DeliChess: A Multi-party Dialogue Dataset for Deliberation in Chess Puzzle Solving
Pith reviewed 2026-06-28 05:59 UTC · model grok-4.3
The pith
Group deliberation on chess puzzles yields higher accuracy than individual solving.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
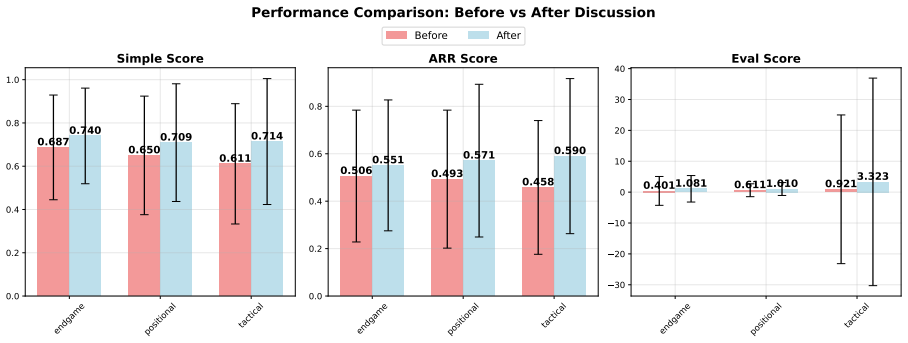
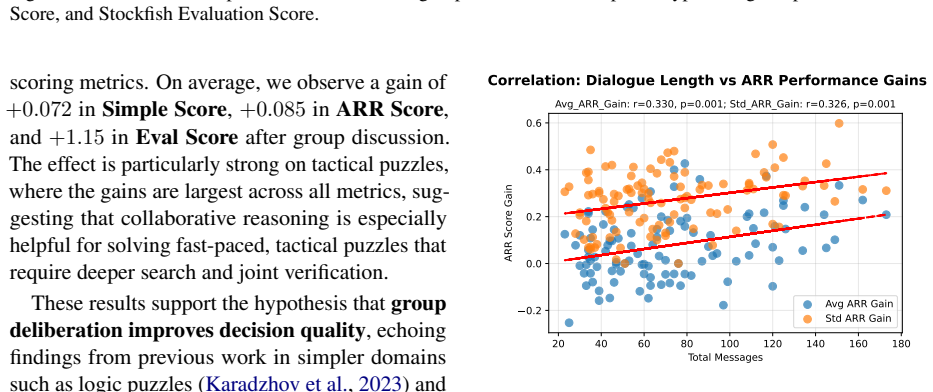
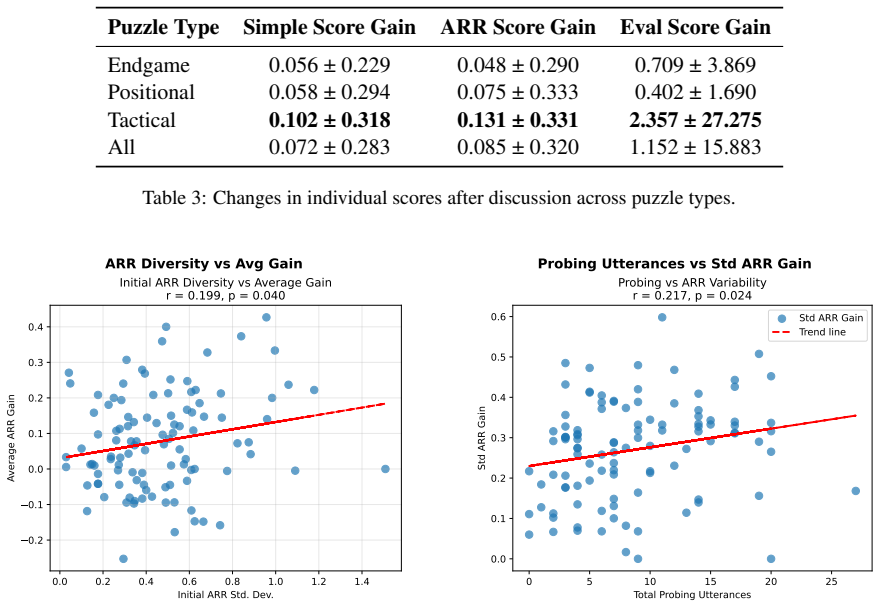
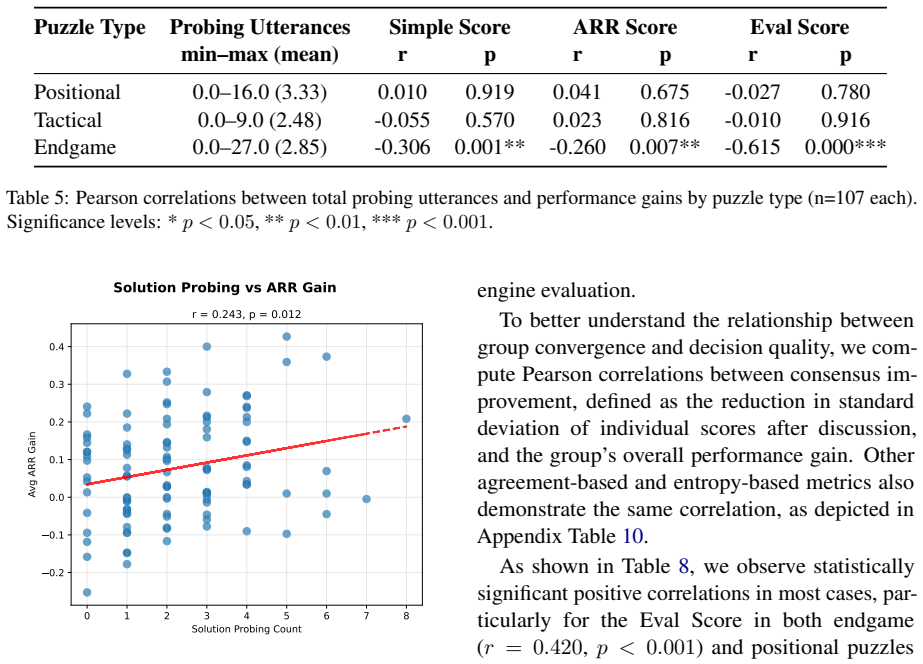
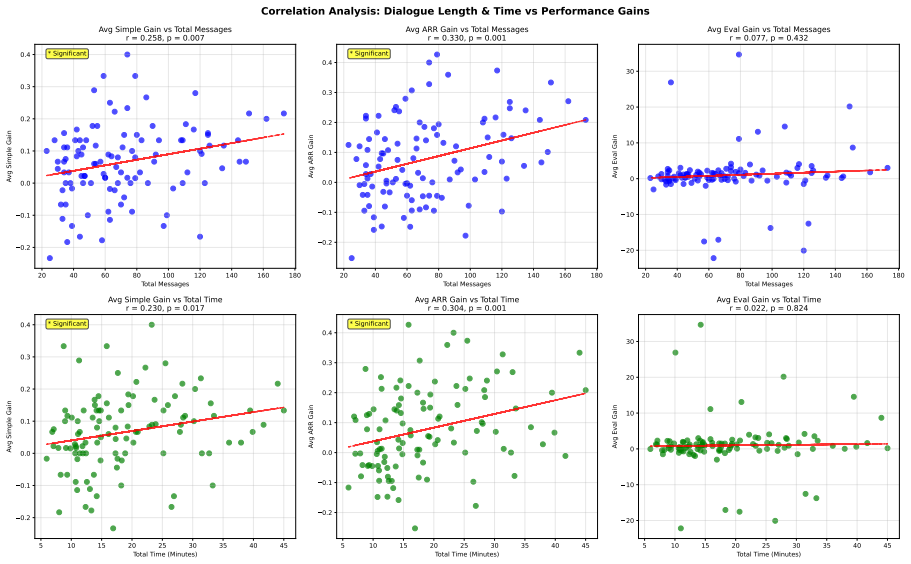
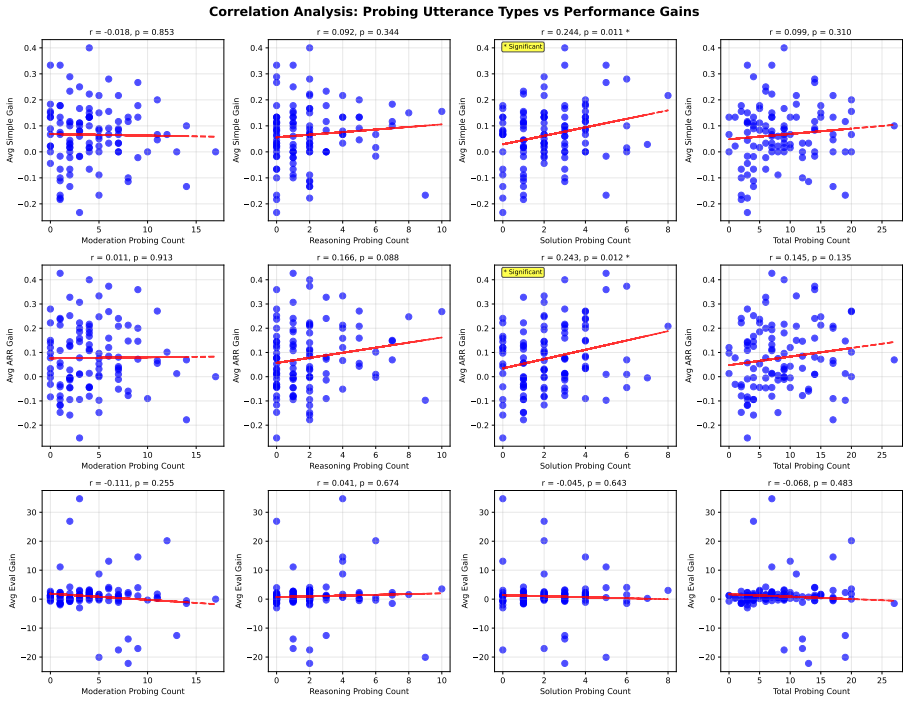
The central discovery is the creation of DeliChess with 107 full dialogue transcripts where groups revise their chess puzzle answers after discussion, demonstrating through engine-based metrics that collective accuracy increases post-deliberation while probing utterances add variability without consistent gains.
What carries the argument
DeliChess dataset of multi-party dialogues on multiple-choice chess puzzles, including pre- and post-discussion choices and metadata, serving as the basis for evaluating deliberation effects.
If this is right
- Deliberation results in better group performance on the puzzles.
- Probing utterances lead to more variable group outcomes.
- The dataset supports research into dialogue dynamics during complex reasoning.
- Differing perspectives are resolved using objective quality indicators from chess engines.
Where Pith is reading between the lines
- The dataset could inspire similar collections for other domains requiring group strategic thinking.
- Findings on probing may inform the design of AI-assisted deliberation tools.
