UniVoice: A Unified Model for Speech and Singing Voice Generation
Pith reviewed 2026-06-27 23:54 UTC · model grok-4.3
The pith
UniVoice unifies speech and singing generation by factorizing conditions into content, melody, and timbre and replacing melody input with a null token for speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniVoice is a unified framework based on conditional flow matching. It factorizes the condition into content, melody, and timbre, which are encoded by modality-appropriate encoders and consumed by a shared Diffusion Transformer backbone. For singing the melody condition is MIDI note sequences; for speech it is replaced with a learned null melody token so the model infers prosody from linguistic and acoustic context. This preserves explicit melody control for singing while avoiding melody constraints on speech, and the null token is analyzed as an approximation to melody marginalization in the conditional flow.
What carries the argument
Condition factorization into content, melody, and timbre encoders feeding a shared Diffusion Transformer backbone, together with substitution of a learned null melody token in place of melody input for speech.
If this is right
- The shared backbone can be trained on combined speech and singing datasets without explicit melody signals harming speech prosody.
- Explicit melody control remains available for singing while speech prosody is inferred freely from context.
- Performance reaches levels comparable to dedicated TTS systems on speech and better than prior unified models on singing.
- The null token functions as an approximation to melody marginalization inside the conditional flow matching objective.
Where Pith is reading between the lines
- The same selective-conditioning pattern could be applied to other paired generation tasks where one domain needs an extra control signal the other does not.
- Replacing the null token at inference time with a singing-derived melody embedding might enable controlled speech-to-singing conversion without retraining.
- Further scaling of data or model size could narrow the remaining gap between unified and specialist singing performance.
Load-bearing premise
The learned null melody token can be substituted for the melody condition in speech without restricting prosody or introducing biases from the shared backbone trained on singing data.
What would settle it
A direct comparison of prosody naturalness scores or word error rates between speech generated by UniVoice using the null token and speech generated by an otherwise identical model trained only on speech data; if the null-token version is markedly worse, the substitution does not preserve natural prosody.
Figures

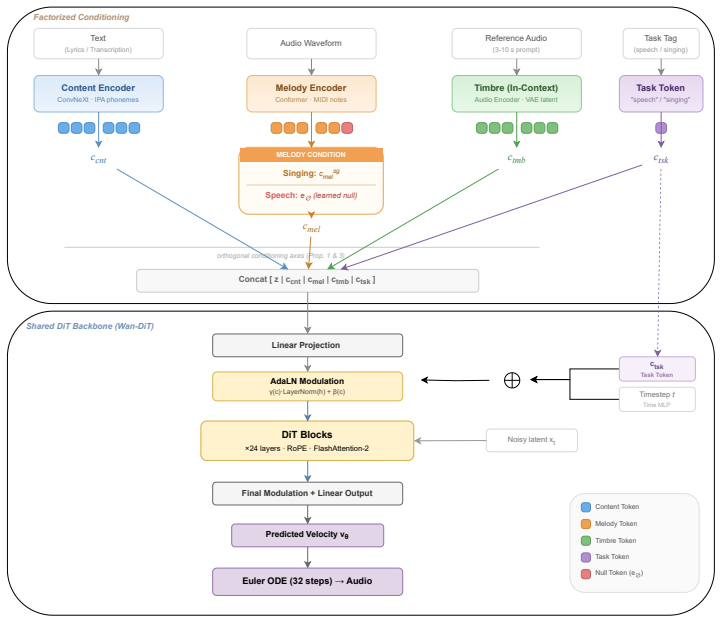
read the original abstract
Text-to-speech (TTS) and singing voice synthesis (SVS) both aim to generate human vocal audio from symbolic inputs, but they impose different requirements on the generation process. Speech generation relies on flexible, language-driven prosody, whereas singing generation requires explicit melody control and accurate rhythmic alignment. This mismatch makes it challenging to train a single model that can generate both natural speech and controllable singing, since melody-related conditions should strongly constrain singing but should not restrict speech prosody. We present UniVoice, a unified speech and singing voice generation framework based on conditional flow matching. Instead of using a single undifferentiated conditioning representation, UniVoice factorizes the condition into content, melody, and timbre, which are encoded by modality-appropriate encoders and consumed by a shared Diffusion Transformer (DiT) backbone. For singing, the melody condition is represented by MIDI note sequences; for speech, it is replaced with a learned null melody token, allowing the model to infer prosody from linguistic and acoustic context. This design preserves explicit melody control for singing while avoiding the need to impose melody constraints on speech. We further analyze the null melody token as an approximation to melody marginalization in the conditional flow. Trained on 30k hours of speech and 35k hours of singing data, UniVoice achieves a speech PER of 5.26\%, comparable to dedicated TTS systems such as F5-TTS (5.21\%) and CosyVoice3 (5.30\%). On singing generation, UniVoice achieves a PER of 16.22\%, outperforming the unified baseline Vevo1.5 (24.72\%).