Beyond Waypoints: A Trajectory-Centric Waypointing Paradigm for Vision-Language Navigation
Pith reviewed 2026-06-27 21:39 UTC · model grok-4.3
The pith
Trajectory Waypoint paradigm using TSDF-guided diffusion achieves superior VLN-CE performance by grounding waypoints in executable trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
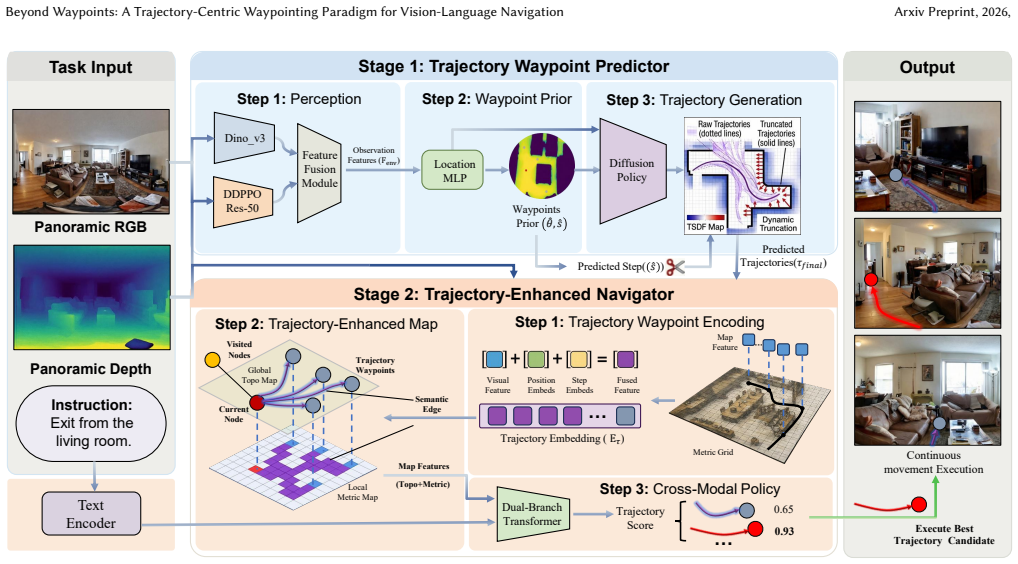
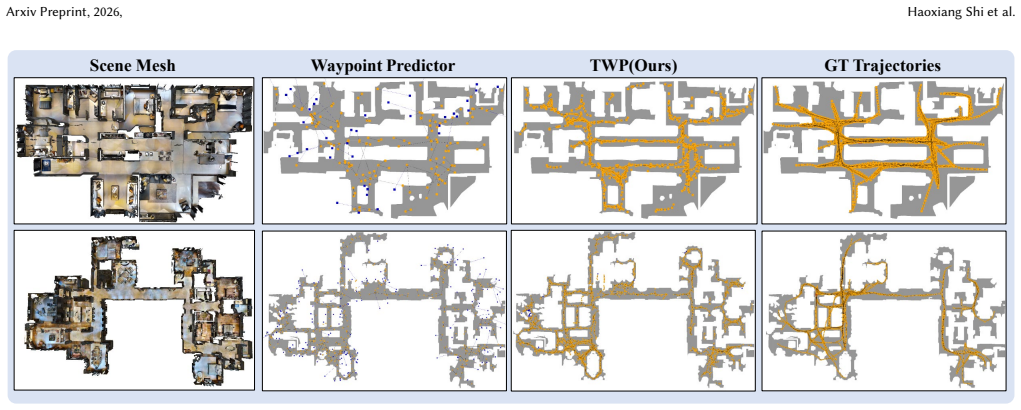
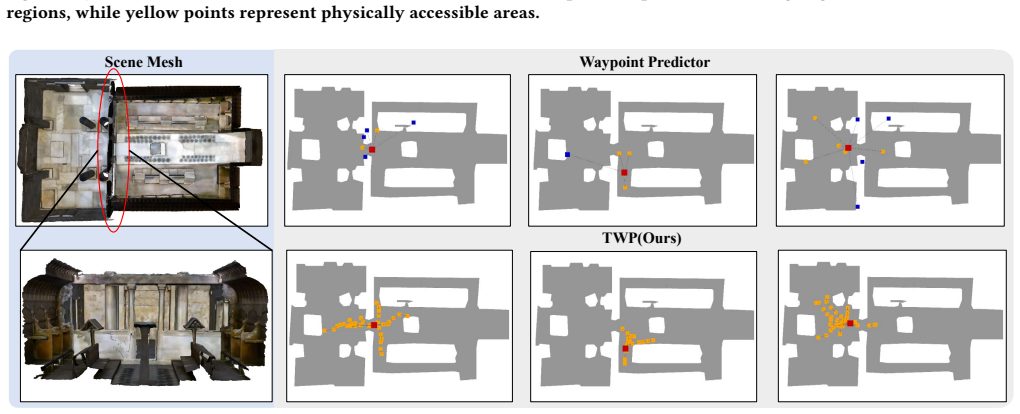
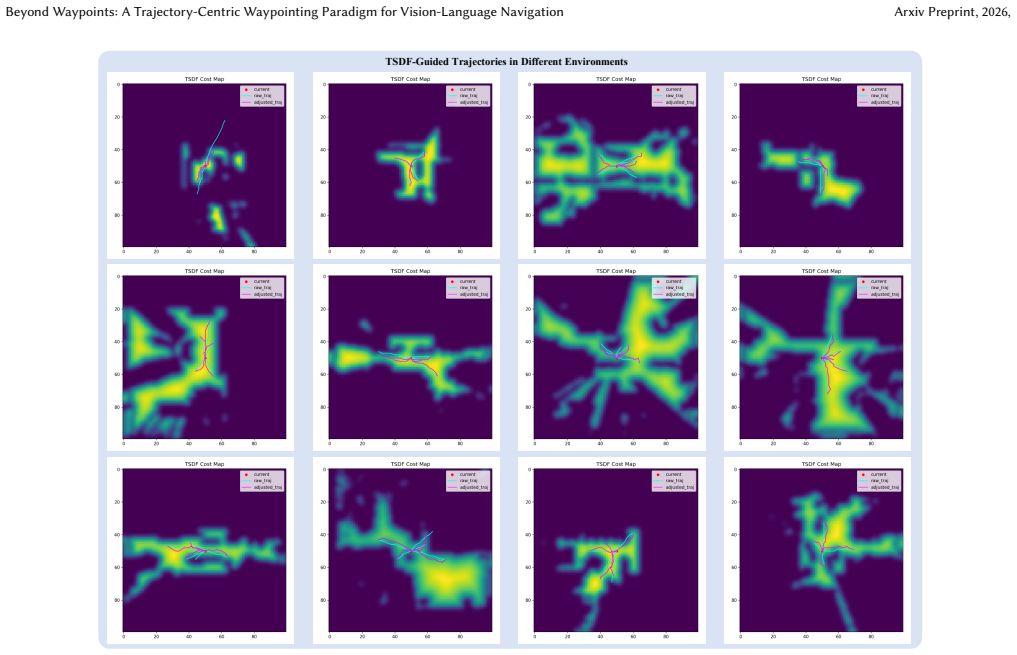
The Trajectory Waypoint paradigm grounds each candidate waypoint in an executable trajectory. This is realized by formulating the predictor as a TSDF-guided diffusion policy that steers trajectory generation away from obstacles, inherently ensuring reachability of the predicted waypoints. A trajectory-enhanced navigator injects the associated trajectory as additional information for planning, enabling strict consistency between high-level semantic decisions and low-level execution.
What carries the argument
Trajectory Waypoint, a waypoint grounded in an executable trajectory, with the TSDF-guided diffusion policy generating reachable paths and the trajectory-enhanced navigator using the full trajectory to enforce planning-execution consistency.
If this is right
- The diffusion policy produces reachable waypoints by using TSDF to avoid obstacles during trajectory generation.
- Trajectory injection into the navigator maintains strict consistency between planning and execution.
- The overall paradigm delivers superior performance compared to standard decoupled waypoint predictors on the VLN-CE benchmark.
- The three-stage framework's problems of unreachable waypoints and planning-control mismatches are directly addressed.
