ReasoningFlow: Discourse Structures for Understanding LLM Reasoning Traces
Pith reviewed 2026-06-28 06:04 UTC · model grok-4.3
The pith
Large reasoning models from different bases produce structurally similar reasoning traces when mapped to discourse DAGs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
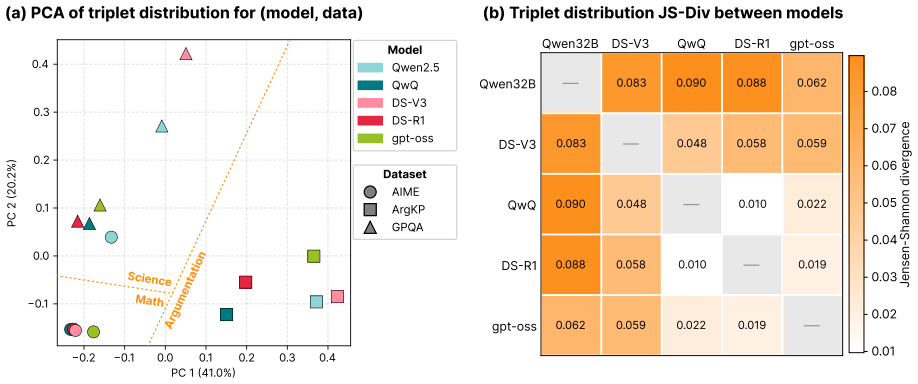
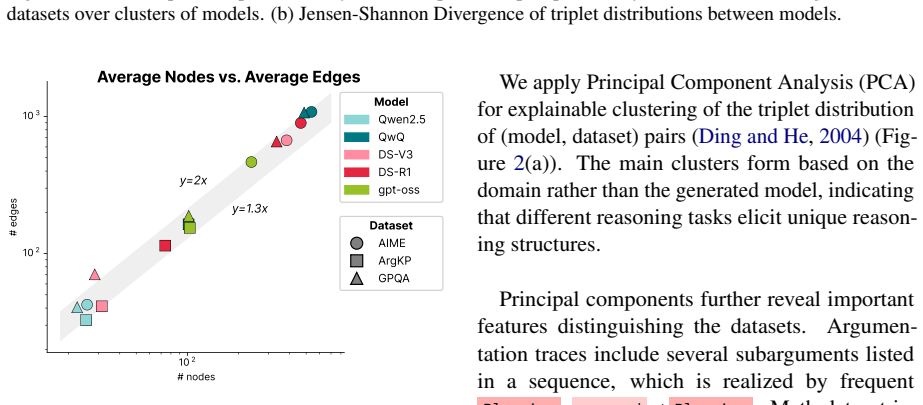
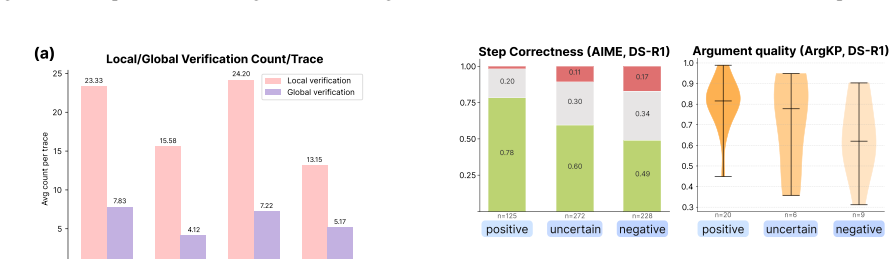
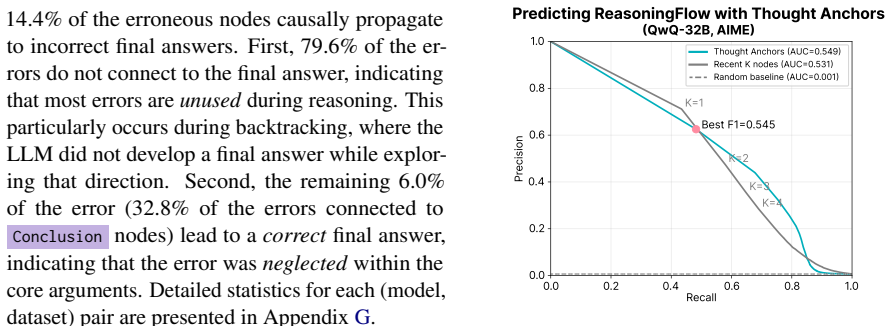
ReasoningFlow turns LRM reasoning traces into fine-grained DAGs of discourse structures. The graphs show that traces remain structurally similar across models trained from different bases and post-training data. They expose fine-grained behaviors such as local verification and self-reflection. Most erroneous steps do not contribute to the final answer. Mechanistic causal links between steps diverge from the language-level discourse structure captured in the graphs.
