Evolving Agents in the Dark: Retrospective Harness Optimization via Self-Preference
Pith reviewed 2026-06-28 01:38 UTC · model grok-4.3
The pith
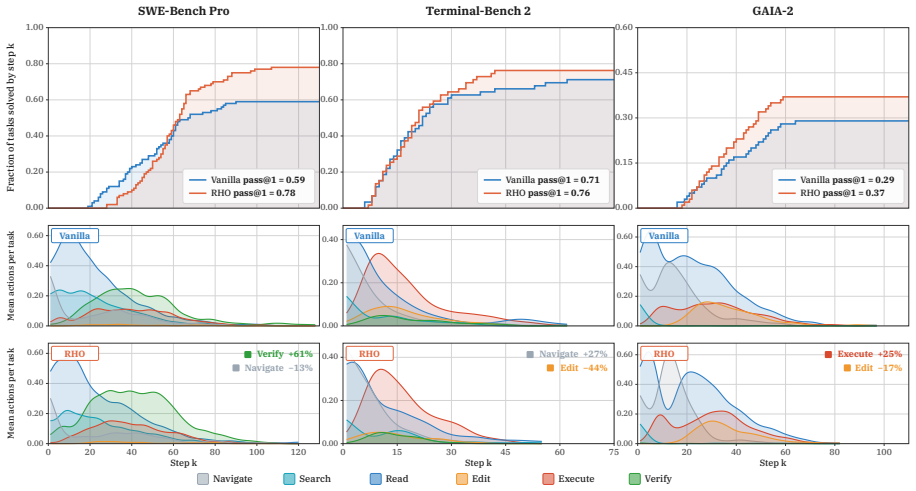
Retrospective Harness Optimization improves agent pass rates on benchmarks like SWE-Bench Pro from 59% to 78% using only past trajectories and self-preference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
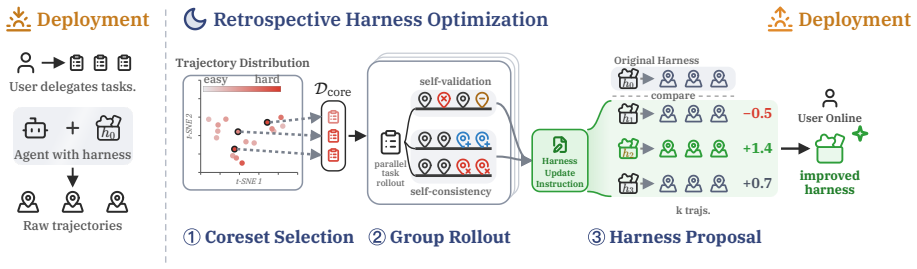
RHO selects a diverse coreset of challenging tasks from past trajectories and re-solves them in parallel. The agent then analyzes these rollouts using self-validation and self-consistency, generates candidate harness updates, and selects the most effective update through its own pairwise self-preference. This process improves the agent's pass rate on SWE-Bench Pro from 59% to 78% without external grading, targets prior failure modes, alters behavior patterns, and sustains higher accuracy in long-horizon sessions.
What carries the argument
Retrospective Harness Optimization (RHO), a loop that extracts a coreset from past trajectories, re-solves them, applies self-validation and self-consistency, and ranks updates by self-preference to evolve the agent's harness.
If this is right
- The optimized harness alters the agent's behavior patterns.
- Higher accuracy is sustained during long-horizon sessions.
- RHO effectively targets prior failure modes across software engineering, technical work, and knowledge work.
- A single optimization round produces the reported gains without external grading.
- Performance improves when the method is applied to past trajectories alone.
Where Pith is reading between the lines
- Agents could apply RHO repeatedly to their own logged sessions to keep improving after deployment.
- The same self-preference loop might reduce reliance on human-curated validation sets for other agent-tuning tasks.
- RHO's coreset selection could be combined with external signals if they become available later, without changing the core loop.
- Similar retrospective self-judgment might apply to non-agent systems that maintain internal consistency metrics over sequences of outputs.
