Multi-Resolution Tactile Imitation Learning for Contact-Rich Robotic Manipulation
Pith reviewed 2026-06-28 00:55 UTC · model grok-4.3
The pith
Multi-resolution tactile sensing fuses heterogeneous sensors to reach 80% success in contact-rich robotic manipulation where vision alone reaches 31%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
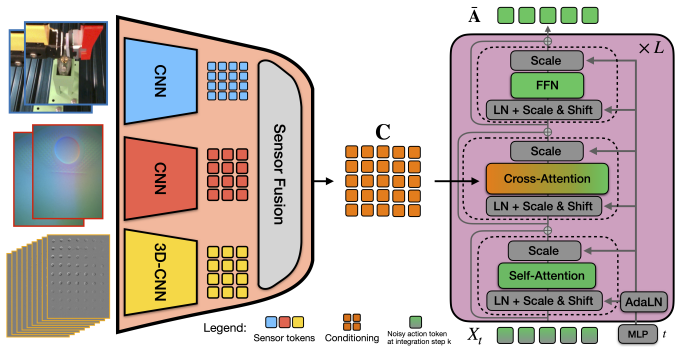
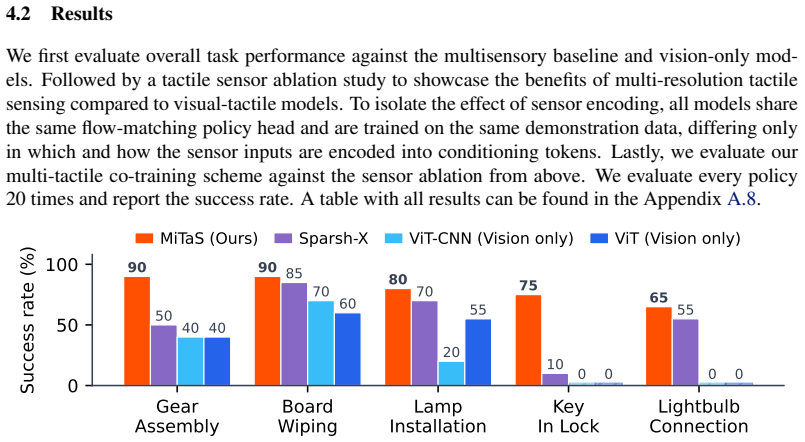
MiTaS uses modality-specific convolutional stems and transformer-based fusion to integrate RGB camera data with a vision-based GelSight Mini sensor and a high-frequency event-based Evetac sensor, then conditions a flow-matching policy on this representation. Across five contact-rich manipulation tasks this yields an average 80% success rate, compared with 31% for vision-only and 54% for visual-tactile baselines. Co-training a visuo-tactile model with the additional multi-tactile data improves performance by more than 10% on some tasks without requiring the Evetac sensor during policy execution.
What carries the argument
Modality-specific convolutional stems plus transformer fusion that combines RGB, GelSight Mini, and Evetac streams at different temporal resolutions to condition a flow-matching policy.
If this is right
- MiTaS achieves 80% average success across the five contact-rich tasks.
- Vision-only baselines reach only 31% and visual-tactile baselines reach 54%.
- Co-training with multi-tactile data raises performance by over 10% in certain tasks even when the high-frequency sensor is absent at test time.
- Attention maps show that each sensor contributes at different stages of task execution.
Where Pith is reading between the lines
- High-frequency event sensors may be needed only for data collection, not for final deployment, if co-training is used.
- The same fusion pattern could be tested on additional robot platforms or task families that involve sustained contact.
- If one sensor modality consistently dominates attention maps, future designs could drop the less-used modality after initial training.
Load-bearing premise
The heterogeneous tactile sensors supply complementary information that is not redundant with vision and that the convolutional-stem-plus-transformer architecture can extract and fuse without task-specific tuning.
