Beyond Retrieval: Learning Compact User Representations for Scalable LLM Personalization
Pith reviewed 2026-06-28 04:20 UTC · model grok-4.3
The pith
TAP-PER encodes user preferences as learnable temporal attentive prefix embeddings for scalable LLM personalization without retrieval or per-user adapters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
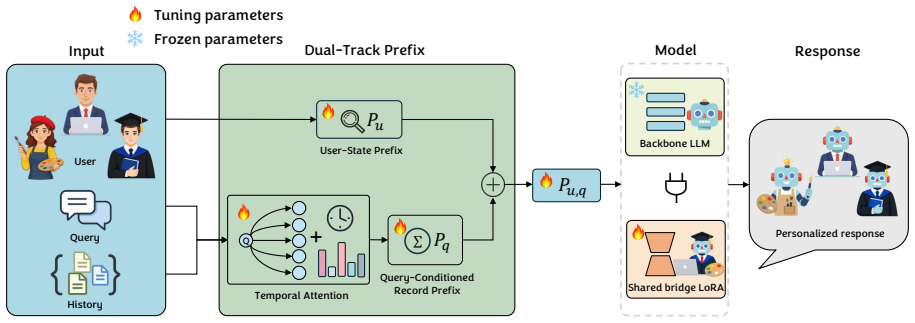
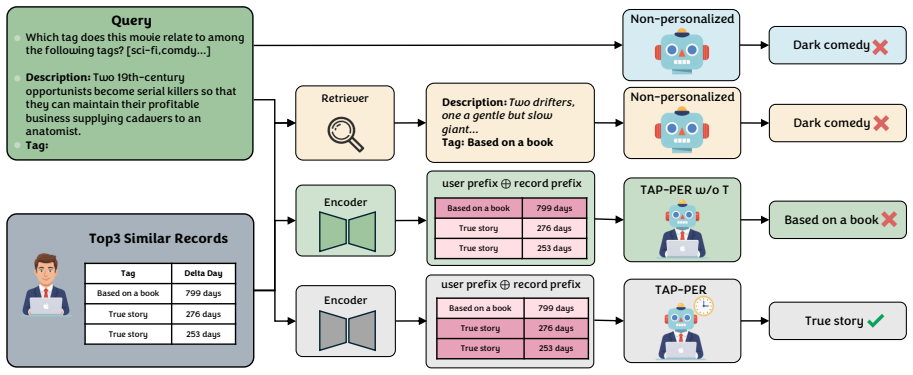
TAP-PER decomposes user modeling into user-state and query-conditioned components encoded as temporal attentive prefix embeddings, which are injected into the LLM to adapt its behavior to individual preferences without constructing explicit prompts from histories or maintaining separate per-user adapter modules.
What carries the argument
Temporal attentive prefix embeddings that encode user preferences as lightweight learnable vectors, with temporal signals to track evolving interests.
If this is right
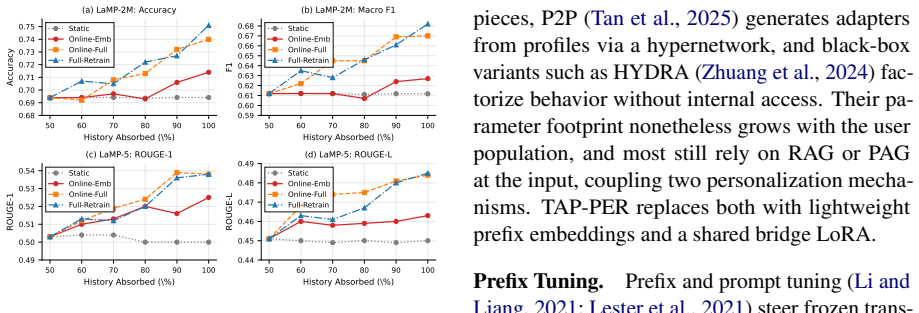
- TAP-PER outperforms prompt-based and model-based baselines on classification, rating, and generation tasks across the six LaMP benchmarks.