Load-bearing premise
The agent's internal self-validation and self-consistency checks can reliably distinguish effective harness updates from ineffective ones when no ground-truth labels are available.
What would settle it
Run RHO on a benchmark with held-out tasks whose correct solutions are known in advance, then measure whether the self-preferred harness update outperforms a randomly chosen update or a no-update baseline on those tasks.
Figures


read the original abstract
AI agents rely on a harness of skills, tools, and workflows to solve complex problems. Continually improving this harness is essential for adapting to new tasks. However, existing optimization methods typically require ground-truth validation sets, yet such labeled data is difficult to acquire in practical deployment settings. To address this problem, we introduce Retrospective Harness Optimization (RHO), a self-supervised method that optimizes the agent harness using only past trajectories. Specifically, RHO selects a diverse coreset of challenging tasks from past trajectories and re-solves them in parallel. The agent analyzes these rollouts using self-validation and self-consistency, then generates candidate harness updates and selects the most effective one by its own pairwise self-preference. We evaluate RHO across three diverse domains, spanning software engineering, technical work, and knowledge work. Notably, a single optimization round improves the pass rate on SWE-Bench Pro from 59% to 78% without any external grading. Furthermore, our analysis demonstrates that RHO effectively targets prior failure modes. As a result, the optimized harness alters the agent's behavior patterns and sustains higher accuracy during long-horizon sessions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Retrospective Harness Optimization (RHO), a self-supervised method for improving an AI agent's harness of skills, tools, and workflows. RHO extracts a diverse coreset from past trajectories, re-solves the tasks in parallel, applies self-validation and self-consistency analysis to the rollouts, generates candidate harness updates, and selects the best update via the agent's own pairwise self-preference. It claims that a single round of RHO raises the pass rate on SWE-Bench Pro from 59% to 78% with no external grading, demonstrates effectiveness across software engineering, technical work, and knowledge work domains, and shows that the optimized harness targets prior failure modes while sustaining higher accuracy in long-horizon sessions.
Significance. If the reported gains prove robust to controls for self-assessment bias, the result would be significant for practical agent deployment in settings where ground-truth validation data is unavailable, offering a route to continual harness adaptation based solely on retrospective trajectories.
major comments (3)
- [Abstract] Abstract: the central empirical claim (59%→78% pass-rate lift on SWE-Bench Pro after one RHO round) is presented without any mention of baseline comparisons, random-update controls, or oracle-selected updates measured on the same coreset; this omission prevents evaluation of whether self-preference actually outperforms alternatives on ground-truth metrics.
- [Method] Method description (as summarized in abstract): the selection step relies exclusively on the agent's internal self-validation, self-consistency, and pairwise self-preference; no external anchor or correlation analysis is supplied to show that these signals predict held-out benchmark success rather than merely reinforcing prior behavioral patterns (e.g., longer traces or syntactically familiar updates).
- [Evaluation] Evaluation claim: the statement that RHO 'effectively targets prior failure modes' and 'alters the agent's behavior patterns' is asserted without quantitative evidence that the chosen harness update improves actual task completion rates on unseen instances rather than only internal consistency scores.
minor comments (2)
- The manuscript should include a dedicated limitations paragraph addressing the risk that self-preference may optimize for spurious internal metrics.
- Clarify the exact size and selection criteria of the 'diverse coreset' and the number of parallel rollouts performed per optimization round.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, clarifying the evidence presented and indicating where revisions will strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim (59%→78% pass-rate lift on SWE-Bench Pro after one RHO round) is presented without any mention of baseline comparisons, random-update controls, or oracle-selected updates measured on the same coreset; this omission prevents evaluation of whether self-preference actually outperforms alternatives on ground-truth metrics.
Authors: We agree that the abstract would benefit from explicit reference to the controls. The full manuscript (Section 4.2) reports comparisons of self-preference against random harness updates and alternative selection strategies evaluated on the identical coreset using ground-truth pass rates. We will revise the abstract to note these comparisons. revision: yes
-
Referee: [Method] Method description (as summarized in abstract): the selection step relies exclusively on the agent's internal self-validation, self-consistency, and pairwise self-preference; no external anchor or correlation analysis is supplied to show that these signals predict held-out benchmark success rather than merely reinforcing prior behavioral patterns (e.g., longer traces or syntactically familiar updates).
