Do Models Share Safety Representations? Cross-Model Steering for Safe Visual Generation
Pith reviewed 2026-06-28 06:13 UTC · model grok-4.3
The pith
Safety directions estimated in one model transfer to others via benign-data alignment, matching native performance without target unsafe data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
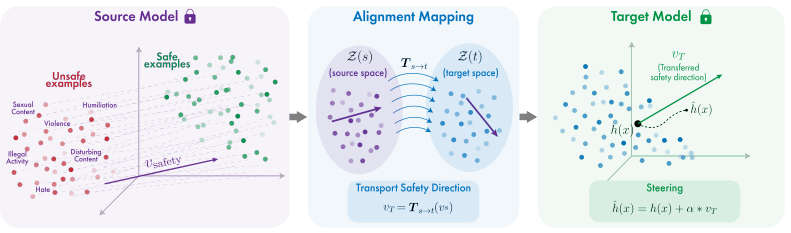
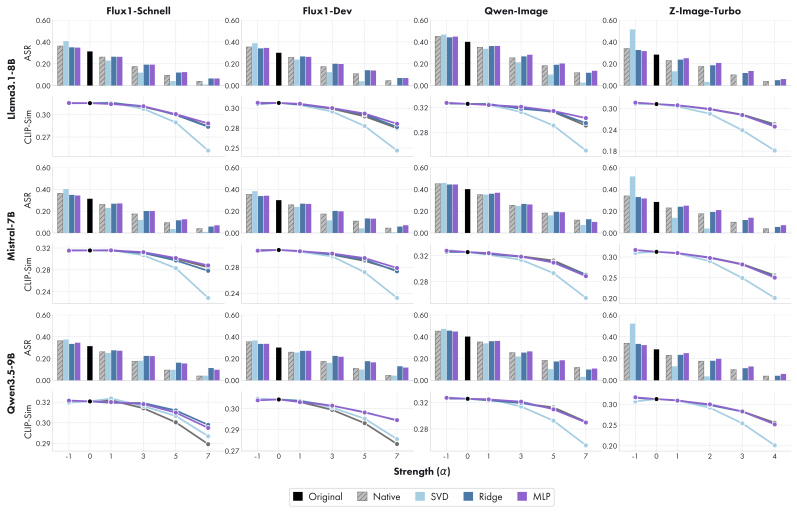
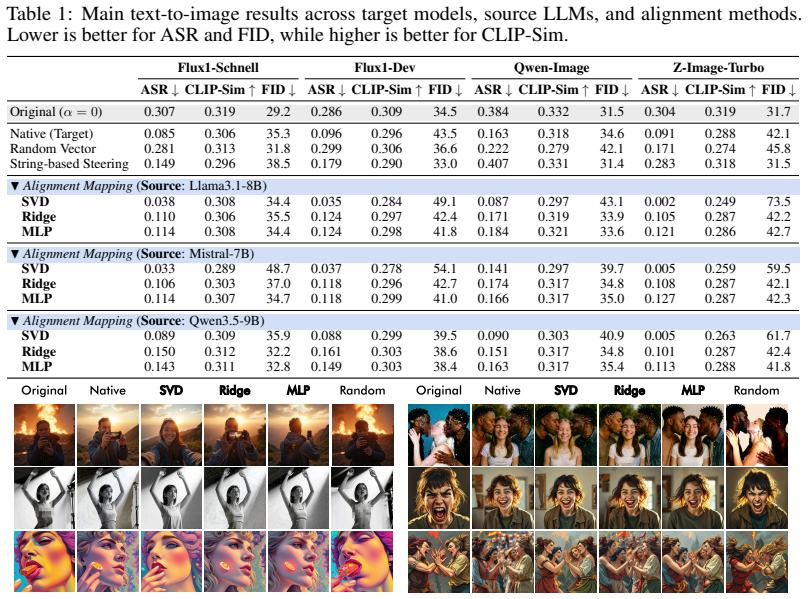
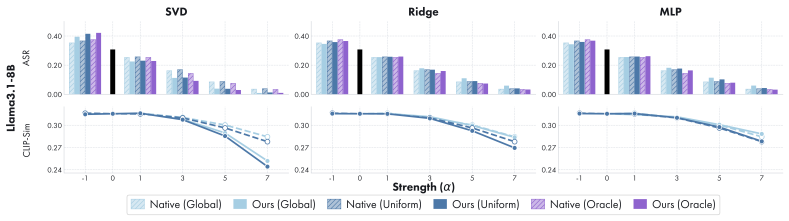
Safety can be represented as a portable latent direction learned in a source LLM from paired safe-unsafe prompts, transported to a target generator through a lightweight alignment fitted on benign data alone, and applied at inference time, yielding ASR reductions and CLIP-Score/FID trade-offs comparable to native directions while requiring no target-side unsafe data.