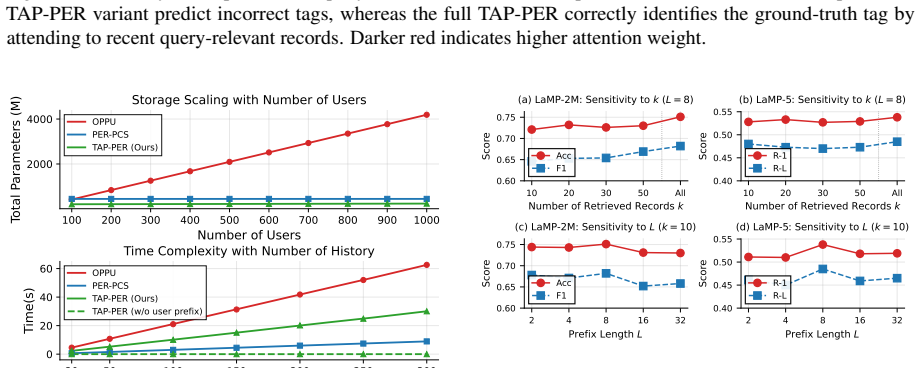
- It requires 130 times fewer per-user parameters than OPPU.
- At the 1,000-user scale it uses roughly half the total parameter count of PER-PCS.
- Personalization becomes feasible at deployment scale without sensitivity to retrieval quality or prompt engineering.
Where Pith is reading between the lines
- The same prefix approach could apply to any sequential user-interaction setting where interests drift over time, such as session-based recommendation.
- Parameter savings would compound further at 10,000 or 100,000 users, potentially enabling per-user adaptation on shared hardware without linear cost growth.
- If the temporal component is ablated, performance on tasks with rapidly changing user behavior would be expected to degrade first.
Load-bearing premise
User preferences can be effectively captured and generalized by learnable temporal attentive prefix embeddings without needing explicit retrieval of user histories or per-user parameter modules.
What would settle it
An experiment on a new LaMP-style task where TAP-PER underperforms both prompt-based and adapter-based baselines at the 1,000-user scale would falsify the central claim.
Figures

read the original abstract
Personalizing large language models requires adapting model behavior to individual users while preserving robustness and deployment-scale efficiency. Existing approaches typically personalize LLMs either at the input level, by retrieving user histories or constructing profile prompts, or at the parameter level, by maintaining user-specific parameter-efficient modules. The former makes personalization sensitive to retrieval quality and prompt design, whereas the latter incurs storage and maintenance costs that grow with the user population. To address these limitations, we propose TAP-PER (Temporal Attentive Prefix for PERsonalization), a prefix-based framework that encodes user preferences as learnable representations, eliminating explicit prompt construction and replacing heavy per-user adapters with lightweight user-state prefix embeddings. Inspired by personalized recommendation systems, TAP-PER decomposes user modeling into user-state and query-conditioned components, and incorporates temporal signals to capture the evolving nature of user interests. Experiments on six LaMP tasks show that TAP-PER consistently outperforms prompt-based and model-based baselines across classification, rating, and generation settings. Moreover, TAP-PER uses 130x fewer per-user parameters than OPPU and roughly half the total parameter footprint of PER-PCS at the 1,000-user scale, demonstrating that scalable LLM personalization can be achieved without explicit prompt construction or heavy per-user adapters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TAP-PER, a prefix-based personalization framework for LLMs that encodes user preferences via learnable temporal attentive prefix embeddings. These embeddings decompose user modeling into user-state and query-conditioned components while incorporating temporal signals. The central claims are that TAP-PER consistently outperforms prompt-based and model-based baselines on six LaMP tasks spanning classification, rating, and generation, while achieving substantial efficiency gains (130x fewer per-user parameters than OPPU; roughly half the total parameter footprint of PER-PCS at the 1,000-user scale).
