Watch, Remember, Reason: Human-View Video Understanding with MLLMs
Pith reviewed 2026-06-27 21:59 UTC · model grok-4.3
The pith
Video MLLMs acquire evidence, preserve context, and produce outputs through watching, remembering, and reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
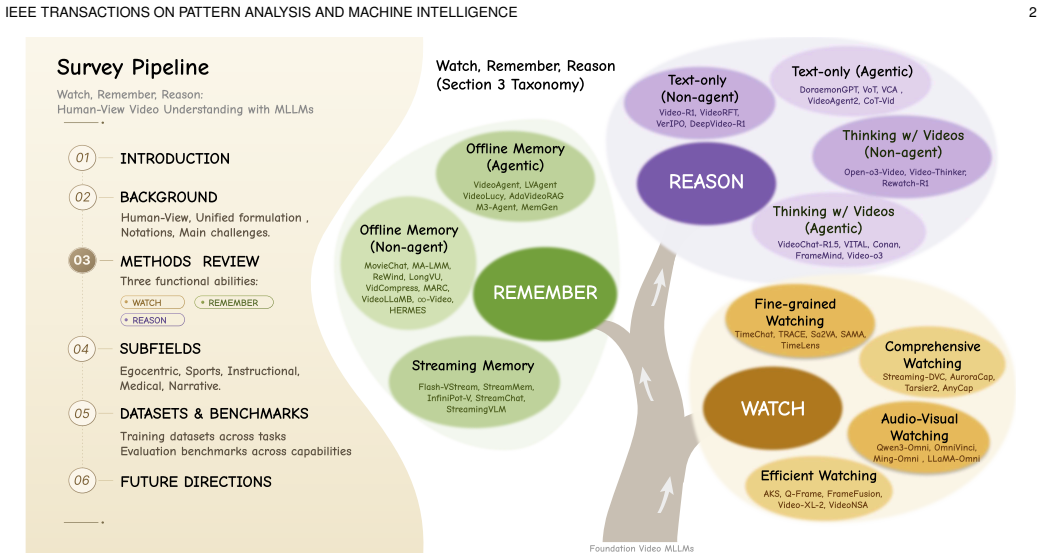
Video understanding with MLLMs is best characterized by a formulation that decomposes systems into perceptual representations, memory states, reasoning traces, and final predictions, which in turn map onto the three abilities of watching, remembering, and reasoning; this decomposition supplies a single lens for organizing methods, identifying challenges in spatio-temporal perception and memory modeling, and covering domains from egocentric to narrative videos.
What carries the argument
The three functional abilities—watching, remembering, and reasoning—that partition video MLLM behavior and link the four system components (perceptual representations, memory states, reasoning traces, final predictions) into a unified analysis structure.
Load-bearing premise
Every video understanding system can be usefully described by four fixed components and partitioned without overlap or remainder into the three abilities of watching, remembering, and reasoning.
What would settle it
A deployed video MLLM whose accuracy, efficiency, or failure modes on long videos cannot be improved or explained by separately measuring or modifying its watching, remembering, or reasoning components.
Figures
read the original abstract
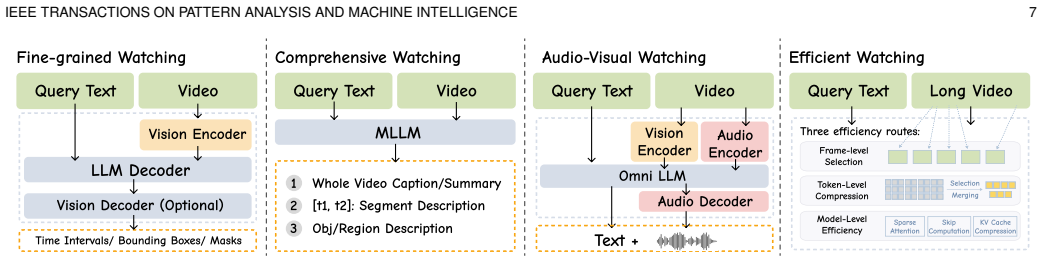
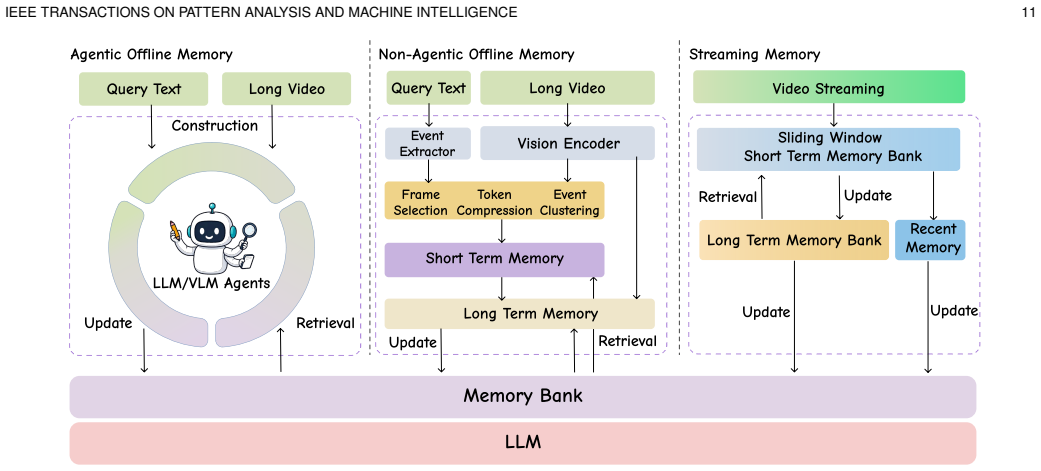
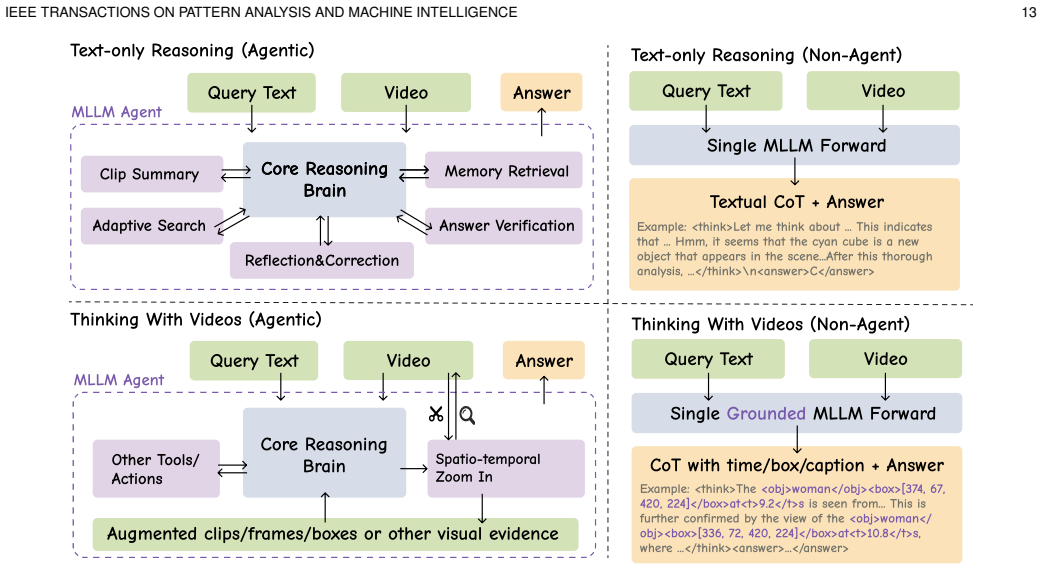
Video understanding is being rapidly transformed by multimodal large language models (MLLMs), as research moves from short clips to long, multimodal, and knowledge-intensive video scenarios. These scenarios require models to handle sparse evidence, long-range dependencies, multimodal alignment, and reliable inference under limited computational budgets. This work presents a human-view perspective on LLM-based video