Neetyabhas: A Framework for Uncertainty-Aware Public Policy Optimization in Rational Agent-Based Models
Pith reviewed 2026-06-28 06:39 UTC · model grok-4.3
The pith
A simulation using RL agents that handle noisy epidemic data and imperfect policy execution shows masks and vaccines reduce outbreak peaks and duration even with variable individual behaviors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
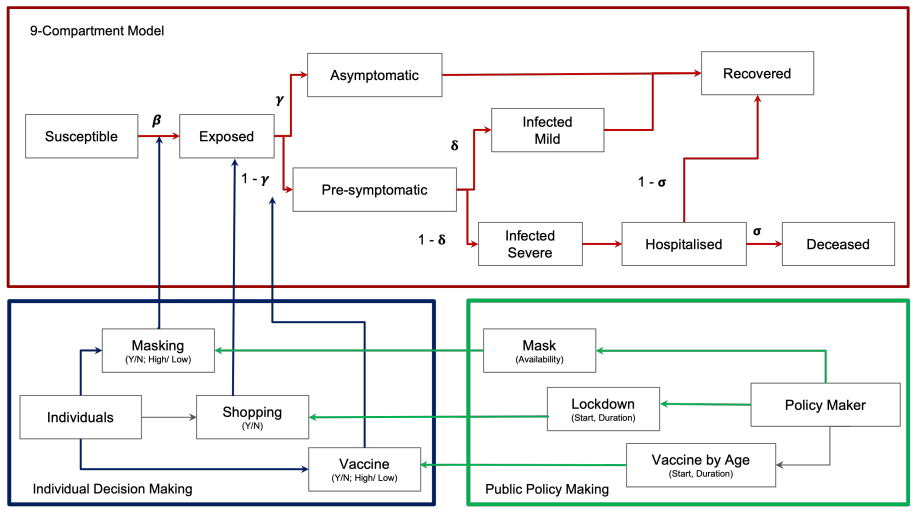
The framework models both citizens and policymakers as reinforcement learning agents operating under explicit uncertainties in measurement of infections and hospitalizations and in the execution of chosen policies, and shows that this integrated treatment allows multifaceted interventions to control simulated epidemic progression where prior perfect-information models do not.
What carries the argument
Hierarchical reinforcement learning agents using deep Q-networks together with uncertainty-aware policy-gradient variants (DDPG and TD3) that optimize intervention choices from imperfect observations in a 1000-agent simulation of individual protective behaviors.
If this is right
- Masking and vaccinations significantly reduce both the height and duration of the simulated outbreak.
- Integrating individual behavioral choices with policy uncertainties produces effective dynamic control of epidemic spread.
- Accounting for imperfect data and execution errors is necessary for realistic public-health policy design.
Where Pith is reading between the lines
- The same uncertainty-handling structure could be tested on non-epidemic policy problems that also involve noisy measurements and behavioral responses, such as traffic or energy-demand management.
- Calibration against multiple real outbreak datasets would reveal whether the learned policies remain stable when the underlying error distributions change.
- The framework implies that optimal intervention thresholds may shift once measurement noise is modeled explicitly rather than assumed away.
Load-bearing premise
The simulation parameters and RL agent behaviors accurately capture real-world human decision-making and the statistical properties of measurement and implementation errors in epidemic settings.
What would settle it
Running the same model on historical COVID-19 case and policy data from a real jurisdiction and checking whether the simulated trajectories under the learned policies match the observed epidemic curves within the reported uncertainty bounds.