What carries the argument
Cross-model safety steering pipeline that estimates a safety direction in the source LLM and transports it to the target generator via lightweight benign-data alignment for inference-time application, with an optional multi-vector extension for category-specific control.
If this is right
- Transferred directions achieve ASR reduction comparable to directions learned natively on the target using unsafe data.
- Generation quality measured by CLIP-Score and FID remains comparable to native steering.
- The multi-vector extension enables selective, category-specific safety control.
- Safety control becomes possible for target models when unsafe data cannot be collected or used.
Where Pith is reading between the lines
- Safety mechanisms could be pre-computed once and reused across many closed or restricted generators.
- The approach might reduce the need for repeated unsafe-data collection when new architectures appear.
- Direct geometry matching without the alignment step could be tested as a simpler alternative.
Load-bearing premise
A lightweight alignment fitted only on benign data is enough to map the safety direction from the source model to the target without any unsafe target examples.
What would settle it
Applying the transported direction to the target model produces no measurable drop in attack success rate relative to the unsteered baseline, or the quality trade-off becomes markedly worse than the native baseline.
Figures

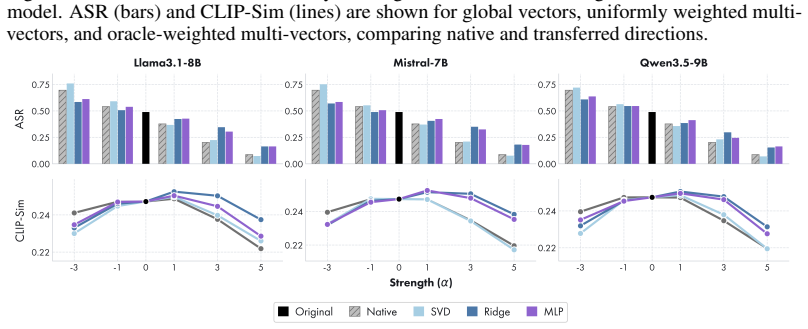
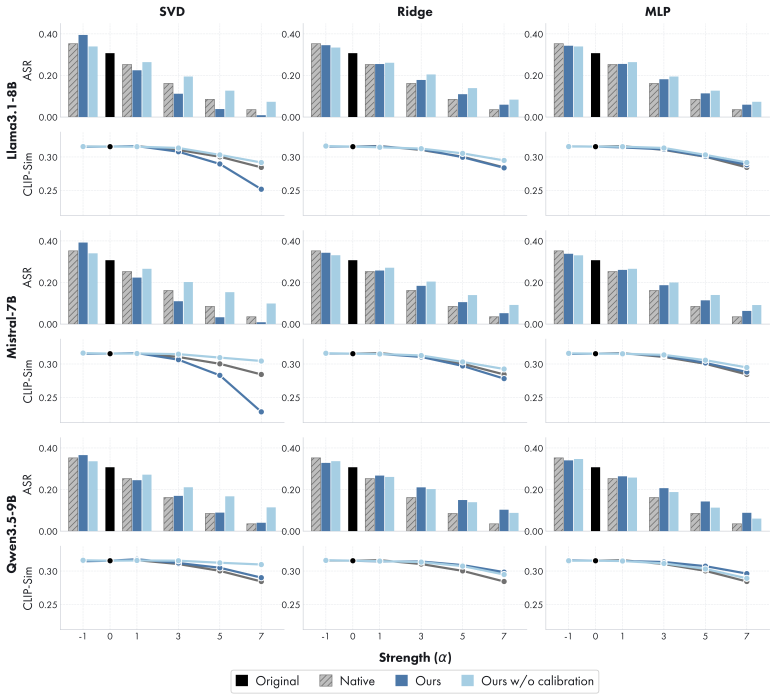







read the original abstract
Recent progress in generative modeling has made safety control a central challenge, yet existing approaches remain largely model-specific, requiring retraining or tailored interventions for each new architecture. In this work, we ask whether safety can be represented as a portable latent direction, learned once and reused across heterogeneous generators. We introduce the first framework for cross-model safety steering, in which a safety direction is estimated in a source LLM from paired safe-unsafe prompts, transported to a target generator through a lightweight alignment fitted on benign data alone, and applied at inference time. Crucially, our pipeline never accesses unsafe data on the target side, isolating whether safety can be transferred through shared representation geometry. Beyond a single global direction, we also identify a multi-vector extension that captures category-specific safety behaviors, enabling more selective control. We evaluate our approach in text-to-image and text-to-video generation across diverse source-target model pairs. Across models, transferred safety directions achieve ASR reduction and CLIP-Score/FID trade-offs comparable to directions learned natively on the target model using unsafe data, while requiring no target-side unsafe data. This indicates that safety improvements do not come at the expense of generation quality. Our results point to a modular view of safety: safety-relevant behavior is not purely model-local, but can be controlled through latent directions that persist across models. This suggests a new path toward lightweight, reusable safety mechanisms that do not require target-side unsafe data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a safety direction estimated in a source LLM from paired safe/unsafe text prompts can be transported to a target visual generator (text-to-image or text-to-video) via a lightweight linear or low-rank alignment learned solely on benign data; the transferred direction, when applied at inference, yields ASR reductions and CLIP-Score/FID trade-offs comparable to directions learned natively on the target using unsafe data, across multiple source-target model pairs, without any target-side unsafe data. A multi-vector extension for category-specific control is also introduced.
