SkillComposer: Learning to Evolve Agent Skills for Specification and Generalization
Pith reviewed 2026-06-28 01:26 UTC · model grok-4.3
The pith
SkillComposer trains language models to create, improve, and merge skills so agents perform better and generalize to new tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
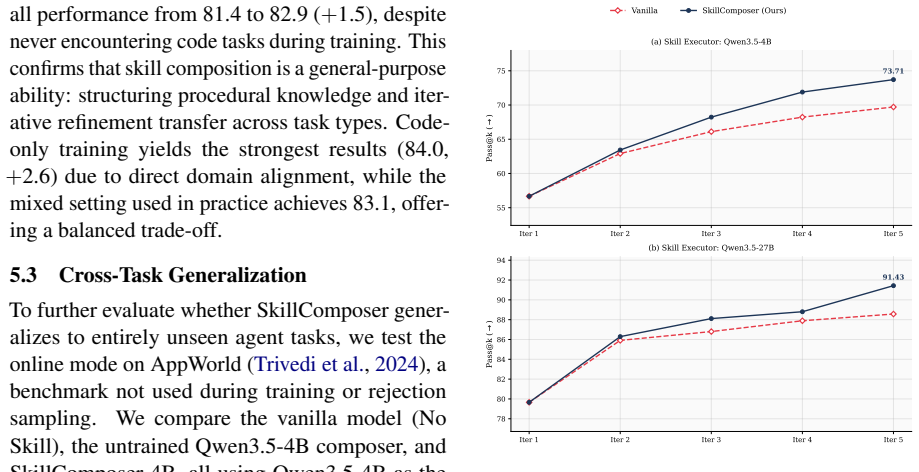
SkillComposer decomposes skill construction into create, improve, and merge operations trained via systematic rejection sampling, allowing language models to self-evolve skills at inference time in offline, online, or hybrid modes; the resulting 4B model raises a 27B executor's scores by up to 4.5 on agent tasks and 3.4 on code tasks while generalizing across domains and task types absent from training.
What carries the argument
The SkillComposer framework that learns the three operations create, improve, and merge to evolve agent skills.
If this is right
- A 4B SkillComposer model can raise a 27B executor's performance by up to 4.5 points on agent benchmarks and 3.4 on code benchmarks.
- The framework supports three deployment modes—offline library building, online task refinement, and hybrid—that can be chosen per use case.
- Merge and improve operations target orthogonal quality dimensions of skills.
- Skill composition functions as a transferable meta-ability that works across domains and task types not seen in training.
Where Pith is reading between the lines
- Smaller models could serve as reusable skill composers for much larger executors without retraining the executor itself.
- The same create-improve-merge recipe might extend to non-agent domains such as tool-use chains or multi-step reasoning traces.
- Explicit decomposition into composition operations may be more important for transfer than the size of the skill library alone.
Load-bearing premise
Systematic rejection sampling reliably produces create, improve, and merge behaviors that yield transferable skills rather than skills overfit to the training task distribution.
What would settle it
Train SkillComposer on one set of tasks and test whether the evolved skills raise performance on a held-out domain or task type where the baseline executor shows no gain.
Figures





read the original abstract
Agent skills, which consist of reusable strategies that guide agent reasoning and action, have shown strong potential for improving model capability at inference time. However, current skill construction methods treat the problem as one-shot extraction, overlooking a fundamental tension: a skill tailored to the specific task fails to transfer, while the abstracted skill often provides insufficient guidance. We attribute this fragility to the absence of explicit mechanisms for skill specification and generalization. To address this gap, we introduce SkillComposer, a framework that decomposes skill construction into three learnable operations: create, improve, and merge. Trained via systematic rejection sampling recipe, SkillComposer enables language models to self-evolve skills at inference time and supports three deployment modes: offline for building generalized libraries, online for task-specific refinement, and hybrid for combining both. Comprehensive experiments on $\tau^2$-Bench, LiveCodeBench v6, and AppWorld show that SkillComposer consistently outperforms baselines. Our SkillComposer-4B improves a 27B executor by up to +4.5 on agent tasks and +3.4 on code tasks, while generalizing across domains and task types unseen during training. Analysis reveals that merge and improve address orthogonal quality dimensions and that skill composition is a transferable meta-ability, providing a practical recipe for skill-augmented inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillComposer, a framework decomposing skill construction into three learnable operations (create, improve, merge) trained via systematic rejection sampling. This enables language models to self-evolve skills at inference time across offline, online, and hybrid deployment modes. Experiments on τ²-Bench, LiveCodeBench v6, and AppWorld report that SkillComposer-4B improves a 27B executor by up to +4.5 on agent tasks and +3.4 on code tasks while generalizing to unseen domains and task types; analysis claims merge and improve address orthogonal quality dimensions and that skill composition is a transferable meta-ability.