Where Pith is reading between the lines
- This trajectory grounding could apply to other instruction-following robotic tasks where semantic plans must align with physical motion.
- The method might reduce error accumulation in long-horizon navigation by keeping the full path explicit at each step.
- Testing the diffusion policy in environments with moving obstacles would show whether reachability guarantees hold beyond static scenes.
Load-bearing premise
The TSDF-guided diffusion policy will inherently produce reachable waypoints and injecting the trajectory into the navigator will enforce consistency without creating new failure modes.
What would settle it
A VLN-CE evaluation run in which the generated trajectory leads to a waypoint the low-level controller cannot reach or in which the navigator's selected action diverges from the injected trajectory during execution.
Figures


read the original abstract
Vision-Language Navigation in Continuous Environments (VLN-CE) requires agents to follow natural-language instructions while navigating in real-world-like environments. Most VLN-CE approach\-es adopt a three-stage framework: a waypoint predictor proposes navigable waypoints, and a navigator selects the best waypoint, with a low-level controller executing the movement to it. However, this decoupled paradigm often leads to unreachable waypoints or inconsistencies between planning and control. In this work, instead of predicting isolated waypoints, we introduce a novel paradigm called Trajectory Waypoint, which grounds each candidate waypoint in an executable trajectory. To realize this, we design a Trajectory Waypoint Predictor formulated as a TSDF-guided diffusion policy, which steers trajectory generation away from obstacles, inherently ensuring the reachability of the predicted waypoints. We further propose a trajectory-enhanced navigator that injects the associated trajectory as additional information for planning, enabling strict consistency between high-level semantic decisions and low-level execution. Extensive experiments on the VLN-CE benchmark show that our Trajectory Waypoint paradigm achieves superior performance over the baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Trajectory Waypoint paradigm for VLN-CE that replaces isolated waypoint prediction with waypoints grounded in executable trajectories. It uses a TSDF-guided diffusion policy as the Trajectory Waypoint Predictor to steer generation away from obstacles (claimed to inherently ensure reachability) and a trajectory-enhanced navigator that injects the full trajectory to enforce planning-execution consistency. The central claim, supported by experiments on the VLN-CE benchmark, is that this yields superior performance over standard three-stage baselines.
Significance. If the reported gains are robust and the reachability/consistency assumptions hold under scrutiny, the work offers a concrete alternative to decoupled waypoint prediction in continuous navigation, with potential to reduce a known failure mode. The choice of TSDF-guided diffusion for trajectory generation is a distinct modeling decision that could be adopted more broadly; the use of a standard benchmark for evaluation is a positive aspect.
major comments (2)
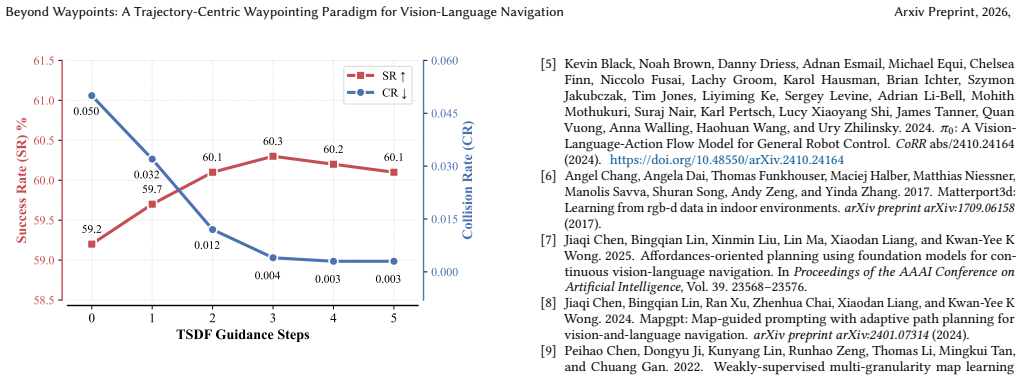
- [Abstract] Abstract (method paragraph on Trajectory Waypoint Predictor): the assertion that TSDF guidance 'inherently ensuring the reachability of the predicted waypoints' lacks supporting analysis. Diffusion sampling remains stochastic and TSDF is a static occupancy field that encodes neither dynamics nor controller limits; without an explicit reachability metric (e.g., fraction of valid trajectories per episode) reported in the experiments, the attribution of benchmark superiority to this property cannot be verified.
