Deterministic Envelopes for Tamed SGLD: Decoupling Stochastic-Gradient Noise and Localizing Taming
Pith reviewed 2026-06-28 04:18 UTC · model grok-4.3
The pith
Taming denominators that depend on the same gradient realization create stationary bias in SGLD, avoided by fixing the denominator first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the taming denominator depends on the same stochastic-gradient realization, it alters the oracle and creates stationary bias; deterministic envelopes fix the denominator beforehand and localize taming, splitting the stationary error into oracle-dependent bias and deterministic error, with a far-tail condition explaining limitations of local soft envelopes and motivating hybrid members with hard-tail control.
What carries the argument
Deterministic envelopes that fix the taming denominator before sampling the stochastic gradient noise and localize stabilization to typical regions.
If this is right
- The stationary error splits into bias from oracle-dependent taming and error from deterministic stabilization.
- Local soft envelopes are limited by far-tail conditions.
- Hybrid soft-in-typical with hard-tail control stabilizes rare excursions.
- Experiments show bias reduction with deterministic-envelope designs.
Where Pith is reading between the lines
- This decoupling could be applied to other tamed stochastic approximation methods beyond SGLD.
- Testing the hybrid in problems with heavier tails would verify the far-tail motivation.
- The bias decomposition suggests measuring oracle dependence in practice to quantify distortion.
Load-bearing premise
Fixing the denominator before sampling the oracle noise preserves the stabilizing effect without introducing new uncontrolled errors in the typical region or requiring unverifiable far-tail bounds.
What would settle it
Comparing the stationary distribution mean or variance under gradient-dependent taming versus the proposed deterministic envelope to see if bias disappears as predicted.
Figures

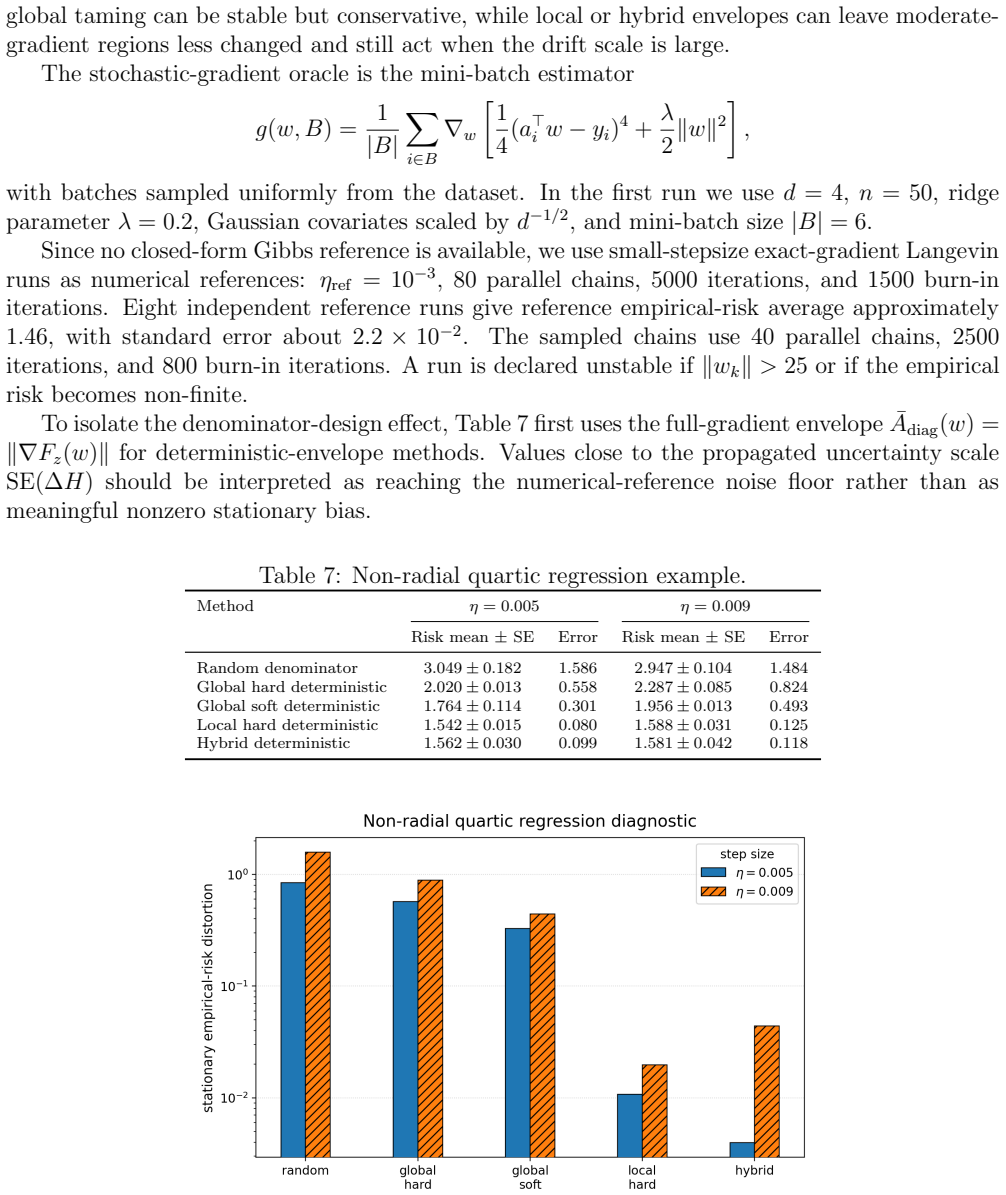
read the original abstract
Stochastic-gradient Langevin algorithms often use tamed denominators to stabilize non-globally Lipschitz drifts. This paper shows that when the denominator depends on the same stochastic-gradient realization as the numerator, the taming step changes the stochastic oracle itself and can create a stationary bias even if the original stochastic gradient is unbiased. We propose a structure-preserving framework for designing tamed denominators. It fixes the denominator before the oracle noise is sampled and uses