Significance. If the central empirical claims hold after verification of controls and generalization mechanisms, the work would supply a concrete recipe for skill-augmented inference and a decomposition that separates specification from abstraction issues in agent skills. The reported gains on a smaller composer model boosting a larger executor, plus the orthogonal-dimensions finding, would be of practical interest for agent and code-generation systems.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the reported gains (+4.5 agent, +3.4 code) and generalization to unseen domains rest on unspecified training/evaluation procedures, baseline implementations, statistical significance tests, and data-exclusion rules. Without these, it is impossible to assess whether the rejection-sampling targets produced transferable meta-operations or merely task-specific skills.
- [§3 and §5] §3 (Method) and §5 (Analysis): the claim that systematic rejection sampling on create/improve/merge yields a generalizable meta-ability (rather than overfitting to surface features of the training-task distribution) is load-bearing for the generalization results, yet no diagnostic is provided to test whether the sampling criterion correlates with task-specific cues versus abstract skill quality.
minor comments (2)
- [Abstract] The abstract states three deployment modes but does not indicate which mode(s) were used for the reported benchmark numbers or how the modes were ablated.
- [§3] Notation for the three operations and the rejection-sampling recipe should be formalized with explicit pseudocode or equations to make the training procedure reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments point by point below, providing clarifications from the manuscript and indicating where expansions will be made.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported gains (+4.5 agent, +3.4 code) and generalization to unseen domains rest on unspecified training/evaluation procedures, baseline implementations, statistical significance tests, and data-exclusion rules. Without these, it is impossible to assess whether the rejection-sampling targets produced transferable meta-operations or merely task-specific skills.
Authors: The training and evaluation procedures are specified in §3.2 (rejection sampling recipe with explicit quality thresholds for create/improve/merge) and §4 (including executor model sizes, deployment modes, and task distributions). Baseline implementations are described in §4.1 with references to standard agent prompting methods. Statistical significance uses paired bootstrap tests (1000 resamples) reported alongside Table 2 results. Data-exclusion rules in §4.2 explicitly remove any training-domain overlap to enforce unseen-domain evaluation. We will add a consolidated controls subsection in §4 for easier verification. revision: partial
-
Referee: [§3 and §5] §3 (Method) and §5 (Analysis): the claim that systematic rejection sampling on create/improve/merge yields a generalizable meta-ability (rather than overfitting to surface features of the training-task distribution) is load-bearing for the generalization results, yet no diagnostic is provided to test whether the sampling criterion correlates with task-specific cues versus abstract skill quality.
Authors: The primary evidence for a transferable meta-ability is the cross-domain generalization in §4.3: models trained solely on τ²-Bench tasks are evaluated on LiveCodeBench v6 and AppWorld (distinct domains and task types), yielding consistent gains. Section 5 further shows that improve and merge target orthogonal dimensions (specification vs. abstraction), an outcome inconsistent with overfitting to training-task surface features. These empirical outcomes on held-out distributions serve as the diagnostic; an auxiliary cue-correlation analysis is not required to support the claims. revision: no
Circularity Check
No significant circularity; empirical framework with benchmark validation
full rationale
The paper introduces SkillComposer as an empirical training framework that decomposes skill construction into create/improve/merge operations learned via rejection sampling, then evaluates generalization on held-out benchmarks (τ²-Bench, LiveCodeBench, AppWorld) including unseen domains. No equations, derivations, or algebraic reductions appear in the text. Central performance claims (+4.5, +3.4) are measured outcomes on external tasks rather than quantities forced by construction from fitted parameters or self-citations. The rejection-sampling recipe is a data-generation procedure whose success criterion is task completion, not a renaming or self-definition of the target generalization metric. This is the common case of a self-contained empirical paper whose claims rest on experimental falsifiability outside any internal fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Autoforge: Automated environment synthesis for agentic reinforcement learning.arXiv preprint arXiv:2512.22857. Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. 2026. Memp: Exploring agent procedural memory.Preprint, arXiv:2508.06433. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Y...