Figures
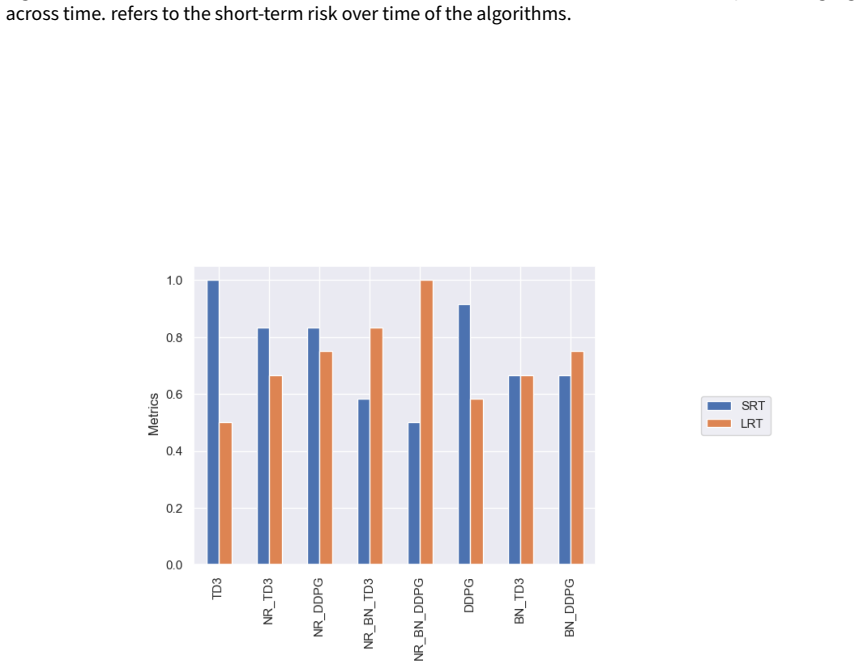
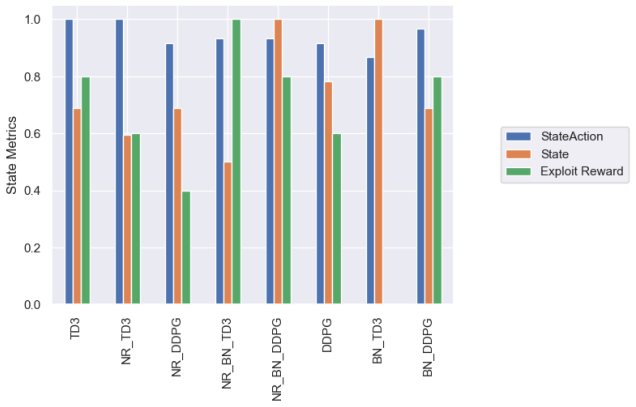
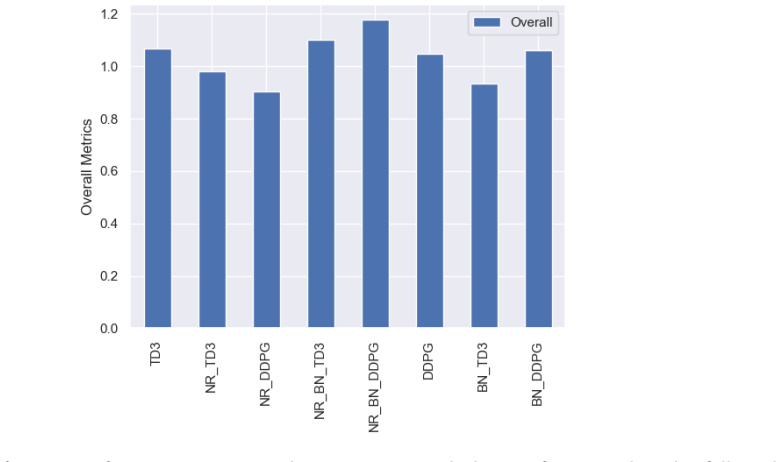





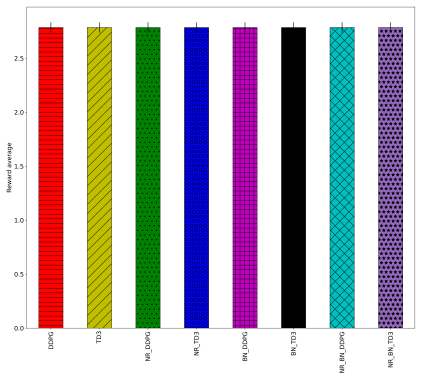
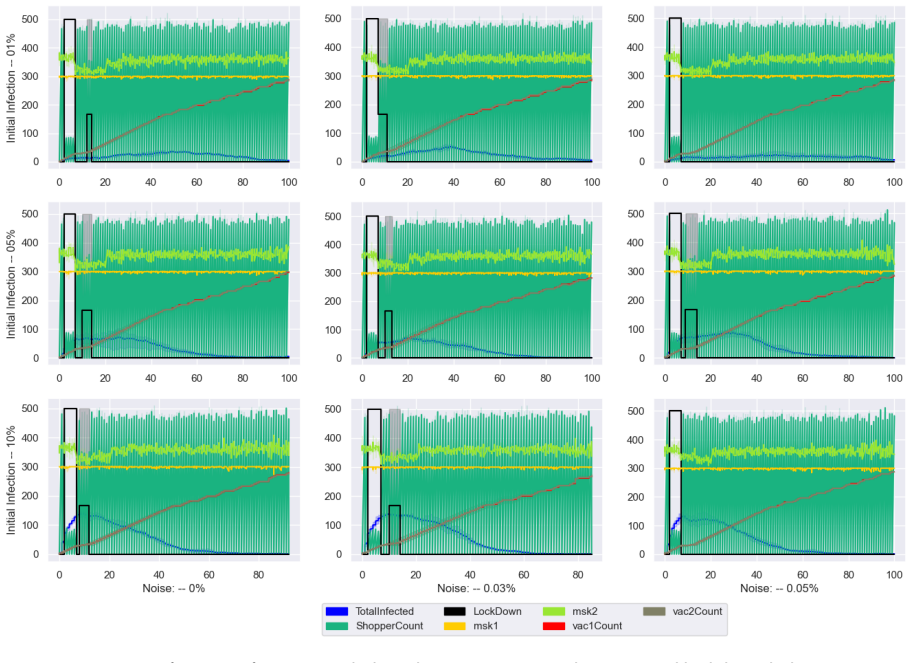
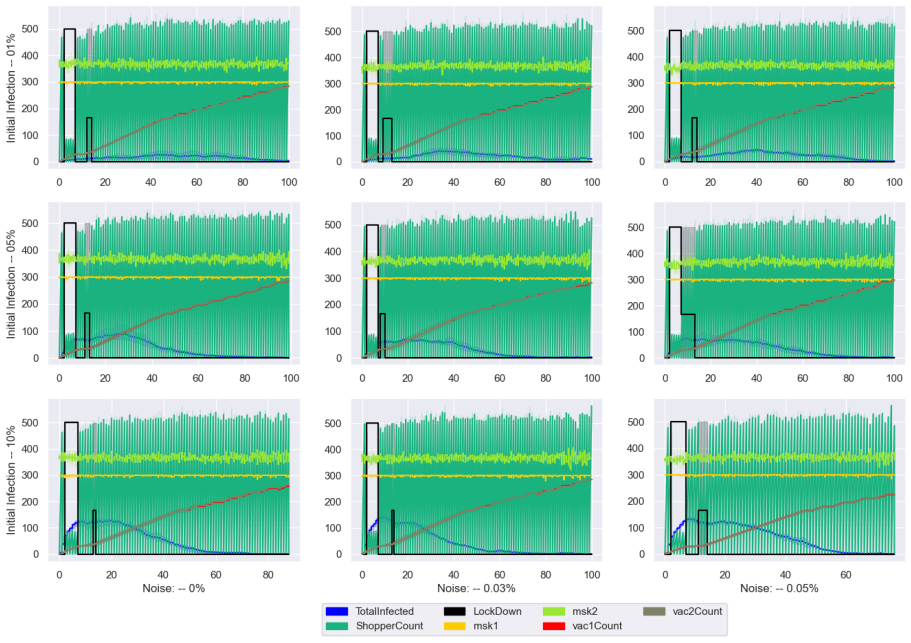
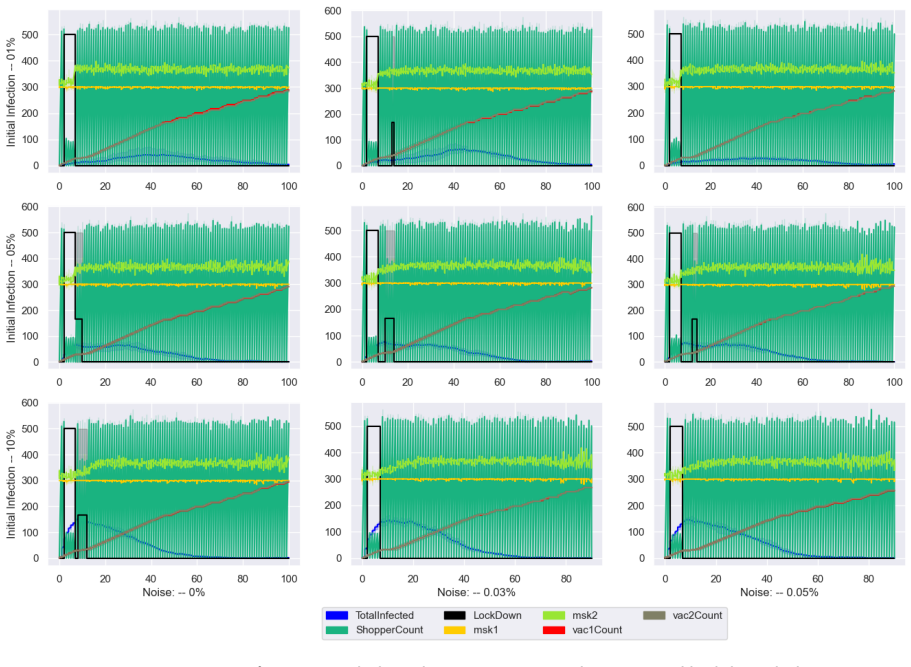
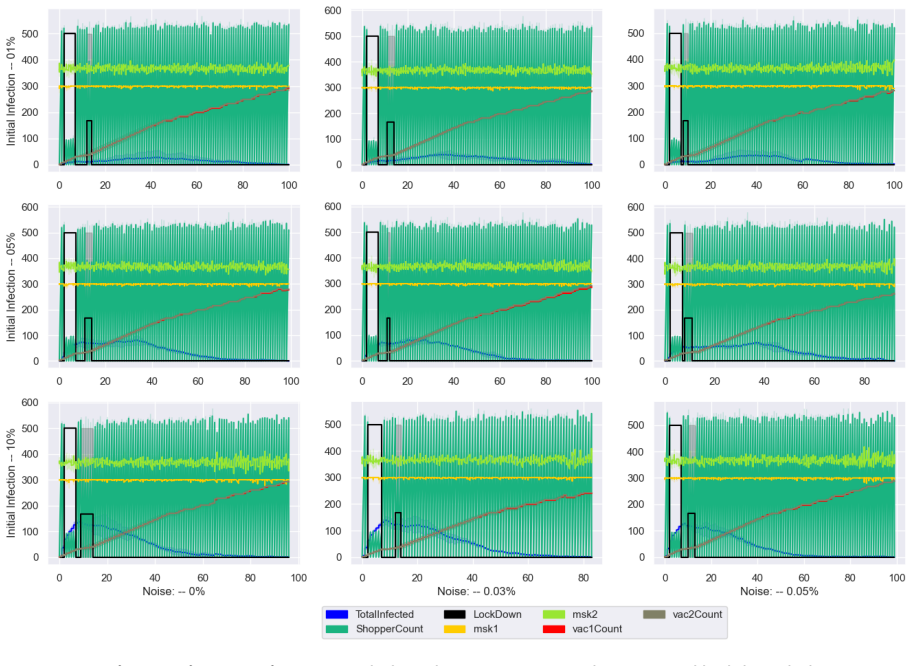
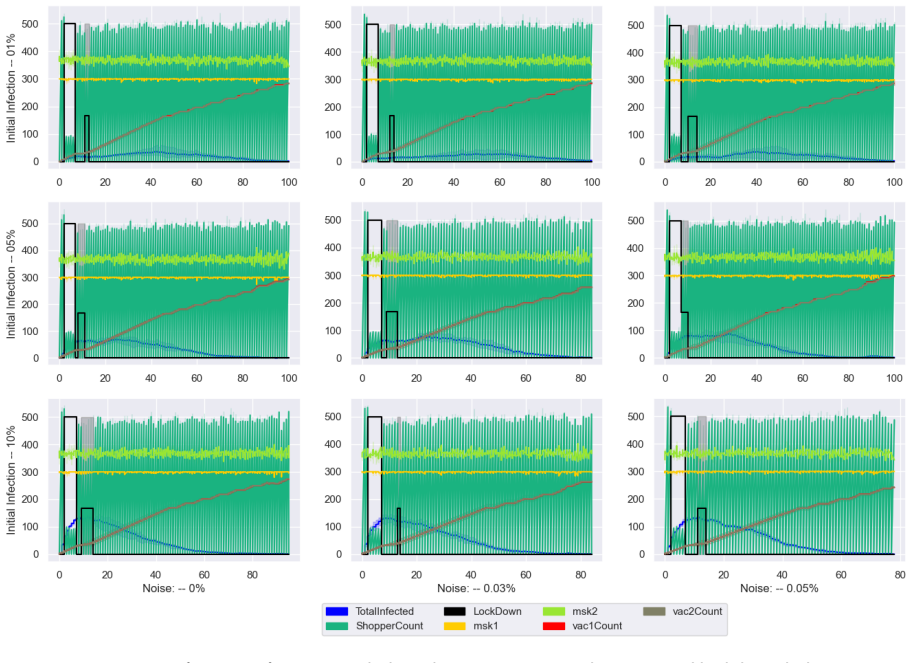
read the original abstract
Purpose The WHO's COVID-19 non-pharmaceutical interventions (e.g., lockdowns, vaccinations) effectively curb transmission but impose heavy economic strains. Existing research often neglects individual behaviors and falsely assumes perfect infection tracking and flawless policy execution, failing to account for real-world uncertainties and errors. Methods We propose an integrative approach incorporating uncertainties in both epidemic measurement (infections/hospitalizations) and policy implementation. We built a simulation model of 1,000 individuals making real-time choices regarding mask-wearing, vaccination, and shopping. Concurrently, policymakers deploy interventions (lockdowns, mandates) based on health and economic observations. This framework is driven by hierarchical reinforcement learning agents, utilizing deep Q-networks alongside uncertainty-aware policy gradient variants (DDPG and TD3). Results The simulations effectively managed the epidemic's progression. Masking and vaccinations proved highly effective, significantly reducing both the outbreak's peak height and duration. By integrating individual behaviors, policy uncertainties, and multifaceted interventions, our dynamic control approach successfully mitigated the epidemic's impact. Conclusions Our model overcomes previous research limitations by embedding uncertainty