Teaching the Way, Not the Answer: Privileged Tutoring Distillation for Multimodal Policy Optimization
Pith reviewed 2026-06-27 21:38 UTC · model grok-4.3
The pith
Privileged hints from attention and reasoning steps supply dense token supervision for multimodal policy optimization without exposing answers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
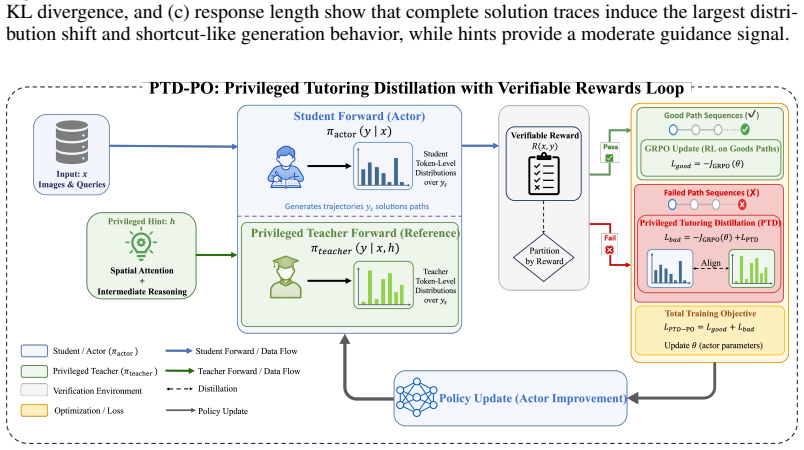
PTD-PO constructs structured privileged hints from spatial attention guidance and intermediate textual reasoning steps, feeds them via in-context learning to produce step-wise token-distribution targets, aligns failed student rollouts to the hint-augmented reference under the original context using Top-K Jensen-Shannon divergence, and thereby supplies dense supervision that improves multimodal reasoning without answer exposure or shortcut behavior.
What carries the argument
The PTD-PO framework that converts spatial-attention and intermediate-reasoning hints into step-wise token-distribution targets for alignment under Top-K Jensen-Shannon divergence.
If this is right
- Dense token supervision becomes available for failed multimodal rollouts without answer leakage.
- Entropy collapse is reduced while complex reasoning accuracy rises on models from 2B to 8B parameters.
- Distillation overhead stays lower than external-teacher methods because hints are generated in-context.
- Shortcut generation is avoided because the student never receives answer-conditioned inputs.
- The same alignment recipe can be applied to any RLVR setup that already produces verifiable rewards.
Where Pith is reading between the lines
- The spatial-attention component of the hints may allow the method to transfer to tasks that require tighter visual grounding.
- If the distribution-shift handling proves robust, the same privileged-hint pattern could be tested on pure-language reasoning chains.
- Replacing the in-context hint generation with a learned hint model might further reduce inference cost at scale.
- The approach suggests a general route for adding intermediate supervision in any sparse-reward policy optimization setting.
Load-bearing premise
Structured privileged hints extracted from attention and reasoning steps can be turned into stable, effective token-distribution targets even when the student sees only the unguided context.
What would settle it
A controlled run on the same benchmarks in which the privileged hints or the Top-K alignment is removed and performance or entropy metrics show no gain over plain RLVR.
Figures








read the original abstract
Recent post-training methods, particularly Reinforcement Learning with Verifiable Rewards (RLVR), have significantly enhanced the reasoning ability of Large Vision-Language Models (LVLMs). However, the sparse nature of verifiable rewards provides little token-level supervision for failed rollouts, often leading to inefficient exploration in complex multimodal reasoning tasks. Although policy distillation can offer dense guidance, external teacher based methods introduce substantial computational overhead, while answer conditioned tuning methods may expose answer-level information and induce shortcut-like generation behavior. To address these limitations, we propose PTD-PO, a Privileged Tutoring Distillation Policy Optimization framework for RLVR that provides dense guidance without exposing the answer to the student policy. Specifically, PTD-PO constructs structured privileged hints from spatial attention guidance and intermediate textual reasoning steps, and uses them through in-context learning to produce step-wise token-distribution supervision. The student is still optimized under the original answer-free context, and its failed rollouts are aligned with the hint-augmented reference model at the token-distribution level. To further stabilize distillation under the distribution shift between guided and unguided contexts, we introduce a Top-K Jensen-Shannon divergence objective that focuses alignment on informative token probabilities while reducing memory overhead. Experiments on LVLMs ranging from 2B to 8B parameters show that PTD-PO consistently outperforms RLVR and distillation baselines, mitigates entropy collapse, and improves complex multimodal reasoning performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PTD-PO, a Privileged Tutoring Distillation Policy Optimization framework for RLVR in LVLMs. It constructs structured privileged hints from spatial attention guidance and intermediate textual reasoning steps, uses in-context learning to generate step-wise token-distribution targets from a hint-augmented reference model, and aligns the student policy (run in the original answer-free context) via a Top-K Jensen-Shannon divergence objective to handle distribution shift. The central empirical claim is that this yields consistent outperformance over RLVR and distillation baselines on 2B–8B LVLMs while mitigating entropy collapse and improving complex multimodal reasoning without exposing answers.
