Almieyar-Oryx-BloomBench: A Bilingual Multimodal Benchmark for Cognitively Informed Evaluation of Vision-Language Models
Pith reviewed 2026-06-28 03:17 UTC · model grok-4.3
The pith
BloomBench shows state-of-the-art vision-language models perform well on semantic understanding but struggle with factual recall and creative synthesis, plus a gap between English and Arabic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BloomBench evaluates state-of-the-art VLMs across the six levels of Bloom's Taxonomy in a bilingual setting and finds that models reach high performance on semantic understanding tasks while showing substantial weaknesses in factual recall and creative synthesis, accompanied by a consistent performance gap between English and Arabic.
What carries the argument
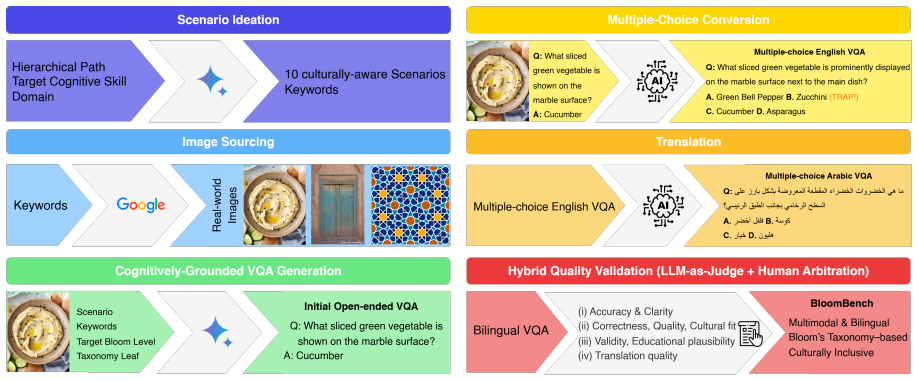
BloomBench, a bilingual benchmark that operationalizes Bloom's Taxonomy levels via image-question-answer tasks built through a semi-automated pipeline and validated by stratified hybrid quality assurance.
Load-bearing premise
Bloom's Taxonomy levels can be accurately and distinctly operationalized through image-question-answer tasks in a bilingual setting without the task design or translation process introducing confounds that invalidate the cognitive profiling.
What would settle it
Re-evaluate the same models on a version of the benchmark where tasks are deliberately reassigned across cognitive levels or where Arabic translations are independently re-validated; if the reported performance asymmetry disappears, the original cognitive mapping is likely confounded.
Figures



read the original abstract
Despite the rapid progress of Vision-Language Models (VLMs), the field lacks benchmarks that rigorously diagnose their true reasoning abilities and chart meaningful progress toward human-like multimodal intelligence. Most existing evaluations focus on piecemeal or disconnected tasks, obscuring critical cognitive weaknesses and providing little insight for targeted improvement. To address this gap, we introduce BloomBench, part of the Almieyar benchmarking series, the first cognitively human-grounded, bilingual (English-Arabic) multimodal benchmark for VLMs. Grounded in Bloom's Taxonomy, BloomBench systematically evaluates six levels of cognition (Remember, Understand, Apply, Analyze, Evaluate, Create) through carefully designed image-question-answer tasks. Built with a semi-automated pipeline and validated through a stratified hybrid quality assurance protocol, it ensures scalability, cultural inclusivity, and linguistic fidelity. Leveraging this framework, we conduct a comprehensive study of state-of-the-art VLMs to diagnose their cognitive profiles. Our analysis reveals a sharp cognitive asymmetry: while state-of-the-art models achieve strong performance ceilings in semantic understanding, they struggle substantially with factual recall and creative synthesis. This demonstrates that current general multimodal proficiency masks deeper limitations in specific cognitive layers. Furthermore, our study highlights a critical performance gap between Arabic and English, exposing limitations in current cross-lingual multimodal reasoning. These findings establish a foundation for developing more cognitively aligned and inclusive VLMs. The benchmark framework and dataset is available at: https://github.com/qcri/Almieyar-Oryx-BloomBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BloomBench (part of the Almieyar series), the first bilingual (English-Arabic) multimodal benchmark for VLMs grounded in Bloom's Taxonomy. It describes a semi-automated pipeline for constructing image-question-answer tasks targeting the six cognitive levels (Remember, Understand, Apply, Analyze, Evaluate, Create), a stratified hybrid QA validation protocol for scalability and fidelity, and an evaluation of SOTA VLMs that reports strong performance on semantic understanding but substantial weaknesses in factual recall and creative synthesis, along with a notable English-Arabic performance gap.