- Extensions could explore how group composition affects the observed accuracy gains.
Load-bearing premise
The chess engine evaluations provide a valid proxy for the correctness of answers to the multiple-choice chess puzzles regardless of difficulty.
What would settle it
Finding a substantial number of puzzles in the dataset where the engine's top move does not match the objectively correct answer as determined by chess experts or exhaustive search.
Figures


read the original abstract
Multi-party dialogue is a critical setting for studying collaborative reasoning and decision-making, yet existing datasets rarely focus on structured, in-depth complex reasoning tasks. We introduce DeliChess, a novel dataset of group deliberation dialogues in which participants collaboratively solve multiple-choice chess puzzles. Each group first completes the puzzle individually, then engages in a multi-party discussion before submitting a revised collective answer. The dataset includes 107 dialogues with full transcripts, pre- and post-discussion choices, and metadata on puzzle difficulty and move quality. We evaluate performance using three metrics based on chess engine evaluations, and find that deliberation significantly improves group accuracy. We further analyse the role of probing utterances (i.e., messages that elicit proposals, justifications, or strategic reflection) using a classifier trained on prior deliberation data. While probing makes group performance more variable after discussion, it does not consistently lead to better performance. Our dataset offers a rich testbed for modelling group reasoning, dialogue dynamics, and the resolution of differing perspectives and opinions in a well-defined strategic domain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DeliChess, a dataset of 107 multi-party dialogue transcripts in which groups of participants first solve multiple-choice chess puzzles individually and then deliberate to produce a collective answer. It reports that deliberation significantly improves group accuracy when performance is measured by three metrics derived from chess-engine evaluations of move quality, and analyzes the effect of probing utterances via a trained classifier.
Significance. If the engine-based metrics are shown to align with puzzle ground truth, the dataset would provide a useful resource for studying collaborative reasoning, dialogue dynamics, and perspective resolution in a well-defined strategic domain. The empirical claims about deliberation effects and probing utterances would then constitute a modest but concrete contribution to group deliberation research.
major comments (3)
- [Abstract / Evaluation] Abstract and Evaluation section: the central claim that 'deliberation significantly improves group accuracy' rests entirely on three chess-engine metrics (centipawn loss, win-rate, etc.). For multiple-choice puzzles the ground-truth label is the designer-specified option; no correlation, agreement rate, or validation between engine rankings and these labels is reported across difficulty levels. This leaves the metric-validity assumption untested and makes the pre/post improvement claim difficult to interpret.