Significance. If the empirical results hold under rigorous controls, the work demonstrates a viable path to scalable LLM personalization that avoids both retrieval sensitivity and the storage costs of per-user adapters. The efficiency numbers, if reproducible, would be a notable practical contribution for large-scale deployment.
minor comments (2)
- The abstract states performance and efficiency results but does not reference the specific LaMP task identifiers, dataset sizes, or statistical significance tests; adding these pointers in §4 would strengthen the summary.
- Notation for the temporal attentive prefix (e.g., how the user-state and query-conditioned components are combined) should be defined explicitly in §3 before the experimental section.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of TAP-PER and the recommendation for minor revision. The summary accurately captures the core contribution of encoding user preferences via lightweight temporal attentive prefix embeddings that avoid both retrieval sensitivity and per-user adapter storage costs. No specific major comments were listed in the report.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical framework (TAP-PER) that learns temporal attentive prefix embeddings for user personalization and evaluates it via experiments on six LaMP tasks against named baselines. No derivation chain, equations, or first-principles results are presented that reduce to inputs by construction, self-definition, or fitted-parameter renaming. Claims rest on direct experimental comparisons and efficiency measurements (e.g., parameter counts), which are independent of any internal reduction. No load-bearing self-citations or uniqueness theorems are invoked in the provided text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Democratizing large language models via personalized parameter-efficient fine-tuning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[9]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Proper: A progressive learning framework for personalized large language models with group-level adaptation , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Lamp: When large language models meet personalization , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[14]
arXiv preprint arXiv:2509.23767 , year=
From Personal to Collective: On the Role of Local and Global Memory in LLM Personalization , author=. arXiv preprint arXiv:2509.23767 , year=
-
[15]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[17]
Salemi, Alireza and Mysore, Sheshera and Bendersky, Michael and Zamani, Hamed , booktitle=. La
-
[18]
arXiv preprint arXiv:2112.10051 , year=
UserAdapter: Few-Shot User Learning in Sentiment Analysis , author=. arXiv preprint arXiv:2112.10051 , year=
-
[19]
arXiv preprint arXiv:2406.10471 , year=
Personalized Pieces: Efficient Personalized Large Language Models through Collaborative Efforts , author=. arXiv preprint arXiv:2406.10471 , year=
-
[20]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
Personalized Soups: Personalized Large Language Model Alignment via Post-hoc Parameter Merging , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , year=
2024
-
[21]
Advances in Neural Information Processing Systems , year=
Fine-Grained Human Feedback Gives Better Rewards for Language Model Training , author=. Advances in Neural Information Processing Systems , year=
-
[22]
Advances in Neural Information Processing Systems , year=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in Neural Information Processing Systems , year=
-
[23]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Personalized pieces: Efficient personalized large language models through collaborative efforts , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[24]
Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
Deep interest network for click-through rate prediction , author=. Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining , pages=
-
[25]
Proceedings of the 13th international conference on web search and data mining , pages=