-
[2]
Agent skills: A data-driven analysis of claude skills for extending large language model functional- ity.CoRR, abs/2602.08004. Hongjun Liu, Yifei Ming, Shafiq Joty, and Chen Zhao. 2026a. Harnessing llm agents with skill programs. Preprint, arXiv:2605.17734. Yujian Liu, Jiabao Ji, Li An, Tommi Jaakkola, Yang Zhang, and Shiyu Chang. 2026b. How well do agen-...
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076, Bangkok, Thai- land
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 16022–16076, Bangkok, Thai- land. Association for Computational Linguistics. Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shu...
-
[4]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Skillx: Automatically constructing skill knowl- edge bases for agents.Preprint, arXiv:2604.04804. Zora Zhiruo Wang, Apurva Gandhi, Graham Neubig, and Daniel Fried. 2025. Inducing programmatic skills for agentic tasks.CoRR, abs/2504.06821. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Ch...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Given a task and a corresponding trajectory generated by a language model, your task is to generate a reusable/generalizable skill based on the 11 Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 56 57 58 59Code Acc. (%) Qwen3.5-4B (Online) Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 53 54 55 56 57 58 59 60 Qwen3.5-4B (Hybrid) Iter 1 Iter 2 Iter 3 Iter 4 Iter 5 79 80 81 82 83 Q...
-
[6]
The reusability/generalizability should be both model-level and task-level: - The skill should help current language model not only solve current task but this type of tasks - The skill should help other language models not only solve current task but this type of tasks [Skill Formulation] The generated skill should consist of three components including n...
-
[9]
**body**: A document in markdown-style. It should contain the name of the skill and several sections with detailed instructions (i.e., what you want the skill to do and roughly how it should do it) to solve this type of tasks. [Skill Create Instructions]
-
[10]
When writing a skill, try to explain to the model why things are important in lieu of heavy-handed musty MUSTs
-
[12]
Start by writing a draft and then look at it with fresh eyes and improve it
-
[13]
‘json {{
Make sure not to introduce any specific concepts, examples or details from the input. [Input Details] Here are the task and the trajectory: 12 ### Task {{task}} ### Trajectory {{trajectory}} [Output Format] Put your final output in a JSON object enclosed by a json code block like: “‘json {{ "name": <skill-name>, "description": <skill-description>, "body":...
-
[14]
Given two seperate skills, your task is to merge them into a more generalizable and reusable skill
-
[15]
The merged skill should cover both the common and diverse instructions within the given two skills. The reusability/generalizability should be both model-level and task-level: - The skill should help current language model not only solve current question but this type of questions - The skill should help other language models not only solve current questi...
-
[18]
**body**: A document in markdown-style. It should contain the name of the skill and several sections with detailed instructions (i.e., what you want the skill to do and roughly how it should do it) to solve this type of tasks. [Skill Merge Instructions]
-
[19]
When merging two skills, try to explain to the model why things are important in lieu of heavy-handed musty MUSTs
-
[20]
Use theory of mind and try to make the skill general and not super-narrow to specific examples
-
[21]
The merged skill should cover both the common and diverse instructions within the given two skills
-
[22]
Merge the two skills into one standalone, executable skill, not a simple combination
-
[23]
Remove overlap and unify similar instructions into the clearest version
-
[24]
‘json {{
Make the final result clearer, cleaner, more reusable and more generalizable than either original skill alone. [Input Details] ### Skill A — name: {name_a} description: {description_a} — {body_a} ### Skill B — name: {name_b} description: {description_b} — {body_b} [Output Format] Put your final output in a JSON object enclosed by a json code block like: “...