Significance. If the results hold, the work offers a practical engineering route to dense token-level supervision in multimodal RLVR that avoids both the sparsity of verifiable rewards and the shortcut risks of answer-conditioned distillation. The Top-K JS formulation is a concrete attempt to reduce memory cost while focusing alignment; credit is due for framing the contribution around privileged hints that teach the 'way' rather than the answer.
major comments (1)
- [Method section describing the Top-K Jensen-Shannon divergence objective] The Top-K Jensen-Shannon objective is introduced specifically to stabilize alignment under the distribution shift between guided (hint-augmented) and unguided contexts. However, the manuscript provides no quantification of token overlap between the top-k sets in these two contexts for multimodal reasoning steps, nor an ablation that replaces Top-K JS with full-distribution JS. This assumption is load-bearing for the claims of stable distillation, entropy-collapse mitigation, and improved reasoning performance; if overlap is low, the objective may regularize irrelevant directions.
minor comments (1)
- [Abstract] The abstract states that hints are 'constructed from spatial attention guidance and intermediate textual reasoning steps' but does not indicate the precise extraction procedure or prompting template used for in-context learning; a short clarifying sentence would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comment raises a valid point regarding the justification for the Top-K Jensen-Shannon formulation. We address it directly below and commit to strengthening the manuscript accordingly.
read point-by-point responses
-
Referee: [Method section describing the Top-K Jensen-Shannon divergence objective] The Top-K Jensen-Shannon objective is introduced specifically to stabilize alignment under the distribution shift between guided (hint-augmented) and unguided contexts. However, the manuscript provides no quantification of token overlap between the top-k sets in these two contexts for multimodal reasoning steps, nor an ablation that replaces Top-K JS with full-distribution JS. This assumption is load-bearing for the claims of stable distillation, entropy-collapse mitigation, and improved reasoning performance; if overlap is low, the objective may regularize irrelevant directions.
Authors: We agree that explicit quantification of top-k token overlap and a direct ablation against full-distribution JS would provide stronger support for the design choice. The Top-K formulation was motivated by the need to reduce memory footprint while concentrating alignment on high-probability tokens where the guided/unguided shift is most relevant; the empirical gains in stability and reasoning performance reported in the experiments are consistent with this intent. In the revised manuscript we will add (i) a quantitative analysis of token-set overlap between the guided and unguided top-k distributions across representative multimodal reasoning steps and (ii) an ablation replacing Top-K JS with its full-distribution counterpart, reporting both performance and memory metrics. These additions will directly address the load-bearing assumption and clarify whether the Top-K restriction regularizes irrelevant directions. revision: yes
Circularity Check
No circularity: derivation is self-contained engineering contribution
full rationale
The paper presents PTD-PO as an independent method that constructs privileged hints from spatial attention and textual steps, applies in-context learning for token supervision, and aligns via a new Top-K JS objective under distribution shift. No equations, fitted parameters, or self-citations are shown reducing the claimed gains or the Top-K alignment to quantities defined by the inputs themselves. The central claims rest on external empirical benchmarks across model sizes rather than internal redefinitions or load-bearing self-citations, satisfying the criteria for a non-circular derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A General Language Assistant as a Laboratory for Alignment
Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, et al. A general language assistant as a laboratory for alignment.arXiv preprint arXiv:2112.00861,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Ken Ding. Hdpo: Hybrid distillation policy optimization via privileged self-distillation.arXiv preprint arXiv:2603.23871,
-
[4]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes
Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics: ACL 2023, pp. 8003–8017,
2023
-
[7]
10 Siyuan Huang, Xiaoye Qu, Yafu Li, Yun Luo, Zefeng He, Daizong Liu, and Yu Cheng. Spotlight on token perception for multimodal reinforcement learning.arXiv preprint arXiv:2510.09285, 2025a. Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reasoning capability in m...