and human behavior into public health policy frameworks. The simulation demonstrates that accounting for individual choices and imperfect data is crucial for designing effective interventions during complex pandemics, with masks and vaccines serving as pivotal tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Neetyabhas, a framework for uncertainty-aware public policy optimization using rational agent-based models. It simulates 1,000 individuals making real-time decisions on masking, vaccination, and shopping, while policymakers use hierarchical reinforcement learning (DQN combined with uncertainty-aware DDPG and TD3) to deploy interventions like lockdowns under uncertainties in epidemic measurements and policy implementation. The central claim is that the simulations effectively managed the epidemic, with masking and vaccination proving highly effective in reducing peak height and duration.
Significance. If the simulation results were validated against external data and baselines, the work could contribute to integrating behavioral agent models with RL for policy optimization under uncertainty. The hierarchical RL structure for handling discrete and continuous actions with uncertainty is a positive technical feature, but the current lack of quantitative grounding limits broader significance.
major comments (3)
- [Abstract] Abstract: The claims that 'the simulations effectively managed the epidemic's progression' and that 'masking and vaccinations proved highly effective, significantly reducing both the outbreak's peak height and duration' provide no quantitative metrics, effect sizes, error bars, or statistical tests to support them.
- [Results] Results: No baseline comparisons are reported against standard compartmental models (e.g., SIR/SEIR) or non-RL policy rules, preventing attribution of any mitigation effect to the hierarchical RL framework rather than simulation parameters.
- [Methods] Methods: The agent behavioral utility functions and measurement/implementation error distributions are not calibrated or validated against real COVID-19 incidence curves or external datasets, so the mitigation outcome may be an artifact of the chosen free parameters (population size, RL hyperparameters).
minor comments (1)
- [Abstract] Abstract: The 'Purpose' paragraph could more explicitly contrast the proposed uncertainty modeling with prior agent-based epidemic studies.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important areas for strengthening the quantitative rigor and grounding of our work. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claims that 'the simulations effectively managed the epidemic's progression' and that 'masking and vaccinations proved highly effective, significantly reducing both the outbreak's peak height and duration' provide no quantitative metrics, effect sizes, error bars, or statistical tests to support them.
Authors: We agree that the abstract would be strengthened by including quantitative support. In the revised version, we will update the abstract to report specific metrics from the simulation results, such as the percentage reduction in peak infections and epidemic duration, along with any associated variability measures. revision: yes
-
Referee: [Results] Results: No baseline comparisons are reported against standard compartmental models (e.g., SIR/SEIR) or non-RL policy rules, preventing attribution of any mitigation effect to the hierarchical RL framework rather than simulation parameters.