What carries the argument
ReasoningFlow, the framework that converts reasoning traces into directed acyclic graphs whose nodes and edges represent discourse relations among individual reasoning steps.
If this is right
- Structurally similar traces across models imply that post-training converges on common discourse patterns even when base models and data differ.
- The finding that most erroneous steps are unused suggests that monitoring only the steps that reach the answer could improve trace evaluation.
- The mismatch between causal step dependencies and discourse structure indicates that language-level analysis and mechanistic analysis must be treated as separate layers.
- Diverse fine-grained behaviors visible in the graphs supply new categories for automated reasoning-trace monitors.
Where Pith is reading between the lines
- If the graphs truly isolate contributory steps, downstream systems could prune non-contributory branches at inference time to reduce compute.
- The similarity result raises the question whether the same discourse patterns appear in non-reasoning generative tasks once the same annotation is applied.
- The released dataset of 1,260 annotated traces could serve as training data for models that predict or correct discourse structure rather than only final answers.
Load-bearing premise
The annotation schema, checked on only 31 manually labeled traces, still captures the same discourse relations when applied automatically to the full set of 1,260 traces.
What would settle it
An additional large reasoning model whose automatically produced ReasoningFlow graphs exhibit markedly different distributions of node types, edge patterns, or error usage from the five models already studied.
Figures




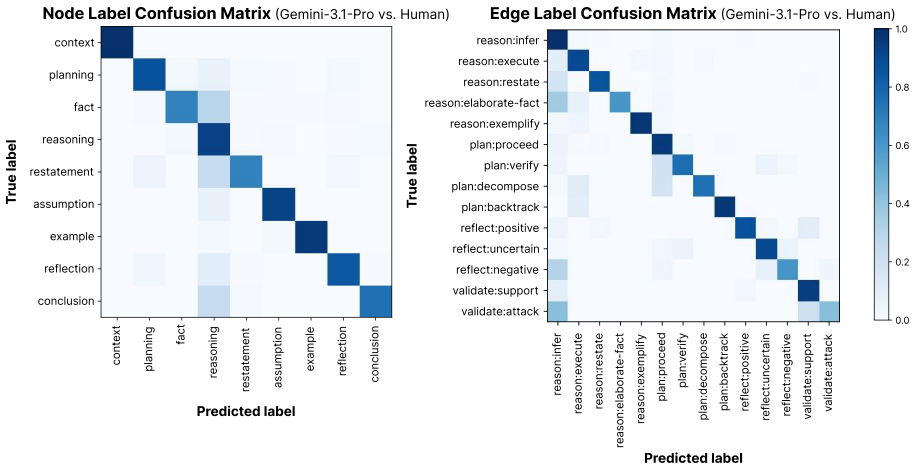
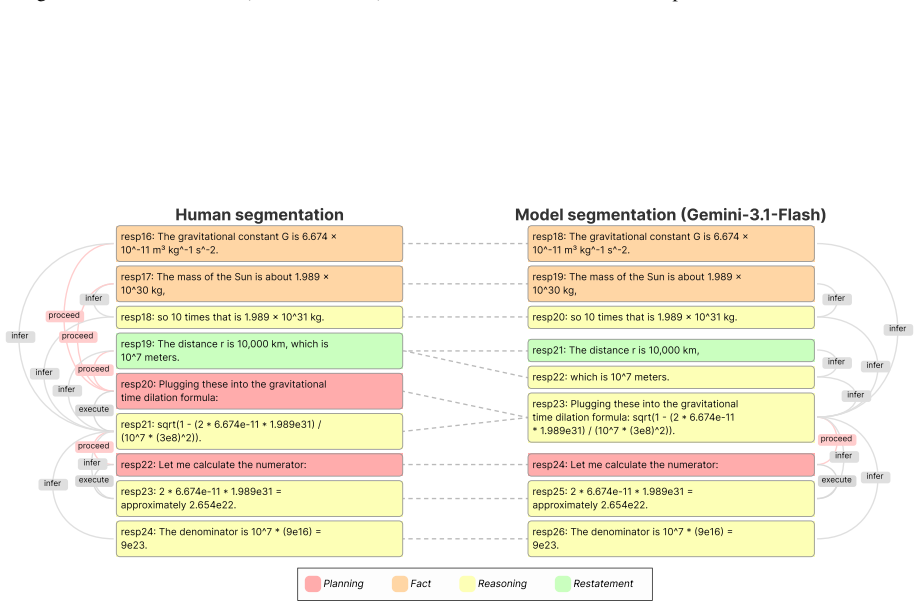

read the original abstract
Large reasoning models (LRMs) produce reasoning traces with non-linear structures, such as backtracking and self-correction, that complicate the evaluation and monitoring of the reasoning process. We introduce ReasoningFlow, a framework that captures the discourse structures of LRM reasoning traces into fine-grained directed acyclic graphs (DAGs). We develop and validate our annotation schema through careful manual annotation of 31 traces (2.1k steps), achieving high inter-annotator agreement, then scale to automatic annotation of 1,260 traces (247.7k steps) spanning three tasks (math, science, argumentation) and five models (Qwen2.5-32B-Inst, QwQ-32B, DeepSeek-V3, DeepSeek-R1, GPT-oss-120B). By analyzing ReasoningFlow graphs, we find: (1) LRMs exhibit structurally similar traces, despite being trained from different base models and potentially non-overlapping post-training data. (2) ReasoningFlow reveals diverse fine-grained