LatentSkill: From In-Context Textual Skills to In-Weight Latent Skills for LLM Agents
Pith reviewed 2026-06-28 01:23 UTC · model grok-4.3
The pith
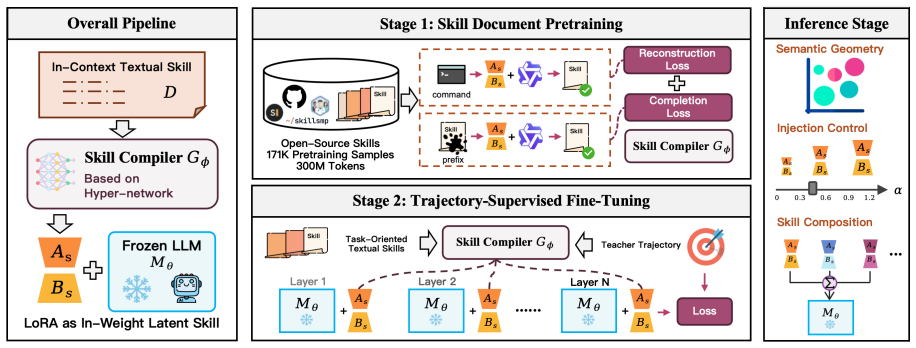
A hypernetwork converts textual skills into LoRA adapters so agents load them in weight space rather than prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
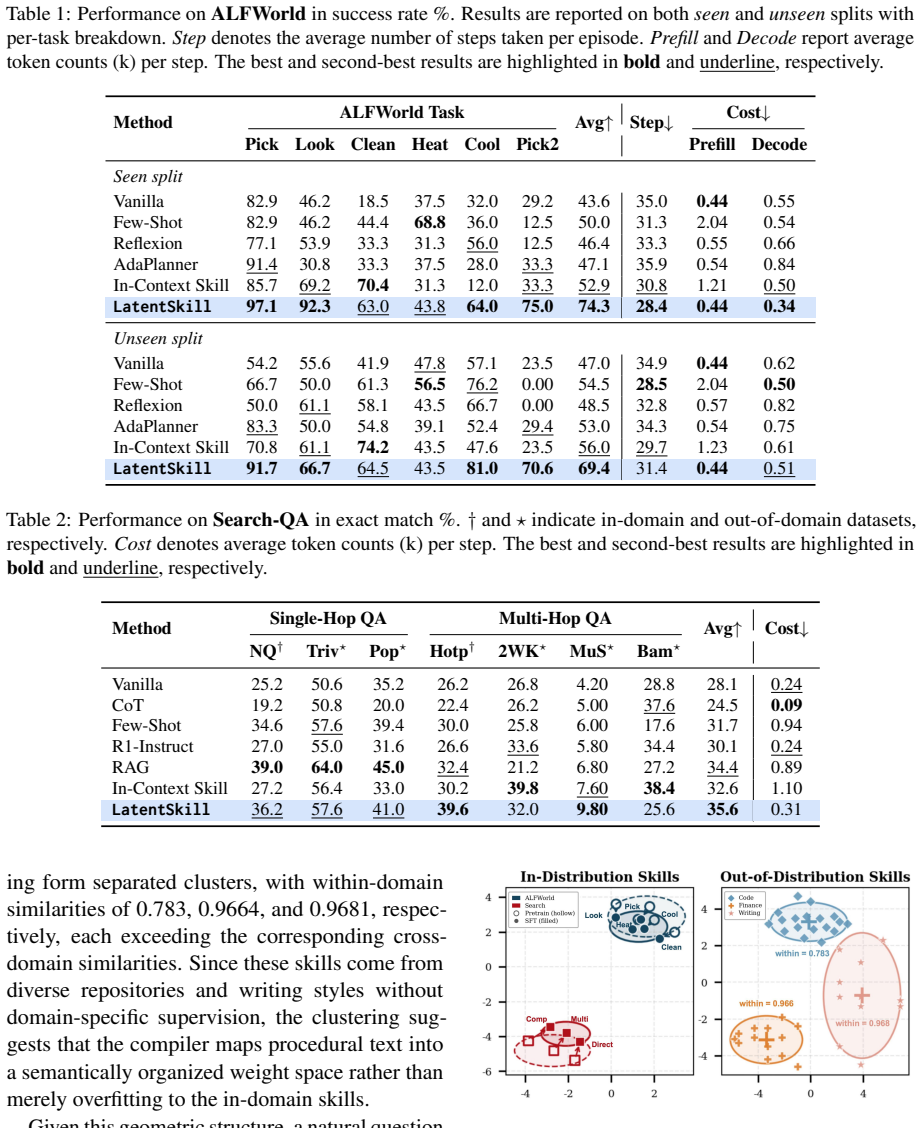
LatentSkill converts textual skills into plug-and-play LoRA adapters through a pretrained hypernetwork. It stores skill knowledge in weight space rather than context space, removing per-step skill tokens while preserving modular loading, scaling, and composition. On ALFWorld and Search-QA the resulting agents outperform the in-context baseline while using substantially fewer prefill tokens.