What would settle it
If the same five tasks are repeated with a policy that receives only the GelSight Mini and RGB data (no Evetac even during training) and the success rate remains at or above 80%, the claim that multi-resolution fusion is required would be falsified.
Figures








read the original abstract
Touch sensing is beneficial for solving a wide variety of manipulation tasks. While there exists a wide range of tactile sensors with different properties, exploiting the fusion of multiple heterogeneous tactile sensors to improve manipulation learning remains underexplored. We present Multi-Resolution Tactile Sensing (MiTaS), a representation framework that leverages multiple tactile sensors operating at different temporal resolutions in order to solve complex contact-rich manipulation tasks. We propose a novel architecture using modality-specific convolutional stems and transformer-based fusion that effectively fuses information from an RGB camera stream, a vision-based GelSight Mini sensor and a high-frequency event-based Evetac sensor. This multi-sensor representation then conditions a flow-matching policy for solving downstream tasks. Experimental results across five contact-rich manipulation tasks demonstrate the effectiveness of multi-resolution tactile features in imitation learning. MiTaS achieves an average success rate of 80 %, while vision-only (31 %) and visual-tactile (54 %) baselines cannot solve the task reliably. Co-training a visuo-tactile model with multi-tactile data boosts performance by over 10 \% in certain tasks, without having access to the Evetac sensor during policy evaluation. A detailed sensor-reading and attention analysis reveals the importance of different sensors throughout task execution, validating our multi-resolution tactile sensing approach. Project Page: http://mitas-touch.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MiTaS, a representation framework for fusing RGB camera data with two heterogeneous tactile sensors (GelSight Mini at standard resolution and high-frequency Evetac event-based sensor) via modality-specific convolutional stems and transformer-based fusion. The fused features condition a flow-matching policy for imitation learning on contact-rich manipulation. It reports an average success rate of 80% across five tasks, outperforming vision-only (31%) and visual-tactile (54%) baselines, with additional results on co-training with multi-tactile data and attention-based sensor analysis.
Significance. If the performance claims hold under rigorous controls, the work would demonstrate the value of multi-resolution tactile sensing for improving imitation learning in contact-rich robotics tasks where vision is insufficient. The attention analysis offers interpretability, and the flow-matching policy is a contemporary choice. The co-training result (boost without Evetac at test time) is a practical strength if replicated.
major comments (3)
- [Results] Results section: No per-modality ablation studies or quantitative information-overlap metrics (e.g., mutual information between modalities) are provided to confirm that the GelSight Mini and Evetac streams supply non-redundant signals beyond the RGB stream and each other; without this, the 26-point gap over the visual-tactile baseline cannot be confidently attributed to multi-resolution tactile features.
- [Results] Results section: The manuscript does not include a table or statement confirming that the identical convolutional-stem-plus-transformer architecture and hyperparameters were applied unchanged across all five tasks; this detail is load-bearing for the claim that the fusion generalizes without task-specific tuning.
- [Abstract] Abstract and Results: The headline success rates (80%, 31%, 54%) are stated without any reference to number of trials, variance, statistical tests, or data-exclusion rules, so the central empirical claim cannot be verified from the supplied information.
minor comments (1)
- [Abstract] Abstract: The baseline label 'visual-tactile (54 %)' should explicitly state which tactile sensor(s) it includes to avoid ambiguity with the proposed multi-tactile setting.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the empirical claims.
read point-by-point responses
-
Referee: [Results] Results section: No per-modality ablation studies or quantitative information-overlap metrics (e.g., mutual information between modalities) are provided to confirm that the GelSight Mini and Evetac streams supply non-redundant signals beyond the RGB stream and each other; without this, the 26-point gap over the visual-tactile baseline cannot be confidently attributed to multi-resolution tactile features.
