Description-Code Inconsistency in Real-world MCP Servers: Measurement, Detection, and Security Implications
Pith reviewed 2026-06-28 05:55 UTC · model grok-4.3
The pith
Nearly 10 percent of tool descriptions provided to LLMs via the Model Context Protocol do not match the actual code behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
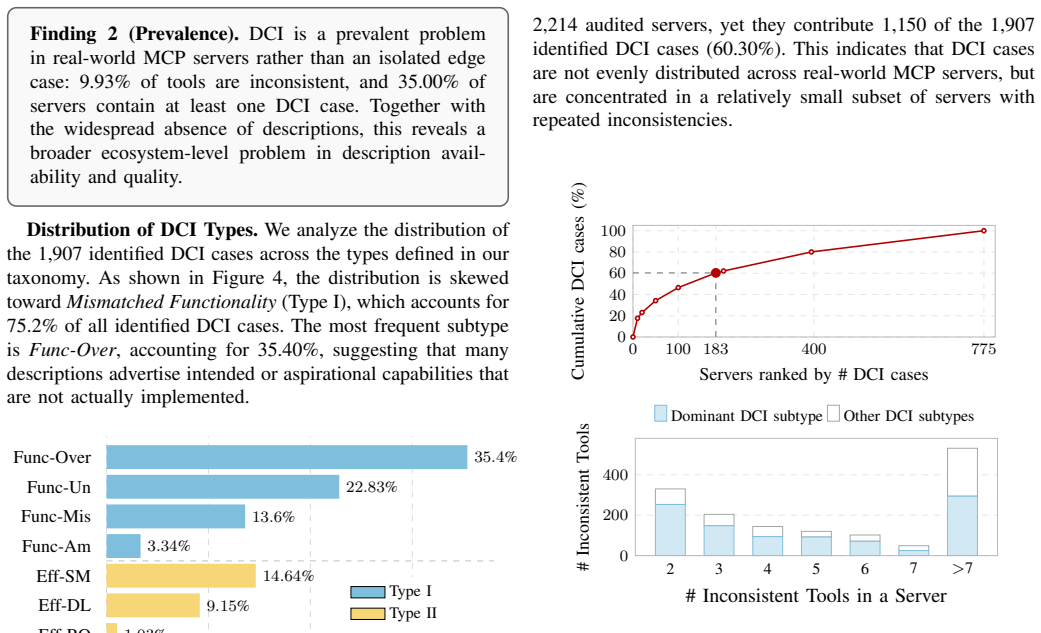
We formally define Description-Code Inconsistency and apply DCIChecker to 19,200 description-code pairs from 2,214 real-world MCP servers, finding that 9.93 percent exhibit inconsistencies spanning functionality gaps and undeclared side effects; these create a defense blind spot that enables risks ranging from operational failures to stealthy malicious behaviors.
What carries the argument
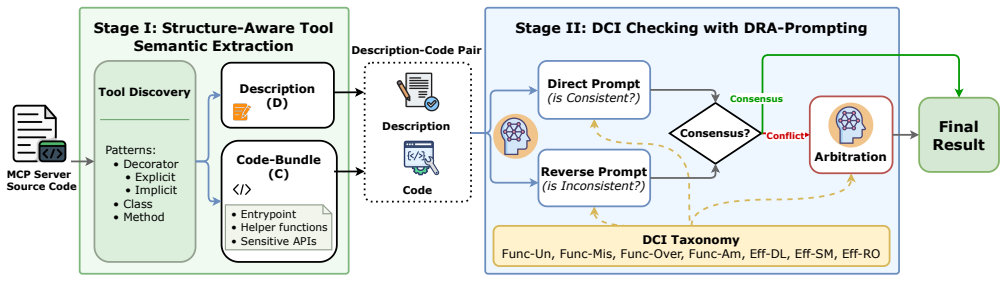
DCIChecker, a framework that combines structure-aware static analysis with Direct-Reverse-Arbitration prompting to cross-validate tool descriptions against code implementations.
If this is right
- MCP servers can silently expose capabilities or side effects that descriptions do not declare.
- LLM agents may select or invoke tools based on misleading information about security boundaries.
- Inconsistencies open pathways for both accidental failures and intentional hidden behaviors.
- Mitigation strategies that enforce semantic consistency between descriptions and code can reduce these risks.