understanding, organized around three functional abilities: watching, remembering, and reasoning. Rather than treating video tasks as isolated benchmarks, this view provides a unified structure for analyzing how video MLLMs acquire evidence, preserve context, and produce grounded outputs. We introduce a formulation that characterizes video understanding systems by their perceptual representations, memory states, reasoning traces, and final predictions. Based on this formulation, we identify challenges in spatio-temporal perception, efficient long-video processing, memory modeling, streaming understanding, and faithful reasoning. Representative methods are organized by their roles in video MLLM systems. Watching covers fine-grained, comprehensive, audio-visual, and efficient perception. Remembering includes offline and streaming memory, while reasoning covers text-only reasoning and thinking with videos. We further examine application domains such as egocentric, sports, instructional, medical, and narrative videos, and cover training datasets and evaluation benchmarks across task types, supervision formats, modalities, and capability dimensions. Finally, we outline open problems and future directions for scalable, memory-aware, and evidence-grounded video intelligence. Related works will be continuously traced at https://github.com/marinero4972/Awesome-HumanView-VideoUnderstanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This survey paper proposes a human-view organizational framework for video understanding with multimodal large language models (MLLMs), structured around three functional abilities (watching, remembering, reasoning) and four system components (perceptual representations, memory states, reasoning traces, final predictions). It uses this framing to categorize methods for fine-grained perception, memory modeling (offline/streaming), and reasoning (text-only or video-grounded), while surveying challenges in spatio-temporal perception and long-video processing, application domains (egocentric, sports, medical, etc.), datasets, benchmarks, and open problems.
