Dynamic Infilling Anchors for Format-Constrained Generation in Diffusion Large Language Models
Pith reviewed 2026-06-28 06:18 UTC · model grok-4.3
The pith
Dynamic Infilling Anchors let diffusion language models adjust generation length on the fly to meet format constraints like JSON or reasoning templates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
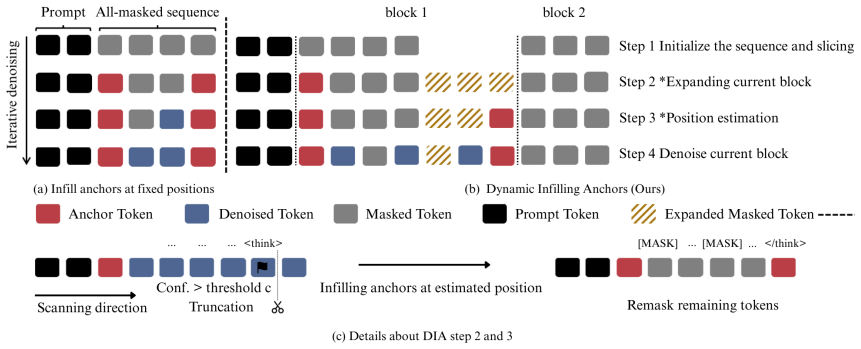
Dynamic Infilling Anchors is a training-free procedure that estimates end-anchor positions dynamically so that the generation length can be corrected before iterative infilling, thereby enforcing structural constraints while keeping semantic coherence intact in diffusion large language models.
What carries the argument
Dynamic Infilling Anchors, a mechanism that estimates end-anchor positions to set generation length before iterative infilling.
If this is right
- Format compliance rises without any model retraining.
- Answer accuracy improves on GSM8K and MATH in zero-shot use.
- Generated text avoids both premature truncation and unnecessary padding.
- The same length-adjustment step supports multiple distinct output templates.
Where Pith is reading between the lines
- The length-estimation step could be applied to other parallel-generation models that must respect output schemas.
- Combining the anchor adjustment with post-generation verification might further reduce malformed outputs.
- The bidirectional nature of diffusion models appears especially helpful when the required format depends on global context.
Load-bearing premise
A training-free dynamic estimation of end-anchor positions can reliably produce both structural correctness and semantic coherence across different format-constrained tasks without introducing new errors in length prediction.
What would settle it
A direct comparison on a new format task in which DIA outputs violate the required structure at the same rate as fixed-anchor baselines would show the claimed advantage does not hold.
Figures

read the original abstract
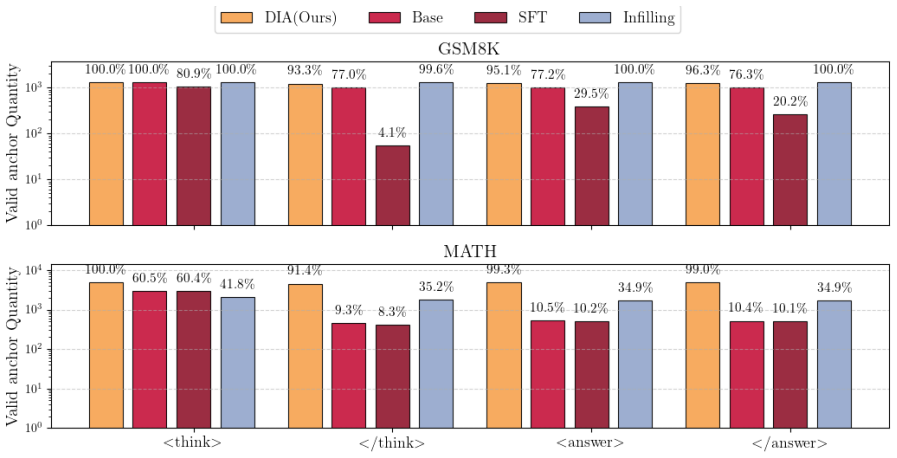
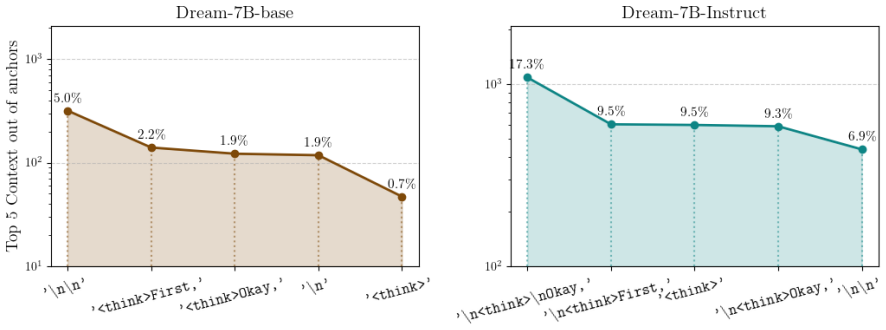
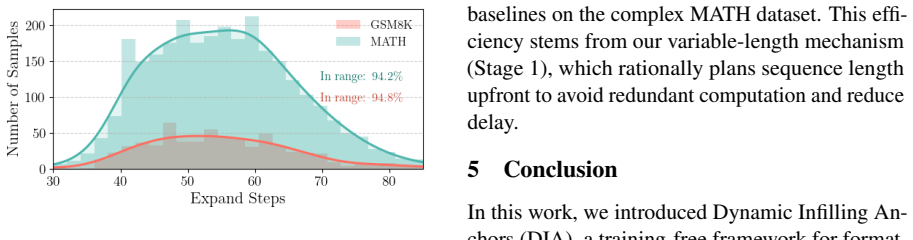
Diffusion large language models (dLLMs) offer bidirectional attention and parallel generation, enabling them to exploit global context and naturally support format-constrained tasks like parseable JSON or reasoning templates. While straightforward fixed anchors can enforce such constraints, they often impose rigid spans, leading to truncated reasoning or redundant content. To overcome this, we propose Dynamic Infilling Anchors (DIA), a training-free