Where Pith is reading between the lines
- Similar description-code gaps likely exist in other tool-calling interfaces used by language models beyond MCP.
- Requiring automated consistency checks at server registration time would shift the burden from LLM runtime to the tool provider.
- The 9.93 percent figure provides a baseline for tracking whether future MCP ecosystem changes reduce or increase the problem.
Load-bearing premise
The combination of static analysis and Direct-Reverse-Arbitration prompting in DCIChecker produces accurate detections of inconsistencies with acceptably low false-positive and false-negative rates.
What would settle it
A manual audit of a random sample of the 9.93 percent flagged pairs to confirm whether the reported inconsistencies actually exist in the code versus the descriptions.
Figures


read the original abstract
The Model Context Protocol (MCP) has emerged as a critical standard empowering Large Language Models (LLMs) to utilize external tools. In this ecosystem, LLMs rely on natural language descriptions provided by MCP servers to select and execute functions. This interaction implicitly assumes that tool descriptions faithfully reflect their underlying implementations, while this assumption is not mandatorily verified in practice. As a result, MCP deployments may suffer from a problem named Description-Code Inconsistency (DCI), where a tool's description of its capabilities and security boundaries is not consistent with what the code actually does. In this paper, we present a comprehensive study of DCI in real-world MCP servers. We formally define the problem and propose a comprehensive taxonomy spanning functionality inconsistencies and undeclared side effects. Guided by this taxonomy, we develop DCIChecker, an automated framework that combines structure-aware static analysis with the Direct-Reverse-Arbitration prompting method to cross-validate tool descriptions against actual code implementations. We apply this framework to a large-scale dataset comprising 19,200 description-code pairs extracted from 2,214 real-world MCP servers. Our measurement reveals that DCI is widespread, with 9.93% of these pairs exhibiting inconsistencies. We further demonstrate that DCI creates a critical defense blind spot, facilitating varied risks from operational failures to stealthy malicious behaviors. Finally, we propose mitigation strategies to enforce semantic consistency and enhance the reliability of the emerging agentic ecosystem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Description-Code Inconsistency (DCI) is widespread in the Model Context Protocol (MCP) ecosystem, affecting 9.93% of 19,200 description-code pairs extracted from 2,214 real-world MCP servers. It defines DCI, introduces a taxonomy of functionality inconsistencies and undeclared side effects, presents the DCIChecker framework (static analysis plus Direct-Reverse-Arbitration prompting) for automated detection, demonstrates security risks from operational failures to stealthy malicious behaviors, and proposes mitigation strategies.
Significance. If the 9.93% prevalence and detection accuracy hold, the work quantifies a previously unmeasured consistency gap in an emerging LLM-tool interaction standard, highlighting a defense blind spot with concrete security implications. The taxonomy and DCIChecker approach could inform future verification standards or tooling for agentic systems.
major comments (1)
- [Measurement section] Measurement / methods section: The headline 9.93% prevalence is produced by applying DCIChecker to the full 19,200-pair corpus, yet the manuscript supplies no ground-truth subset, inter-rater agreement, precision/recall figures, or false-positive evaluation on real MCP description-code pairs. Without these, systematic over-flagging by the LLM arbitration step cannot be ruled out and directly scales the reported rate.
minor comments (1)
- [Abstract] Abstract and §3: Dataset construction details (selection criteria for the 2,214 servers, extraction method for the 19,200 pairs, and any filtering steps) are referenced only at high level; adding these would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on validation of the measurement results. We address the concern directly below and commit to revisions that strengthen the empirical claims without altering the core findings.
read point-by-point responses
-
Referee: [Measurement section] Measurement / methods section: The headline 9.93% prevalence is produced by applying DCIChecker to the full 19,200-pair corpus, yet the manuscript supplies no ground-truth subset, inter-rater agreement, precision/recall figures, or false-positive evaluation on real MCP description-code pairs. Without these, systematic over-flagging by the LLM arbitration step cannot be ruled out and directly scales the reported rate.