localized deterministic envelopes to avoid unnecessary taming in typical regions. These kernels keep the stabilizing effect of taming while avoiding the bias introduced by a gradient-dependent denominator. Our theory explains how the stationary error splits into the bias caused by oracle-dependent taming and the remaining error introduced by deterministic stabilization. Within this deterministic-envelope family, the analysis identifies a far-tail condition that explains the limitation of local soft envelopes and motivates a hybrid member: soft in the typical region, but protected by hard-tail control on rare excursions. Experiments confirm the predicted stationary distortions of random denominators, the bias reduction of deterministic-envelope designs, and the stabilizing effect of the hybrid construction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that taming denominators in SGLD that depend on the same stochastic-gradient realization introduce stationary bias even when the underlying gradient is unbiased. It proposes fixing the denominator before sampling the oracle and using localized deterministic envelopes (with a hybrid soft-hard member) to localize taming, preserve stability, and avoid this bias. The theory decomposes stationary error into oracle-dependent bias and deterministic-envelope error; experiments are reported to confirm the predicted distortions and bias reductions.
Significance. If the central decomposition and bias-avoidance claims hold under the stated assumptions, the work supplies a structure-preserving design principle for tamed SGLD that separates the effects of stochastic noise from stabilization, which could guide algorithm construction in non-globally Lipschitz regimes common to deep learning. The explicit error split and the hybrid-envelope construction are concrete contributions that could be tested further.
major comments (1)
- [Abstract] Abstract: the far-tail condition invoked to motivate the hybrid envelope is stated as sufficient for the analysis, yet the manuscript leaves open whether this condition is automatically satisfied or checkable from problem data for concrete loss functions; without such verification the hybrid member risks reintroducing the very tail-control problem the deterministic-envelope framework was intended to localize.
minor comments (1)
- The abstract states that experiments confirm the predictions but supplies no dataset details, error-bar information, or quantitative measures of bias reduction; adding these would strengthen the empirical section without altering the central claims.