method that dynamically estimates end-anchor positions to adjust generation length before iterative infilling. This flexible mechanism ensures structural correctness and semantic coherence, avoiding the inefficiencies of fixed-span methods. Experiments on reasoning benchmarks demonstrate that DIA substantially improves format compliance and answer accuracy, achieving significant zero-shot gains on GSM8K and MATH. These results establish DIA as a robust pathway toward reliable, structure-aware generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Dynamic Infilling Anchors (DIA), a training-free technique for diffusion large language models that dynamically estimates end-anchor positions to adjust generation length prior to iterative infilling. This is positioned as an improvement over fixed anchors for format-constrained tasks, with claimed substantial zero-shot gains in format compliance and answer accuracy on GSM8K and MATH benchmarks.
Significance. If the experimental results hold with proper controls, DIA would represent a lightweight, training-free mechanism for balancing structural constraints and semantic coherence in bidirectional generation, potentially useful for structured output tasks where fixed spans cause truncation or redundancy.
major comments (2)
- [Abstract] Abstract: The central claim of 'significant zero-shot gains on GSM8K and MATH' is unsupported by any baselines, implementation details for the dynamic position estimator, error bars, or quantitative metrics, preventing evaluation of whether the method actually improves upon fixed anchors or introduces length-prediction errors.
- [Abstract] Abstract (method description): The training-free heuristic for estimating end-anchor positions is described only at a high level with no explicit validation or pseudocode; this directly bears on the skeptic's concern that systematic bias in length prediction could erode gains on reasoning chains without any learned component.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the concerns regarding the abstract below and will revise it to better support the claims while maintaining its concise nature. The main text already contains the requested details, but we agree the abstract can be strengthened.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'significant zero-shot gains on GSM8K and MATH' is unsupported by any baselines, implementation details for the dynamic position estimator, error bars, or quantitative metrics, preventing evaluation of whether the method actually improves upon fixed anchors or introduces length-prediction errors.