Authors: We agree that the current manuscript lacks an explicit ground-truth evaluation, inter-rater agreement statistics, and precision/recall figures on real MCP pairs, which leaves open the possibility of systematic bias from the LLM arbitration component. The framework mitigates this through structure-aware static analysis that constrains the LLM prompts, but this design choice alone does not substitute for reported validation metrics. In the revised version we will add a dedicated validation subsection that reports: (1) a manually labeled ground-truth subset of 300 randomly sampled description-code pairs with two independent annotators, (2) Cohen’s kappa for inter-rater agreement, and (3) precision, recall, and false-positive rate of DCIChecker against these labels. These additions will allow readers to quantify any over-flagging and will be placed immediately before the headline prevalence result. revision: yes
Circularity Check
No circularity: pure empirical measurement with direct counts
full rationale
The paper is an empirical measurement study. It defines DCI, builds a detector (DCIChecker) via static analysis plus prompting, applies it to 19,200 real-world pairs, and reports the observed 9.93% inconsistency rate as a direct count. No derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes appear in the provided text. The central claim reduces only to the output of the applied tool on external data, with no reduction by construction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Natural-language tool descriptions can be meaningfully compared to extracted code behavior via static analysis and LLM prompting
- domain assumption The collected set of 2,214 MCP servers is representative of real-world deployments
Reference graph
Works this paper leans on
-
[1]
S. Abdelnabi, K. Greshake, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real- world LLM-integrated applications with indirect prompt injection,” inProceedings of the 16th ACM Workshop on Artificial Intelligence and Security, ser. AISec ’23. Copenhagen, Denmark: Association for Computing Machinery, 2023, pp. 79–...
-
[2]
Prompt injection attack against LLM-integrated applications,
Y . Liu, G. Deng, Y . Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y . Liu, H. Wang, Y . Zheng, L. Y . Zhang, and Y . Liu, “Prompt injection attack against LLM-integrated applications,” 2023, last revised 29 Dec 2025. [Online]. Available: https://arxiv.org/abs/2306.05499
Pith/arXiv arXiv 2023
-
[3]
MCP Security Notification: Tool Poisoning Attacks,
L. Beurer-Kellner and M. Fischer, “MCP Security Notification: Tool Poisoning Attacks,” Invariant Labs blog, Apr. 2025, accessed: 2026-04-
2025
-
[4]
Available: https://invariantlabs.ai/blog/mcp-security-notif ication-tool-poisoning-attacks
[Online]. Available: https://invariantlabs.ai/blog/mcp-security-notif ication-tool-poisoning-attacks
-
[5]
MCPTox: A benchmark for tool poisoning attack on real-world MCP servers,
Z. Wang, Y . Gao, Y . Wang, S. Liu, H. Sun, H. Cheng, G. Shi, H. Du, and X. Li, “MCPTox: A benchmark for tool poisoning attack on real-world MCP servers,” 2025. [Online]. Available: https://arxiv.org/abs/2508.14925
arXiv 2025
-
[6]
Towards understanding sycophancy in language models,
M. Sharma, M. Tong, T. Korbak, D. Duvenaud, A. Askell, S. R. Bowman, N. Cheng, E. Durmus, Z. Hatfield-Dodds, S. R. Johnston, S. Kravec, T. Maxwell, S. McCandlish, K. Ndousse, O. Rausch, N. Schiefer, D. Yan, M. Zhang, and E. Perez, “Towards understanding sycophancy in language models,” inThe Twelfth International Conference on Learning Representations, ser...
