Code2LoRA: Hypernetwork-Generated Adapters for Code Language Models under Software Evolution
Pith reviewed 2026-06-28 00:02 UTC · model grok-4.3
The pith
A hypernetwork generates repository-specific LoRA adapters for code language models from single snapshots or sequences of diffs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
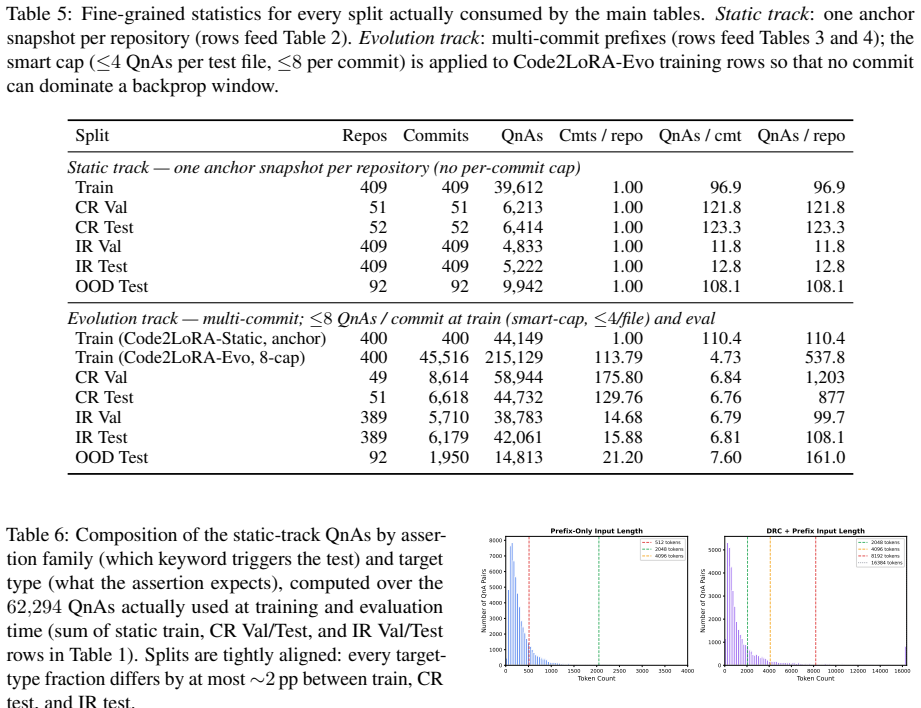
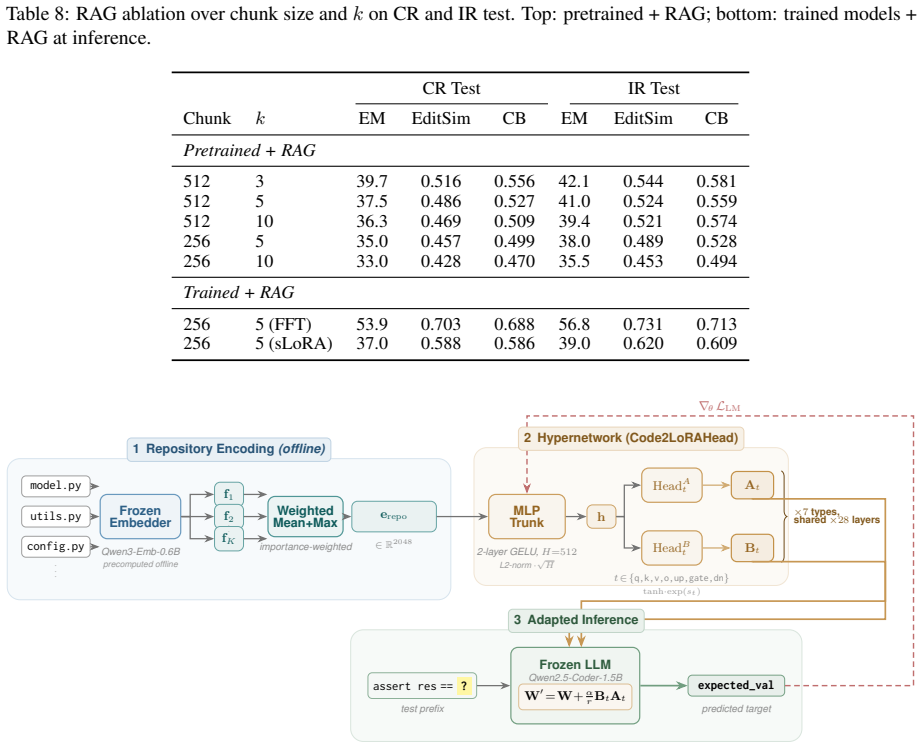
Code2LoRA trains a hypernetwork to map either a repository snapshot or a sequence of code diffs into the low-rank updates of a LoRA adapter; on the static track this reaches 63.8 percent cross-repository and 66.2 percent in-repository exact match, matching the per-repository LoRA upper bound, while on the evolution track the diff-updated version reaches 60.3 percent cross-repository exact match, 5.2 points above a single shared LoRA.