What carries the argument
A pretrained hypernetwork that maps arbitrary textual skill descriptions to LoRA adapters.
Load-bearing premise
A pretrained hypernetwork can map arbitrary textual skill descriptions to LoRA adapters that preserve the functional modularity, controllability, and composability of the original in-context skills.
What would settle it
Train the hypernetwork on skill descriptions, then compare agent success when the skills are supplied only as generated LoRA adapters versus when the identical skills are supplied as repeated text in every prompt.
Figures


read the original abstract
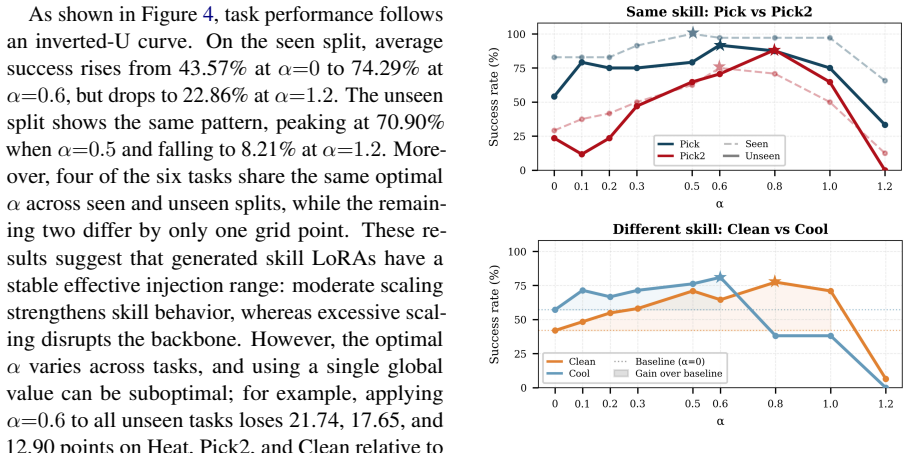
Agent systems increasingly use textual skills to encode reusable task procedures, but injecting these skills into the prompt at every step incurs substantial context overhead and exposes skill content as plaintext. We present LatentSkill, a framework that converts textual skills into plug-and-play LoRA adapters through a pretrained hypernetwork. LatentSkill stores skill knowledge in weight space rather than context space, removing per-step skill tokens while preserving modular loading, scaling, and composition. On ALFWorld and Search-QA, LatentSkill outperforms the corresponding in-context skill baseline while using substantially fewer prefill tokens: it improves ALFWorld success by 21.4 and 13.4 points on the seen and unseen splits with 64.1% fewer prefill tokens, and improves Search-QA exact match by 3.0 points with 72.2% lower skill-token overhead. Further analysis shows that generated skill LoRAs form a structured semantic geometry, can be precisely controlled via the LoRA scaling coefficient, and can be composed through parameter-space arithmetic when skill components are aligned. These findings suggest that weight-space skills provide an efficient, modular, and less exposed substrate for extending LLM agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LatentSkill, a framework that employs a pretrained hypernetwork to convert in-context textual skills into plug-and-play LoRA adapters stored in weight space. This approach aims to eliminate per-step skill tokens from the prompt while preserving modular loading, scaling, and composition. On ALFWorld, it reports success-rate gains of 21.4 and 13.4 points on seen and unseen splits with 64.1% fewer prefill tokens; on Search-QA it reports a 3.0-point exact-match improvement with 72.2% lower skill-token overhead. Additional analysis claims that the generated LoRAs exhibit semantic geometry, admit precise control via the scaling coefficient, and support parameter-space arithmetic composition when skill components align.