- [Abstract] Abstract (method paragraph on trajectory-enhanced navigator): the claim that injecting the trajectory 'enabling strict consistency between high-level semantic decisions and low-level execution' is not demonstrated. The navigator still selects among candidates, so it remains possible for new mismatch modes to arise; an ablation comparing planning-execution mismatch rates with and without trajectory injection is required to substantiate the central consistency benefit.
minor comments (1)
- [Abstract] The abstract states superior performance but supplies no numerical results, error bars, or ablation tables, which hinders immediate assessment of effect sizes and robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below with clarifications from the full paper and indicate where revisions will be made to strengthen the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract (method paragraph on Trajectory Waypoint Predictor): the assertion that TSDF guidance 'inherently ensuring the reachability of the predicted waypoints' lacks supporting analysis. Diffusion sampling remains stochastic and TSDF is a static occupancy field that encodes neither dynamics nor controller limits; without an explicit reachability metric (e.g., fraction of valid trajectories per episode) reported in the experiments, the attribution of benchmark superiority to this property cannot be verified.
Authors: We agree that the abstract phrasing attributes reachability too strongly without direct quantification. The TSDF guidance is designed to bias diffusion sampling toward obstacle-free regions during trajectory generation, and the full manuscript includes qualitative trajectory visualizations and overall benchmark gains that are consistent with improved reachability. However, to allow verification of this mechanism, we will add an explicit reachability metric (fraction of collision-free, controller-executable trajectories per episode) in the experiments section of the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (method paragraph on trajectory-enhanced navigator): the claim that injecting the trajectory 'enabling strict consistency between high-level semantic decisions and low-level execution' is not demonstrated. The navigator still selects among candidates, so it remains possible for new mismatch modes to arise; an ablation comparing planning-execution mismatch rates with and without trajectory injection is required to substantiate the central consistency benefit.
Authors: We acknowledge that the consistency benefit is asserted but not directly quantified via mismatch rates. The trajectory-enhanced navigator conditions waypoint selection on the full predicted trajectory to reduce mismatches, and the manuscript reports superior VLN-CE performance as supporting evidence. To provide the requested substantiation, we will add an ablation measuring planning-execution mismatch rates (e.g., cases where selected waypoints lead to unexecuted or failed segments) with and without trajectory injection. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper introduces a Trajectory Waypoint paradigm via a TSDF-guided diffusion policy and trajectory-enhanced navigator as independent modeling choices. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or method description. The reachability claim is presented as an inherent property of the design rather than a reduction to inputs by construction. The central performance claim rests on experimental results on VLN-CE rather than any self-referential logic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dong An, Yuankai Qi, Yangguang Li, Yan Huang, Liang Wang, Tieniu Tan, and Jing Shao. 2023. BEVBert: Multimodal Map Pre-training for Language-guided Navigation.Proceedings of the IEEE/CVF International Conference on Computer Vision(2023)
2023
-
[2]
Dong An, Hanqing Wang, Wenguan Wang, Zun Wang, Yan Huang, Keji He, and Liang Wang. 2024. Etpnav: Evolving topological planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence(2024)
2024
-
[3]
Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünder- hauf, Ian Reid, Stephen Gould, and Anton Van Den Hengel. 2018. Vision-and- language navigation: Interpreting visually-grounded navigation instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition. 3674–3683
2018
-
[4]
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y. Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, brian ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li- Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Allen Z. Ren,...