Simulated Author's Rebuttal
We thank the referee for the detailed reading and the constructive observation on the far-tail condition. The comment correctly identifies a point where additional clarification would strengthen the presentation. We address it directly below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the far-tail condition invoked to motivate the hybrid envelope is stated as sufficient for the analysis, yet the manuscript leaves open whether this condition is automatically satisfied or checkable from problem data for concrete loss functions; without such verification the hybrid member risks reintroducing the very tail-control problem the deterministic-envelope framework was intended to localize.
Authors: We agree that the manuscript would benefit from an explicit statement on how the far-tail condition can be verified from problem data. The condition is a growth restriction on the deterministic envelope itself (specifically, that its hard component dominates the loss gradient for ||x|| larger than a data-dependent radius R), rather than a property that must be re-checked for each loss. In the revised version we will add a short paragraph after the definition of the hybrid envelope (new Section 3.3) showing that the condition reduces to a simple comparison of the envelope's tail exponent against the known polynomial growth order of the loss, which is routinely available for standard deep-learning objectives. We will also include a brief numerical check on a quadratic-plus-logistic loss confirming that the chosen hard envelope satisfies the inequality for all ||x|| > R with R computed from the data scale. This addition keeps the localization property intact and does not reintroduce uncontrolled tails, because the hard component is applied only outside the typical region already controlled by the soft envelope. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The provided abstract and description present a structure-preserving framework that fixes the denominator before sampling oracle noise, then splits stationary error into oracle-dependent bias versus deterministic-envelope error. No equations, definitions, or self-citations are exhibited that reduce any claimed result (bias split, far-tail condition, or hybrid construction) to a tautology or fitted input by construction. The far-tail condition is invoked as a sufficient analytic assumption rather than derived from the paper's own outputs, and the hybrid member is motivated as an extension rather than forced by prior self-citation. The central claims therefore remain independent of the inputs they analyze, satisfying the default expectation of non-circularity.
Axiom & Free-Parameter Ledger
invented entities (2)
-
localized deterministic envelopes
no independent evidence
-
hybrid soft-hard envelope
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Deterministic Denominator Design for Localized Tamed Stochastic-Gradient Langevin Dynamics
Develops proxy-quantile deterministic denominator designs for localized tamed SGLD that track errors via a conditional perturbation bridge and outperform basic deterministic taming in experiments.
Reference graph
Works this paper leans on
-
[1]
Welling and Y
M. Welling and Y. W. Teh. Bayesian learning via stochastic gradient Langevin dynamics. In Proceedings of the 28th International Conference on Machine Learning, pages 681–688, 2011
2011
-
[2]
Y. W. Teh, A. H. Thiery, and S. J. Vollmer. Consistency and fluctuations for stochastic gradient Langevin dynamics.Journal of Machine Learning Research, 17(7):1–33, 2016
2016
-
[3]
S. J. Vollmer, K. C. Zygalakis, and Y. W. Teh. Exploration of the (non-)asymptotic bias and variance of stochastic gradient Langevin dynamics.Journal of Machine Learning Research, 17(159):1–48, 2016
2016
-
[4]
Raginsky, A
M. Raginsky, A. Rakhlin, and M. Telgarsky. Non-convex learning via stochastic gradient Langevin dynamics: a nonasymptotic analysis. InProceedings of the 2017 Conference on Learning Theory, volume 65 ofProceedings of Machine Learning Research, pages 1674–1703. PMLR, 2017