Authors: We agree that dedicated per-modality ablations and mutual-information metrics would provide clearer evidence of complementary signals. The existing attention analysis offers some interpretability, but does not substitute for these quantitative controls. We will add the requested ablation studies and information-overlap metrics in the revised Results section. revision: yes
-
Referee: [Results] Results section: The manuscript does not include a table or statement confirming that the identical convolutional-stem-plus-transformer architecture and hyperparameters were applied unchanged across all five tasks; this detail is load-bearing for the claim that the fusion generalizes without task-specific tuning.
Authors: The architecture and hyperparameters were held fixed across tasks. We will insert an explicit statement and a summary table in the revised Results section documenting this consistency. revision: yes
-
Referee: [Abstract] Abstract and Results: The headline success rates (80%, 31%, 54%) are stated without any reference to number of trials, variance, statistical tests, or data-exclusion rules, so the central empirical claim cannot be verified from the supplied information.
Authors: We will revise the abstract and Results section to report the number of trials per task, standard deviations, and data-exclusion criteria. Statistical comparisons will be added where appropriate. revision: yes
Circularity Check
No circularity: purely empirical evaluation of proposed architecture
full rationale
The paper introduces the MiTaS framework and a conv-stem+transformer architecture for fusing RGB, GelSight Mini, and Evetac data to condition a flow-matching policy, then reports success rates from imitation learning rollouts on five tasks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. All central claims rest on direct experimental comparisons (80% vs. 31%/54% baselines) rather than any reduction to inputs by construction, satisfying the default expectation of a non-circular empirical robotics paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Johansson and J. Flanagan. Tactile sensory control of object manipulation in humans.The Senses: A Comprehensive Reference, 6:67–86, 01 2010. doi:10.1016/B978-012370880-9. 00346-7
-
[2]
W. Yuan, S. Dong, and E. H. Adelson. GelSight: High-Resolution Robot Tactile Sensors for Estimating Geometry and Force.Sensors, 17(12):2762, Dec. 2017. ISSN 1424-8220. doi: 10.3390/s17122762. URLhttps://www.mdpi.com/1424-8220/17/12/2762
-
[3]
Lambeta, P.-W
M. Lambeta, P.-W. Chou, S. Tian, B. Yang, B. Maloon, V . R. Most, D. Stroud, R. Santos, A. Byagowi, G. Kammerer, et al. Digit: A novel design for a low-cost compact high-resolution tactile sensor with application to in-hand manipulation.IEEE Robotics and Automation Letters, 5(3):3838–3845, 2020
2020
-
[4]
Ward-Cherrier, N
B. Ward-Cherrier, N. Pestell, L. Cramphorn, B. Winstone, M. E. Giannaccini, J. Rossiter, and N. F. Lepora. The tactip family: Soft optical tactile sensors with 3d-printed biomimetic morphologies.Soft robotics, 5(2):216–227, 2018
2018
-
[5]
S. Dong, D. K. Jha, D. Romeres, et al. Tactile-rl for insertion: Generalization to objects of unknown geometry. InICRA, 2021
2021
-
[6]