What carries the argument
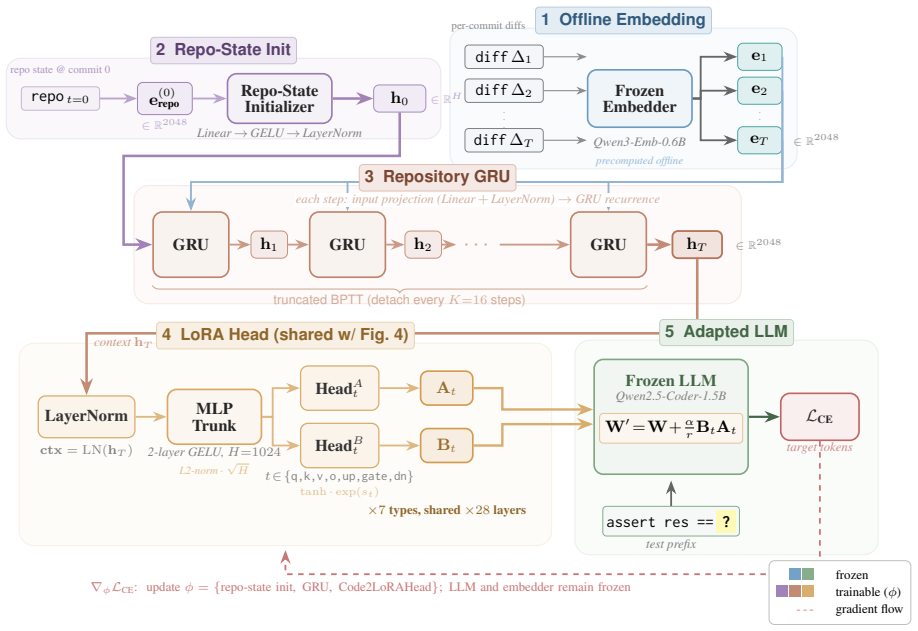
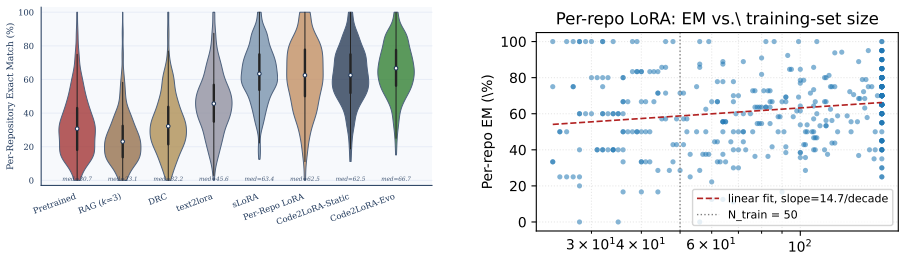
The hypernetwork that converts a repository snapshot or diff sequence into LoRA parameter values, with a GRU hidden state maintaining continuity across commits in the evolutionary case.
If this is right
- Repository knowledge can be stored and applied as compact adapter weights rather than as retrieved tokens or repeated fine-tuning.
- Continuous development can be tracked by updating a single hidden state instead of retraining or reloading adapters per commit.
- Inference cost remains constant regardless of the number of repositories a model must support.
- The same hypernetwork architecture can be reused across different base code models without changing the downstream task heads.
Where Pith is reading between the lines
- The approach could be tested on non-Python languages or on tasks beyond assertion completion to check whether the hypernetwork learns general repository structure.
- If the generated adapters prove stable, they might reduce reliance on ever-larger context windows for repository-scale code understanding.
- The framework suggests a path toward maintaining many project-specific models as a single base model plus a lightweight hypernetwork rather than a growing collection of fine-tuned checkpoints.
Load-bearing premise
The hypernetwork, once trained on the assertion and commit-derived tasks, can produce LoRA weights that embed the project-specific knowledge required for the completion tasks.
What would settle it
A replication in which Code2LoRA-Static exact-match scores on the static-track test set fall more than a few points below the per-repository LoRA baseline.