Significance. If the tasks cleanly isolate the intended cognitive levels without confounds, this benchmark would provide a diagnostically useful framework that goes beyond standard VLM evaluations to identify specific reasoning limitations, supporting more targeted model development. The public release of the dataset and code at the cited GitHub repository is a clear strength for reproducibility and community use.
major comments (3)
- [§3] §3 (Benchmark Construction): The semi-automated pipeline and 'stratified hybrid quality assurance protocol' are described at a high level, but no quantitative validation results (e.g., inter-annotator agreement, level-difficulty calibration, or controls for phrasing/image artifacts) are reported. This is load-bearing for the central claim, as the reported cognitive asymmetry and Arabic-English gap cannot be attributed to specific Bloom levels without evidence that the operationalization avoids the confounds noted in task design.
- [§5] §5 (Experimental Results): Aggregate performance scores are used to claim 'sharp cognitive asymmetry' (strong on Understand, weak on Remember/Create), yet no per-level statistical tests, ablation studies, or controls for lexical overlap, answer format, or image features are presented. Without these, the differences may reflect benchmark artifacts rather than model cognitive profiles.
- [§4] §4 (Bilingual Aspects): The translation and cultural adaptation process for Arabic items is not detailed with metrics showing preserved cognitive demands or absence of systematic difficulty shifts. This directly undermines attribution of the reported performance gap to cross-lingual multimodal reasoning limitations.
minor comments (2)
- [Abstract] Abstract: Ensure consistent naming between the paper title and the benchmark reference ('Almieyar-Oryx-BloomBench' vs. 'BloomBench').
- [§2] Figure captions and §2 (Related Work): Expand discussion of how BloomBench differs from prior cognitive or multilingual VLM benchmarks to strengthen positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The semi-automated pipeline and 'stratified hybrid quality assurance protocol' are described at a high level, but no quantitative validation results (e.g., inter-annotator agreement, level-difficulty calibration, or controls for phrasing/image artifacts) are reported. This is load-bearing for the central claim, as the reported cognitive asymmetry and Arabic-English gap cannot be attributed to specific Bloom levels without evidence that the operationalization avoids the confounds noted in task design.
Authors: We agree that quantitative validation results are needed to support the claims. In the revised manuscript we will report inter-annotator agreement from the stratified hybrid QA protocol, level-difficulty calibration statistics, and explicit controls for phrasing and image artifacts. These additions will demonstrate that the tasks isolate the intended Bloom levels without the noted confounds. revision: yes
-
Referee: [§5] §5 (Experimental Results): Aggregate performance scores are used to claim 'sharp cognitive asymmetry' (strong on Understand, weak on Remember/Create), yet no per-level statistical tests, ablation studies, or controls for lexical overlap, answer format, or image features are presented. Without these, the differences may reflect benchmark artifacts rather than model cognitive profiles.
Authors: We acknowledge that the current analysis relies on aggregate scores without the requested statistical safeguards. The revised version will add per-level statistical tests for performance differences, ablation studies, and controls for lexical overlap, answer format, and image features. These will help establish that the observed asymmetry reflects model cognitive profiles rather than artifacts. revision: yes
-
Referee: [§4] §4 (Bilingual Aspects): The translation and cultural adaptation process for Arabic items is not detailed with metrics showing preserved cognitive demands or absence of systematic difficulty shifts. This directly undermines attribution of the reported performance gap to cross-lingual multimodal reasoning limitations.