Significance. If the hypernetwork faithfully transfers functional skill behavior rather than merely correlating with task-specific effects, the token-efficiency and reduced-exposure benefits would be practically valuable for agent systems. The reported semantic geometry and arithmetic composability, if reproducible, would constitute a non-trivial extension of prior work on modular adaptation. No machine-checked proofs or parameter-free derivations are present, but the empirical token-reduction numbers, if supported by complete ablations, would strengthen the case for weight-space skill representations.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central performance claims (ALFWorld +21.4/13.4 points, Search-QA +3.0 EM) are presented without training details, baseline definitions, statistical tests, or ablation data. This prevents assessment of whether the gains arise from faithful skill transfer or from implicit task adaptation.
- [§3 and §5] §3 (Hypernetwork) and §5 (Analysis): the claim that generated LoRAs preserve exact functional equivalence, modularity, and controllability of the original textual skills is not isolated from task-specific effects. No ablation is reported that holds the base model and training data fixed while varying only the input skill description versus a matched in-context prompt.
minor comments (2)
- [§2] Notation for the hypernetwork input/output mapping and the LoRA scaling coefficient should be defined explicitly in §2 before being used in later sections.
- [Figures] Figure captions for the semantic-geometry visualizations should state the exact dimensionality reduction method and the number of skills plotted.
Simulated Author's Rebuttal
We thank the referee for the thoughtful feedback. We address the two major comments below and will revise the manuscript to incorporate additional experimental details and ablations as requested.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central performance claims (ALFWorld +21.4/13.4 points, Search-QA +3.0 EM) are presented without training details, baseline definitions, statistical tests, or ablation data. This prevents assessment of whether the gains arise from faithful skill transfer or from implicit task adaptation.
Authors: We agree that the current presentation of results would benefit from greater transparency. In the revised manuscript we will expand §4 with: (i) complete hypernetwork training hyperparameters and data sources, (ii) explicit definitions of all baselines including the precise in-context skill prompting protocol, (iii) statistical significance tests (paired t-tests across 5 random seeds) for the reported ALFWorld and Search-QA gains, and (iv) component ablations that isolate the contribution of the hypernetwork versus other factors. These additions will make it possible to evaluate whether the observed improvements stem from faithful skill transfer. revision: yes
-
Referee: [§3 and §5] §3 (Hypernetwork) and §5 (Analysis): the claim that generated LoRAs preserve exact functional equivalence, modularity, and controllability of the original textual skills is not isolated from task-specific effects. No ablation is reported that holds the base model and training data fixed while varying only the input skill description versus a matched in-context prompt.
Authors: We acknowledge that the existing comparison to the in-context baseline does not fully isolate the hypernetwork's transfer fidelity from task-specific adaptation. In the revision we will add a controlled ablation in §5 that fixes the base LLM, training corpus, and downstream task while varying only the textual skill description fed to the hypernetwork versus an equivalent in-context prompt containing the identical skill text. Results from this ablation will be reported alongside the existing semantic-geometry and controllability analyses. revision: yes
Circularity Check
No circularity: empirical results on skill transfer, no derivations or self-referential predictions
full rationale
The paper describes an empirical framework (LatentSkill) that trains a hypernetwork to map textual skill descriptions to LoRA adapters and reports measured improvements on ALFWorld and Search-QA benchmarks. No equations, first-principles derivations, or quantities defined in terms of fitted parameters from the same data appear in the abstract or description. Performance numbers are presented as experimental outcomes, not as quantities forced by construction from inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes smuggled via citation are invoked. The central claim rests on external task measurements rather than tautological reduction to the method's own definitions or fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2023 , eprint=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. 2023 , eprint=
2023
-
[9]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[10]
2024 , eprint=
SWE-bench: Can Language Models Resolve Real-World GitHub Issues? , author=. 2024 , eprint=
2024
-
[11]
arXiv preprint arXiv:2305.16291 , year=
Voyager: An open-ended embodied agent with large language models , author=. arXiv preprint arXiv:2305.16291 , year=
-
[12]
2026 , eprint=
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author=. 2026 , eprint=
2026
-
[13]
2026 , eprint=
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author=. 2026 , eprint=
2026
-
[14]
2026 , eprint=
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle , author=. 2026 , eprint=
2026
-
[15]
2026 , eprint=
SkillOS: Learning Skill Curation for Self-Evolving Agents , author=. 2026 , eprint=
2026
-
[16]
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , title =. Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence and Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence and Fourteenth Symposium on Educational Advances in Artificial Intelligence , articleno =....