-
[8]
Gengsheng Li, Tianyu Yang, Junfeng Fang, Mingyang Song, Mao Zheng, Haiyun Guo, Dan Zhang, Jinqiao Wang, and Tat-Seng Chua. Unifying group-relative and self-distillation policy optimiza- tion via sample routing.arXiv preprint arXiv:2604.02288, 2026a. Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training wi...
-
[9]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan- ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016, 2026b. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy L...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Zhihang Lin, Mingbao Lin, Yuan Xie, and R Cppo Ji. Accelerating the training of group relative policy optimization-based reasoning models.arXiv preprint arXiv:2503.22342, 37,
-
[11]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts.arXiv preprint arXiv:2310.02255,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
MM-Eureka: Exploring the Frontiers of Multimodal Reasoning with Rule-based Reinforcement Learning
Fanqing Meng, Lingxiao Du, Zongkai Liu, Zhixiang Zhou, Quanfeng Lu, Daocheng Fu, Botian Shi, Wenhai Wang, Junjun He, Kaipeng Zhang, et al. Mm-eureka: Exploring visual aha moment with rule-based large-scale reinforcement learning.arXiv preprint arXiv:2503.07365,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
What can you do when you have zero rewards during rl? arXiv preprint arXiv:2510.03971,
Jatin Prakash and Anirudh Buvanesh. What can you do when you have zero rewards during rl? arXiv preprint arXiv:2510.03971,
-
[14]
11 Yanwei Ren, Haotian Zhang, Likang Xiao, Xikai Zhang, Jiaxing Huang, Jiayan Qiu, Baosheng Yu, Quan Chen, and Liu Liu. Recycling failures: Salvaging exploration in rlvr via fine-grained off-policy guidance.arXiv preprint arXiv:2602.24110,
-
[15]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Hieu Tran, Zonghai Yao, and Hong Yu. Exploiting tree structure for credit assignment in rl training of llms.arXiv preprint arXiv:2509.18314,
-
[19]
Perception-Aware Policy Optimization for Multimodal Reasoning
Zhenhailong Wang, Xuehang Guo, Sofia Stoica, Haiyang Xu, Hongru Wang, Hyeonjeong Ha, Xiusi Chen, Yangyi Chen, Ming Yan, Fei Huang, et al. Perception-aware policy optimization for mul- timodal reasoning.arXiv preprint arXiv:2507.06448,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
Yijia Xiao, Edward Sun, Tianyu Liu, and Wei Wang. Logicvista: Multimodal llm logical reasoning benchmark in visual contexts.arXiv preprint arXiv:2407.04973,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
Tianzhu Ye, Li Dong, Zewen Chi, Xun Wu, Shaohan Huang, and Furu Wei. Black-box on-policy distillation of large language models.arXiv preprint arXiv:2511.10643,
-
[22]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
12 Wenjing Zhang, Jiangze Yan, Jieyun Huang, Yi Shen, Shuming Shi, Ping Chen, Ning Wang, Zhaox- iang Liu, Kai Wang, and Shiguo Lian. Heal: Hindsight entropy-assisted learning for reasoning distillation.arXiv preprint arXiv:2603.10359,
-
[24]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734,
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673,
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shao- han Huang, Lei Cui, Qixiang Ye, et al. Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673,
-
[26]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
R1-Zero's "Aha Moment" in Visual Reasoning on a 2B Non-SFT Model
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero’s “aha moment” in visual reasoning on a 2b non-sft model, 2025.URL https://arxiv. org/abs/2503.05132, 9:10–16. 13 APPENDIX APPENDIXCONTENTS A Related Work 15 B More Implementation Details 15 C Data Construction and Quality Control 17 C.1 Privileged Hints Construc...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
X a∈V q(a|s) log q(a|s) pθ(a|s) # .(28) Withqfixed, minimizing Eq. equation 28 is equivalent to minimizing the cross-entropy −Es
with automatically checkable outcome signals. In text-only domains, DeepSeekMath, DeepSeek-R1, Kimi k1.5, and related rule-based RL methods show that verifiable rewards can elicit mathematical and multi-step reasoning abilities (Shao et al., 2024; Guo et al., 2025; Team et al., 2025; Yu et al., 2026; Zheng et al., 2025; Zhao et al., 2025). Recent studies ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.