2024
-
[7]
Survey of hallucination in natural language generation,
Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y . Xu, E. Ishii, Y . J. Bang, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,”ACM Computing Surveys, vol. 55, no. 12, pp. 1–38, Mar
- [8]
-
[9]
Model context protocol speci- fication,
Model Context Protocol Contributors, “Model context protocol speci- fication,” https://modelcontextprotocol.io/specification/latest, 2025, version 2025-11-25. Accessed: 2026-04-29
2025
-
[10]
Agent2Agent (A2A) Protocol,
A2A Project, “Agent2Agent (A2A) Protocol,” GitHub repository and protocol specification, 2025, official open-source project under the Linux Foundation, contributed by Google. Accessed: 2026-04-29. [Online]. Available: https://github.com/a2aproject/A2A
2025
-
[11]
Z. Li, B. Ma, X. Dai, M. Xu, Y . Zhang, B. Yan, and K. Li, “Don’t believe everything you read: Understanding and measuring MCP behavior under misleading tool descriptions,” 2026. [Online]. Available: https://arxiv.org/abs/2602.03580
arXiv 2026
-
[12]
Snyk Agent Scan,
Snyk, “Snyk Agent Scan,” GitHub repository, 2026, security scanner for AI agents, MCP servers, and agent skills. Accessed: 2026-04-29. [Online]. Available: https://github.com/snyk/agent-scan
2026
-
[13]
MCP-Shield: Security scanner for MCP servers,
Rise and Ignite, “MCP-Shield: Security scanner for MCP servers,” GitHub repository, 2025, accessed: 2026-04-29. [Online]. Available: https://github.com/riseandignite/mcp-shield
2025
-
[14]
Semgrep: Lightweight static analysis for many languages,
Semgrep, Inc., “Semgrep: Lightweight static analysis for many languages,” GitHub repository, 2026, accessed: 2026-04-29. [Online]. Available: https://github.com/semgrep/semgrep
2026
-
[15]
Bandit: A tool designed to find common security issues in python code,
PyCQA, “Bandit: A tool designed to find common security issues in python code,” GitHub repository, 2026, accessed: 2026-04-29. [Online]. Available: https://github.com/PyCQA/bandit
2026
-
[16]
A measurement study of Model Context Protocol ecosystem,
H. Guo, Y . Hao, Y . Zhang, M. Xu, P. Lv, J. Chen, and X. Cheng, “A measurement study of Model Context Protocol ecosystem,” 2025. [Online]. Available: https://arxiv.org/abs/2509.25292
arXiv 2025
-
[17]
Securing the model context protocol: Defending LLMs against tool poisoning and adversarial attacks,
S. Jamshidi, K. W. Nafi, A. M. Dakhel, N. Shahabi, F. Khomh, and N. Ezzati-Jivan, “Securing the model context protocol: Defending LLMs against tool poisoning and adversarial attacks,” 2025. [Online]. Available: https://arxiv.org/abs/2512.06556
Pith/arXiv arXiv 2025
-
[18]
MCPSecBench: A systematic security benchmark and playground for testing model context protocols,
Y . Yang, C. Gao, D. Wu, Y . Chen, Y . Li, and S. Wang, “MCPSecBench: A systematic security benchmark and playground for testing model context protocols,” 2025, last revised 12 Feb 2026. [Online]. Available: https://arxiv.org/abs/2508.13220
arXiv 2025
-
[19]
Vetting undesirable behaviors in Android apps with permission use analysis,
Y . Zhang, M. Yang, B. Xu, Z. Yang, G. Gu, P. Ning, X. S. Wang, and B. Zang, “Vetting undesirable behaviors in Android apps with permission use analysis,” inProceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, ser. CCS ’13. New York, NY , USA: Association for Computing Machinery, 2013, pp. 611–622. [Online]. Available: http...
-
[20]
DescribeCtx: Context-aware description synthesis for sensitive behaviors in mobile apps,
S. Yang, Y . Wang, Y . Yao, H. Wang, Y . Ye, and X. Xiao, “DescribeCtx: Context-aware description synthesis for sensitive behaviors in mobile apps,” inProceedings of the 44th International Conference on Software Engineering, ser. ICSE ’22. Pittsburgh, Pennsylvania, USA: Association for Computing Machinery, 2022, pp. 685–697. [Online]. Available: https://d...
-
[21]
Attention: There is an inconsistency between Android permissions and application metadata!
H. Alecakir, B. Can, and S. Sen, “Attention: There is an inconsistency between Android permissions and application metadata!”International Journal of Information Security, vol. 20, no. 6, pp. 797–815, 2021. [Online]. Available: https://doi.org/10.1007/s10207-020-00536-1
-
[22]
What’s done is not what’s claimed: Detecting and interpreting inconsistencies in app behaviors,
C. Yue, K. Chen, Z. Guo, J. Dai, X. Sun, and Y . Yang, “What’s done is not what’s claimed: Detecting and interpreting inconsistencies in app behaviors,” inProceedings of the 2025 Network and Distributed System Security Symposium, ser. NDSS ’25. San Diego, CA, USA: Internet Society, 2025. [Online]. Available: https://www.ndss-symposium.org/ndss-paper/whats...