Authors: The absence of baseline comparisons is a valid observation that limits causal attribution. While the core contribution is the hierarchical RL structure for uncertainty-aware decisions, we will add comparisons to SIR/SEIR models and non-RL policy heuristics in the revised results section to better isolate the framework's effects. revision: yes
-
Referee: [Methods] Methods: The agent behavioral utility functions and measurement/implementation error distributions are not calibrated or validated against real COVID-19 incidence curves or external datasets, so the mitigation outcome may be an artifact of the chosen free parameters (population size, RL hyperparameters).
Authors: We acknowledge that the utility functions and error distributions rely on literature-derived assumptions rather than direct calibration to incidence data. This is a genuine limitation. In revision, we will incorporate a parameter sensitivity analysis for population size and RL hyperparameters and add an explicit discussion of external validation as a limitation, while outlining directions for future calibration. revision: partial
Circularity Check
No significant circularity; simulation outputs with no derivation chain
full rationale
The paper presents a simulation framework with 1000 agents, hierarchical RL (DQN + uncertainty-aware DDPG/TD3), and policy interventions, reporting that the runs show reduced epidemic peak and duration. No equations, derivations, or first-principles results are described that could reduce a claimed prediction to its own inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked to support the central mitigation claim. Results are direct simulation outputs under the stated behavioral and error models; this is the normal, non-circular case for simulation studies.