Authors: RHO is intentionally label-free. We demonstrate that the resulting harness yields higher pass rates on held-out benchmarks, but we acknowledge the absence of an explicit correlation study between self-preference scores and ground-truth success. We can add such an analysis during revision using the existing rollout data. revision: partial
-
Referee: [Evaluation] Evaluation claim: the statement that RHO 'effectively targets prior failure modes' and 'alters the agent's behavior patterns' is asserted without quantitative evidence that the chosen harness update improves actual task completion rates on unseen instances rather than only internal consistency scores.
Authors: The reported 59% to 78% improvement is measured on the complete SWE-Bench Pro benchmark after optimization on a coreset drawn from prior trajectories; the benchmark instances are disjoint from the coreset. Section 5 further quantifies per-category gains on previously failed task types, providing direct evidence of improved completion rates on unseen tasks. revision: no
Circularity Check
No circularity: empirical gain measured on external benchmark
full rationale
The paper presents RHO as a self-supervised procedure that selects harness updates via internal self-validation, self-consistency and pairwise self-preference on past trajectories. The central empirical claim—an increase from 59% to 78% pass rate on SWE-Bench Pro—is evaluated against an external, held-out benchmark that is never used inside the selection loop. No equation, definition or selection step equates the reported external improvement to the internal preference signal by construction. The method therefore remains falsifiable by the external metric and does not reduce to a renaming or self-reinforcement of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
SWE-Bench Pro: Can AI agents solve long- horizon software engineering tasks?arXiv preprint arXiv:2509.16941. Sebastian Farquhar, Jannik Kossen, Lorenz Kuhn, and Yarin Gal. 2024. Detecting hallucinations in large language models using semantic entropy.Nature, 630:625–630. Romain Froger and 1 others. 2026. Gaia2: Benchmark- ing LLM agents on dynamic and asy...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Minhua Lin, Zhiwei Zhang, Hanqing Lu, Hui Liu, Xianfeng Tang, Qi He, Xiang Zhang, and Suhang Wang
Sleep-time compute: Beyond inference scaling at test-time.arXiv preprint arXiv:2504.13171. Minhua Lin, Zhiwei Zhang, Hanqing Lu, Hui Liu, Xianfeng Tang, Qi He, Xiang Zhang, and Suhang Wang. 2026. MemMA: Coordinating the memory cycle through multi-agent reasoning and in-situ self- evolution.arXiv preprint arXiv:2603.18718. Zhichao Liu, Wenbo Pan, Haining Y...
-
[3]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as operating sys- tems.arXiv preprint arXiv:2310.08560. Wenbo Pan, Shujie Liu, Xiangyang Zhou, Shiwei Zhang, Wanlu Shi, Mirror Xu, and Xiaohua Jia. 2026a. M⋆: Every task deserves its own memory harness.arXiv preprint arXiv:2604.11811. Wenbo Pan, Zhichao Liu, Xianlong Wang, Haining Yu, and Xiaohua Jia. 2026b. Towards long-horizon inter...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Can LLMs Refuse Questions They Do Not Know? Measuring Knowledge-Aware Refusal in Factual Tasks
Can LLMs refuse questions they do not know? Measuring knowledge-aware refusal in factual tasks. arXiv preprint arXiv:2510.01782. Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. 2024. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.arXi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Familiarize yourself with the information and available tools in harness/
-
[6]
Read and analyze task/prompt.md
-
[7]
For code repair tasks, modify files directly under ,→task/repo/
Complete the task. For code repair tasks, modify files directly under ,→task/repo/
-
[8]
difficulty
Present your final answer in your last message, in the format prompt.md ,→specifies (or plain prose if unspecified). B.2 Coreset Selection (Difficulty Judge) The difficulty judge produces the score ri ∈[0,10] and the abstract fingerprint ϕi that drive the DPP coreset selector of §4.1. It sees the task description together with a length-bounded digest of o...