-
[17]
2026 , eprint=
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents , author=. 2026 , eprint=
2026
-
[18]
2023 , eprint=
FireAct: Toward Language Agent Fine-tuning , author=. 2023 , eprint=
2023
-
[19]
A gent T uning: Enabling Generalized Agent Abilities for LLM s
Zeng, Aohan and Liu, Mingdao and Lu, Rui and Wang, Bowen and Liu, Xiao and Dong, Yuxiao and Tang, Jie. A gent T uning: Enabling Generalized Agent Abilities for LLM s. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.181
-
[20]
2026 , eprint=
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization , author=. 2026 , eprint=
2026
-
[21]
Greshake, Kai and Abdelnabi, Sahar and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , title =. Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security , pages =. 2023 , isbn =. doi:10.1145/3605764.3623985 , abstract =
-
[22]
2025 , eprint=
Prompt Injection attack against LLM-integrated Applications , author=. 2025 , eprint=
2025
-
[23]
2026 , eprint=
Towards Secure Agent Skills: Architecture, Threat Taxonomy, and Security Analysis , author=. 2026 , eprint=
2026
-
[24]
2026 , eprint=
SHINE: A Scalable In-Context Hypernetwork for Mapping Context to LoRA in a Single Pass , author=. 2026 , eprint=
2026
-
[25]
2016 , eprint=
HyperNetworks , author=. 2016 , eprint=
2016
-
[26]
2021 , eprint=
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
2021
-
[27]
2025 , eprint=
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author=. 2025 , eprint=
2025
-
[28]
2024 , eprint=
Generative Adapter: Contextualizing Language Models in Parameters with A Single Forward Pass , author=. 2024 , eprint=
2024
-
[29]
Text-to-Lo
Rujikorn Charakorn and Edoardo Cetin and Yujin Tang and Robert Tjarko Lange , booktitle=. Text-to-Lo. 2025 , url=
2025
-
[30]
Task-Agnostic Low-Rank Adapters for Unseen E nglish Dialects
Xiao, Zedian and Held, William and Liu, Yanchen and Yang, Diyi. Task-Agnostic Low-Rank Adapters for Unseen E nglish Dialects. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.487
-
[31]
M. H. I. Abdalla and Zhipin Wang and Christian Frey and Steffen Eger and Josif Grabocka , year=. Zhyper: Factorized Hypernetworks for Conditioned
-
[32]
2026 , eprint=
Externalization in LLM Agents: A Unified Review of Memory, Skills, Protocols and Harness Engineering , author=. 2026 , eprint=
2026
-
[33]
2026 , eprint=
SkillRet: A Large-Scale Benchmark for Skill Retrieval in LLM Agents , author=. 2026 , eprint=
2026
-
[34]
LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models
Jiang, Huiqiang and Wu, Qianhui and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili. LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.825
-
[35]
L ong LLML ingua: Accelerating and Enhancing LLM s in Long Context Scenarios via Prompt Compression
Jiang, Huiqiang and Wu, Qianhui and Luo, Xufang and Li, Dongsheng and Lin, Chin-Yew and Yang, Yuqing and Qiu, Lili. L ong LLML ingua: Accelerating and Enhancing LLM s in Long Context Scenarios via Prompt Compression. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024....