Axiom & Free-Parameter Ledger
free parameters (2)
- Simulation population size
- RL algorithm hyperparameters
axioms (2)
- domain assumption Individuals act as rational agents making real-time choices based on local observations
- domain assumption Uncertainties in epidemic measurements and policy execution can be captured by uncertainty-aware policy gradient variants
Reference graph
Works this paper leans on
-
[1]
K., Khan, S
Awasthi, R., Guliani, K. K., Khan, S. A., Vashishtha, A., Gill, M. S., Bhatt, A., Nagori, A., Gupta, A., Kumaraguru, P . & Sethi, T . (2022). Vacsim: Learning effective strategies for covid-19 vaccine distribution using reinforcement learning.Intelligence-Based Medicine, (p. 100060) 30 Figure 15:Baseline ExperimentDetailed masking, vaccination, shopping a...
2022
-
[2]
& Papapetrou, P
Bampa, M., Fasth, T ., Magnusson, S. & Papapetrou, P . (2022). : Learning intervention strategies for epidemics with reinforcement learning. InInternational Conference on Artificial Intelligence in Medicine, (pp. 189–199). Springer
2022
-
[3]
& Galea, S
Bavli, I., Sutton, B. & Galea, S. (2020). Harms of public health interventions against covid-19 must not be ignored. Bmj,371
2020
-
[4]
P ., Singh, A
Bednarski, B. P ., Singh, A. D. & Jones, W. M. (2021). On collaborative reinforcement learning to optimize the redistribution of critical medical supplies throughout the covid-19 pandemic.Journal of the American Medical Informatics Association,28(4), 874–878
2021
-
[5]
& Bhuiyan, S
Brodeur, A., Gray, D., Islam, A. & Bhuiyan, S. (2021). A literature review of the economics of covid-19.Journal of Economic Surveys,35(4), 1007–1044
2021
-
[6]
& Odry, B
Browning, J., Kornreich, M., Chow, A., Pawar, J., Zhang, L., Herzog, R. & Odry, B. L. (2021). Uncertainty aware deep reinforcement learning for anatomical landmark detection in medical images. InInternational Confer- ence on Medical Image Computing and Computer-Assisted Intervention, (pp. 636–644). Springer
2021
-
[7]
& Mousannif, H
Chadi, M.-A. & Mousannif, H. (2022). A reinforcement learning based decision support tool for epidemic control: Validation study for covid-19.Applied Artificial Intelligence, (pp. 1–33)
2022
-
[8]
C., Fishman, S., Canny, J., Korattikara, A
Chan, S. C., Fishman, S., Canny, J., Korattikara, A. & Guadarrama, S. (2020). Measuring the reliability of reinforce- ment learning algorithms. InInternational Conference on Learning Representations, Addis Ababa, Ethiopia
2020
-
[9]
Cherian, P ., Kshirsagar, J., Neekhra, B., Deshkar, G., Hayatnagarkar, H., Kapoor, K., Kaski, C., Kathar, G., Khan- dekar, S., Mookherje, S. et al. (2023). Bharatsim: An agent-based modelling framework for india.medRxiv, (pp. 2023–06) 31 Figure 16:High Mask ExperimentDetailed masking, vaccination, shopping and lockdown behavior 32 Figure 17:Low Mask Exper...