Figures



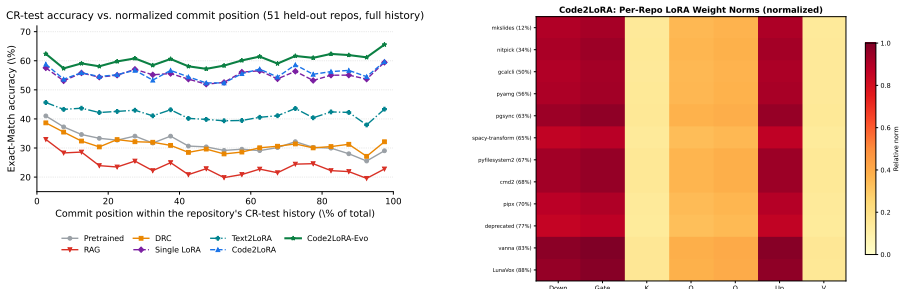



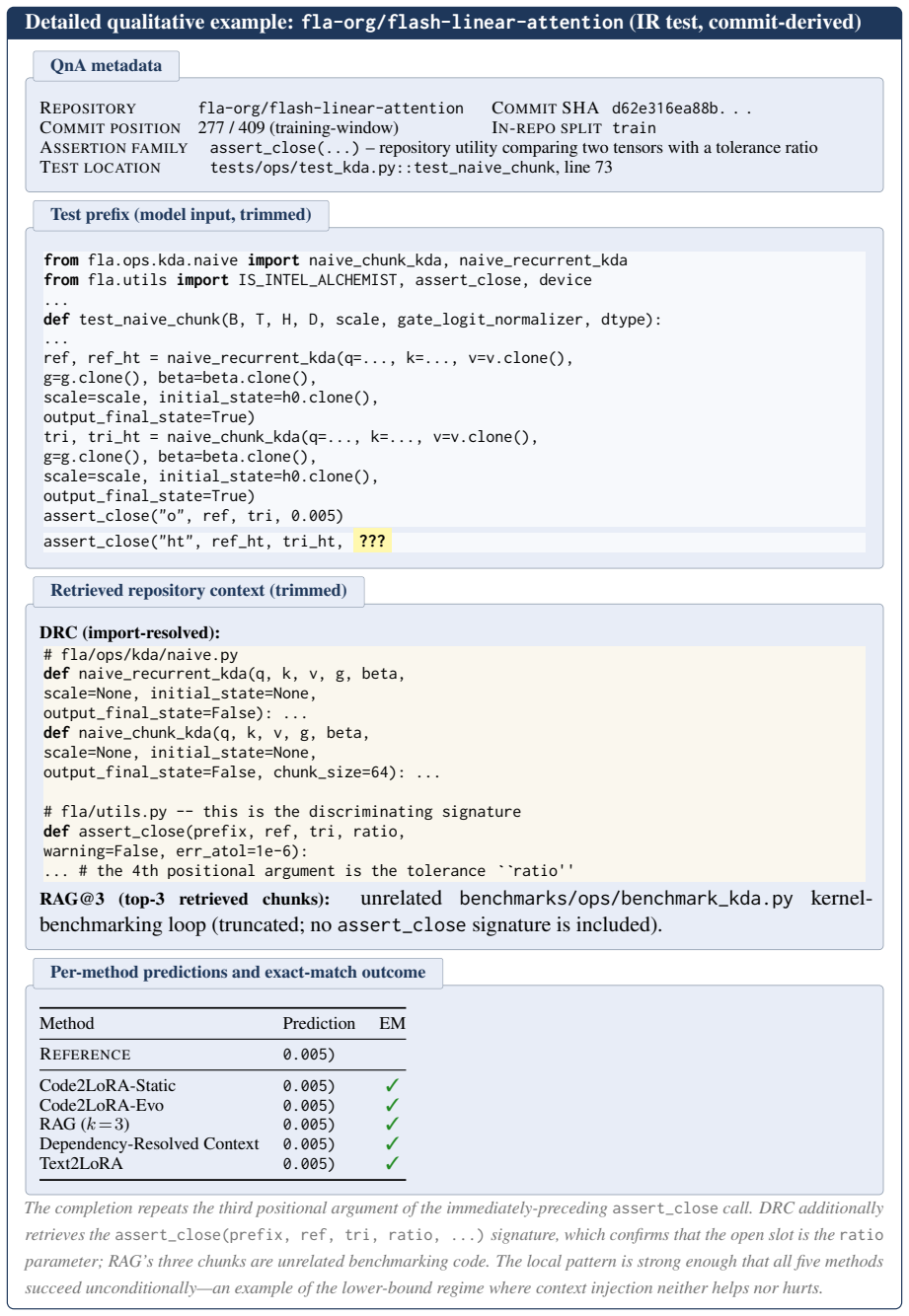
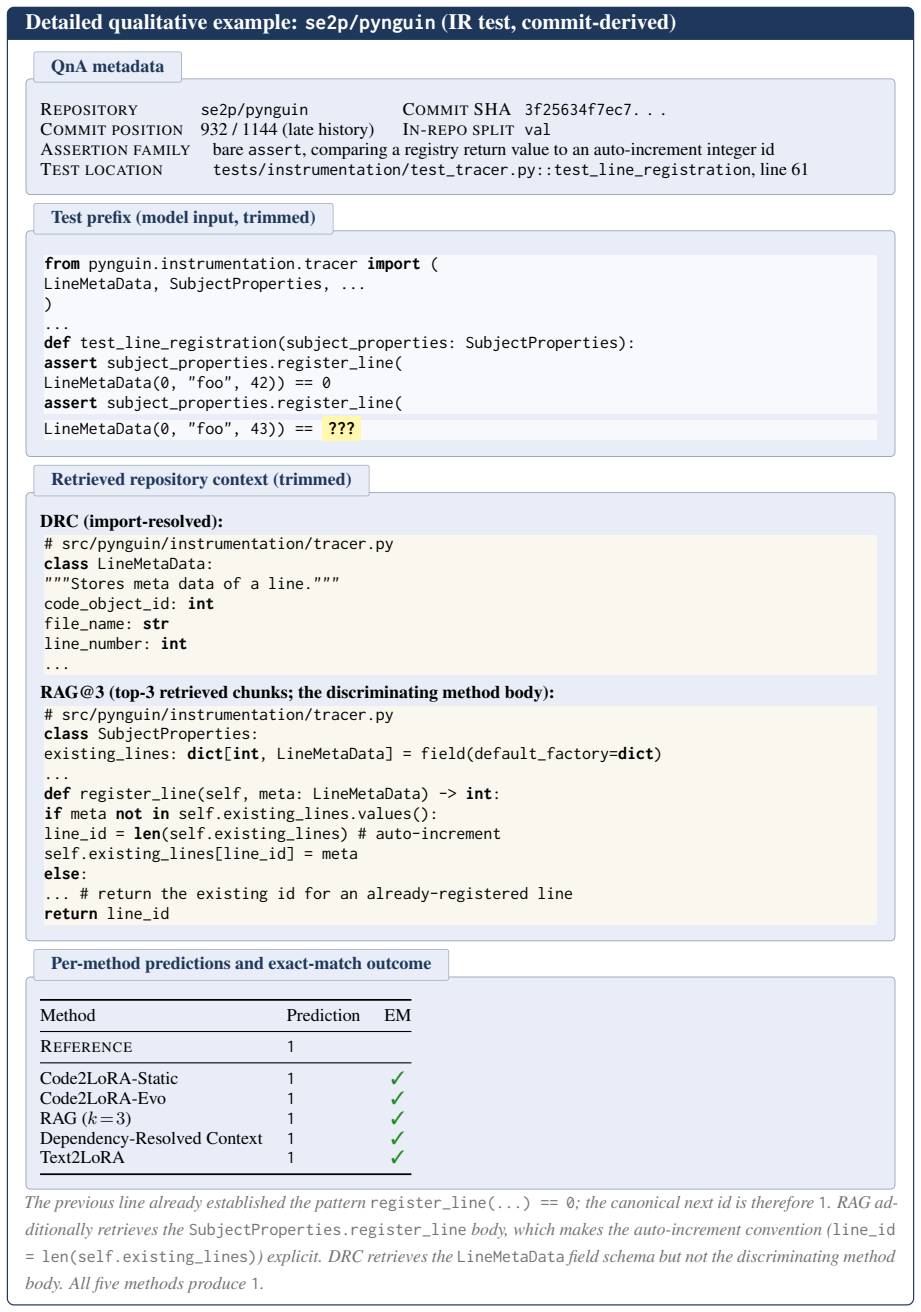
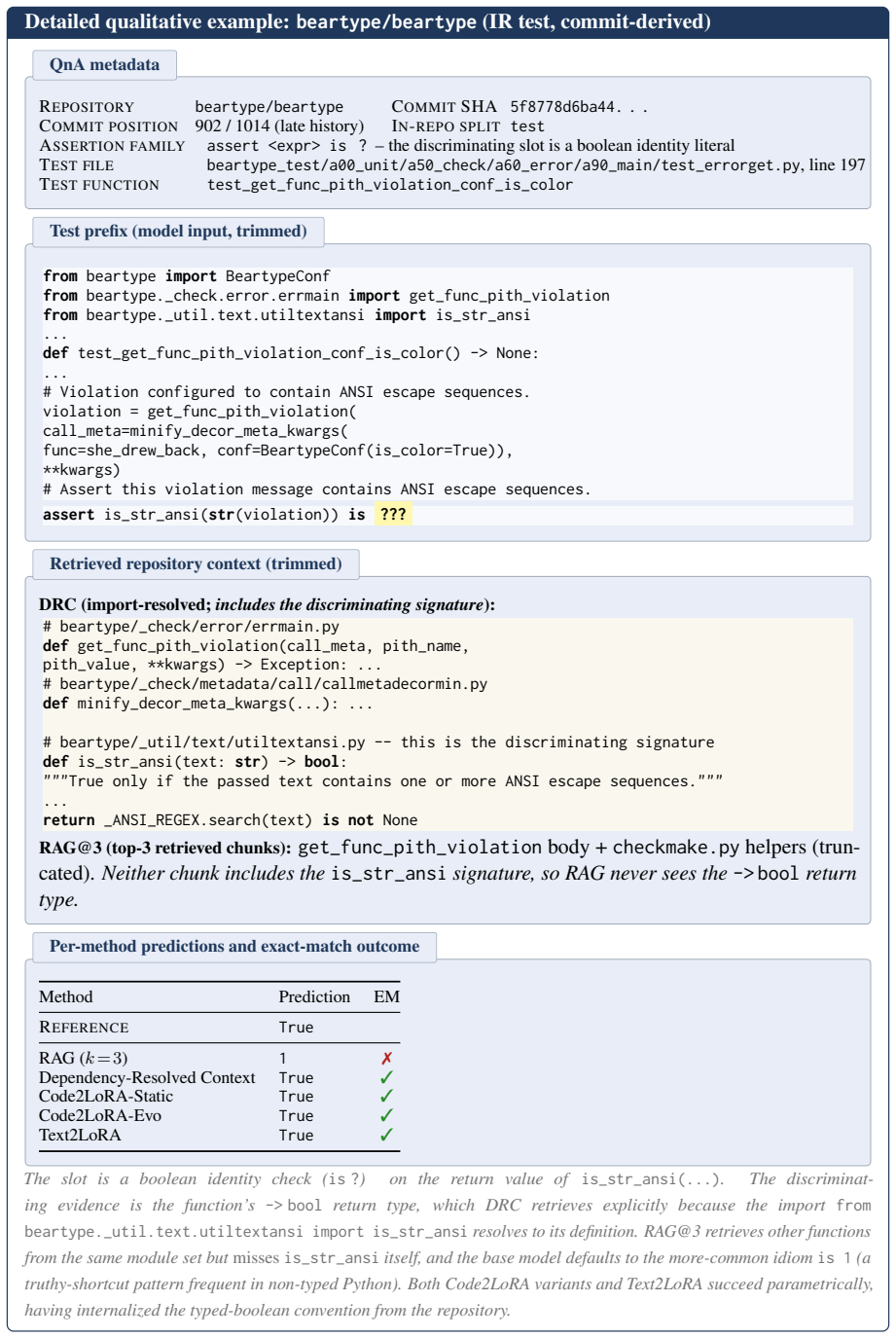

read the original abstract
Code language models need repository-level context to resolve imports, APIs, and project conventions. Existing methods inject this knowledge as long inputs (retrieved through RAG or dependency analysis) or through per-repository fine-tuning and LoRA -- costly at repository scale and brittle to evolving codebases. We introduce Code2LoRA, a hypernetwork framework that generates repository-specific LoRA adapters, effectively injecting repository knowledge with zero inference-time token overhead. Code2LoRA supports two usage scenarios: Code2LoRA-Static converts a single repository snapshot into an adapter, suitable