Time interval aware self-attention for sequential recommendation , author=. Proceedings of the 13th international conference on web search and data mining , pages=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Where to go next: Modeling long-and short-term user preferences for point-of-interest recommendation , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep interest evolution network for click-through rate prediction , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[28]
2018 IEEE international conference on data mining (ICDM) , pages=
Self-attentive sequential recommendation , author=. 2018 IEEE international conference on data mining (ICDM) , pages=. 2018 , organization=
2018
-
[29]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author=. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[30]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
The Power of Scale for Parameter-Efficient Prompt Tuning , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages=
2021
-
[31]
Parameter-Efficient Transfer Learning for
Houlsby, Neil and Giurgiu, Andrei and Jastrzebski, Stanislaw and Morrone, Bruna and De Laroussilhe, Quentin and Gesmundo, Andrea and Attariyan, Mona and Gelly, Sylvain , booktitle=. Parameter-Efficient Transfer Learning for
-
[32]
Advances in Neural Information Processing Systems , year=
Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learning , author=. Advances in Neural Information Processing Systems , year=
-
[33]
Uncovering
Dai, Sunhao and Shao, Ninglu and Zhao, Haiyuan and Yu, Weijie and Si, Zihua and Xu, Chen and Sun, Zhongxiang and Zhang, Xiao and Xu, Jun , journal=. Uncovering
-
[34]
Kang, Wang-Cheng and Ni, Jianmo and Mehta, Nikhil and Sathiamoorthy, Maheswaran and Hong, Lichan and Chi, Ed and Cheng, Derek Zhiyuan , journal=. Do
-
[35]
Li, Cheng and Zhang, Mingyang and Mei, Qiaozhu and Wang, Yaqing and Hulgeri, Spurthi Amba and Dong, Yi and Najork, Marc and Bendersky, Michael , journal=. Teach
-
[36]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , journal=. The
-
[37]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , journal=
-
[38]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
Transformers: State-of-the-Art Natural Language Processing , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pages=
2020
-
[39]
Lin, Chin-Yew , booktitle=
-
[40]
Improvements to
Trotman, Andrew and Puurula, Antti and Burgess, Blake , journal=. Improvements to
-
[41]
Sun, Fei and Liu, Jun and Wu, Jian and Pei, Changhua and Lin, Xiao and Ou, Wenwu and Jiang, Peng , booktitle=
-
[42]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume=
-
[43]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2020
-
[44]
30th USENIX Security Symposium (USENIX Security 21) , pages=
Extracting Training Data from Large Language Models , author=. 30th USENIX Security Symposium (USENIX Security 21) , pages=
-
[45]
arXiv preprint arXiv:2305.15498 , year=
Large Language Models for User Interest Journeys , author=. arXiv preprint arXiv:2305.15498 , year=
-
[46]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[47]
Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
Pfeiffer, Jonas and Kamath, Aishwarya and R. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[48]
HyperNetworks , author=. arXiv preprint arXiv:1609.09106 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
World Wide Web , volume=
When Large Language Models Meet Personalization: Perspectives of Challenges and Opportunities , author=. World Wide Web , volume=
-
[50]
Nature Machine Intelligence , pages=
The Benefits, Risks and Bounds of Personalizing the Alignment of Large Language Models to Individuals , author=. Nature Machine Intelligence , pages=
-
[51]
Zhuang, Yuchen and Sun, Haotian and Yu, Yue and Qiang, Rushi and Wang, Qifan and Zhang, Chao and Dai, Bo , booktitle=
-
[52]
Persona-
Sun, Chenkai and Yang, Ke and Reddy, Revanth Gangi and Fung, Yi Ren and Chan, Hou Pong and Small, Kevin and Zhai, ChengXiang and Ji, Heng , booktitle=. Persona-
-
[53]
and Qian, Cheng and Kim, Jeonghwan and Hakkani-Tur, Dilek and Ji, Heng , booktitle=
Wu, Shujin and Fung, Yi R. and Qian, Cheng and Kim, Jeonghwan and Hakkani-Tur, Dilek and Ji, Heng , booktitle=. Aligning
-
[54]
Advances in Neural Information Processing Systems , year=
Attention is all you need , author=. Advances in Neural Information Processing Systems , year=
-
[55]
Advances in Neural Information Processing Systems , year=