Significance. If the central claim is supported by the experiments, the work provides evidence that safety-relevant latent directions are portable across heterogeneous generative models, enabling reusable, modular safety interventions that avoid the need to collect or expose unsafe data on each new target. This would be a meaningful advance for scalable safety mechanisms in generative AI.
major comments (2)
- [§3.2] §3.2 (alignment procedure): the claim that the lightweight map fitted on benign data alone suffices to transport the safety contrast estimated from source unsafe pairs is load-bearing for the 'no target unsafe data' result, yet the manuscript provides no verification (e.g., cosine similarity between transported vector and target unsafe contrast, or an ablation where the safety direction is made orthogonal to the benign span) that the map actually preserves the relevant component.
- [§5] §5 (evaluation): the reported comparability of ASR reduction and quality metrics to native target directions is the central empirical support, but the text does not state the number of independent runs, statistical tests, or confidence intervals; without these, it is impossible to determine whether the transferred directions truly match native performance or whether the result is driven by a subset of model pairs.
minor comments (2)
- [Table 1] Table 1 (model pairs): list the exact architectures, parameter counts, and training data regimes for each source-target pair to allow readers to assess heterogeneity.
- [§3.3] Notation: the definition of the safety direction vector (Eq. 3) and the alignment matrix (Eq. 5) should be cross-referenced explicitly when describing the multi-vector extension in §3.3.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (alignment procedure): the claim that the lightweight map fitted on benign data alone suffices to transport the safety contrast estimated from source unsafe pairs is load-bearing for the 'no target unsafe data' result, yet the manuscript provides no verification (e.g., cosine similarity between transported vector and target unsafe contrast, or an ablation where the safety direction is made orthogonal to the benign span) that the map actually preserves the relevant component.
Authors: We agree that explicit verification would strengthen the central claim regarding preservation of the safety component. In the revised manuscript, we will add a diagnostic analysis computing cosine similarity between the transported safety direction and the native target safety direction (estimated solely for verification purposes). We will also include an ablation projecting the transported vector orthogonal to the benign activation span, showing degraded performance and thereby confirming that the alignment preserves the relevant safety information. revision: yes
-
Referee: [§5] §5 (evaluation): the reported comparability of ASR reduction and quality metrics to native target directions is the central empirical support, but the text does not state the number of independent runs, statistical tests, or confidence intervals; without these, it is impossible to determine whether the transferred directions truly match native performance or whether the result is driven by a subset of model pairs.