Significance. If the proposed partition proves useful for synthesis, the work could help researchers map existing methods onto a common structure for identifying gaps in memory-aware and evidence-grounded video intelligence, particularly as the field shifts toward long, multimodal scenarios. Its value is primarily in organization and coverage rather than new derivations or measurements.
minor comments (3)
- The formulation characterizing systems by perceptual representations, memory states, reasoning traces, and final predictions is introduced in the abstract and presumably detailed early in the manuscript; if this is presented only descriptively without a diagram or explicit mapping table to the three abilities, it risks remaining informal for readers attempting to apply the framework to new papers.
- The abstract states that representative methods are 'organized by their roles in video MLLM systems' under the three abilities, but without an explicit cross-reference table or section that lists which cited works map to which component, the organizational claim is harder to verify.
- The GitHub link for continuously traced related works is mentioned but not cited as a reference; adding a formal citation or footnote would improve traceability.
Simulated Author's Rebuttal
We thank the referee for their positive summary of our survey and the recommendation of minor revision. No specific major comments were provided in the report, so we have no individual points requiring point-by-point rebuttal. We will incorporate minor improvements for clarity and completeness in the revised version.
Circularity Check
No significant circularity; organizational survey framing is self-contained
full rationale
The paper is a literature survey that proposes an organizational perspective on video MLLMs structured around three functional abilities (watching, remembering, reasoning) and four system components (perceptual representations, memory states, reasoning traces, final predictions). The central claim is that this supplies a unified structure for analyzing existing methods, challenges, datasets, and benchmarks rather than introducing new empirical results or a falsifiable model. The partition is presented as a useful framing for the survey; no stronger claim of exhaustiveness, disjointness, or predictive power is required for the work to fulfill its stated purpose. No equations, fitted parameters, predictions, or self-citation chains appear in the derivation chain. All cited works are external and the framework does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3.5: Towards native multimodal agents,
Qwen Team, “Qwen3.5: Towards native multimodal agents,” February 2026. [Online]. Available: https://qwen.ai/blog?id= qwen3.5
2026
-
[2]
J. Xu, Z. Guo, H. Hu, Y. Chu, X. Wang, J. He, Y. Wang, X. Shi, T. He, X. Zhu, Y. Lv, Y. Wang, D. Guo, H. Wang, L. Ma, P . Zhang, X. Zhang, H. Hao, Z. Guo, B. Yang, B. Zhang, Z. Ma, X. Wei, S. Bai, K. Chen, X. Liu, P . Wang, M. Yang, D. Liu, X. Ren, B. Zheng, R. Men, F. Zhou, B. Yu, J. Yang, L. Yu, J. Zhou, and J. Lin, “Qwen3- omni technical report,” arXiv...
