LadderMan: Learning Humanoid Perceptive Ladder Climbing
Pith reviewed 2026-06-28 01:20 UTC · model grok-4.3
The pith
A two-stage pipeline distills multiple climbing experts into one depth-based policy that lets humanoid robots climb diverse ladders and manipulate objects with zero-shot hardware transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
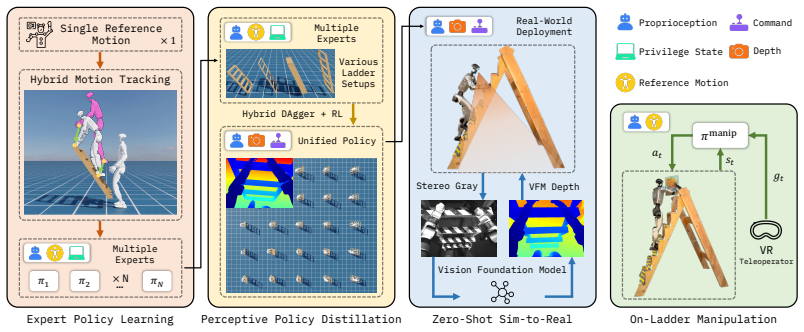
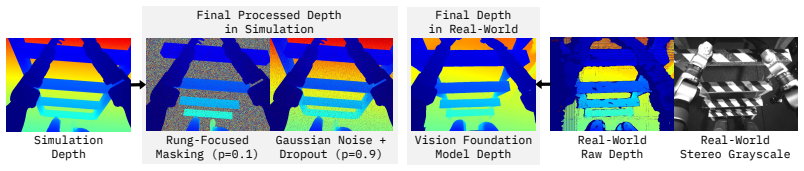
LadderMan is a unified system whose climbing policy is produced by hybrid motion tracking that yields multiple experts from a single reference motion, followed by hybrid imitation and reinforcement learning that distills them into one depth-based visuomotor policy; vision foundation models bridge the sim-to-real depth gap, and a dual-agent formulation adds stable on-ladder manipulation.
What carries the argument
Hybrid motion tracking that produces multiple climbing experts from one reference motion, distilled via hybrid imitation and reinforcement learning into a unified depth-based visuomotor policy.
If this is right
- The policy produces robust climbing on a wide range of ladder geometries.
- The same policy transfers to real hardware without additional training.
- A dual-agent manipulation policy built on the climbing controller supports teleoperated tasks while on the ladder.
- The overall system works under the constrained footholds and handholds typical of ladders.
Where Pith is reading between the lines
- The expert-distillation step may reduce the need for many separate reference motions when learning other multi-contact locomotion skills.
- Decoupling perception via off-the-shelf foundation models could let the same control pipeline accept improved depth estimators as they appear.
- The dual-agent manipulation layer suggests that climbing and manipulation can be trained sequentially rather than jointly in high-dimensional spaces.
Load-bearing premise
Hybrid motion tracking creates multiple experts from one motion that can be distilled into a single policy whose performance holds after vision foundation models supply real depth estimates.
What would settle it
A ladder geometry outside the training set on which the distilled policy consistently fails to reach the top, or a zero-shot hardware trial that requires retraining or fails outright.
Figures








read the original abstract
Humanoid robots hold great promise for operating in human-centered environments, yet ladder climbing remains one of the most challenging tasks due to sparse footholds and handholds, complex whole-body coordination, and sensitivity to perception and control errors. We present \textbf{LadderMan}, a unified system that enables humanoid robots to robustly climb diverse ladders and perform manipulation under such constrained conditions. Our climbing policy is built on a scalable two-stage learning pipeline, where we use hybrid motion tracking to learn multiple climbing experts from a single reference motion, and distill these experts into a unified depth-based visuomotor climbing policy via hybrid imitation and reinforcement learning. To enable real-world deployment, we leverage vision foundation models to bridge the sim-to-real gap in depth perception. Building on the learned climbing policy, we further train a separate manipulation policy using a dual-agent formulation, allowing stable on-ladder manipulation via teleoperation. Experiments demonstrate that LadderMan achieves robust ladder climbing across a wide range of geometries, successfully transfers to real-world hardware in a zero-shot manner, and supports various manipulation tasks under challenging ladder constraints. Video results are available at https://ladderman-robot.github.io .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents LadderMan, a unified system for humanoid ladder climbing and on-ladder manipulation. It proposes a scalable two-stage learning pipeline that first uses hybrid motion tracking to derive multiple climbing experts from a single reference motion, then distills them into a unified depth-based visuomotor policy via hybrid imitation and reinforcement learning. Vision foundation models are employed to bridge the sim-to-real gap for depth perception. A separate dual-agent manipulation policy is trained to enable stable teleoperated tasks under ladder constraints. The central claims are that the system achieves robust climbing across diverse ladder geometries, zero-shot transfer to real hardware, and support for manipulation tasks.