2025
-
[5]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky. 2024. 𝜋0: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164 2024
-
[6]
Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niessner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017. Matterport3d: Learning from rgb-d data in indoor environments.arXiv preprint arXiv:1709.06158 (2017)
Pith/arXiv arXiv 2017
-
[7]
Jiaqi Chen, Bingqian Lin, Xinmin Liu, Lin Ma, Xiaodan Liang, and Kwan-Yee K Wong. 2025. Affordances-oriented planning using foundation models for con- tinuous vision-language navigation. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 39. 23568–23576
2025
-
[8]
Jiaqi Chen, Bingqian Lin, Ran Xu, Zhenhua Chai, Xiaodan Liang, and Kwan-Yee K Wong. 2024. Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation.arXiv preprint arXiv:2401.07314(2024)
arXiv 2024
-
[9]
Peihao Chen, Dongyu Ji, Kunyang Lin, Runhao Zeng, Thomas Li, Mingkui Tan, and Chuang Gan. 2022. Weakly-supervised multi-granularity map learning for vision-and-language navigation.Advances in Neural Information Processing Systems35 (2022), 38149–38161
2022
-
[10]
Shizhe Chen, Pierre-Louis Guhur, Cordelia Schmid, and Ivan Laptev. 2021. History aware multimodal transformer for vision-and-language navigation.Advances in neural information processing systems34 (2021), 5834–5847
2021
-
[11]
Shizhe Chen, Pierre-Louis Guhur, Makarand Tapaswi, Cordelia Schmid, and Ivan Laptev. 2022. Think global, act local: Dual-scale graph transformer for vision- and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16537–16547
2022
-
[12]
An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Zaitian Gongye, Xueyan Zou, Jan Kautz, Erdem Bıyık, Hongxu Yin, Sifei Liu, and Xiaolong Wang. 2024. Nav- ila: Legged robot vision-language-action model for navigation.arXiv preprint arXiv:2412.04453(2024)
arXiv 2024
-
[13]
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burch- fiel, Russ Tedrake, and Shuran Song. 2023. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research(2023), 02783649241273668
2023
-
[14]
Georgios Georgakis, Karl Schmeckpeper, Karan Wanchoo, Soham Dan, Eleni Miltsakaki, Dan Roth, and Kostas Daniilidis. 2022. Cross-modal map learning for vision and language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15460–15470
2022
-
[15]
Weituo Hao, Chunyuan Li, Xiujun Li, Lawrence Carin, and Jianfeng Gao. 2020. Towards learning a generic agent for vision-and-language navigation via pre- training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 13137–13146
2020
-
[16]
Yicong Hong, Zun Wang, Qi Wu, and Stephen Gould. 2022. Bridging the gap be- tween learning in discrete and continuous environments for vision-and-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 15439–15449
2022
-
[17]
Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould
-
[18]
InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition
Vln bert: A recurrent vision-and-language bert for navigation. InProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition. 1643– 1653
-
[19]
Yicong Hong, Yang Zhou, Ruiyi Zhang, Franck Dernoncourt, Trung Bui, Stephen Gould, and Hao Tan. 2023. Learning navigational visual representations with semantic map supervision. InProceedings of the IEEE/CVF International Conference on Computer Vision. 3055–3067
2023
-
[20]
Junjun Hu, Jintao Chen, Haochen Bai, Minghua Luo, Shichao Xie, Ziyi Chen, Fei Liu, Zedong Chu, Xinda Xue, Botao Ren, et al . 2025. AstraNav-World: World Model for Foresight Control and Consistency.arXiv preprint arXiv:2512.21714 (2025)
Pith/arXiv arXiv 2025
-
[21]
Sungjune Kim, Gyeongrok Oh, Heeju Ko, Daehyun Ji, Dongwook Lee, Byung-Jun Lee, Sujin Jang, and Sangpil Kim. 2025. Test-time adaptation for online vision- language navigation with feedback-based reinforcement learning. InForty-second International Conference on Machine Learning
2025
-
[22]