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents UniVoice, a unified conditional flow matching model for text-to-speech and singing voice synthesis. It factorizes conditioning into content, melody, and timbre encoders feeding a shared DiT backbone; melody is supplied via MIDI for singing data but replaced by a learned null token for speech data so that prosody can be inferred from linguistic and acoustic context alone. Trained on 30k hours of speech plus 35k hours of singing, the model reports a speech PER of 5.26% (comparable to F5-TTS at 5.21% and CosyVoice3 at 5.30%) and a singing PER of 16.22% (outperforming the unified baseline Vevo1.5 at 24.72%). The null-token substitution is presented as an approximation to melody marginalization in the conditional flow.
Significance. If the evaluation protocols and prosody claims can be substantiated, the result would be a practically useful demonstration that a single large-scale DiT can handle both flexible speech prosody and explicit melody control without dedicated branches. The scale of the combined training corpus and the direct head-to-head numbers against strong dedicated TTS systems constitute a concrete engineering contribution; the factorization into modality-appropriate encoders is a clean design choice that could be adopted more broadly.
major comments (3)
- [Abstract, §4] Abstract and §4 (Results): the central unification claim rests on the null melody token allowing the shared backbone to infer natural prosody for speech while still respecting explicit melody on singing data, yet the only quantitative support is aggregate PER. PER measures phoneme content accuracy and does not assess prosodic naturalness, F0 distribution match, duration statistics, or rhythmic alignment; therefore the reported numbers do not confirm that the null token neither over-constrains speech prosody nor under-constrains singing training.
- [Abstract, §3] Abstract and §3 (Method): the statement that the null melody token constitutes “an approximation to melody marginalization in the conditional flow” is presented without an explicit derivation or ablation showing how the learned token affects the flow-matching objective or the resulting marginal distribution over prosody. A concrete comparison (e.g., KL divergence on F0 or an ablation replacing the null token with random MIDI) is needed to substantiate the claim.
- [Abstract] Abstract: the speech and singing PER figures are given without any description of evaluation protocol, test-set construction, data splits, statistical significance, or the precise definition of singing PER (e.g., whether melody alignment is enforced during phoneme error computation). These details are load-bearing for the comparability statements against F5-TTS, CosyVoice3, and Vevo1.5.
minor comments (2)
- [§3] Notation for the three condition encoders (content, melody, timbre) should be introduced once with consistent symbols and referenced in all subsequent equations and figures.
- [§4] Figure captions and axis labels for any spectrogram or F0 plots should explicitly state whether examples are drawn from the speech or singing test partition.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to incorporate clarifications and additional analyses where feasible.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (Results): the central unification claim rests on the null melody token allowing the shared backbone to infer natural prosody for speech while still respecting explicit melody on singing data, yet the only quantitative support is aggregate PER. PER measures phoneme content accuracy and does not assess prosodic naturalness, F0 distribution match, duration statistics, or rhythmic alignment; therefore the reported numbers do not confirm that the null token neither over-constrains speech prosody nor under-constrains singing training.