2025
-
[23]
Large language models for software engineering: A systematic literature review,
X. Hou, Y . Zhao, Y . Liu, Z. Yang, K. Wang, L. Li, X. Luo, D. Lo, J. Grundy, and H. Wang, “Large language models for software engineering: A systematic literature review,” 2023. [Online]. Available: https://arxiv.org/abs/2308.10620
arXiv 2023
-
[24]
LLMs in software security: A survey of vulnerability detection techniques and insights,
Z. Sheng, Z. Chen, S. Gu, H. Huang, G. Gu, and J. Huang, “LLMs in software security: A survey of vulnerability detection techniques and insights,” 2025. [Online]. Available: https://arxiv.org/abs/2502.07049
arXiv 2025
-
[25]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging LLM-as-a-judge with MT-Bench and Chatbot Arena,” inAdvances in Neural Information Processing Systems, vol. 36. New Orleans, LA, USA: Neural Information Processing Systems Foundation, 2023, pp. 46 595–46 623. ...
2023
-
[26]
Improving factuality and reasoning in language models through multiagent debate,
Y . Du, S. Li, A. Torralba, J. B. Tenenbaum, and I. Mordatch, “Improving factuality and reasoning in language models through multiagent debate,” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. Vienna, Austria: PMLR, 2024, pp. 11 733–11 763. [Online]. Available: https://procee...
2024
-
[27]
Encouraging divergent thinking in large language models through multi-agent debate,
T. Liang, Z. He, W. Jiao, X. Wang, Y . Wang, R. Wang, Y . Yang, S. Shi, and Z. Tu, “Encouraging divergent thinking in large language models through multi-agent debate,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 17 889–17 904. [Onl...
2024
-
[28]
Self-refine: Iterative refinement with self-feedback,
A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y . Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” inAdvances in Neural Information Processing Systems, vol. 36. New Orleans, LA, USA: Neural Information Proces...
2023
-
[30]
- SM: Permanent state alteration (writes) when description implies read-only
Type II: Undeclared Side Effects - RO: Excessive resource consumption. - SM: Permanent state alteration (writes) when description implies read-only. - DL: Unauthorized data exfiltration. Evaluation Logic: Focus on the functional alignment. If logic aligns with semantic claims, it is consistent. Ignore style. Scoring Instructions: Consistency Score (0-100)...
-
[31]
- Func-Un: The implementation includes additional functional features not mentioned
Type I: Functionality Inconsistency - Func-Mis: The implementation performs a task unrelated to description. - Func-Un: The implementation includes additional functional features not mentioned. - Func-Over: Description promises capabilities non-existent in code. - Func-Am: Description is too vague to establish a deterministic boundary
-
[32]
Code Implementation
Type II: Undeclared Side Effects - RO: Excessive resource consumption. - SM: Permanent state alteration (writes) when description implies read-only. - DL: Unauthorized data exfiltration. Evaluation Logic: Focus on detecting any evidence where the implementation deviates from or exceeds its descriptive commitments. Scoring Instructions: Inconsistency Score...
-
[33]
- Func-Un: Implementation includes additional functional features not mentioned
Type I: Functionality Inconsistency - Func-Mis: Implementation performs a task unrelated to description. - Func-Un: Implementation includes additional functional features not mentioned. - Func-Over: Description promises capabilities non-existent in code. - Func-Am: Description is too vague to establish a deterministic boundary
-
[34]
- SM: Permanent state alteration (writes) when description implies read-only
Type II: Undeclared Side Effects - RO: Excessive resource consumption. - SM: Permanent state alteration (writes) when description implies read-only. - DL: Unauthorized data exfiltration. Arbitration Logic:
-
[35]
Review the [Code] and [Description] independently before considering either branch’s rationale
-
[36]
Does the alleged inconsistency actually exist? Is it a significant violation or a trivial nitpick?
Analyze the Reverse branch’s rationale. Does the alleged inconsistency actually exist? Is it a significant violation or a trivial nitpick?
-
[37]
Does it reasonably explain the behavior?
Analyze the Direct branch’s rationale. Does it reasonably explain the behavior?
-
[38]
A pair should be marked inconsistent only when the evidence shows a meaningful functional mismatch, an undeclared side effect, or an unfulfilled descriptive commitment
Distinguish semantic violations from non- semantic implementation details. A pair should be marked inconsistent only when the evidence shows a meaningful functional mismatch, an undeclared side effect, or an unfulfilled descriptive commitment
-
[39]
Consistent
Make a final verdict. Output Format: [Verdict]: Choose one: "Consistent" or " Inconsistent". [Confidence]: 0-100 score of your own confidence. [Rationale]: Explain the final decision with clear and concise reasoning. [Type1]: If inconsistent, one Type I type; else blank. [Type2]: If side-effect type, one Type II type; else blank
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.