Jacob Krantz, Aaron Gokaslan, Dhruv Batra, Stefan Lee, and Oleksandr Maksymets. 2021. Waypoint models for instruction-guided navigation in contin- uous environments. InProceedings of the IEEE/CVF International Conference on Computer Vision. 15162–15171
2021
-
[23]
Jacob Krantz and Stefan Lee. 2022. Sim-2-sim transfer for vision-and-language navigation in continuous environments. InEuropean conference on computer vision. Springer, 588–603
2022
-
[24]
Jacob Krantz, Erik Wijmans, Arjun Majumdar, Dhruv Batra, and Stefan Lee
-
[25]
InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16
Beyond the nav-graph: Vision-and-language navigation in continuous environments. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII 16. Springer, 104–120
2020
-
[26]
Guoxin Lian, Shuo Wang, Yucheng Wang, Yongcai Wang, Maiyue Chen, Kaihui Wang, Bo Zhang, Zhizhong Su, Deying Li, and Zhaoxin Fan. 2026. MapDream: Arxiv Preprint, 2026, Haoxiang Shi et al. Task-Driven Map Learning for Vision-Language Navigation.arXiv preprint arXiv:2602.00222(2026)
arXiv 2026
-
[27]
Bingqian Lin, Yunshuang Nie, Ziming Wei, Yi Zhu, Hang Xu, Shikui Ma, Jianzhuang Liu, and Xiaodan Liang. 2024. Correctable landmark discovery via large models for vision-language navigation.IEEE Transactions on Pattern Analy- sis and Machine Intelligence46, 12 (2024), 8534–8548
2024
-
[28]
Rui Liu, Wenguan Wang, and Yi Yang. 2024. Vision-language navigation with energy-based policy.Advances in Neural Information Processing Systems37 (2024), 108208–108230
2024
-
[29]
Rui Liu, Wenguan Wang, and Yi Yang. 2024. Volumetric environment representa- tion for vision-language navigation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16317–16328
2024
-
[30]
Yuxing Long, Wenzhe Cai, Hongcheng Wang, Guanqi Zhan, and Hao Dong. 2024. Instructnav: Zero-shot system for generic instruction navigation in unexplored environment.arXiv preprint arXiv:2406.04882(2024)
arXiv 2024
-
[31]
Zhangyang Qi, Zhixiong Zhang, Yizhou Yu, Jiaqi Wang, and Hengshuang Zhao
-
[32]
Vln-r1: Vision-language navigation via reinforcement fine-tuning.arXiv preprint arXiv:2506.17221(2025)
arXiv 2025
-
[33]
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. 2015. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention. Springer, 234–241
2015
-
[34]
Xiangyu Shi, Zerui Li, Wenqi Lyu, Jiatong Xia, Feras Dayoub, Yanyuan Qiao, and Qi Wu. 2025. SmartWay: Enhanced Waypoint Prediction and Backtracking for Zero-Shot Vision-and-Language Navigation.arXiv preprint arXiv:2503.10069 (2025)
arXiv 2025
-
[35]
Ajay Sridhar, Dhruv Shah, Catherine Glossop, and Sergey Levine. 2024. Nomad: Goal masked diffusion policies for navigation and exploration. In2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 63–70
2024
-
[36]
Hanqing Wang, Wei Liang, Luc Van Gool, and Wenguan Wang. 2023. Dreamwalker: Mental planning for continuous vision-language navigation. In Proceedings of the IEEE/CVF international conference on computer vision. 10873– 10883
2023
-
[37]
Shuo Wang, Yongcai Wang, Zhaoxin Fan, Yucheng Wang, Maiyue Chen, Kaihui Wang, Zhizhong Su, Wanting Li, Xudong Cai, Yeying Jin, et al. 2026. Monodream: Monocular vision-language navigation with panoramic dreaming. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 10074–10082
2026
-
[38]
Yunheng Wang, Yuetong Fang, Taowen Wang, Yixiao Feng, Yawen Tan, Shuning Zhang, Peiran Liu, Yiding Ji, and Renjing Xu. 2025. Dreamnav: A trajectory-based imaginative framework for zero-shot vision-and-language navigation.arXiv preprint arXiv:2509.11197(2025)
arXiv 2025
-
[39]
Zihan Wang, Seungjun Lee, and Gim Hee Lee. 2025. Dynam3D: Dynamic Layered 3D Tokens Empower VLM for Vision-and-Language Navigation. InAdvances in Neural Information Processing Systems
2025
-
[40]
Zihan Wang, Xiangyang Li, Jiahao Yang, Yeqi Liu, and Shuqiang Jiang. 2023. Gridmm: Grid memory map for vision-and-language navigation. InProceedings of the IEEE/CVF International conference on computer vision. 15625–15636