for comprehension of stable codebases; while Code2LoRA-Evo maintains an adapter backed by a GRU hidden state updated per code diff, suitable for active development of evolving codebases. To evaluate Code2LoRA against parameter-efficient fine-tuning baselines, we build RepoPeftBench, a benchmark of 604 Python repositories with two tracks: a static track with 40K training and 12K test assertion-completion tasks, and an evolution track with 215K commit-derived training and 87K commit-derived test tasks. On the static track, Code2LoRA-Static achieves 63.8% cross-repo and 66.2% in-repo exact match, matching the per-repository LoRA upper bound; on the evolution track, Code2LoRA-Evo achieves 60.3% cross-repo exact match (+5.2 pp over a single shared LoRA). Code2LoRA's code can be found at https://anonymous.4open.science/r/code2lora-6857; the model checkpoints and RepoPeftBench datasets can be found at https://huggingface.co/code2lora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Code2LoRA, a hypernetwork framework that generates repository-specific LoRA adapters from repository snapshots (Code2LoRA-Static) or diff sequences via a GRU hidden state (Code2LoRA-Evo) to inject project-level knowledge into code language models with zero inference-time overhead. It constructs RepoPeftBench from 604 Python repositories, containing 40K/12K static assertion-completion tasks and 215K/87K commit-derived evolution tasks, and reports that Code2LoRA-Static matches the per-repository LoRA upper bound (63.8% cross-repo, 66.2% in-repo exact match) while Code2LoRA-Evo improves 5.2 pp over a shared LoRA (60.3% cross-repo exact match).