R. Calandra, A. Owens, M. Upadhyaya, W. Yuan, J. Lin, E. H. Adelson, and S. Levine. The feeling of success: Does touch sensing help predict grasp outcomes?, 2025. URLhttps: //arxiv.org/abs/1710.05512
arXiv 2025
- [7]
-
[8]
In: 2022 International Conference on Robotics and Automation (ICRA), pp
J. Hansen, F. Hogan, D. Rivkin, D. Meger, M. Jenkin, and G. Dudek. Visuotactile-RL: Learn- ing Multimodal Manipulation Policies with Deep Reinforcement Learning. In2022 Interna- tional Conference on Robotics and Automation (ICRA), pages 8298–8304, May 2022. doi: 10.1109/ICRA46639.2022.9812019. URLhttps://ieeexplore.ieee.org/document/ 9812019
-
[10]
M. Yang, A. Church, Y . Lin, C. J. Ford, H. Li, E. Psomopoulou, D. A. Barton, N. F. Lepora, et al. Anyrotate: Gravity-invariant in-hand object rotation with sim-to-real touch. InConfer- ence on Robot Learning, pages 4727–4747. PMLR, 2025
2025
-
[11]
Romero, H.-S
B. Romero, H.-S. Fang, P. Agrawal, and E. Adelson. Eyesight hand: Design of a fully-actuated dexterous robot hand with integrated vision-based tactile sensors and compliant actuation. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 1853–1860. IEEE, 2024. 9
2024
-
[12]
N. Funk, E. Helmut, G. Chalvatzaki, R. Calandra, and J. Peters. Evetac: An Event-based Optical Tactile Sensor for Robotic Manipulation, Aug. 2024. URLhttp://arxiv.org/abs/ 2312.01236. arXiv:2312.01236 [cs]
arXiv 2024
-
[13]
D. Yin, S. Lu, J. Yang, Y . Zhang, Z. Dai, D. Nan, B. Cai, S. He, and X. Chen. Gelevent—a novel high-speed tactile sensor with event camera.IEEE Transactions on Instrumentation and Measurement, 74:1–13, 2025. doi:10.1109/TIM.2025.3551440
-
[14]
Q. Li, O. Kroemer, Z. Su, F. F. Veiga, M. Kaboli, and H. J. Ritter. A review of tactile informa- tion: Perception and action through touch.IEEE Transactions on Robotics, 36(6):1619–1634, 2020
2020
-
[15]
Calandra, A
R. Calandra, A. Owens, D. Jayaraman, J. Lin, W. Yuan, J. Malik, E. H. Adelson, and S. Levine. More than a feeling: Learning to grasp and regrasp using vision and touch.IEEE Robotics and Automation Letters, 3(4):3300–3307, 2018
2018
-
[16]
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik. General in-hand object rotation with vision and touch. InConference on Robot Learning, pages 2549–2564. PMLR, 2023
2023
-
[17]
Huang, Y
B. Huang, Y . Wang, X. Yang, Y . Luo, and Y . Li. 3d-vitac: Learning fine-grained manipulation with visuo-tactile sensing. InConference on Robot Learning, pages 2557–2578. PMLR, 2025
2025
-
[18]
H. Li, Y . Zhang, J. Zhu, S. Wang, M. A. Lee, H. Xu, E. Adelson, L. Fei-Fei, R. Gao, and J. Wu. See, Hear, and Feel: Smart Sensory Fusion for Robotic Manipulation, Dec. 2022. URL http://arxiv.org/abs/2212.03858. arXiv:2212.03858 [cs]
arXiv 2022
-
[19]
Ablett, O
T. Ablett, O. Limoyo, A. Sigal, A. Jilani, J. Kelly, K. Siddiqi, F. Hogan, and G. Dudek. Mul- timodal and force-matched imitation learning with a see-through visuotactile sensor.IEEE Transactions on Robotics, 41:946–959, 2024
2024
-
[20]
N. Funk, C. Chen, T. Schneider, G. Chalvatzaki, R. Calandra, and J. Peters. On the Importance of Tactile Sensing for Imitation Learning: A Case Study on Robotic Match Lighting.IEEE Robotics and Automation Letters, 11(5):6218–6225, 2026
2026
-
[21]