-
[9]
Inspect final_message.txt and events.jsonl to understand the action and ,→decision process
-
[10]
Evaluate whether the trajectory accurately and efficiently completed the ,→task
-
[11]
Set successful to 1 if the trajectory accurately completed the task, ,→otherwise set it to 0
-
[12]
task_id":
In quality_analysis, note what evidence, files, tools, or reasoning steps ,→the trajectory relied on, and whether there was unnecessary work, missed ,→information, misleading evidence, or an incorrect decision. ## Step 2: Analyze failure modes If all three trajectories accurately and efficiently completed the task, this ,→section can be brief. Otherwise, ...
-
[13]
Read each diagnosis in diagnoses/task_XXXX/diagnosis.md and the ,→corresponding prompt.md
-
[14]
Higher severity means the diagnosis should influence optimization ,→more strongly
Use Severity as a soft attention weight from 0.00 to 1.00, not as ground ,→truth. Higher severity means the diagnosis should influence optimization ,→more strongly
-
[15]
Look for patterns across diagnoses - are multiple tasks failing for similar ,→reasons?
-
[16]
Prioritize high-severity recurring failure modes and high-severity recurring ,→inconsistency root causes
-
[17]
Low-severity tasks usually should not cause a harness edit by themselves ,→unless the same issue motif recurs across tasks
-
[18]
15 When done, send the changes and your rationale as your final message
Make surgical improvements to harness/ that address the high-level diagnosed ,→issues. 15 When done, send the changes and your rationale as your final message. If you ,→made no changes, explain why the current harness is already sufficient. Each diagnoses/task_XXXX/ subdirectory holds the serialized diagnosis JSON rendered as Mark- down alongside the orig...
-
[19]
Read task/prompt.md to understand what the task requires
-
[20]
value": <integer in [-10, 10]>,
Read and compare trajectory_A and trajectory_B. Your final reply must be exactly one JSON object (no markdown fences, no other ,→text): {"value": <integer in [-10, 10]>, "rationale": "<one-sentence rationale>"} The candidate score Sj in Algorithm 1 averages this integer (with the orientation flip described above) over the coreset Dcore, and the candidate ...
2012
-
[21]
for fingerprint or query embedding. We execute the encoder locally, so these calls do not hit a remote endpoint and are not aggregated with 21 Table 7: Agent invocations by role for the optimization phase on SWE-Bench Pro (k= 10 train tasks, Mtest = 100 held-out tasks).ROLLOUTis G parallel solves per coreset task,AFTERis one solve per candidate per corese...
2025
-
[22]
The matched-budget configuration we report in Table 2 reduces this to I= 1 , C= 3 , T= 1 , amounting to MsearchT+I(1 +CM searchT) = 10 + 31 = 41 optimization-phase invocations; this is the configuration whose held-out pass rate (0.62 on SWE-Bench Pro) is reported alongside RHO’s in the main text. The 10-round configu- ration reported in the same table kee...
2025
-
[23]
Read the prompt as a contract. Write a short requirement ledger covering: exact public names, file paths, payload shapes, errors/status codes, default values, supported backends/platforms, and called-out edge cases
-
[24]
Prefer adapting proven behavior over guessing
Look for an existing reference when the task sounds like a known fix: local git history, tags, upstream commits, tests, fixtures, or nearby implementation patterns. Prefer adapting proven behavior over guessing
-
[25]
Follow stored data back to user-visible artifacts, config values back to their runtime representation, and wrappers back to the implementation that actually executes
Trace the real path end to end before editing. Follow stored data back to user-visible artifacts, config values back to their runtime representation, and wrappers back to the implementation that actually executes
-
[26]
Keep generated files, caches, temporary smoke tests, and local environment output out of the submitted diff
Make the smallest production-source change that satisfies the contract. Keep generated files, caches, temporary smoke tests, and local environment output out of the submitted diff
-
[27]
Syntax checks are not enough: run at least one focused smoke that calls every new public route/function/method and covers each explicit failure/edge condition in the prompt
Verify executable behavior. Syntax checks are not enough: run at least one focused smoke that calls every new public route/function/method and covers each explicit failure/edge condition in the prompt
-
[28]
0"‘ and ‘
Re-open the requirement ledger before the final answer. Check literal API names, response shapes, defaults, cleanup behavior, and every backend or platform named by the prompt. ## Tools - ‘harness/bin/repair-verify‘ discovers common non-PATH toolchains, runs cheap language checks, reports generated artifacts, and accepts extra task-specific commands. - ‘h...