Significance. If the central claims are supported by the experimental design, the work provides a practical path to repository-aware adaptation that avoids both long-context retrieval and per-repository fine-tuning costs, which is relevant for maintaining code models on evolving codebases. The public release of code, model checkpoints, and the RepoPeftBench dataset is a clear strength that enables direct reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: the claim that Code2LoRA-Static matches the per-repository LoRA upper bound at 63.8%/66.2% exact match is load-bearing for the knowledge-injection thesis, yet the abstract supplies no description of how the 40K/12K assertion-completion tasks were constructed to require cross-file imports, API conventions, or project state rather than local function context alone; without such validation the matching result does not demonstrate successful hypernetwork-mediated transfer.
- [Abstract] Abstract / Evaluation: no architecture details, training procedure, hypernetwork conditioning mechanism, GRU dimension, ablation studies, or statistical tests are reported, leaving the +5.2 pp evolution-track gain and the static-track parity unassessable for robustness or alternative explanations.
minor comments (2)
- The anonymous GitHub and Hugging Face links should be replaced with permanent identifiers in the camera-ready version.
- Clarify the precise definition of 'exact match' and the construction of the cross-repo versus in-repo splits.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the significance of the work along with the value of the public releases. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that Code2LoRA-Static matches the per-repository LoRA upper bound at 63.8%/66.2% exact match is load-bearing for the knowledge-injection thesis, yet the abstract supplies no description of how the 40K/12K assertion-completion tasks were constructed to require cross-file imports, API conventions, or project state rather than local function context alone; without such validation the matching result does not demonstrate successful hypernetwork-mediated transfer.
Authors: We agree that the abstract would be strengthened by including a brief description of the task construction. The full manuscript details in Section 3.2 that the assertion-completion tasks are derived from repository test suites, which necessitate resolving cross-file imports, API conventions, and project state. We will revise the abstract to incorporate a concise explanation of this construction process to better support the knowledge-injection claim. revision: yes
-
Referee: [Abstract] Abstract / Evaluation: no architecture details, training procedure, hypernetwork conditioning mechanism, GRU dimension, ablation studies, or statistical tests are reported, leaving the +5.2 pp evolution-track gain and the static-track parity unassessable for robustness or alternative explanations.
Authors: The full manuscript reports these elements in dedicated sections: the hypernetwork architecture and conditioning mechanism in Section 4, the training procedure in Section 5, GRU dimension in Section 4.2, ablation studies in Section 6.3, and statistical tests in Appendix B. We acknowledge that the abstract does not summarize these, which may make the results harder to assess at a glance. We will add a brief summary of the key architectural and training choices to the abstract and ensure the evaluation section explicitly references the ablations and tests. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is an empirical contribution introducing Code2LoRA, a hypernetwork for generating repository-specific LoRA adapters, and evaluating it on the newly constructed RepoPeftBench benchmark with static and evolution tracks. Reported results (e.g., matching per-repo LoRA upper bound at 63.8/66.2% exact match) are direct experimental comparisons to external baselines on assertion-completion and commit-derived tasks. No equations, self-definitional derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text; the central claims rest on benchmark performance rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- hypernetwork size and conditioning mechanism
- GRU hidden-state dimension
axioms (1)
- domain assumption Repository knowledge required for code-completion tasks can be captured by a low-rank adapter whose weights are predictable from a compact repository encoding.