Authors: We will expand the description in §4 to include quantitative metrics on the translation and cultural adaptation steps. This will encompass expert ratings confirming preservation of cognitive demands across levels and checks for systematic difficulty shifts between English and Arabic versions, thereby supporting attribution of the gap to cross-lingual multimodal reasoning. revision: yes
Circularity Check
No circularity: empirical benchmark with external grounding
full rationale
The paper introduces BloomBench as a new evaluation dataset grounded in the externally established Bloom's Taxonomy. No equations, parameter fitting, predictions, or derivations are present. Claims about model performance asymmetries rest on direct empirical evaluation of VLMs on the benchmark tasks rather than any self-referential construction or self-citation chain. The design is described as validated via hybrid QA and semi-automated pipeline, but these are methodological details, not reductions of results to inputs by construction. This is a standard self-contained benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Bloom's Taxonomy provides a valid and separable framework for diagnosing cognitive abilities in vision-language models
Reference graph
Works this paper leans on
-
[1]
Fanar 2.0: Arabic generative ai stack.arXiv preprint arXiv:2603.16397. Mohammad Mahdi Abootorabi, Omid Ghahroodi, Par- dis Sadat Zahraei, Hossein Behzadasl, Alireza Mir- rokni, Mobina Salimipanah, Arash Rasouli, Bahar Behzadipour, Sara Azarnoush, Benyamin Maleki, and 1 others. 2025a. Generative ai for character animation: A comprehensive survey of techniq...
-
[2]
Si Chen, Le Huy Khiem, Annalisa Szymanski, Ronald Metoyer, Ting Hua, and Nitesh V Chawla
Evaluating large language models trained on code. Si Chen, Le Huy Khiem, Annalisa Szymanski, Ronald Metoyer, Ting Hua, and Nitesh V Chawla. 2026. Au- tomated benchmark generation from domain guide- lines informed by bloom’s taxonomy.arXiv preprint arXiv:2601.20253. Zhuang Chen, Jincenzi Wu, Jinfeng Zhou, Bosi Wen, Guanqun Bi, Gongyao Jiang, Yaru Cao, Meng...
-
[3]
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Mar- cel Blistein, Ori Ram, Dan Zhang, Evan Rosen, Luke Marris, Sam Petulla, Colin Gaffney, Asaf Aharoni, Nathan Lintz, Tiago Cardal Pais, Henrik Jacobs- son, Idan Szpektor, Na...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Camel-bench: A comprehensive arabic lmm benchmark.arXiv preprint arXiv:2410.18976. Omid Ghahroodi, Arshia Hemmat, Marzia Nouri, Seyed Mohammad Hadi Hosseini, Doratossadat Dastgheib, Mohammad Vali Sanian, Alireza Sahebi, Reihaneh Zohrabi, Mohammad Hossein Rohban, Ehsaneddin Asgari, and 1 others. 2025. Meena (persianmmmu): Multimodal-multilingual educationa...
-
[5]
Why multimodality? why co-operative ac- tion?(transcribed by j. philipsen).Social Interaction. Video-Based Studies of Human Sociality, 1(2). Google DeepMind. 2025. Gemini 3 flash: Frontier in- telligence built for speed. https://blog.google/ products/gemini/gemini-3-flash/. Google Blog. Accessed: 2026-04-10. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jau...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882
Mitigating object hallucinations in large vision- language models through visual contrastive decod- ing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13872–13882. Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. 2023a. Blip-2: bootstrapping language-image pre- training with frozen image encoders and larg...
2023
-
[7]
Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi
Beyond finite data: Towards data-free out-of- distribution generalization via extrapolation.arXiv preprint arXiv:2403.05523. Zongxia Li, Xiyang Wu, Hongyang Du, Fuxiao Liu, Huy Nghiem, and Guangyao Shi. 2025. A survey of state of the art large vision language models: Align- ment, benchmark, evaluations and challenges.arXiv preprint arXiv:2501.02189. Fuxia...
-
[8]
Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, and Cong Yao
Curran Associates, Inc. Chuwei Luo, Yufan Shen, Zhaoqing Zhu, Qi Zheng, Zhi Yu, and Cong Yao. 2024. Layoutllm: Layout instruc- tion tuning with large language models for document understanding. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 15630–15640. Yinghang Ma, Jiho Shin, Leuson Da Silva, Zhen Ming, Song ...