Significance. If the empirical results hold with rigorous validation, the work would advance humanoid robotics by addressing a high-difficulty task involving sparse contacts, whole-body coordination, and perception sensitivity. The hybrid tracking-to-distillation pipeline and use of off-the-shelf vision models for sim-to-real depth bridging represent potentially reusable techniques for complex locomotion. Credit is due for framing the problem as both perceptive climbing and constrained manipulation, which aligns with practical deployment needs.
major comments (1)
- [Abstract] Abstract: The central claims of 'robust ladder climbing across a wide range of geometries' and 'successfully transfers to real-world hardware in a zero-shot manner' are presented without any quantitative metrics (e.g., success rates, traversal times, failure modes), ablation studies, or hardware specifications. This absence makes it impossible to evaluate whether the hybrid motion tracking and distillation pipeline actually delivers the reported outcomes, rendering the experimental demonstration load-bearing but unsupported.
minor comments (1)
- [Abstract] The abstract references a project website for video results but provides no summary of what the videos demonstrate (e.g., specific ladder variations or failure recoveries), which would aid assessment of the claims.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of the work's significance and for the constructive comment on the abstract. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of 'robust ladder climbing across a wide range of geometries' and 'successfully transfers to real-world hardware in a zero-shot manner' are presented without any quantitative metrics (e.g., success rates, traversal times, failure modes), ablation studies, or hardware specifications. This absence makes it impossible to evaluate whether the hybrid motion tracking and distillation pipeline actually delivers the reported outcomes, rendering the experimental demonstration load-bearing but unsupported.
Authors: We agree that the abstract would benefit from including quantitative metrics to support the stated claims and make the summary self-contained. The body of the manuscript reports the relevant experimental results, including success rates across ladder geometries, traversal times, failure mode analysis, ablation studies on the hybrid tracking and distillation components, and hardware specifications for the zero-shot transfer. We will revise the abstract to incorporate key quantitative results from these experiments. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents an empirical two-stage learning pipeline (hybrid motion tracking to produce climbing experts from one reference motion, followed by distillation into a unified depth-based policy via imitation+RL, plus vision foundation models for sim-to-real) and a separate dual-agent manipulation policy. No equations, fitted parameters, or mathematical derivations appear in the provided abstract or described claims. Central results are framed as experimental demonstrations of robustness, zero-shot transfer, and manipulation capability rather than predictions that reduce to inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in a load-bearing way. This matches the reader's assessment of score 2.0 but is set to 0 because no circular steps of any enumerated kind are identifiable from the text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Hammer and U
W. Hammer and U. Schmalz. Human behaviour when climbing ladders with varying inclina- tions.Safety Science, 15(1):21–38, 1992