2023
-
[10]
L., Kain, M
Childs, M. L., Kain, M. P ., Kirk, D., Harris, M., Couper, L., Nova, N., Delwel, I., Ritchie, J. & Mordecai, E. A. (2020). The impact of long-term non-pharmaceutical interventions on covid-19 epidemic dynamics and control.MedRxiv
2020
-
[11]
& Prague, M
Colas, C., Hejblum, B., Rouillon, S., Thiébaut, R., Oudeyer, P .-Y., Moulin-Frier, C. & Prague, M. (2021). Epidemiop- tim: A toolbox for the optimization of control policies in epidemiological models.Journal of Artificial Intelli- gence Research,71, 479–519
2021
-
[12]
DeAngelis, D. L. & Diaz, S. G. (2019). Decision-making in agent-based modeling: A current review and future prospectus.Frontiers in Ecology and Evolution,6, 237
2019
-
[13]
& Xia, L
Dong, Y., Yu, C. & Xia, L. (2020). Hierarchical reinforcement learning for epidemics intervention
2020
-
[14]
Feng, T ., Xia, T ., Fan, X., Wang, H., Zong, Z. & Li, Y. (2022). Precise mobility intervention for epidemic control using unobservable information via deep reinforcement learning. InProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, (pp. 2882–2892)
2022
-
[15]
Festor, P ., Luise, G., Komorowski, M. & Faisal, A. A. (2021). Enabling risk-aware reinforcement learning for med- ical interventions through uncertainty decomposition.arXiv preprint arXiv:2109.07827
-
[16]
& Xiong, M
Ge, Q., Hu, Z., Zhang, K., Li, S., Lin, W., Jin, L. & Xiong, M. (2020). Recurrent neural reinforcement learning for counterfactual evaluation of public health interventions on the spread of covid-19 in the world.medRxiv
2020
-
[17]
Bayesian Reinforcement Learning: A Survey
Ghavamzadeh, M., Mannor, S., Pineau, J. & Tamar, A. (2016). Bayesian reinforcement learning: A survey.CoRR, abs/1609.04436
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[18]
E., Salako, K
Gnanvi, J. E., Salako, K. V., Kotanmi, G. B. & Kakaï, R. G. (2021). On the reliability of predictions on covid-19 dynamics: A systematic and critical review of modelling techniques.Infectious Disease Modelling,6, 258–272 33 Figure 18:High Vaccine ExperimentDetailed masking, vaccination, shopping and lockdown behavior
2021
-
[19]
& Fookes, C
Goan, E. & Fookes, C. (2020). Bayesian neural networks: An introduction and survey. InCase Studies in Applied Bayesian Data Science, (pp. 45–87). Springer
2020
-
[20]
K., Pujari, B
Hazra, D. K., Pujari, B. S., Shekatkar, S. M., Mozaffer, F., Sinha, S., Guttal, V., Chaudhuri, P . & Menon, G. I. (2021). The indsci-sim model for covid-19 in india.medRxiv
2021
-
[21]
C., Stuart, R
Kerr, C. C., Stuart, R. M., Mistry, D., Abeysuriya, R. G., Rosenfeld, K., Hart, G. R., Núñez, R. C., Cohen, J. A., Selvaraj, P ., Hagedorn, B. et al. (2021). Covasim: an agent-based model of covid-19 dynamics and interventions.PLOS Computational Biology,17(7), e1009149
2021
-
[22]
& Seetharam, D
Khadilkar, H., Ganu, T . & Seetharam, D. P . (2020). Optimising lockdown policies for epidemic control using reinforcement learning.Transactions of the Indian National Academy of Engineering,5(2), 129–132
2020
-
[23]
Kompella, V., Capobianco, R., Jong, S., Browne, J., Fox, S., Meyers, L., Wurman, P . & Stone, P . (2020). Reinforce- ment learning for optimization of covid-19 mitigation policies.arXiv preprint arXiv:2010.10560
-
[24]
H., Ling, L
Kwak, G. H., Ling, L. & Hui, P . (2021). Deep reinforcement learning approaches for global public health strategies for covid-19 pandemic.PloS one,16(5), e0251550
2021
-
[25]
Continuous control with deep reinforcement learning
Lillicrap, T . P ., Hunt, J. J., Pritzel, A., Heess, N., Erez, T ., Tassa, Y., Silver, D. & Wierstra, D. (2015). Continuous control with deep reinforcement learning.arXiv preprint arXiv:1509.02971
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Rashidi, P ., Upchurch Jr, G. R. et al. (2022). Uncertainty-aware deep learning in healthcare: A scoping review. PLOS Digital Health,1(8), e0000085
2022
-
[27]
J., Laber, E
Luckett, D. J., Laber, E. B., Kahkoska, A. R., Maahs, D. M., Mayer-Davis, E. & Kosorok, M. R. (2019). Estimating dynamic treatment regimes in mobile health using v-learning.Journal of the American Statistical Association 34 Figure 19:Low Vaccine ExperimentDetailed masking, vaccination, shopping and lockdown behavior
2019
-
[28]
& Tambe, M
Mate, A., Perrault, A. & Tambe, M. (2021). Risk-aware interventions in public health: Planning with restless multi-armed bandits. InAAMAS, (pp. 880–888)