-
[9]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv preprint arXiv:2402.07927. Paul-Edouard Sarlin, Daniel DeTone, Tomasz Mal- isiewicz, and Andrew Rabinovich. 2020. Superglue: Learning feature matching with graph neural net- works. InProceedings of the IEEE/CVF conference on computer vision and pattern r...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[10]
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information pro- cessing systems, 36:46595–46623. Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. 2024. AGIEval: A human-centric benchmark for evaluating foundation models. In Findings of the Association for Computati...
2024
-
[11]
Artifacts, 3
Animals, 2. Artifacts, 3. Arts, 4.Clothing & Accessories, 5. CommonObjects, 6. Food & Beverage, 7. IndoorScenes, 8. Outdoor Scenes, 9. People,10. Produce & Plants, 11. Technology &Electronics, 12. Vehicles Symbol Recognition
-
[12]
Astrological &Zodiac Signs, 3
App & Tech Icons, 2. Astrological &Zodiac Signs, 3. Currency Symbols, 4.Flags, 5. Logos & Brands, 6. ReligiousSymbols, 7. Safety Symbols, 8. TrafficSigns, 9. Emoji, 10. Formula, 11. Music Text Attribute Recognition1. Number, 2. Books, 3. Documents, 4.Handwriting, 5. Lines, 6. Newsletter, 7.PowerPoint Slides, 8. Scene Text Understand Compositional Core Obj...
-
[13]
Animals, 3
Closed Vocabulary Object Detec-tion, 2. Animals, 3. Artifacts, 4. Arts,5. Clothing & Accessories, 6. CommonObjects, 7. Food & Beverage, 8. IndoorScenes, 9. Outdoor Scenes, 10. People,11. Produce & Plants, 12. Technology &Electronics, 13. Vehicles Compositional Attribute Recogni-tion 1. Artistic Style, 2. Shape, 3. Size, 4.Texture Cognitive Understanding
-
[14]
Lingual Expression Alternation, 3.Semantic Understanding (Knowledge), 4.Visual Alternation Apply Knowledge Application
Facial & Emotional Understanding,2. Lingual Expression Alternation, 3.Semantic Understanding (Knowledge), 4.Visual Alternation Apply Knowledge Application
-
[15]
Ap-plying a Mathematical Formula, 3
Applying a Design Principle, 2. Ap-plying a Mathematical Formula, 3. Ap-plying a Scientific Concept, 4. Procedu-ral Step Following Basic Logic Operation1. Coordination Interpretation, 2. Nega-tion Understanding, 3. Word Order Un-derstanding Analyze Atypical Attribute Identification1. Artistic Style, 2. Color, 3. Shape, 4.Size, 5. Texture Contextual Inference
-
[16]
Common-sense Reasoning, 3
Ambiguity Resolution, 2. Common-sense Reasoning, 3. Comparative Rea-soning, 4. Ellipsis Resolution, 5. Pro-noun Resolution Logical and Scientific Reasoning1. Logical Reasoning, 2. Math Reason-ing, 3. Scientific Reasoning Structured Data Analysis
-
[17]
Chemical Struc-ture Analysis, 3
Chart Analysis, 2. Chemical Struc-ture Analysis, 3. Diagram Analysis, 4.Document Analysis, 5. Sheet MusicAnalysis, 6. Table Analysis Evaluate Harm & Safety Evaluation
-
[18]
Contex-tual Suitability, 3
Age-Appropriateness, 2. Contex-tual Suitability, 3. Cultural Sensitivity,4. Safety Evaluation, 5. Toxicity Detec-tion Logical Coherence Evaluation1. Conflicting Scenario Evaluation, 2.Object Hallucination Evaluation Quality Evaluation 1. Artistic Evaluation, 2. Image QualityAssessment Create Structured Creation
-
[19]
Design-ing an Experiment, 3
Counterfactual Creation, 2. Design-ing an Experiment, 3. Dialogue Genera-tion, 4. Image-based Question Genera-tion Creative Generation
-
[20]
Pattern Recognition
Creative Title Generation, 2. Joke, 3.Meme Caption Creative Generation, 4.Poem, 5. Short Story, 6. Image Caption-ing, 7. Visual Storytelling Figure 4: The complete hierarchical structure of the BloomBench taxonomy. The diagram illustrates the decomposi- tion of Bloom’s six cognitive levels into specific sub-categories and fine-grained task types, defining...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.