1992
- [2]
- [3]
-
[4]
H. Wang, Z. Wang, J. Ren, Q. Ben, T. Huang, W. Zhang, and J. Pang. Beamdojo: Learning agile humanoid locomotion on sparse footholds. InRobotics: Science and Systems (RSS), 2025
2025
-
[5]
Yoneda, K
H. Yoneda, K. Sekiyama, Y . Hasegawa, and T. Fukuda. Vertical ladder climbing motion with posture control for multi-locomotion robot. In2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 3579–3584, 2008
2008
-
[6]
J. Luo, Y . Zhang, K. Hauser, H. A. Park, M. Paldhe, C. S. G. Lee, M. Grey, M. Stilman, J. H. Oh, J. Lee, I. Kim, and P. Oh. Robust ladder-climbing with a humanoid robot with application to the darpa robotics challenge. In2014 IEEE International Conference on Robotics and Automation (ICRA), pages 2792–2798, 2014
2014
-
[7]
Vaillant, A
J. Vaillant, A. Kheddar, H. Audren, F. Keith, S. Brossette, A. Escande, K. Kaneko, M. Mori- sawa, P. Gergondet, E. Yoshida, S. Kajita, and F. Kanehiro. Multi-contact vertical ladder climbing with an hrp-2 humanoid.Autonomous Robots, 2016
2016
-
[8]
Yoshiike, M
T. Yoshiike, M. Kuroda, R. Ujino, H. Kaneko, H. Higuchi, S. Iwasaki, Y . Kanemoto, M. Asa- tani, and T. Koshiishi. Development of experimental legged robot for inspection and disaster response in plants. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 4869–4876, 2017
2017
-
[9]
X. Sun, K. Hashimoto, T. Teramachi, T. Matsuzawa, S. Kimura, N. Sakai, S. Hayashi, Y . Yoshida, and A. Takanishi. Planning and control of stable ladder climbing motion for the four-limbed robot “warec-1”. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 6547–6554, 2017
2017
-
[10]
A. A. Saputra, Y . Toda, N. Takesue, and N. Kubota. A novel capabilities of quadruped robot moving through vertical ladder without handrail support. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1448–1453, 2019
2019
-
[11]
X. Sun, K. Hashimoto, S. Hayashi, M. Okawara, T. Mastuzawa, and A. Takanishi. Stable vertical ladder climbing with rung recognition for a four-limbed robot.Journal of Bionic Engineering, 2021
2021
-
[12]
H. Weng, Y . Li, N. Sobanbabu, Z. Wang, Z. Luo, T. He, D. Ramanan, and G. Shi. Hdmi: Learning interactive humanoid whole-body control from human videos.arXiv preprint arXiv:2509.16757, 2025
arXiv 2025
-
[13]
S. Zhao, Y . Ze, Y . Wang, C. K. Liu, P. Abbeel, G. Shi, and R. Duan. Resmimic: From gen- eral motion tracking to humanoid whole-body loco-manipulation via residual learning.arXiv preprint arXiv:2510.05070, 2025
arXiv 2025
-
[14]
B. Wen, S. Dewan, and S. Birchfield. Fast-FoundationStereo: Real-time zero-shot stereo matching.CVPR, 2026. 10
2026
- [15]
-
[16]
Y . Ze, S. Zhao, W. Wang, A. Kanazawa, R. Duan, P. Abbeel, G. Shi, J. Wu, and C. K. Liu. Twist2: Scalable, portable, and holistic humanoid data collection system.arXiv preprint arXiv:2511.02832, 2025
arXiv 2025
-
[17]
Z. Luo, Y . Yuan, T. Wang, C. Li, S. Chen, F. Casta ˜neda, Z.-A. Cao, J. Li, D. Minor, Q. Ben, X. Da, R. Ding, C. Hogg, L. Song, E. Lim, E. Jeong, T. He, H. Xue, W. Xiao, Z. Wang, S. Yuen, J. Kautz, Y . Chang, U. Iqbal, L. Fan, and Y . Zhu. Sonic: Supersizing motion tracking for natural humanoid whole-body control.arXiv preprint arXiv:2511.07820, 2025
Pith/arXiv arXiv 2025
-
[18]
Darpa robotics challenge (drc)
Defense Advanced Research Projects Agency (DARPA). Darpa robotics challenge (drc). https://www.darpa.mil/research/programs/darpa-robotics-challenge, 2026
2026
- [19]
-
[20]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust per- ceptive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022