2021
-
[29]
& Brown, E
Matrajt, L., Eaton, J., Leung, T . & Brown, E. R. (2021). Vaccine optimization for covid-19: Who to vaccinate first? Science Advances,7(6), eabf1374
2021
-
[30]
& Vullikanti, A
Minutoli, M., Sambaturu, P ., Halappanavar, M., Tumeo, A., Kalyananaraman, A. & Vullikanti, A. (2020). Preempt: scalable epidemic interventions using submodular optimization on multi-gpu systems. InSC20: International Conference for High Performance Computing, Networking, Storage and Analysis, (pp. 1–15). IEEE
2020
-
[31]
Nanayakkara, T ., Clermont, G., Langmead, C. J. & Swigon, D. (2022). Unifying cardiovascular modelling with deep reinforcement learning for uncertainty aware control of sepsis treatment.PLOS Digital Health,1(2), e0000012
2022
-
[32]
Q., Mridha, M., Monowar, M
Ohi, A. Q., Mridha, M., Monowar, M. M., Hamid, M. et al. (2020). Exploring optimal control of epidemic spread using reinforcement learning.Scientific reports,10(1), 1–19
2020
-
[33]
B., Concina, D., Portinale, L., Canonico, M., Seys, D., Vanhaecht, K
Payedimarri, A. B., Concina, D., Portinale, L., Canonico, M., Seys, D., Vanhaecht, K. & Panella, M. (2021). Pre- diction models for public health containment measures on covid-19 using artificial intelligence and machine learning: a systematic review.International journal of environmental research and public health,18(9), 4499
2021
-
[34]
Perra, N. (2021). Non-pharmaceutical interventions during the covid-19 pandemic: A review.Physics Reports, 913, 1–52
2021
-
[35]
Puron-Cid, G., Gil-Garcia, J. R. & Luna-Reyes, L. F. (2016). Opportunities and challenges of policy informatics: Tackling complex problems through the combination of open data, technology and analytics.International Journal of Public Administration in the Digital Age (IJPADA),3(2), 66–85 35
2016
-
[36]
& Karaletsos, T
Ritter, H. & Karaletsos, T . (2022). Tyxe: Pyro-based bayesian neural nets for pytorch.Proceedings of Machine Learning and Systems,4, 398–413
2022
-
[37]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P ., Radford, A. & Klimov, O. (2017). Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[38]
Sequeira, P . & Gervasio, M. (2020). Interestingness elements for explainable reinforcement learn- ing: Understanding agents’ capabilities and limitations.Artificial Intelligence,288, 103367. doi: https://doi.org/10.1016/j.artint.2020.103367
- [39]
- [40]
-
[41]
& Mannor, S
Tessler, C., Efroni, Y. & Mannor, S. (2019). Action robust reinforcement learning and applications in continuous control. InInternational Conference on Machine Learning, (pp. 6215–6224). PMLR
2019
-
[42]
& Luong, T
Tolles, J. & Luong, T . (2020). Modeling epidemics with compartmental models.Jama,323(24), 2515–2516 van Veenstra, A. F. & Kotterink, B. (2017). Data-driven policy making: The policy lab approach. In P . Parycek, Y. Charalabidis, A. V. Chugunov, P . Panagiotopoulos, T . A. Pardo, Ø. Sæbø & E. Tambouris (Eds.),Electronic Participation, (pp. 100–111). Cham:...
2020
-
[43]
& Marathe, M
Venkatramanan, S., Lewis, B., Chen, J., Higdon, D., Vullikanti, A. & Marathe, M. (2018). Using data-driven agent- based models for forecasting emerging infectious diseases.Epidemics,22, 43–49
2018
-
[44]
(2022).Advances in Statistical Inference and Policy Optimization for Reinforcement Learning
Wan, R. (2022).Advances in Statistical Inference and Policy Optimization for Reinforcement Learning. Ph.D. thesis, North Carolina State University
2022
-
[45]
& Laber, E
Weltz, J., Volfovsky, A. & Laber, E. B. (2022). Reinforcement learning methods in public health.Clinical thera- peutics,44(1), 139–154
2022
-
[46]
Deterministic Variational Inference for Robust Bayesian Neural Networks
Wu, A., Nowozin, S., Meeds, E., Turner, R. E., Hernandez-Lobato, J. M. & Gaunt, A. L. (2018). Deterministic varia- tional inference for robust bayesian neural networks.arXiv preprint arXiv:1810.03958
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[47]
Wu, C. (2022). Economic impacts of the covid-19 pandemic
2022
-
[48]
& van Dam, K
Yang, L., Iwami, M., Chen, Y., Wu, M. & van Dam, K. H. (2022). Computational decision-support tools for urban design to improve resilience against covid-19 and other infectious diseases: A systematic review.Progress in planning, (p. 100657) 36
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.