Authors: We agree that statistical details are necessary to assess reliability. The revised manuscript will state that all metrics are averaged over 5 independent runs with distinct random seeds, report means with standard deviations for ASR, CLIP-Score, and FID, and include paired statistical tests (e.g., t-tests) comparing transferred versus native directions across model pairs to confirm the observed comparability is not driven by outliers. revision: yes
Circularity Check
No circularity: empirical transfer pipeline is self-contained
full rationale
The paper describes an empirical method that estimates a safety direction from source paired prompts, fits a lightweight alignment exclusively on benign target data, and evaluates the transferred steering via separate ASR, CLIP-Score, and FID metrics on held-out generations. No equation or step equates a reported performance quantity to the alignment fit by construction, no self-citation supplies a load-bearing uniqueness theorem or ansatz, and the source/target data separation prevents the results from reducing tautologically to the inputs. The derivation chain therefore remains independent of its own fitting procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Persistent Anti-Muslim Bias in Large Language Models
Abubakar Abid, Maheen Farooqi, and James Zou. Persistent Anti-Muslim Bias in Large Language Models. InACM AIES, 2021
2021
-
[2]
Mitigating Sexual Content Generation via Embedding Distortion in Text-conditioned Diffusion Models
Jaesin Ahn and Heechul Jung. Mitigating Sexual Content Generation via Embedding Distortion in Text-conditioned Diffusion Models. InNeurIPS, 2025
2025
-
[3]
Refusal in Language Models Is Mediated by a Single Direction
Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Panickssery, Wes Gurnee, and Neel Nanda. Refusal in Language Models Is Mediated by a Single Direction. InNeurIPS, 2024
2024
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, et al. Qwen2.5-VL Technical Report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Revisiting Model Stitching to Compare Neural Representations
Yamini Bansal, Preetum Nakkiran, and Boaz Barak. Revisiting Model Stitching to Compare Neural Representations. InNeurIPS, 2021
2021
-
[6]
NudeNet: Neural Nets for Nudity Classification, Detection, and Selective Censor- ing, 2019
P Bedapudi. NudeNet: Neural Nets for Nudity Classification, Detection, and Selective Censor- ing, 2019
2019
-
[7]
Femi Bello, Anubrata Das, Fanzhi Zeng, Fangcong Yin, and Liu Leqi. Linear Representation Transferability Hypothesis: Leveraging Small Models to Steer Large Models.arXiv preprint arXiv:2506.00653, 2025
-
[8]
Abeba Birhane, Vinay Uday Prabhu, and Emmanuel Kahembwe. Multimodal datasets: misog- yny, pornography, and malignant stereotypes.arXiv preprint arXiv:2110.01963, 2021
-
[9]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the Opportunities and Risks of Foundation Models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-Image: An Efficient Image Generation Foundation Model with Single-Stream Diffusion Transformer.arXiv preprint arXiv:2511.22699, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Transferring Linear Features Across Language Models With Model Stitching
Alan Chen, Jack Merullo, Alessandro Stolfo, and Ellie Pavlick. Transferring Linear Features Across Language Models With Model Stitching. InNeurIPS, 2025
2025
-
[12]
Conditioned Activation Transport for T2I Safety Steering
Maciej Chrab ˛ aszcz, Aleksander Szymczyk, Jan Dubi ´nski, Tomasz Trzci ´nski, Franziska Boenisch, and Adam Dziedzic. Conditioned Activation Transport for T2I Safety Steering. arXiv preprint arXiv:2603.03163, 2026
-
[13]
Hyung Won Chung, Noah Constant, Xavier Garcia, Adam Roberts, Yi Tay, Sharan Narang, and Orhan Firat. UniMax: Fairer and More Effective Language Sampling for Large-Scale Multilingual Pretraining.arXiv preprint arXiv:2304.09151, 2023
-
[14]
Scaling rectified flow transform- ers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transform- ers for high-resolution image synthesis. InICML, 2024
2024
-
[15]
Video Unlearning via Low-Rank Refusal Vector
Simone Facchiano, Stefano Saravalle, Matteo Migliarini, Edoardo De Matteis, Alessio Sampieri, Andrea Pilzer, Emanuele Rodolà, Indro Spinelli, Luca Franco, and Fabio Galasso. Video Unlearning via Low-Rank Refusal Vector. InICLR, 2026. 10