Language Models are Few-Shot Learners , author=. Advances in Neural Information Processing Systems , year=
-
[56]
Journal of Machine Learning Research , volume=
Exploring the limits of transfer learning with a unified text-to-text transformer , author=. Journal of Machine Learning Research , volume=
-
[57]
Advances in Neural Information Processing Systems , year=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems , year=
-
[58]
LLaMA: Open and Efficient Foundation Language Models
LLaMA: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Ben Zaken, Elad and Goldberg, Yoav and Ravfogel, Shauli , booktitle=
-
[60]
Advances in Neural Information Processing Systems , year=
Compacter: Efficient Low-Rank Hypercomplex Adapter Layers , author=. Advances in Neural Information Processing Systems , year=
-
[61]
Zhang, Renrui and Han, Jiaming and Liu, Chris and Zhou, Aojun and Lu, Pan and Qiao, Yu and Li, Hongsheng and Gao, Peng , booktitle=
-
[62]
Zhang, Qingru and Chen, Minshuo and Bukharin, Alexander and He, Pengcheng and Cheng, Yu and Chen, Weizhu and Zhao, Tuo , booktitle=
-
[63]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle=
-
[64]
Liu, Shih-Yang and Wang, Chien-Yi and Yin, Hongxu and Molchanov, Pavlo and Wang, Yu-Chiang Frank and Cheng, Kwang-Ting and Chen, Min-Hung , booktitle=
-
[65]
International Conference on Learning Representations , year=
Session-based Recommendations with Recurrent Neural Networks , author=. International Conference on Learning Representations , year=
-
[66]
Proceedings of WSDM , year=
Personalized top-N sequential recommendation via convolutional sequence embedding , author=. Proceedings of WSDM , year=
-
[67]
He, Xiangnan and Deng, Kuan and Wang, Xiang and Li, Yan and Zhang, Yongdong and Wang, Meng , booktitle=
-
[68]
Proceedings of the National Academy of Sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the National Academy of Sciences , volume=
-
[69]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Learning without Forgetting , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
-
[70]
Advances in Neural Information Processing Systems , year=
Gradient Episodic Memory for Continual Learning , author=. Advances in Neural Information Processing Systems , year=
-
[71]
Efficient Lifelong Learning with
Chaudhry, Arslan and Ranzato, Marc'Aurelio and Rohrbach, Marcus and Elhoseiny, Mohamed , booktitle=. Efficient Lifelong Learning with
-
[72]
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H , booktitle=
-
[73]
Findings of EMNLP , year=
Orthogonal Subspace Learning for Language Model Continual Learning , author=. Findings of EMNLP , year=
-
[74]
Zhang, Tianyi and Kishore, Varsha and Wu, Felix and Weinberger, Kilian Q and Artzi, Yoav , journal=
-
[75]
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle=
-
[76]
He, Yun and Zheng, Steven and Tay, Yi and Gupta, Jai and Du, Yu and Aribandi, Vamsi and Zhao, Zhe and Li, YaGuang and Chen, Zhao and Metzler, Donald and Cheng, Heng-Tze and Chi, Ed H , booktitle=
-
[77]
Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard Lanas and Gao, Irena and others , booktitle=
-
[78]
Shi, Weijia and Min, Sewon and Yasunaga, Michihiro and Seo, Minjoon and James, Rich and Lewis, Mike and Zettlemoyer, Luke and Yih, Wen-tau , booktitle=
-
[79]
Transactions of the Association for Computational Linguistics , year=
In-Context Retrieval-Augmented Language Models , author=. Transactions of the Association for Computational Linguistics , year=
-
[80]
Rajbhandari, Samyam and Rasley, Jeff and Ruwase, Olatunji and He, Yuxiong , booktitle=
-
[81]
Proceedings of SIGIR , year=
Optimization Methods for Personalizing Large Language Models through Retrieval Augmentation , author=. Proceedings of SIGIR , year=
-
[82]
Selective Prompting Tuning for Personalized Conversations with
Huang, Qiushi and Liu, Xubo and Ko, Tom and Wu, Bo and Wang, Wenwu and Zhang, Yu and Tang, Lilian , journal=. Selective Prompting Tuning for Personalized Conversations with
-
[83]
Generative Sequential Recommendation with
Petrov, Aleksandr V and Macdonald, Craig , booktitle=. Generative Sequential Recommendation with
-
[84]
World Wide Web Journal , year=
A Survey on Large Language Models for Recommendation , author=. World Wide Web Journal , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.