-
[25]
Given a question, an original skill, and a corresponding trajectory generated by a language model when injecting this original skill into its context, your task is to generate an improved version of the skill
-
[26]
- Decompose the trajectory’s completion degree: identify specific parts that were executed well and parts that were insufficient or incorrect
The improved skill should maintain its reusability/generalizability at both model-level and task-level: - The skill should help current language model not only solve current question but this type of questions 13 - The skill should help other language models not only solve current question but this type of questions [Expert Analysis Before Improvement] Be...
-
[27]
Once the name is generated, it will never be further modified
**name**: The identifier of the skill. Once the name is generated, it will never be further modified. Therefore, make its name as general and abstract as possible, rather than limiting it to the current input problem and trajectory
-
[28]
when to use
**description**: When to trigger, what it does. This is the primary triggering mechanism - include both what the skill does AND specific contexts for when to use it. All "when to use" info goes here, not in the body
-
[29]
**body**: A document in markdown-style. It should contain the name of the skill and several sections with detailed instructions (i.e., what you want the skill to do and roughly how it should do it) to solve this type of tasks. [Skill Improve Instructions]
-
[30]
Use the original skill as a foundation and produce an improved version that is clearer, more complete, and more reusable
-
[31]
Preserve what already works, strengthen weak or missing guidance, and reflect the lessons from the trajectory
-
[32]
Keep the skill generalizable across similar tasks rather than overfitting to the current example
-
[33]
‘json {{
If the trajectory does not provide useful improvement signal, return the original skill unchanged. [Input Details] Here are the question, the trajectory, and the original skill: ### Question {{question}} ### Trajectory {{trajectory}} ### Skill — name: {name} description: {description} — {body} [Output Format] Put your final output in a JSON object enclose...
-
[34]
Sort `P` (optional optimization)
-
[35]
Maintain `min_cost` function that returns `sum(P[i]*x_i^2)` and `sum(x_i)` for given `x_i` derived from `V`
Binary search for `V` in `[0, M]`. Maintain `min_cost` function that returns `sum(P[i]*x_i^2)` and `sum(x_i)` for given `x_i` derived from `V`
-
[36]
`min_cost(V).cost <= M`
Find max `V` s.t. `min_cost(V).cost <= M`
-
[37]
Take base answer `base_ans = count_from_V(V)`
-
[38]
Compute `rem_budget = M - cost_from_V(V)`
-
[39]
If `cost_for(V+1) > M`, we can potentially add fractional part of `(V+1)` group
Try incrementing `V` slightly or re-evaluating `count` for `V+1`. If `cost_for(V+1) > M`, we can potentially add fractional part of `(V+1)` group. Add `floor(rem_budget / (V+1))` (bounded by actual availability of `(V+1)` items)
-
[40]
Output total. # Quadratic Budget Allocation Optimization ## Overview This skill addresses resource allocation problems where multiple categories of items e xist, each with a quadratic cost function. Unlike linear costs (where you simply pick ch eapest per- unit), here the marginal cost of subsequent units increases linearly (e.g., first unit costs P, secon...
-
[41]
Try mid=4
BS Range [0, 9]. Try mid=4. - For P=4: k=floor((4//4+1)/2)=1. Cost=4.*1=4. - For P=1: k=floor((4//1+1)/2)=2. Cost=1.*4=4. - Total Cost=8 <= 9. Feasible. `best_V`=4. Low=5
-
[42]
Continue BS until converging around 4
-
[43]
Base Units = 3 (1 from P=4, 2 from P=1). Cost=8
-
[44]
Available P=1 units at cost 5? Yes
Next Cost candidate (V+1=5). Available P=1 units at cost 5? Yes. Diff Count > 0
-
[45]
Can afford 5? Rem(1)//5 = 0
-
[46]
Before Skill Improve: Pass@k=0.0 After Skill Improve: Pass@k=1.0 Figure 7: A case study on under-improved skill (left) and improved skill (right)
Final Answer = 3. Before Skill Improve: Pass@k=0.0 After Skill Improve: Pass@k=1.0 Figure 7: A case study on under-improved skill (left) and improved skill (right). 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.