2022
-
[21]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model.arXiv preprint arXiv:2411.14386, 2024
arXiv 2024
-
[22]
Hoeller, N
D. Hoeller, N. Rudin, D. Sako, and M. Hutter. Anymal parkour: Learning agile navigation for quadrupedal robots.Science Robotics, 9(88):eadi7566, 2024
2024
-
[23]
J. He, C. Zhang, F. Jenelten, R. Grandia, M. B ¨acher, and M. Hutter. Attention-based map encoding for learning generalized legged locomotion.Science Robotics, 10(105):eadv3604, 2025
2025
-
[24]
Fankhauser, M
P. Fankhauser, M. Bloesch, and M. Hutter. Probabilistic terrain mapping for mobile robots with uncertain localization.IEEE Robotics and Automation Letters, 3(4):3019–3026, 2018
2018
-
[25]
Q. Ben, B. Xu, K. Li, F. Jia, W. Zhang, J. Wang, J. Wang, D. Lin, and J. Pang. Gallant: V oxel grid-based humanoid locomotion and local-navigation across 3d constrained terrains.arXiv preprint arXiv:2511.14625, 2025
arXiv 2025
-
[26]
Agarwal, A
A. Agarwal, A. Kumar, J. Malik, and D. Pathak. Legged locomotion in challenging terrains using egocentric vision. InProceedings of The 6th Conference on Robot Learning, volume 205 ofProceedings of Machine Learning Research, pages 403–415. PMLR, 14–18 Dec 2023
2023
- [27]
- [28]
-
[29]
R. Yang, M. Zhang, N. Hansen, H. Xu, and X. Wang. Learning vision-guided quadrupedal lo- comotion end-to-end with cross-modal transformers.arXiv preprint arXiv:2107.03996, 2021
arXiv 2021
-
[30]
Z. Wu, X. Huang, L. Yang, Y . Zhang, X. Chen, P. Abbeel, R. Duan, A. Kanazawa, C. Sferrazza, G. Shi, and C. K. Liu. Perceptive humanoid parkour: Chaining dynamic human skills via motion matching.arXiv preprint arXiv:2602.15827, 2026
Pith/arXiv arXiv 2026
-
[31]
Z. Zhang, K. Wen, M. Xu, J. He, C. Li, T. Miki, C. Schwarke, C. Zhang, X. B. Peng, and M. Hutter. Learning whole-body humanoid locomotion via motion generation and motion tracking.arXiv preprint arXiv:2604.17335, 2026. 11
Pith/arXiv arXiv 2026
-
[32]
X. B. Peng, P. Abbeel, S. Levine, and M. van de Panne. Deepmimic: Example-guided deep reinforcement learning of physics-based character skills.ACM Trans. Graph., 37(4):143:1– 143:14, 2018
2018
-
[33]
Q. Liao, T. E. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyondmimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025
Pith/arXiv arXiv 2025
-
[34]
S. Ross, G. Gordon, and D. Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 627–635. PMLR, 2011
2011
-
[35]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[36]
M. Macklin. Warp: A high-performance python framework for gpu simulation and graphics, Mar. 2022. URLhttps://github.com/NVIDIA/warp. NVIDIA GPU Technology Confer- ence (GTC)
2022
-
[37]
S. Zhu, Z. Zhuang, M. Zhao, K.-Y . Lee, and H. Zhao. Hiking in the wild: A scalable perceptive parkour framework for humanoids.arXiv preprint arXiv:2601.07718, 2026
arXiv 2026
- [38]
- [39]
-
[40]
Mahmood, N
N. Mahmood, N. Ghorbani, N. F. Troje, G. Pons-Moll, and M. J. Black. AMASS: Archive of motion capture as surface shapes. InInternational Conference on Computer Vision, pages 5442–5451, 2019
2019
-
[41]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[42]
L. Yang, X. Huang, Z. Wu, A. Kanazawa, P. Abbeel, C. Sferrazza, C. K. Liu, R. Duan, and G. Shi. Omniretarget: Interaction-preserving data generation for humanoid whole-body loco- manipulation and scene interaction.arXiv preprint arXiv:2509.26633, 2025. 12 A Method A.1 Learning Multiple Expert Policies from a Single Reference Motion In this stage, our goal...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.