 2024. DET-LSH: A Locality-Sensitive Hashing Scheme with Dynamic Encoding Tree for Approx- imate Nearest Neighbor Search.Proc. VLDB Endow.17, 9 (2024), 2241–2254. doi:10.14778/3665844.3665854
-
[62]
Han Xiao, Kashif Rasul, and Roland Vollgraf. 2017. Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms.CoRRabs/1708.07747 (2017). arXiv:1708.07747 http://arxiv.org/abs/1708.07747
Pith/arXiv arXiv 2017
-
[63]
Yahoo Japan. 2018. NGT: Neighborhood Graph and Tree for Indexing High- dimensional Data. https://github.com/yahoojapan/NGT. Accessed: 2026-05-20
2018
-
[64]
Donghui Yan, Yingjie Wang, Jin Wang, Honggang Wang, and Zhenpeng Li. 2018. K-nearest Neighbor Search by Random Projection Forests. InIEEE International Conference on Big Data (IEEE BigData 2018), Seattle, W A, USA, December 10-13, 2018, Naoki Abe, Huan Liu, Calton Pu, Xiaohua Hu, Nesreen K. Ahmed, Mu Qiao, Yang Song, Donald Kossmann, Bing Liu, Kisung Lee,...
-
[65]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InConference on Empirical Methods in Natural Language Processing (EMNLP)
2018
-
[66]
Qiang Yue, Xiaoliang Xu, Yuxiang Wang, Yikun Tao, and Xuliyuan Luo. 2024. Routing-Guided Learned Product Quantization for Graph-Based Approximate Nearest Neighbor Search. In40th IEEE International Conference on Data Engi- neering, ICDE 2024, Utrecht, The Netherlands, May 13-16, 2024. IEEE, 4870–4883. doi:10.1109/ICDE60146.2024.00370
-
[67]
Weinberger, and Yoav Artzi
Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi
-
[68]
https://api.semanticscholar.org/CorpusID:127986044
BERTScore: Evaluating Text Generation with BERT.ArXivabs/1904.09675 (2019). https://api.semanticscholar.org/CorpusID:127986044
Pith/arXiv arXiv 1904
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.