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu. Reactive Diffusion Policy: Slow-Fast Visual-Tactile Policy Learning for Contact-Rich Manipulation, Apr. 2025. URLhttp://arxiv.org/abs/2503.02881. arXiv:2503.02881 [cs]
arXiv 2025
-
[22]
N. Cheng, J. Xu, C. Guan, J. Gao, W. Wang, Y . Li, F. Meng, J. Zhou, B. Fang, and W. Han. Touch100k: A large-scale touch-language-vision dataset for touch-centric multimodal rep- resentation.Information Fusion, 124:103305, Dec. 2025. ISSN 1566-2535. doi:10.1016/ j.inffus.2025.103305. URLhttps://www.sciencedirect.com/science/article/pii/ S1566253525003781
arXiv 2025
-
[23]
C. Higuera, A. Sharma, T. Fan, C. K. Bodduluri, B. Boots, M. Kaess, M. Lambeta, T. Wu, Z. Liu, F. R. Hogan, and M. Mukadam. Tactile Beyond Pixels: Multisensory Touch Repre- sentations for Robot Manipulation, June 2025. URLhttp://arxiv.org/abs/2506.14754. arXiv:2506.14754 [cs]
arXiv 2025
- [24]
-
[25]
Z. Zhao, S. Haldar, J. Cui, L. Pinto, and R. Bhirangi. Touch begins where vision ends: Gen- eralizable policies for contact-rich manipulation, June 2025. URLhttp://arxiv.org/abs/ 2506.13762. arXiv:2506.13762 [cs]. 10
arXiv 2025
-
[26]
V . Dave, F. Lygerakis, and E. Rueckert. Multimodal Visual-Tactile Representation Learn- ing through Self-Supervised Contrastive Pre-Training, Jan. 2024. URLhttp://arxiv.org/ abs/2401.12024. arXiv:2401.12024 [cs]
arXiv 2024
-
[27]
L. Fu, H. Huang, L. Berscheid, H. Li, K. Goldberg, and S. Chitta. Safe Self-Supervised Learning in Real of Visuo-Tactile Feedback Policies for Industrial Insertion, Mar. 2023. URL http://arxiv.org/abs/2210.01340. arXiv:2210.01340 [cs]
arXiv 2023
- [28]
-
[29]
G. Ye, Z. Zhang, X. Zhao, S. Wu, H. Lu, S. Lu, and H. Liu. Learning to Feel the Future: DreamTacVLA for Contact-Rich Manipulation, Dec. 2025. URLhttp://arxiv.org/abs/ 2512.23864. arXiv:2512.23864 [cs]
Pith/arXiv arXiv 2025
-
[30]
R. Feng, J. Hu, W. Xia, T. Gao, A. Shen, Y . Sun, B. Fang, and D. Hu. AnyTouch: Learning Unified Static-Dynamic Representation across Multiple Visuo-tactile Sensors, Apr. 2025. URL http://arxiv.org/abs/2502.12191. arXiv:2502.12191 [cs]
arXiv 2025
-
[31]
J. Zhao, Y . Ma, L. Wang, and E. H. Adelson. Transferable Tactile Transformers for Repre- sentation Learning Across Diverse Sensors and Tasks, Oct. 2024. URLhttp://arxiv.org/ abs/2406.13640. arXiv:2406.13640 [cs]
arXiv 2024
-
[32]
M. A. Lee, Y . Zhu, K. Srinivasan, P. Shah, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making Sense of Vision and Touch: Self-Supervised Learning of Multimodal Representations for Contact-Rich Tasks.CoRR, abs/1810.10191, 2018. URLhttp://arxiv.org/abs/1810. 10191. eprint: 1810.10191
Pith/arXiv arXiv 2018
-
[33]
M. A. Lee, Y . Zhu, P. Zachares, M. Tan, K. Srinivasan, S. Savarese, L. Fei-Fei, A. Garg, and J. Bohg. Making Sense of Vision and Touch: Learning Multimodal Representa- tions for Contact-Rich Tasks, July 2019. URLhttp://arxiv.org/abs/1907.13098. arXiv:1907.13098 [cs]
arXiv 2019
-
[34]
R. Feng, D. Hu, W. Ma, and X. Li. Play to the Score: Stage-Guided Dynamic Multi-Sensory Fusion for Robotic Manipulation, Oct. 2024. URLhttp://arxiv.org/abs/2408.01366. arXiv:2408.01366 [cs]
arXiv 2024
-
[35]
C. Sferrazza, Y . Seo, H. Liu, Y . Lee, and P. Abbeel. The Power of the Senses: Generalizable Manipulation from Vision and Touch through Masked Multimodal Learning, Nov. 2023. URL http://arxiv.org/abs/2311.00924. arXiv:2311.00924 [cs]