reasoning behaviors (e.g., local verification, self-reflection, and assumptions) that can be used for better reasoning trace monitorability. (3) In LRMs, most of the erroneous steps are not used to derive final answers. (4) Mechanistic causal dependencies between steps do not reflect the language-level discourse structure. We release the dataset and code in: https://github.com/jinulee-v/reasoningflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ReasoningFlow, a framework that converts LRM reasoning traces into fine-grained DAGs encoding discourse relations such as backtracking, self-correction, local verification, and assumptions. The authors manually annotate 31 traces (2.1k steps) achieving high inter-annotator agreement, then apply an automatic annotator to scale to 1,260 traces (247.7k steps) across math, science, and argumentation tasks and five models (Qwen2.5-32B-Inst, QwQ-32B, DeepSeek-V3, DeepSeek-R1, GPT-oss-120B). From the resulting graphs they report four findings: (1) structurally similar traces across models despite different training, (2) diverse fine-grained behaviors useful for monitorability, (3) most erroneous steps are not used to derive final answers, and (4) mechanistic causal dependencies diverge from language-level discourse structure. Dataset and code are released.
Significance. If the automatic annotations faithfully capture the intended discourse relations, the framework supplies a concrete, graph-based representation that could improve reasoning-trace monitoring and error analysis in LRMs. The public release of the 1,260-trace dataset and annotation code is a clear strength that supports reproducibility and follow-on work.
major comments (2)
- [Automatic annotation procedure (methods section following the manual annotation description)] The annotation schema is validated only via high IAA on the 31 manually labeled traces (2.1k steps); no held-out quantitative evaluation (precision, recall, or F1), error analysis on a larger sample, or description of how the automatic annotator was trained or prompted is supplied. This directly undermines the reliability of the four findings, all of which rest on the automatically produced DAGs for the full 1,260 traces.
- [Results section reporting finding (3)] Finding (3) states that 'most of the erroneous steps are not used to derive final answers,' yet the manuscript provides no explicit definition or operationalization of how erroneous steps are identified or how 'used to derive' is determined within the DAGs. Without these details the statistic cannot be independently verified.
minor comments (2)
- [Abstract] The abstract would be strengthened by reporting the actual IAA value and at least one key graph statistic (e.g., average number of backtracking edges per trace).