-
[29]
Extract the contract from the prompt: - final artifacts and exact paths, usually under ‘/app‘ - exact command(s) or invocation style the grader may use - allowed and forbidden files; treat ‘test/‘ and ‘tests/‘ as different names - whether the task is black-box/API-only, reverse engineering, package ,→repair, system setup, or stochastic implementation
-
[30]
It avoids quoting failures and leaves a useful command trail in ,→‘/host-ws‘
Use the host-to-container script pattern from the prompt for nontrivial ,→commands. It avoids quoting failures and leaves a useful command trail in ,→‘/host-ws‘
-
[31]
Readable
Inspect only sources that are consistent with the task. "Readable" is not ,→the same as "methodologically allowed."
-
[32]
by ,→making queries
Start with a tiny reproducible probe, then scale to the full input. Save ,→intermediate scripts, logs, and validation commands in the host workspace ,→when useful. ## Integrity Boundaries For tasks framed as black-box recovery, model extraction, API querying, or "by ,→making queries": - Do not read implementation internals to recover hidden parameters, co...
-
[33]
Read the user request through AgentUserInterface, not the Codex prompt or ,→‘poll‘ alone: ‘‘‘bash python task/tools/are.py call AgentUserInterface get_all_messages --json ’{}’ ‘‘‘
-
[34]
Avoid dumping the ,→full ‘are.py list‘ output unless the catalog is missing or corrupt
Read ‘task/tools/catalog.json‘ for app and function names. Avoid dumping the ,→full ‘are.py list‘ output unless the catalog is missing or corrupt
-
[35]
today",
Get the simulated current time before resolving relative dates, windows, ,→"today", "this month", or deadline math: ‘‘‘bash python task/tools/are.py call SystemApp get_current_time --json ’{}’ ‘‘‘ 35
-
[36]
For each needed function, inspect its exact schema before calling it: ‘‘‘bash python task/tools/are.py schema <AppName> <function_name> ‘‘‘
-
[37]
Then email X that the cab was ordered
Do not read ‘task/.gaia2/scenario.json‘. Avoid broad ‘.gaia2_state‘ or ,→sidecar-log inspection; use app APIs unless normal APIs cannot expose ,→required evidence. ## Request Decomposition Before writes, make a short private checklist: - Mandatory writes: every send, create, delete, order, move, booking, or final ,→user reply that must happen. - Condition...
-
[38]
Enumerate the candidates with stable identifiers and distinguishing metadata
-
[39]
If the user told you to clarify on issues, ask through AgentUserInterface ,→and wait only as long as the task gives you a deadline or the environment ,→convention requires
-
[40]
Complete unambiguous parts, report the ,→unresolved blocker to the user through AgentUserInterface, and do not ,→perform the ambiguous write
For irreversible external actions such as sending email, deleting ,→files/events, ordering products, or booking rides, do not invent a ,→fallback after no clarification. Complete unambiguous parts, report the ,→unresolved blocker to the user through AgentUserInterface, and do not ,→perform the ambiguous write
-
[41]
reply at 2024-10-15 ,→07:04:00; add to cart at 07:04:30
Only use a fallback when the user specified it or the app data gives a ,→single unambiguous, documented rule. ## Timing And Waiting Treat timing constraints as first-class requirements. 36 - Compute absolute deadlines from the user message timestamp/current simulated ,→time before doing other work. - Keep exact target times visible in notes, for example "...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.