2026
-
[16]
SalUn: Em- powering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. SalUn: Em- powering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classification and Generation. InICLR, 2024
2024
-
[17]
Erasing Concepts from Diffusion Models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing Concepts from Diffusion Models. InICCV, 2023
2023
-
[18]
Unified Concept Editing in Diffusion Models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´nska, and David Bau. Unified Concept Editing in Diffusion Models. InWACV, 2024
2024
-
[19]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The Llama 3 Herd of Models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In NeurIPS, 2017
2017
-
[21]
Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers
Chi-Pin Huang, Kai-Po Chang, Chung-Ting Tsai, Yung-Hsuan Lai, Fu-En Yang, and Yu- Chiang Frank Wang. Receler: Reliable Concept Erasing of Text-to-Image Diffusion Models via Lightweight Erasers. InECCV, 2024
2024
-
[22]
Cross-model Transferability among Large Language Models on the Platonic Representations of Concepts
Youcheng Huang, Chen Huang, Duanyu Feng, Wenqiang Lei, and Jiancheng Lv. Cross-model Transferability among Large Language Models on the Platonic Representations of Concepts. In ACL, 2025
2025
-
[23]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The Platonic Representation Hypothesis. InICML, 2024
2024
-
[24]
Harnessing the Universal Geometry of Embeddings.arXiv preprint arXiv:2505.12540, 2025
Rishi Jha, Collin Zhang, Vitaly Shmatikov, and John X Morris. Harnessing the Universal Geometry of Embeddings.arXiv preprint arXiv:2505.12540, 2025
-
[25]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, et al. Mistral 7B.arXiv preprint arXiv:2310.06825, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
FLUX.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. FLUX.https://github.com/black-forest-labs/flux, 2024
2024
-
[27]
Understanding Image Representations by Measuring Their Equivariance and Equivalence
Karel Lenc and Andrea Vedaldi. Understanding Image Representations by Measuring Their Equivariance and Equivalence. InCVPR, 2015
2015
-
[28]
Microsoft COCO: Common Objects in Context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft COCO: Common Objects in Context. In ECCV, 2014
2014
-
[29]
SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation
Runtao Liu, Chen I Chieh, Jindong Gu, Jipeng Zhang, Renjie Pi, Qifeng Chen, Philip Torr, Ashkan Khakzar, and Fabio Pizzati. SafetyDPO: Scalable Safety Alignment for Text-to-Image Generation. InICCV, 2025
2025
-
[30]
Latent Guard: a Safety Framework for Text-to-image Generation
Runtao Liu, Ashkan Khakzar, Jindong Gu, Qifeng Chen, Philip Torr, and Fabio Pizzati. Latent Guard: a Safety Framework for Text-to-image Generation. InECCV, 2024
2024
-
[31]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InICLR, 2019
2019
-
[32]
MACE: Mass Concept Erasure in Diffusion Models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. MACE: Mass Concept Erasure in Diffusion Models. InCVPR, 2024
2024
-
[33]
One-dimensional Adapter to Rule Them All: Concepts Diffusion Models and Erasing Applications
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional Adapter to Rule Them All: Concepts Diffusion Models and Erasing Applications. InCVPR, 2024
2024
-
[34]
Pointer Sentinel Mixture Models
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer Sentinel Mixture Models.arXiv preprint arXiv:1609.07843, 2016. 11
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[35]
T2VSafetyBench: Evaluating the Safety of Text-to-Video Generative Models
Yibo Miao, Yifan Zhu, Lijia Yu, Jun Zhu, Xiao-Shan Gao, and Yinpeng Dong. T2VSafetyBench: Evaluating the Safety of Text-to-Video Generative Models. InNeurIPS, 2024
2024
-
[36]
Activation Space Interventions Can Be Transferred Between Large Language Models
Narmeen Fatimah Oozeer, Dhruv Nathawani, Nirmalendu Prakash, Michael Lan, Abir Harrasse, and Amir Abdullah. Activation Space Interventions Can Be Transferred Between Large Language Models. InICML, 2025
2025
-
[37]
The Linear Representation Hypothesis and the Geometry of Large Language Models
Kiho Park, Yo Joong Choe, and Victor Veitch. The Linear Representation Hypothesis and the Geometry of Large Language Models. InICML, 2024
2024
-
[38]
Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models