- [Methods] Clarify whether the automatic annotator was applied uniformly across all five models or whether model-specific prompting was used; any differences would affect the cross-model similarity claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments, which highlight important areas for clarification. We address each major comment below and will revise the manuscript accordingly to strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: The annotation schema is validated only via high IAA on the 31 manually labeled traces (2.1k steps); no held-out quantitative evaluation (precision, recall, or F1), error analysis on a larger sample, or description of how the automatic annotator was trained or prompted is supplied. This directly undermines the reliability of the four findings, all of which rest on the automatically produced DAGs for the full 1,260 traces.
Authors: We agree that the current manuscript lacks sufficient detail on the automatic annotation procedure. In the revised version, we will add a dedicated subsection describing the prompting strategy for the automatic annotator (including the exact prompts and few-shot examples used), along with a quantitative evaluation on a held-out sample of 50 traces. This evaluation will report precision, recall, and F1 scores by comparing automatic annotations to additional manual labels. We will also include an error analysis discussing common failure modes. These additions will directly support the reliability of the reported findings. revision: yes
-
Referee: Finding (3) states that 'most of the erroneous steps are not used to derive final answers,' yet the manuscript provides no explicit definition or operationalization of how erroneous steps are identified or how 'used to derive' is determined within the DAGs. Without these details the statistic cannot be independently verified.
Authors: We acknowledge the need for explicit operational definitions. In the revision, we will define 'erroneous steps' as those involving incorrect calculations, factual errors, or invalid inferences, as flagged by discourse relations such as self-correction or assumption nodes and verified against task ground truth where applicable. 'Used to derive the final answer' will be operationalized as the existence of a directed path in the ReasoningFlow DAG from the erroneous step to the final answer node. We will include this definition in the results section, along with illustrative examples from the dataset to enable independent verification. revision: yes
Circularity Check
No significant circularity; empirical annotation and statistics
full rationale
The paper introduces an annotation schema for discourse structures in LRM traces, validates it manually on 31 traces with reported IAA, then applies automatic annotation to produce DAGs for 1,260 traces and computes graph statistics. No equations, derivations, fitted parameters presented as predictions, or self-citation chains are used to support the central claims; the reported structural similarities and error-usage patterns are direct observations from the constructed graphs rather than reductions to inputs by construction. The method is self-contained against external benchmarks in the sense that claims rest on observable data patterns, not tautological redefinitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reasoning traces contain identifiable discourse structures that can be consistently labeled as nodes and directed edges in a DAG.
invented entities (1)
-
ReasoningFlow DAG
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Prob- lems.CoRR, abs/2110.14168. Antonia Creswell, Murray Shanahan, and Irina Higgins
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023
Selection-Inference: Exploiting Large Lan- guage Models for Interpretable logical Reasoning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net. Bhavana Dalvi, Peter Jansen, Oyvind Tafjord, Zhengnan Xie, Hannah Smith, Leighanna Pipatanangkura, and Peter Clark. 2021. Explaining Ans...
2023
-
[3]
Association for Computational Linguistics. DeepSeek-AI. 2024. DeepSeek-V3 Technical Report. CoRR, abs/2412.19437. Chris H. Q. Ding and Xiaofeng He. 2004. \emphK- means clustering via principal component analysis. InMachine Learning, Proceedings of the Twenty- first International Conference (ICML 2004), Banff, Alberta, Canada, July 4-8, 2004. ACM. 9 Yufeng...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
AAAI Press. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. 2024. A Survey on LLM-as-a-Judge. CoRR, abs/2411.15594. Etash Kumar Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zay...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
OpenThoughts: Data Recipes for Reasoning Models
OpenThoughts: Data Recipes for Reasoning Models.CoRR, abs/2506.04178. Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 oth- ers. 2025. DeepSeek-R1 incentivizes reasoning in LL...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Association for Computational Linguistics
Can Large Language Models Detect Errors in Long Chain-of-Thought Reasoning? InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, pages 18468–18489. Association for Computational Linguistics. Gangwei Jiang, Yahui Liu, Zhaoyi Li, Wei Bi, Fuzhen...