- [Abstract] Abstract: the statement that deliberation 'significantly improves' accuracy is presented without any mention of statistical tests, effect sizes, sample-size justification (N=107 dialogues), controls for individual baseline performance, or how the three engine metrics were aggregated or weighted. These details are required to assess whether the reported improvement is robust.
- [Analysis of probing utterances] Analysis of probing utterances: the claim that probing 'makes group performance more variable after discussion, [but] does not consistently lead to better performance' is presented without the classifier's accuracy, inter-annotator agreement on the training data, or any ablation showing that the variability effect survives controls for discussion length or puzzle difficulty.
minor comments (1)
- [Abstract] The abstract states that the dataset includes 'metadata on puzzle difficulty and move quality' but does not specify how difficulty was quantified or whether it was balanced across the 107 dialogues.
Simulated Author's Rebuttal
Thank you for your thorough review and valuable suggestions. We address each of the major comments below and will revise the manuscript accordingly to improve clarity and robustness.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the central claim that 'deliberation significantly improves group accuracy' rests entirely on three chess-engine metrics (centipawn loss, win-rate, etc.). For multiple-choice puzzles the ground-truth label is the designer-specified option; no correlation, agreement rate, or validation between engine rankings and these labels is reported across difficulty levels. This leaves the metric-validity assumption untested and makes the pre/post improvement claim difficult to interpret.
Authors: We agree that a direct validation of the engine metrics against the ground-truth labels would enhance interpretability. Our choice of engine-based metrics allows for a nuanced evaluation of move quality, which is particularly relevant in chess where multiple options can have varying degrees of optimality. In the revised manuscript, we will add a section reporting the correlation and agreement rates between engine evaluations and the designer-specified correct answers, including breakdowns by puzzle difficulty levels. revision: yes
-
Referee: [Abstract] Abstract: the statement that deliberation 'significantly improves' accuracy is presented without any mention of statistical tests, effect sizes, sample-size justification (N=107 dialogues), controls for individual baseline performance, or how the three engine metrics were aggregated or weighted. These details are required to assess whether the reported improvement is robust.
Authors: The Evaluation section of the manuscript provides the statistical analyses, including tests for significance, effect sizes, and controls. However, we acknowledge that the abstract should highlight these to make the claims more transparent. We will revise the abstract to include references to the statistical tests performed, the sample size, and a brief note on metric aggregation. Sample-size justification will be added based on the number of dialogues collected. revision: yes
-
Referee: [Analysis of probing utterances] Analysis of probing utterances: the claim that probing 'makes group performance more variable after discussion, [but] does not consistently lead to better performance' is presented without the classifier's accuracy, inter-annotator agreement on the training data, or any ablation showing that the variability effect survives controls for discussion length or puzzle difficulty.
Authors: We agree that providing the performance metrics of the probing classifier and additional controls is essential. The classifier details, including accuracy and inter-annotator agreement, will be reported in the revised version. We will also conduct and report an ablation analysis to verify that the observed variability effect holds after controlling for discussion length and puzzle difficulty. revision: yes
Circularity Check
No circularity: empirical dataset paper with independent measurements
full rationale
The paper constructs a new dialogue dataset and reports pre/post-discussion accuracy changes measured directly against external chess-engine move evaluations on fixed multiple-choice puzzles. No equations, parameter fits, self-definitional loops, or load-bearing self-citations reduce any result to its own inputs by construction. The central empirical claim (deliberation improves group accuracy) rests on observable before/after choices rather than any renamed or fitted quantity, satisfying the self-contained criterion for an empirical dataset release.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2201.10808 , year=
Speed, quality, and the optimal timing of complex decisions: Field evidence , author=. arXiv preprint arXiv:2201.10808 , year=
-
[2]
Behavioral and brain sciences , volume=
Why do humans reason? Arguments for an argumentative theory , author=. Behavioral and brain sciences , volume=. 2011 , publisher=