Authors: We agree that PER alone does not directly measure prosodic naturalness or F0/duration alignment. The paper uses PER to demonstrate that the shared backbone maintains content accuracy under both explicit melody (singing) and null-token (speech) conditions. In revision we will add F0 correlation, duration statistics, and subjective prosody ratings to better substantiate the unification claim. revision: yes
-
Referee: [Abstract, §3] Abstract and §3 (Method): the statement that the null melody token constitutes “an approximation to melody marginalization in the conditional flow” is presented without an explicit derivation or ablation showing how the learned token affects the flow-matching objective or the resulting marginal distribution over prosody. A concrete comparison (e.g., KL divergence on F0 or an ablation replacing the null token with random MIDI) is needed to substantiate the claim.
Authors: The phrasing is intended as an intuitive description of the design choice rather than a formal derivation. We will revise §3 to clarify the conceptual link and add an ablation replacing the null token with random MIDI, reporting F0 KL divergence and PER impact to quantify the effect on the learned marginal. revision: yes
-
Referee: [Abstract] Abstract: the speech and singing PER figures are given without any description of evaluation protocol, test-set construction, data splits, statistical significance, or the precise definition of singing PER (e.g., whether melody alignment is enforced during phoneme error computation). These details are load-bearing for the comparability statements against F5-TTS, CosyVoice3, and Vevo1.5.
Authors: We will expand the abstract with a concise statement of the evaluation protocol and singing PER definition (phoneme-level alignment without melody enforcement during error computation). Full details on test sets, splits, and significance testing already appear in §4 and will be cross-referenced. revision: yes
Circularity Check
No significant circularity; model is an empirical engineering adaptation
full rationale
The paper presents UniVoice as a conditional flow matching architecture with a shared DiT backbone and a design choice to replace melody conditioning with a learned null token for speech data. No equations, derivations, or first-principles results are claimed that reduce performance metrics or unification to fitted parameters by construction. The reported PER numbers are empirical outcomes on held-out data, not predictions derived from the conditioning scheme itself. No self-citations are invoked as load-bearing uniqueness theorems, and the null-token substitution is described as an explicit engineering decision rather than a mathematical marginalization proven within the paper. The work is therefore self-contained against external benchmarks with no circular reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Conditional flow matching provides a suitable generative framework for vocal audio
invented entities (1)
-
null melody token
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Neural codec language models are zero-shot text to speech synthesizers.IEEE Transactions on Audio, Speech and Language Processing, 33:705–718, 2025
Sanyuan Chen, Chengyi Wang, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Neural codec language models are zero-shot text to speech synthesizers.IEEE Transactions on Audio, Speech and Language Processing, 33:705–718, 2025
2025
-
[2]
Sanyuan Chen, Shujie Liu, Long Zhou, Yanqing Liu, Xu Tan, Jinyu Li, Sheng Zhao, Yao Qian, and Furu Wei. V ALL-E 2: Neural codec language models are human parity zero-shot text to speech synthesizers.arXiv preprint arXiv:2406.05370, 2024
-
[3]
Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, et al. CosyV oice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.arXiv preprint arXiv:2407.05407, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, JianZhao Bian, Kai Yu, and Xie Chen. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics, pages 6255–6271, 2025
2025
-
[5]
Kai Shen, Zeqian Ju, Xu Tan, Yanqing Liu, Yichong Leng, Lei He, Tao Qin, Sheng Zhao, and Jiang Bian. NaturalSpeech 2: Latent diffusion models are natural and zero-shot speech and singing synthesizers.arXiv preprint arXiv:2304.09116, 2023
-
[6]
arXiv preprint arXiv:2403.03100 , year=
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Yanqing Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. NaturalSpeech 3: Zero-shot speech synthesis with factorized codec and diffusion models.arXiv preprint arXiv:2403.03100, 2024