-
[7]
InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s Verify Step by Step. InThe Twelfth International Conference on Learning Representa- tions, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. Chenyu Lin, Yilin Wen, Du Su, Hexiang Tan, Fei Sun, Muhan Chen, Chenfu Bao, and Zhonghou Lyu
2024
-
[8]
ArXiv:2506.05154 [cs] version: 2
Resisting Contextual Interference in RAG via Parametric-Knowledge Reinforcement.arXiv preprint. ArXiv:2506.05154 [cs] version: 2. Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, and Hao Su. 2023. Deductive Verification of Chain-of-Thought Reason- ing. InAdvances in Neural Information Processing Systems 36: Annual Conference o...
-
[9]
Imitate, Explore, and Self-Improve: A Reproduction Report on Slow-thinking Reasoning Systems
Imitate, Explore, and Self-Improve: A Repro- duction Report on Slow-thinking reasoning Systems. CoRR, abs/2412.09413. 11 Mathieu Morey, Philippe Muller, and Nicholas Asher
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
gpt-oss-120b & gpt-oss-20b Model Card
How much progress have we made on RST dis- course parsing? A replication study of recent results on the RST-DT. InProceedings of the 2017 Con- ference on Empirical Methods in Natural Language Processing, EMNLP 2017, Copenhagen, Denmark, September 9-11, 2017, pages 1319–1324. Associa- tion for Computational Linguistics. Sagnik Mukherjee, Abhinav Chinta, Ta...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Solving math word problems with process- and outcome-based feedback
Solving math word problems with process- and outcome-based feedback.CoRR, abs/2211.14275. Nicole Van Hoeck, Patrick D. Watson, and Aron K. Bar- bey. 2015. Cognitive neuroscience of human counter- factual reasoning.Frontiers in Human Neuroscience, 9:420. Douglas Walton, Christopher Reed, and Fabrizio Macagno. 2008. Argumentation Schemes. Cam- bridge Univer...
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[12]
Tree of Thoughts: Deliberate Problem Solv- ing with Large Language Models. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Sys- tems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. Evelyn Yee, Alice Li, Chenyu Tang, Yeon Ho Jung, Ramamohan Paturi, and Leon Bergen. 2024. Dissoci- ...
-
[13]
Can Aha Moments Be Fake? Towards Quantifying Decorative and True Thinking in Chain-of-Thought
Can Aha Moments Be Fake? Identifying True and Decorative Thinking steps in Chain-of-Thought. CoRR, abs/2510.24941. Chujie Zheng, Zhenru Zhang, Beichen Zhang, Runji Lin, Keming Lu, Bowen Yu, Dayiheng Liu, Jingren Zhou, and Junyang Lin. 2025. ProcessBench: Iden- tifying Process Errors in Mathematical Reasoning. InProceedings of the 63rd Annual Meeting of th...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
OpenReview.net. Jiaru Zou, Ling Yang, Jingwen Gu, Jiahao Qiu, Ke Shen, Jingrui He, and Mengdi Wang. 2025. ReasonFlux-PRM: Trajectory-Aware PRMs for Long Chain-of-Thought Reasoning in LLMs.CoRR, abs/2506.18896. 13 A ReasoningFlow annotation guide This section includes annotation guides for nodes and edges. For each subtype of nodes and edges, we provide on...
-
[15]
but" ( contrast) or
identified the global structure of reasoning traces in four stages. The framework states that LRMs first tend to restate the problem in their own language (Problem definition), derive an initial so- lution (Bloom), try recomputation or alternative approaches to verify the initial solution (Recon- struction), and decide the final answer (Final de- cision)....
2025
-
[16]
Capital punishment is against god’s will
for detecting errors in LRM traces (GPT-4- Turbo 37.4%). Error detection with PRMs.Process Reward Models (PRMs) (Uesato et al., 2022; Lightman et al., 2024) are LLM-based classifiers specifically trained to predict whether the given step is correct or not. However, we do not apply PRMs for several reasons. First, state-of-the-art PRMs like Qwen2.5- Math-P...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.