Reference graph
Works this paper leans on
- [1]
-
[2]
Rujikorn Charakorn, Edoardo Cetin, Yujin Tang, and Robert Tjarko Lange. 2025. https://openreview.net/forum?id=zWskCdu3QA Text-to-lo RA : Instant transformer adaption . In Forty-second International Conference on Machine Learning
2025
- [3]
-
[4]
Saumya Chaturvedi, Aman Chadha, and Laurent Bindschaedler. 2025. https://openreview.net/forum?id=b0foNPsPaH Lo RAC ode: Lo RA adapters for code embeddings . In ICLR 2025 Third Workshop on Deep Learning for Code
2025
-
[5]
Tong Chen, Hao Fang, Patrick Xia, Xiaodong Liu, Benjamin Van Durme, Luke Zettlemoyer, Jianfeng Gao, and Hao Cheng. 2025. https://openreview.net/forum?id=bc3sUsS6ck Generative adapter: Contextualizing language models in parameters with a single forward pass . In The Thirteenth International Conference on Learning Representations
2025
-
[6]
Ken Deng, Jiaheng Liu, He Zhu, Congnan Liu, Jingxin Li, Jiakai Wang, Peng Zhao, Chenchen Zhang, Yanan Wu, Xueqiao Yin, Yuanxing Zhang, Zizheng Zhan, Wenbo Su, Bangyu Xiang, Tiezheng Ge, and Bo Zheng. 2025. https://arxiv.org/abs/2406.01359 R2c2-coder: Enhancing and benchmarking real-world repository-level code completion abilities of code large language mo...
-
[7]
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. QLoRA : Efficient finetuning of quantized LLMs . In Conference on Neural Information Processing Systems
2023
-
[8]
Yangruibo Ding, Zijian Wang, Wasi Ahmad, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2024. https://aclanthology.org/2024.lrec-main.305/ C o C o MIC : Code completion by jointly modeling in-file and cross-file context . In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Langu...
2024
-
[9]
Yangruibo Ding, Zijian Wang, Wasi Uddin Ahmad, Hantian Ding, Ming Tan, Nihal Jain, Murali Krishna Ramanathan, Ramesh Nallapati, Parminder Bhatia, Dan Roth, and Bing Xiang. 2023. https://arxiv.org/pdf/2310.11248.pdf Crosscodeeval: A diverse and multilingual benchmark for cross-file code completion . In Thirty-seventh Conference on Neural Information Proces...
-
[10]
Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. 2024. https://arxiv.org/abs/2401.14196 Deepseek-coder: When the large language model meets programming -- the rise of code intelligence . Preprint, arXiv:2401.14196
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Dai, and Quoc V
David Ha, Andrew M. Dai, and Quoc V. Le. 2017. https://openreview.net/forum?id=rkpACe1lx Hypernetworks . In International Conference on Learning Representations
2017
-
[12]
Ahmed E. Hassan. 2008. The road ahead for mining software repositories. In 2008 Frontiers of Software Maintenance, pages 48--57
2008
-
[13]
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. https://openreview.net/forum?id=nZeVKeeFYf9 Lo RA : Low-rank adaptation of large language models . In International Conference on Learning Representations
2022
- [14]
-
[15]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, Kai Dang, Yang Fan, Yichang Zhang, An Yang, Rui Men, Fei Huang, Bo Zheng, Yibo Miao, Shanghaoran Quan, and 5 others. 2024. https://arxiv.org/abs/2409.12186 Qwen2.5-Coder technical report . Preprint, arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. 2021. https://proceedings.mlr.press/v139/jaegle21a.html Perceiver: General perception with iterative attention . In Proceedings of the 38th International Conference on Machine Learning, volume 139, pages 4651--4664
2021
-
[17]
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. 2025. https://openreview.net/forum?id=chfJJYC3iL Livecodebench: Holistic and contamination free evaluation of large language models for code . In The Thirteenth International Conference on Learning Representations
2025
-
[18]
Joel Jang, Seonghyeon Ye, Sohee Yang, Joongbo Shin, Janghoon Han, Gyeonghun Kim, Stanley Jungkyu Choi, and Minjoon Seo. 2022. Towards continual knowledge learning of language models. In International Conference on Learning Representations
2022
-
[19]
Collard, and Jonathan I
Huzefa Kagdi, Michael L. Collard, and Jonathan I. Maletic. 2007. A survey and taxonomy of approaches for mining software repositories in the context of software evolution. Journal of Software Maintenance and Evolution: Research and Practice, 19(2):77--131
2007
-
[20]
Angeliki Lazaridou, Adhi Kuncoro, Elena Gribovskaya, Devang Agrawal, Adam Liska, Tayfun Terzi, Mai Gimenez, Cyprien de Masson d'Autume, Tom \'a s Kocisk \`y , Sebastian Ruder, Dani Yogatama, Kris Cao, Susannah Young, and Phil Blunsom. 2021. Mind the gap: Assessing temporal generalization in neural language models. In Conference on Neural Information Proce...