2023
-
[41]
Zihan Wang, Yaohui Zhu, Gim Hee Lee, and Yachun Fan. 2025. Navrag: Gen- erating user demand instructions for embodied navigation through retrieval- augmented llm. InFindings of the Association for Computational Linguistics: ACL
2025
-
[42]
Meng Wei, Chenyang Wan, Jiaqi Peng, Xiqian Yu, Yuqiang Yang, Delin Feng, Wenzhe Cai, Chenming Zhu, Tai Wang, Jiangmiao Pang, et al . 2025. Ground slow, move fast: A dual-system foundation model for generalizable vision-and- language navigation.arXiv preprint arXiv:2512.08186(2025)
arXiv 2025
-
[43]
Meng Wei, Chenyang Wan, Xiqian Yu, Tai Wang, Yuqiang Yang, Xiaohan Mao, Chenming Zhu, Wenzhe Cai, Hanqing Wang, Yilun Chen, et al. 2025. Streamvln: Streaming vision-and-language navigation via slowfast context modeling.arXiv preprint arXiv:2507.05240(2025)
arXiv 2025
-
[44]
Xuan Yao, Junyu Gao, and Changsheng Xu. 2025. Navmorph: A self-evolving world model for vision-and-language navigation in continuous environments. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5536– 5546
2025
-
[45]
Shuang Zeng, Dekang Qi, Xinyuan Chang, Feng Xiong, Shichao Xie, Xiaolong Wu, Shiyi Liang, Mu Xu, and Xing Wei. 2025. JanusVLN: Decoupling Semantics and Spatiality with Dual Implicit Memory for Vision-Language Navigation.arXiv preprint arXiv:2509.22548(2025)
arXiv 2025
-
[46]
Yiming Zeng, Hao Ren, Shuhang Wang, Junlong Huang, and Hui Cheng. 2025. Navidiffusor: Cost-guided diffusion model for visual navigation. In2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 11994–12001
2025
-
[47]
Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, et al. 2025. Embodied navigation foundation model.arXiv preprint arXiv:2509.12129(2025)
arXiv 2025
-
[48]
Jiwen Zhang, Zejun Li, Siyuan Wang, Xiangyu Shi, Zhongyu Wei, and Qi Wu
-
[49]
SpatialNav: Leveraging Spatial Scene Graphs for Zero-Shot Vision-and- Language Navigation.arXiv preprint arXiv:2601.06806(2026)
arXiv 2026
-
[50]
Jiazhao Zhang, Kunyu Wang, Shaoan Wang, Minghan Li, Haoran Liu, Songlin Wei, Zhongyuan Wang, Zhizheng Zhang, and He Wang. 2024. Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks.arXiv preprint arXiv:2412.06224(2024)
Pith/arXiv arXiv 2024
-
[51]
Jiazhao Zhang, Kunyu Wang, Rongtao Xu, Gengze Zhou, Yicong Hong, Xiaomeng Fang, Qi Wu, Zhizheng Zhang, and He Wang. 2024. Navid: Video-based vlm plans the next step for vision-and-language navigation.arXiv preprint arXiv:2402.15852 (2024)
Pith/arXiv arXiv 2024
-
[52]
Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Peng- wei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu
-
[53]
InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
Mapnav: A novel memory representation via annotated semantic maps for vlm-based vision-and-language navigation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 13032–13056
-
[54]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. 2025. Efficient- VLN: A Training-Efficient Vision-Language Navigation Model.arXiv preprint arXiv:2512.10310(2025)
arXiv 2025
-
[55]
Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Liwei Wang. 2024. To- wards learning a generalist model for embodied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 13624–13634
2024
-
[56]
Gengze Zhou, Yicong Hong, Zun Wang, Chongyang Zhao, Mohit Bansal, and Qi Wu. 2025. Same: Learning generic language-guided visual navigation with state-adaptive mixture of experts. InProceedings of the IEEE/CVF International Conference on Computer Vision. 7794–7807
2025
-
[57]
Gengze Zhou, Yicong Hong, and Qi Wu. 2024. Navgpt: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7641–7649. Beyond Waypoints: A Trajectory-Centric Waypointing Paradigm for Vision-Language Navigation Arxiv Preprint, 2026, Beyond Waypoints: A Traject...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.