2011
-
[3]
Thinking & Reasoning , volume=
Collaborative reasoning: Evidence for collective rationality , author=. Thinking & Reasoning , volume=. 1998 , publisher=
1998
-
[4]
Sourcebook for political communication research , pages=
Methods for analyzing and measuring group deliberation , author=. Sourcebook for political communication research , pages=. 2014 , publisher=
2014
-
[5]
Educational Psychologist , volume=
Natural-born arguers: Teaching how to make the best of our reasoning abilities , author=. Educational Psychologist , volume=. 2017 , publisher=
2017
-
[6]
Swiss Political Science Review , volume=
Groups and deliberation , author=. Swiss Political Science Review , volume=. 2007 , publisher=
2007
-
[7]
Hastings Cent Rep , volume=
What is public deliberation , author=. Hastings Cent Rep , volume=
-
[8]
Journal of management , volume=
Structured conflict and consensus outcomes in group decision making , author=. Journal of management , volume=. 1995 , publisher=
1995
-
[9]
, title =
Haghtalab, Nika and et al. , title =. Proceedings of the National Academy of Sciences , volume =. 2023 , doi =
2023
-
[10]
arXiv preprint arXiv:2506.02533 , year =
Behrendt, Maike and Wagner, Stefan Sylvius and Weinmann, Carina and Bormann, Marike and Warne, Mira and Harmeling, Stefan , title =. arXiv preprint arXiv:2506.02533 , year =
-
[11]
arXiv preprint arXiv:2402.01427 , year=
The effect of diversity on group decision-making , author=. arXiv preprint arXiv:2402.01427 , year=
-
[12]
Proceedings of the ACM on Human-Computer Interaction , volume=
Delidata: A dataset for deliberation in multi-party problem solving , author=. Proceedings of the ACM on Human-Computer Interaction , volume=. 2023 , publisher=
2023
-
[13]
Quarterly journal of experimental psychology , volume=
Reasoning about a rule , author=. Quarterly journal of experimental psychology , volume=. 1968 , publisher=
1968
-
[14]
arXiv preprint arXiv:2101.10917 , year=
I beg to differ: A study of constructive disagreement in online conversations , author=. arXiv preprint arXiv:2101.10917 , year=
-
[15]
Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Movie-DiC: a movie dialogue corpus for research and development , author=. Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[16]
A Repository of Conversational Datasets , year =
Matthew Henderson and Pawe. A Repository of Conversational Datasets , year =. Proceedings of the Workshop on
-
[17]
2025 , eprint=
Collaborative Evaluation of Deepfake Text with Deliberation-Enhancing Dialogue Systems , author=. 2025 , eprint=
2025
-
[18]
Stockfish : a free and open-source UCI chess engine
The Stockfish developers. Stockfish : a free and open-source UCI chess engine. 2025
2025
-
[19]
arXiv preprint arXiv:2502.17419 , year=
From system 1 to system 2: A survey of reasoning large language models , author=. arXiv preprint arXiv:2502.17419 , year=
-
[20]
arXiv preprint arXiv:2501.09686 , year=
Towards Large Reasoning Models: A Survey of Reinforced Reasoning with Large Language Models , author=. arXiv preprint arXiv:2501.09686 , year=
-
[21]
The American journal of psychology , volume=
A psychometric analysis of chess expertise , author=. The American journal of psychology , volume=. 2005 , publisher=
2005
-
[22]
Cognition , volume=
Why good thoughts block better ones: The mechanism of the pernicious Einstellung (set) effect , author=. Cognition , volume=. 2008 , publisher=
2008
-
[23]
arXiv preprint arXiv:2207.12035 , year=
What makes you change your mind? An empirical investigation in online group decision-making conversations , author=. arXiv preprint arXiv:2207.12035 , year=
-
[24]
Cognitive psychology , volume=
Inflexibility of experts—Reality or myth? Quantifying the Einstellung effect in chess masters , author=. Cognitive psychology , volume=. 2008 , publisher=
2008
-
[25]
Current Directions in Psychological Science , volume=
The mechanism of the Einstellung (set) effect: A pervasive source of cognitive bias , author=. Current Directions in Psychological Science , volume=. 2010 , publisher=
2010
-
[26]
, author=
Pooling of unshared information in group decision making: Biased information sampling during discussion. , author=. Journal of personality and social psychology , volume=. 1985 , publisher=
1985
-
[27]
arXiv preprint arXiv:2410.12428 , year=
Conformity in large language models , author=. arXiv preprint arXiv:2410.12428 , year=
-
[28]
arXiv preprint arXiv:2402.06782 , year=
Debating with more persuasive llms leads to more truthful answers , author=. arXiv preprint arXiv:2402.06782 , year=
-
[29]
2024 , school=
DEliBots: Deliberation Enhancing Bots , author=. 2024 , school=
2024
-
[30]
, author=
Victims of groupthink: A psychological study of foreign-policy decisions and fiascoes. , author=. 1972 , publisher=
1972
-
[31]
A minority of one against a unanimous majority
Studies of independence and conformity: I. A minority of one against a unanimous majority. , author=. Psychological monographs: General and applied , volume=. 1956 , publisher=
1956
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.