2021
-
[21]
Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, Jia Li, Jenny Chim, Qian Liu, Evgenii Zheltonozhskii, Terry Yue Zhuo, Thomas Wang, Olivier Dehaene, Mishig Davaadorj, Joel Lamy-Poirier, João Monteiro, Oleh Shliazhko, and 48 others. 2023. https://arxiv.org/abs/2305.06161 Starcoder:...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. 2024 a . https://proceedings.mlr.press/v235/liu24bn.html D o RA : Weight-decomposed low-rank adaptation . In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, page...
2024
-
[23]
Tianyang Liu, Canwen Xu, and Julian McAuley. 2024 b . https://arxiv.org/abs/2306.03091 Repobench: Benchmarking repository-level code auto-completion systems
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Chuancheng Lv, Lei Li, Shitou Zhang, Gang Chen, Fanchao Qi, Ningyu Zhang, and Hai-Tao Zheng. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.956 H yper L o RA : Efficient cross-task generalization via constrained low-rank adapters generation . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16376--16393
-
[25]
Mooney, and Milos Gligoric
Pengyu Nie, Jiyang Zhang, Junyi Jessy Li, Raymond J. Mooney, and Milos Gligoric. 2022. Impact of evaluation methodologies on code summarization. In Annual Meeting of the Association for Computational Linguistics, pages 4936--4960
2022
-
[26]
Huy N. Phan, Hoang N. Phan, Tien N. Nguyen, and Nghi D. Q. Bui. 2025. https://doi.org/10.1109/Forge66646.2025.00009 Repohyper: Search-expand-refine on semantic graphs for repository-level code completion . In 2025 IEEE/ACM Second International Conference on AI Foundation Models and Software Engineering (Forge), page 14–25. IEEE Press
-
[27]
Jason Phang, Yi Mao, Pengcheng He, and Weizhu Chen. 2023. https://proceedings.mlr.press/v202/phang23a.html H yper T uning: Toward adapting large language models without back-propagation . In Proceedings of the 40th International Conference on Machine Learning, volume 202, pages 27854--27875. PMLR
2023
-
[28]
Python Software Foundation . 2024. difflib --- helpers for computing deltas. https://docs.python.org/3/library/difflib.html
2024
-
[29]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. https://arxiv.org/abs/2009.10297 Codebleu: a method for automatic evaluation of code synthesis . Preprint, arXiv:2009.10297
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[30]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, and 7 others. 2024. https://arxiv.org/abs/2308.12950 Code ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [31]
-
[32]
Jacek \'S liwerski, Thomas Zimmermann, and Andreas Zeller. 2005. When do changes induce fixes? ACM SIGSOFT Software Engineering Notes, 30(4):1--5
2005
-
[33]
Eshkevari, Davood Mazinanian, and Danny Dig
Nikolaos Tsantalis, Mohammad Mansouri, Laleh M. Eshkevari, Davood Mazinanian, and Danny Dig. 2018. Accurate and efficient refactoring detection in commit history. In International Conference on Software Engineering, pages 483--494
2018
-
[34]
Leandro von Werra, Younes Belkada, Lewis Tunstall, Edward Beeching, Tristan Thrush, Nathan Lambert, Shengyi Huang, Kashif Rasul, and Quentin Gallouédec. 2020. https://github.com/huggingface/trl TRL: Transformers Reinforcement Learning
2020
- [35]
-
[36]
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. 2023. TIES -merging: Resolving interference when merging models. In Thirty-seventh Conference on Neural Information Processing Systems
2023
-
[37]
Fengji Zhang, Bei Chen, Yue Zhang, Jacky Keung, Jin Liu, Daoguang Zan, Yi Mao, Jian-Guang Lou, and Weizhu Chen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.151 R epo C oder: Repository-level code completion through iterative retrieval and generation . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 24...
-
[38]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025. https://arxiv.org/abs/2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . Preprint, arXiv:2506.05176
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Yifan Zong, Yuntian Deng, and Pengyu Nie. 2025. https://doi.org/10.1109/LLM4Code66737.2025.00030 Mix-of-Language-Experts Architecture for Multilingual Programming . In 2025 IEEE/ACM International Workshop on Large Language Models for Code (LLM4Code), pages 200--208. IEEE Computer Society
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.