2017
-
[5]
A. Durmus and E. Moulines. Nonasymptotic convergence analysis for the unadjusted Langevin algorithm.Annals of Applied Probability, 27(3):1551–1587, 2017. doi:10.1214/16-AAP1238
-
[6]
A. S. Dalalyan and A. G. Karagulyan. User-friendly guarantees for the Langevin Monte Carlo with inaccurate gradient.Stochastic Processes and their Applications, 129(12):5278– 5311, 2019. doi:10.1016/j.spa.2019.02.016
-
[7]
S. P. Meyn and R. L. Tweedie.Markov Chains and Stochastic Stability. Springer, 1993
1993
-
[8]
G. O. Roberts and R. L. Tweedie. Exponential convergence of Langevin distributions and their discrete approximations.Bernoulli, 2(4):341–363, 1996. doi:10.2307/3318418
-
[9]
J. C. Mattingly, A. M. Stuart, and D. J. Higham. Ergodicity for SDEs and approximations: locally Lipschitz vector fields and degenerate noise.Stochastic Processes and their Applica- tions, 101(2):185–232, 2002. doi:10.1016/S0304-4149(02)00150-3
-
[10]
D. Talay and L. Tubaro. Expansion of the global error for numerical schemes solving stochastic differential equations.Stochastic Analysis and Applications, 8(4):483–509, 1990. doi:10.1080/07362999008809220
-
[11]
J. C. Mattingly, A. M. Stuart, and M. V. Tretyakov. Convergence of numerical time-averaging and stationary measures via Poisson equations.SIAM Journal on Numerical Analysis, 48(2):552–577, 2010. doi:10.1137/090770527
-
[12]
Entropic repulsion and the maximum of the two-dimensional harmonic crystal
E. Pardoux and A. Yu. Veretennikov. On the Poisson equation and diffusion approximation. I.Annals of Probability, 29(3):1061–1085, 2001. doi:10.1214/aop/1015345596
-
[13]
Gilbarg and N
D. Gilbarg and N. S. Trudinger.Elliptic Partial Differential Equations of Second Order. Classics in Mathematics. Springer, 2001. 39
2001
-
[14]
M. Hutzenthaler, A. Jentzen, and P. E. Kloeden. Strong and weak divergence in finite time of Euler’s method for stochastic differential equations with non-globally Lipschitz continuous coefficients.Proceedings of the Royal Society A, 467(2130):1563–1576, 2011. doi:10.1098/rspa.2010.0348
-
[15]
M. Hutzenthaler, A. Jentzen, and P. E. Kloeden. Strong convergence of an explicit numeri- cal method for SDEs with non-globally Lipschitz continuous coefficients.Annals of Applied Probability, 22(4):1611–1641, 2012. doi:10.1214/11-AAP803
-
[16]
S. Sabanis. A note on tamed Euler approximations.Electronic Communications in Probability, 18:1–10, 2013. doi:10.1214/ECP.v18-2824
-
[17]
S. Sabanis. Euler approximations with varying coefficients: the case of superlinearly growing diffusion coefficients.Annals of Applied Probability, 26(4):2083–2105, 2016. doi:10.1214/15- AAP1140
work page doi:10.1214/15- 2083
-
[18]
X. Mao. The truncated Euler–Maruyama method for stochastic differential equa- tions.Journal of Computational and Applied Mathematics, 290:370–384, 2015. doi:10.1016/j.cam.2015.06.002
-
[19]
N. Brosse, A. Durmus, E. Moulines, and S. Sabanis. The tamed unadjusted Langevin algorithm.Stochastic Processes and their Applications, 129(10):3638–3663, 2019. doi:10.1016/j.spa.2018.10.002
-
[20]
M. Eisenmann and T. Stillfjord. Sublinear convergence of a tamed stochastic gradient de- scent method in Hilbert space.SIAM Journal on Optimization, 32(3):1642–1667, 2022. doi:10.1137/21M1427450
-
[21]
A. Lovas, I. Lytras, M. R´ asonyi, and S. Sabanis. Taming neural networks with TUSLA: Nonconvex learning via adaptive stochastic gradient Langevin algorithms.SIAM Journal on Mathematics of Data Science, 5(2):323–345, 2023. doi:10.1137/22M1514283
-
[22]
D.-Y. Lim, A. Neufeld, S. Sabanis, and Y. Zhang. Non-asymptotic estimates for TUSLA algorithm for non-convex learning with applications to neural networks with ReLU activation function.IMA Journal of Numerical Analysis, 44(3):1464–1559, 2024. doi:10.1093/imanum/drad038. 40
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.