Samuele Poppi, Tobia Poppi, Federico Cocchi, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. Safe-CLIP: Removing NSFW Concepts from Vision-and-Language Models. In ECCV, 2024
2024
-
[39]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents, 2026
Qwen Team. Qwen3.5: Accelerating Productivity with Native Multimodal Agents, 2026
2026
-
[40]
Learning Transferable Visual Models From Natural Language Supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. InICML, 2021
2021
-
[41]
Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.JMLR, 21(140):1–67, 2020
2020
-
[42]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering Llama 2 via Contrastive Activation Addition. InACL, 2024
2024
-
[43]
Controlling Language and Diffusion Models by Transporting Activations
Pau Rodriguez, Arno Blaas, Michal Klein, Luca Zappella, Nicholas Apostoloff, Xavier Suau, et al. Controlling Language and Diffusion Models by Transporting Activations. InICLR, 2025
2025
-
[44]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. InCVPR, 2022
2022
-
[45]
Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting. Safe Latent Diffusion: Mitigating Inappropriate Degeneration in Diffusion Models. InCVPR, 2023
2023
-
[46]
Can Machines Help Us Answering Question 16 in Datasheets, and In Turn Reflecting on Inappropriate Content? In ACM FAccT, 2022
Patrick Schramowski, Christopher Tauchmann, and Kristian Kersting. Can Machines Help Us Answering Question 16 in Datasheets, and In Turn Reflecting on Inappropriate Content? In ACM FAccT, 2022
2022
-
[47]
LAION- 5B: An open large-scale dataset for training next generation image-text models
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. LAION- 5B: An open large-scale dataset for training next generation image-text models. InNeurIPS, 2022
2022
-
[48]
Improving Instruction-Following in Language Models through Activation Steering
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving Instruction-Following in Language Models through Activation Steering. InICLR, 2025
2025
-
[49]
Extracting Latent Steering Vectors from Pretrained Language Models
Nishant Subramani, Nivedita Suresh, and Matthew E Peters. Extracting Latent Steering Vectors from Pretrained Language Models. InACL, 2022
2022
-
[50]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J Vazquez, Ulisse Mini, and Monte MacDiarmid. Steering Language Models With Activation Engineering.arXiv preprint arXiv:2308.10248, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and Advanced Large-Scale Video Generative Models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
Taxonomy of Risks posed by Language Models
Laura Weidinger, Jonathan Uesato, Maribeth Rauh, Conor Griffin, Po-Sen Huang, John Mellor, Amelia Glaese, Myra Cheng, Borja Balle, Atoosa Kasirzadeh, et al. Taxonomy of Risks posed by Language Models. InACM FAccT, 2022. 12
2022
-
[53]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng-ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al. Qwen-Image Technical Report.arXiv preprint arXiv:2508.02324, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[54]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
MMA- Diffusion: MultiModal Attack on Diffusion Models
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu. MMA- Diffusion: MultiModal Attack on Diffusion Models. InCVPR, 2024
2024
-
[56]
From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.TACL, 2:67–78, 2014
Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions.TACL, 2:67–78, 2014
2014
-
[57]
A Survey of Large Language Models
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. A Survey of Large Language Models.arXiv preprint arXiv:2303.18223, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[58]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation Engineering: A Top-Down Approach to AI Transparency.arXiv preprint arXiv:2310.01405, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
a person
Andy Zou, Long Phan, Justin Wang, Derek Duenas, Maxwell Lin, Maksym Andriushchenko, Rowan Wang, Zico Kolter, Matt Fredrikson, and Dan Hendrycks. Improving Alignment and Robustness with Circuit Breakers. InNeurIPS, 2024. 13 A Alignment Mappings In Sec. 3, we introduced a general cross-model mapping Ts→t used to transport safety directions between represent...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.