Authors: We agree that the abstract as written does not embed these supporting elements. The full manuscript includes fixed-anchor baselines (Section 4.1), the dynamic estimator implementation (Section 3.2), and results with error bars (Tables 2–3). We will revise the abstract to briefly note the baseline comparison and the scale of gains (e.g., “+X% format compliance over fixed anchors”) while keeping length constraints in mind. revision: yes
-
Referee: [Abstract] Abstract (method description): The training-free heuristic for estimating end-anchor positions is described only at a high level with no explicit validation or pseudocode; this directly bears on the skeptic's concern that systematic bias in length prediction could erode gains on reasoning chains without any learned component.
Authors: The heuristic, its pseudocode (Algorithm 1), and empirical validation against length-prediction bias appear in the main body (Sections 3.2 and 4.3). We will revise the abstract to include a short clause referencing the validation that the estimator does not systematically truncate reasoning chains, thereby addressing the concern within the abstract itself. revision: yes
Circularity Check
No circularity: method described at high level with no equations, fits, or self-citation chains
full rationale
The paper presents DIA as a training-free heuristic for dynamic end-anchor estimation in dLLMs. No equations, parameter fits, or derivations appear in the provided text. The central claim (improved format compliance via dynamic length adjustment) is not shown to reduce to any input by construction, self-definition, or load-bearing self-citation. No uniqueness theorems or ansatzes are invoked. The derivation chain is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Large Language Diffusion Models , author=. 2025 , eprint=
2025
-
[2]
2025 , eprint=
Dream 7B: Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[3]
2025 , eprint=
Mercury: Ultra-Fast Language Models Based on Diffusion , author=. 2025 , eprint=
2025
-
[4]
2025 , eprint=
Seed Diffusion: A Large-Scale Diffusion Language Model with High-Speed Inference , author=. 2025 , eprint=
2025
-
[5]
2024 , url =
Gemini Diffusion: Our state-of-the-art, experimental text diffusion model , author =. 2024 , url =
2024
-
[6]
2025 , eprint=
Beyond Fixed: Training-Free Variable-Length Denoising for Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[7]
2021 , eprint=
Training Verifiers to Solve Math Word Problems , author=. 2021 , eprint=
2021
-
[8]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[9]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[10]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
DeepSeek-V3 Technical Report , author=. 2025 , eprint=
2025
-
[12]
2025 , url =
Gemini 2.5: Our most intelligent AI model , author =. 2025 , url =
2025
-
[13]
2025 , url =
Grok 4 , author =. 2025 , url =
2025
-
[14]
2025 , url =
Introducing Claude 4 , author =. 2025 , url =
2025
-
[15]
2025 , url =
Introducing GPT-5 , author =. 2025 , url =
2025
-
[16]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[17]
2022 , eprint=
Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? , author=. 2022 , eprint=
2022
-
[18]
2022 , eprint=
Training language models to follow instructions with human feedback , author=. 2022 , eprint=
2022
-
[19]
2017 , eprint=
Proximal Policy Optimization Algorithms , author=. 2017 , eprint=
2017
-
[20]
2024 , eprint=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. 2024 , eprint=
2024
-
[21]
2024 , eprint=
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models , author=. 2024 , eprint=
2024
-
[22]
2023 , eprint=
BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models , author=. 2023 , eprint=
2023
-
[23]
2023 , eprint=
Visual Instruction Tuning , author=. 2023 , eprint=
2023
-
[24]
2024 , eprint=
Prompt Engineering a Prompt Engineer , author=. 2024 , eprint=
2024
-
[25]
2025 , eprint=
LLM4Rerank: LLM-based Auto-Reranking Framework for Recommendations , author=. 2025 , eprint=
2025
-
[26]
2025 , eprint=
Rank-R1: Enhancing Reasoning in LLM-based Document Rerankers via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[27]
2023 , eprint=
DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task , author=. 2023 , eprint=
2023
-
[28]
2024 , eprint=
Chatlaw: A Multi-Agent Collaborative Legal Assistant with Knowledge Graph Enhanced Mixture-of-Experts Large Language Model , author=. 2024 , eprint=
2024
-
[29]
2023 , eprint=
FinGPT: Open-Source Financial Large Language Models , author=. 2023 , eprint=
2023
-
[31]
2025 , eprint=
CRANE: Reasoning with constrained LLM generation , author=. 2025 , eprint=
2025
-
[32]
2019 , eprint=
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding , author=. 2019 , eprint=
2019
-
[33]
2025 , eprint=
Continuous Diffusion Model for Language Modeling , author=. 2025 , eprint=
2025
-
[34]
2023 , eprint=
Structured Denoising Diffusion Models in Discrete State-Spaces , author=. 2023 , eprint=
2023
-
[35]
2025 , eprint=
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Scaling Diffusion Language Models via Adaptation from Autoregressive Models , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
MMaDA: Multimodal Large Diffusion Language Models , author=. 2025 , eprint=
2025
-
[38]
2025 , eprint=
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning , author=. 2025 , eprint=
2025
-
[39]
2025 , eprint=
Revolutionizing Reinforcement Learning Framework for Diffusion Large Language Models , author=. 2025 , eprint=
2025
-
[40]
2025 , eprint=
d1: Scaling Reasoning in Diffusion Large Language Models via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[41]
2025 , eprint=
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation , author=. 2025 , eprint=
2025
-
[42]
2016 , eprint=
Neural Text Generation from Structured Data with Application to the Biography Domain , author=. 2016 , eprint=
2016
-
[43]
Anthropic. 2025. https://www.anthropic.com/news/claude-4 Introducing claude 4
2025
-
[44]
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
Marianne Arriola, Aaron Gokaslan, Justin T. Chiu, Zhihan Yang, Zhixuan Qi, Jiaqi Han, Subham Sekhar Sahoo, and Volodymyr Kuleshov. 2025. https://arxiv.org/abs/2503.09573 Block diffusion: Interpolating between autoregressive and diffusion language models . Preprint, arXiv:2503.09573
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg
Jacob Austin, Daniel D. Johnson, Jonathan Ho, Daniel Tarlow, and Rianne van den Berg. 2023. https://arxiv.org/abs/2107.03006 Structured denoising diffusion models in discrete state-spaces . Preprint, arXiv:2107.03006
- [46]
-
[47]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. https://arxiv.org/abs/2110.14168 Training verifiers to solve math word problems . Preprint, arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[48]
Jiaxi Cui, Munan Ning, Zongjian Li, Bohua Chen, Yang Yan, Hao Li, Bin Ling, Yonghong Tian, and Li Yuan. 2024. https://arxiv.org/abs/2306.16092 Chatlaw: A multi-agent collaborative legal assistant with knowledge graph enhanced mixture-of-experts large language model . Preprint, arXiv:2306.16092
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Google Deepmind. 2024. https://deepmind.google/models/gemini-diffusion/ Gemini diffusion: Our state-of-the-art, experimental text diffusion model
2024
-
[50]
Google Deepmind. 2025. https://blog.google/technology/google-deepmind/gemini-model-thinking-updates-march-2025/ Gemini 2.5: Our most intelligent ai model
2025
-
[51]
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, and 181 others. 2025. https://arxiv.org/abs/2412.19437 Deepseek-v3 technical report . Preprint, arXiv:2412.19437
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. https://arxiv.org/abs/1810.04805 Bert: Pre-training of deep bidirectional transformers for language understanding . Preprint, arXiv:1810.04805
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [53]
-
[54]
Shansan Gong, Shivam Agarwal, Yizhe Zhang, Jiacheng Ye, Lin Zheng, Mukai Li, Chenxin An, Peilin Zhao, Wei Bi, Jiawei Han, Hao Peng, and Lingpeng Kong. 2025 a . https://arxiv.org/abs/2410.17891 Scaling diffusion language models via adaptation from autoregressive models . Preprint, arXiv:2410.17891
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [55]
-