-
[36]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Liu, Nelson F. and Lin, Kevin and Hewitt, John and Paranjape, Ashwin and Bevilacqua, Michele and Petroni, Fabio and Liang, Percy. Lost in the Middle: How Language Models Use Long Contexts. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00638
-
[37]
2024 , eprint=
The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions , author=. 2024 , eprint=
2024
-
[38]
A dapter F usion: Non-Destructive Task Composition for Transfer Learning
Pfeiffer, Jonas and Kamath, Aishwarya and R. A dapter F usion: Non-Destructive Task Composition for Transfer Learning. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.39
-
[39]
2024 , eprint=
LoraHub: Efficient Cross-Task Generalization via Dynamic LoRA Composition , author=. 2024 , eprint=
2024
-
[40]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[41]
2021 , eprint=
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author=. 2021 , eprint=
2021
-
[42]
2023 , eprint=
AdaPlanner: Adaptive Planning from Feedback with Language Models , author=. 2023 , eprint=
2023
-
[43]
2025 , eprint=
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning , author=. 2025 , eprint=
2025
-
[44]
2024 , eprint=
Text Embeddings by Weakly-Supervised Contrastive Pre-training , author=. 2024 , eprint=
2024
-
[45]
2023 , eprint=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. 2023 , eprint=
2023
-
[46]
Guo, Daya and Yang, Dejian and Zhang, Haowei and Song, Junxiao and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Zhang, Ruoyu and Ma, Shirong and Bi, Xiao and Zhang, Xiaokang and Yu, Xingkai and Wu, Yu and Wu, Z. F. and Gou, Zhibin and Shao, Zhihong and Li, Zhuoshu and Gao, Ziyi and Liu, Aixin and Xue, Bing and Wang, Bingxuan and Wu, Bochao and Feng, Bei ...
-
[47]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[48]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[49]
T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
Joshi, Mandar and Choi, Eunsol and Weld, Daniel and Zettlemoyer, Luke. T rivia QA : A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. doi:10.18653/v1/P17-1147
-
[50]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[51]
H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[52]
Ho, Xanh and Duong Nguyen, Anh-Khoa and Sugawara, Saku and Aizawa, Akiko. Constructing A Multi-hop QA Dataset for Comprehensive Evaluation of Reasoning Steps. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.580
-
[53]
♫ M u S i Q ue: Multihop Questions via Single-hop Question Composition
Trivedi, Harsh and Balasubramanian, Niranjan and Khot, Tushar and Sabharwal, Ashish. M u S i Q ue: Multihop Questions via Single-hop Question Composition. Transactions of the Association for Computational Linguistics. 2022. doi:10.1162/tacl_a_00475
-
[54]
Measuring and Narrowing the Compositionality Gap in Language Models
Press, Ofir and Zhang, Muru and Min, Sewon and Schmidt, Ludwig and Smith, Noah and Lewis, Mike. Measuring and Narrowing the Compositionality Gap in Language Models. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.378
-
[55]
2025 , eprint=
Text-to-LoRA: Instant Transformer Adaption , author=. 2025 , eprint=
2025
-
[56]
2024 , eprint=
In-context Autoencoder for Context Compression in a Large Language Model , author=. 2024 , eprint=
2024
-
[57]
2026 , eprint=
Doc-to-LoRA: Learning to Instantly Internalize Contexts , author=. 2026 , eprint=
2026
-
[58]
2026 , eprint=
SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration , author=. 2026 , eprint=
2026
-
[59]
2026 , eprint=
SkillMAS: Skill Co-Evolution with LLM-based Multi-Agent System , author=. 2026 , eprint=
2026
-
[60]
2026 , eprint=
Skills on the Fly: Test-Time Adaptive Skill Synthesis for LLM Agents , author=. 2026 , eprint=
2026
-
[61]
2025 , eprint=
A Survey of AI Agent Protocols , author=. 2025 , eprint=
2025
-
[62]
2026 , eprint=
MMSkills: Towards Multimodal Skills for General Visual Agents , author=. 2026 , eprint=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.