arXiv 2023
-
[36]
M. Lambeta, T. Wu, A. Sengul, V . R. Most, N. Black, K. Sawyer, R. Mercado, H. Qi, A. Sohn, B. Taylor, N. Tydingco, G. Kammerer, D. Stroud, J. Khatha, K. Jenkins, K. Most, N. Stein, R. Chavira, T. Craven-Bartle, E. Sanchez, Y . Ding, J. Malik, and R. Calandra. Digitizing touch with an artificial multimodal fingertip, 2024. URLhttps://arxiv.org/abs/2411.02479
arXiv 2024
-
[37]
J. Zhao, N. Kuppuswamy, S. Feng, B. Burchfiel, and E. Adelson. Polytouch: A robust multi- modal tactile sensor for contact-rich manipulation using tactile-diffusion policies. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 104–110. IEEE, 2025
2025
-
[38]
P. Jin, B. Huang, W. W. Lee, T. Li, and W. Yang. Visual-Force-Tactile Fusion for Gen- tle Intricate Insertion Tasks.IEEE Robotics and Automation Letters, 9(5):4830–4837, May
-
[39]
ISSN 2377-3766. doi:10.1109/LRA.2024.3379803. URLhttps://ieeexplore. ieee.org/document/10476678/. 11
-
[40]
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao. MimicTouch: Leveraging Multi- modal Human Tactile Demonstrations for Contact-rich Manipulation, Feb. 2025. URLhttp: //arxiv.org/abs/2310.16917. arXiv:2310.16917 [cs]
arXiv 2025
-
[41]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
Pith/arXiv arXiv 2026
-
[42]
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[43]
T. Xiao, M. Singh, E. Mintun, T. Darrell, P. Doll ´ar, and R. Girshick. Early convolutions help transformers see better, 2021. URLhttps://arxiv.org/abs/2106.14881
arXiv 2021
-
[44]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin. Attention is all you need, 2023. URLhttps://arxiv.org/abs/1706.03762
Pith/arXiv arXiv 2023
- [45]
-
[46]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[47]
W. Peebles and S. Xie. Scalable diffusion models with transformers, 2023. URLhttps: //arxiv.org/abs/2212.09748
Pith/arXiv arXiv 2023
- [48]
-
[49]
R. Krohn, V . Prasad, G. Tiboni, and G. Chalvatzaki. Self-supervised multisensory pretraining for contact-rich robot reinforcement learning.IEEE Robotics and Automation Letters, 11(6): 6799–6806, 2026. doi:10.1109/LRA.2026.3681156
-
[50]
A. Nagrani, S. Yang, A. Arnab, A. Jansen, C. Schmid, and C. Sun. Attention bottlenecks for multimodal fusion, 2022. URLhttps://arxiv.org/abs/2107.00135
arXiv 2022
-
[51]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URLhttps: //arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[52]
B. Tang, M. A. Lin, I. Akinola, A. Handa, G. S. Sukhatme, F. Ramos, D. Fox, and Y . Narang. Industreal: Transferring contact-rich assembly tasks from simulation to reality, 2023. URL https://arxiv.org/abs/2305.17110
arXiv 2023
-
[53]
M. Heo, Y . Lee, D. Lee, and J. J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation. InRobotics: Science and Systems, 2023
2023
-
[54]
M. Tancik, P. P. Srinivasan, B. Mildenhall, S. Fridovich-Keil, N. Raghavan, U. Singhal, R. Ra- mamoorthi, J. T. Barron, and R. Ng. Fourier features let networks learn high frequency func- tions in low dimensional domains, 2020. URLhttps://arxiv.org/abs/2006.10739. 12 A Appendix This appendix provides supplementary material that supports the experimental e...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.