-
[7]
V oicebox: Text-guided multilin- gual universal speech generation at scale.Advances in Neural Information Processing Systems, 36:14005–14034, 2023
Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. V oicebox: Text-guided multilin- gual universal speech generation at scale.Advances in Neural Information Processing Systems, 36:14005–14034, 2023
2023
-
[8]
Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling.arXiv preprint arXiv:2303.03926, 2023
-
[9]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 4195–4205, 2023
2023
-
[11]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning.arXiv preprint arXiv:2307.08691, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[14]
Conformer: Convolution-augmented transformer for speech recognition,
Anmol Gulati, James Qin, Chung-Cheng Chiu, Niki Parmar, Yu Zhang, Jiahui Yu, Wei Han, Shibo Wang, Zhengdong Zhang, Yonghui Wu, et al. Conformer: Convolution-augmented transformer for speech recognition.arXiv preprint arXiv:2005.08100, 2020
-
[15]
Prompt-Singer: Controllable singing-voice-synthesis with natural language prompt
Yongqi Wang, Ruofan Hu, Rongjie Huang, Zhiqing Hong, Ruiqi Li, Wenrui Liu, Fuming You, Tao Jin, and Zhou Zhao. Prompt-Singer: Controllable singing-voice-synthesis with natural language prompt. InProceedings of NAACL-HLT, pages 4780–4794, 2024
2024
-
[16]
Semin Kim, Myeonghun Jeong, Hyeonseung Lee, Minchan Kim, Byoung Jin Choi, and Nam Soo Kim. MakeSinger: A semi-supervised training method for data-efficient singing voice synthesis via classifier-free diffusion guidance.arXiv preprint arXiv:2406.05965, 2024. 10
-
[17]
DiTSinger: Scaling singing voice synthesis with diffusion transformer and implicit alignment
Zongcai Du, Guilin Deng, Xiaofeng Guo, Xin Gao, Linke Li, Kaichang Cheng, Fubo Han, Siyu Yang, Peng Liu, Pan Zhong, et al. DiTSinger: Scaling singing voice synthesis with diffusion transformer and implicit alignment. InICASSP, pages 17717–17721, 2026
2026
-
[18]
Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning,
Xueyao Zhang, Junan Zhang, Yuancheng Wang, Chaoren Wang, Yuanzhe Chen, Dongya Jia, Zhuo Chen, and Zhizheng Wu. Vevo2: Bridging controllable speech and singing voice generation via unified prosody learning.arXiv preprint arXiv:2508.16332, 2025
-
[19]
E2-TTS: Embarrassingly easy fully non-autoregressive zero-shot TTS
Sefik Emre Eskimez, Xiaofei Wang, Manthan Thakker, Canrun Li, Chung-Hsien Tsai, Zhen Xiao, Hemin Yang, Zirun Zhu, Min Tang, Xu Tan, et al. E2-TTS: Embarrassingly easy fully non-autoregressive zero-shot TTS. InProceedings of the IEEE Spoken Language Technology Workshop, pages 682–689, 2024
2024
-
[20]
Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation
Haorui He, Zengqiang Shang, Chaoren Wang, Xuyuan Li, Yicheng Gu, Hua Hua, Liwei Liu, Chen Yang, Jiaqi Li, Peiyang Shi, et al. Emilia: An extensive, multilingual, and diverse speech dataset for large-scale speech generation. InProceedings of the IEEE Spoken Language Technology Workshop, pages 885–890, 2024
2024
-
[21]
Kai-Tuo Xu, Feng-Long Xie, Xu Tang, and Yao Hu. FireRedASR: Open-source industrial-grade Mandarin speech recognition models from encoder-decoder to LLM integration.arXiv preprint arXiv:2501.14350, 2025
-
[22]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, A.J. Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[24]
Disentangling by factorising
Hyunjik Kim and Andriy Mnih. Disentangling by factorising. InProceedings of the International Conference on Machine Learning, pages 2649–2658, 2018
2018
-
[25]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023
2023
-
[26]
Chenyu Yang, Shuai Wang, Hangting Chen, Wei Tan, Jianwei Yu, and Haizhou Li. SongBloom: Coherent song generation via interleaved autoregressive sketching and diffusion refinement. arXiv preprint arXiv:2506.07634, 2025
-
[27]
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, and Jordi Pons. Stable Audio Open.arXiv preprint arXiv:2407.14358, 2024
-
[28]
melody-absent
Daniel Silver, Monica Lee, and C. Clayton Childress. Genre complexes in popular music.PLOS ONE, 11:1–23, 2016. A Extended Proofs and Theoretical Details This appendix provides detailed proofs and additional theoretical analysis for the results presented in Sections 3.3 and 3.4. A.1 Representation Conflict: Formal Definition Definition 1(Representation con...
2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.