[56]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[57]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. https://arxiv.org/abs/2103.03874 Measuring mathematical problem solving with the math dataset . Preprint, arXiv:2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
- [58]
-
[59]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. https://arxiv.org/abs/2001.08361 Scaling laws for neural language models . Preprint, arXiv:2001.08361
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[60]
Inception Labs, Samar Khanna, Siddhant Kharbanda, Shufan Li, Harshit Varma, Eric Wang, Sawyer Birnbaum, Ziyang Luo, Yanis Miraoui, Akash Palrecha, Stefano Ermon, Aditya Grover, and Volodymyr Kuleshov. 2025. https://arxiv.org/abs/2506.17298 Mercury: Ultra-fast language models based on diffusion . Preprint, arXiv:2506.17298
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[61]
Remi Lebret, David Grangier, and Michael Auli. 2016. https://arxiv.org/abs/1603.07771 Neural text generation from structured data with application to the biography domain . Preprint, arXiv:1603.07771
work page internal anchor Pith review Pith/arXiv arXiv 2016
- [62]
-
[63]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023. https://arxiv.org/abs/2301.12597 Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models . Preprint, arXiv:2301.12597
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. https://arxiv.org/abs/2304.08485 Visual instruction tuning . Preprint, arXiv:2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[65]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2022. https://arxiv.org/abs/2202.12837 Rethinking the role of demonstrations: What makes in-context learning work? Preprint, arXiv:2202.12837
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
Niels Mündler, Jingxuan He, Hao Wang, Koushik Sen, Dawn Song, and Martin Vechev. 2025. https://doi.org/10.1145/3729274 Type-constrained code generation with language models . Proceedings of the ACM on Programming Languages, 9(PLDI):601–626
-
[67]
Shen Nie, Fengqi Zhu, Zebin You, Xiaolu Zhang, Jingyang Ou, Jun Hu, Jun Zhou, Yankai Lin, Ji-Rong Wen, and Chongxuan Li. 2025. https://arxiv.org/abs/2502.09992 Large language diffusion models . Preprint, arXiv:2502.09992
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
OpenAI. 2025. https://openai.com/index/introducing-gpt-5/ Introducing gpt-5
2025
-
[69]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. https://arxiv.org/abs/2203.02155 Training language models to f...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[70]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2024. https://arxiv.org/abs/2305.18290 Direct preference optimization: Your language model is secretly a reward model . Preprint, arXiv:2305.18290
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[71]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. https://arxiv.org/abs/1707.06347 Proximal policy optimization algorithms . Preprint, arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[72]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Yuxuan Song, Zheng Zhang, Cheng Luo, Pengyang Gao, Fan Xia, Hao Luo, Zheng Li, Yuehang Yang, Hongli Yu, Xingwei Qu, Yuwei Fu, Jing Su, Ge Zhang, Wenhao Huang, Mingxuan Wang, Lin Yan, Xiaoying Jia, Jingjing Liu, Wei-Ying Ma, and 3 others. 2025. https://arxiv.org/abs/2508.02193 Seed diffusion: A large-scale diffusion language model with high-speed inference...
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [74]
-
[75]
xAI. 2025. https://x.ai/news/grok-4 Grok 4
2025
- [76]
-
[77]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025 a . https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [78]
-
[79]
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. 2025 b . https://arxiv.org/abs/2505.15809 Mmada: Multimodal large diffusion language models . Preprint, arXiv:2505.15809
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[80]
Jiacheng Ye, Zhihui Xie, Lin Zheng, Jiahui Gao, Zirui Wu, Xin Jiang, Zhenguo Li, and Lingpeng Kong. 2025. https://arxiv.org/abs/2508.15487 Dream 7b: Diffusion large language models . Preprint, arXiv:2508.15487
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [81]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.