Pith/arXiv arXiv 2025
-
[3]
Qwen3-vl technical report,
S. Bai, Y. Cai, R. Chen, K. Chen, X. Chenet al., “Qwen3-vl technical report,” Nov. 2025. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 24
2025
-
[4]
Qwen2. 5-omni technical report,
J. Xu, Z. Guo, J. He, H. Hu, T. He, S. Bai, K. Chen, J. Wang, Y. Fan, K. Danget al., “Qwen2. 5-omni technical report,” arXiv preprint arXiv:2503.20215, 2025
Pith/arXiv arXiv 2025
-
[5]
Video-xl-2: Towards very long-video under- standing through task-aware kv sparsification,
M. Qin, X. Liu, Z. Liang, Y. Shu, H. Yuan, J. Zhou, S. Xiao, B. Zhao, and Z. Liu, “Video-xl-2: Towards very long-video under- standing through task-aware kv sparsification,” arXiv preprint arXiv:2506.19225, 2025
arXiv 2025
-
[6]
Msr-vtt: A large video descrip- tion dataset for bridging video and language,
J. Xu, T. Mei, T. Yao, and Y. Rui, “Msr-vtt: A large video descrip- tion dataset for bridging video and language,” inProceedings of the IEEE conference on computer vision and pattern recognition. Los Alamitos, CA, USA: IEEE Computer Society, 2016, pp. 5288–5296
2016
-
[7]
Video question answering via gradually refined attention over appearance and motion,
D. Xu, Z. Zhao, J. Xiao, F. Wu, H. Zhang, X. He, and Y. Zhuang, “Video question answering via gradually refined attention over appearance and motion,” inProceedings of the 25th ACM interna- tional conference on Multimedia. New York, NY, USA: Association for Computing Machinery, 2017, pp. 1645–1653
2017
-
[8]
Tgif-qa: Toward spatio-temporal reasoning in visual question answering,
Y. Jang, Y. Song, Y. Yu, Y. Kim, and G. Kim, “Tgif-qa: Toward spatio-temporal reasoning in visual question answering,” in Proceedings of the IEEE conference on computer vision and pattern recognition. Los Alamitos, CA, USA: IEEE Computer Society, 2017, pp. 2758–2766
2017
-
[9]
LongVU: Spatiotemporal adaptive compression for long video- language understanding,
X. Shen, Y. Xiong, C. Zhao, L. Wu, J. Chen, C. Zhu, Z. Liu, F. Xiao, B. Varadarajan, F. Bordes, Z. Liu, H. Xu, H. J. Kim, B. Soran, R. Krishnamoorthi, M. Elhoseiny, and V . Chandra, “LongVU: Spatiotemporal adaptive compression for long video- language understanding,” inForty-second International Conference on Machine Learning, 2025
2025
-
[10]
Longvideo-r1: Smart navigation for low-cost long video understanding,
J. Qiu, L. Xie, X. Huo, Q. Tian, and Q. Ye, “Longvideo-r1: Smart navigation for low-cost long video understanding,” arXiv preprint arXiv:2602.20913, 2026
Pith/arXiv arXiv 2026
-
[11]
Video-o3: Native inter- leaved clue seeking for long video multi-hop reasoning,
X. Zeng, Z. Zhang, Y. Zhu, X. Li, Z. Wang, C. Ma, Q. Zhang, Z. Huang, K. Ouyang, T. Jianget al., “Video-o3: Native inter- leaved clue seeking for long video multi-hop reasoning,” arXiv preprint arXiv:2601.23224, 2026
Pith/arXiv arXiv 2026
-
[12]
Ego4d: Around the world in 3,000 hours of egocentric video,
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liuet al., “Ego4d: Around the world in 3,000 hours of egocentric video,” inCVPR. Los Alamitos, CA, USA: IEEE Computer Society, 2022
2022
-
[14]
A visually grounded language model for fetal ultrasound understanding,
X. Guo, M. Alsharid, H. Zhao, Y. Wang, J. Lander, A. T. Pa- pageorghiou, and J. A. Noble, “A visually grounded language model for fetal ultrasound understanding,” Nature Biomedical Engineering, advance online publication, 2026
2026
-
[15]
Streamingvlm: Real-time understanding for infinite video streams,
R. Xu, G. Xiao, Y. Chen, L. He, K. Peng, Y. Lu, and S. Han, “Streamingvlm: Real-time understanding for infinite video streams,” 2025. [Online]. Available: https://arxiv.org/abs/2510. 09608
2025
-
[16]
Timechat: A time- sensitive multimodal large language model for long video un- derstanding,
S. Ren, L. Yao, S. Li, X. Sun, and L. Hou, “Timechat: A time- sensitive multimodal large language model for long video un- derstanding,” arXiv preprint arXiv:2312.02051, 2023
arXiv 2023
-
[17]
Adaptive keyframe sampling for long video understanding,
X. Tang, J. Qiu, L. Xie, Y. Tian, J. Jiao, and Q. Ye, “Adaptive keyframe sampling for long video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition. Los Alamitos, CA, USA: IEEE Computer Society, 2025, pp. 29 118–29 128
2025
-
[18]
FrameFusion: Combining similarity and importance for video token reduction on large vision language models,
T. Fu, T. Liu, Q. Han, G. Dai, S. Yan, H. Yang, X. Ning, and Y. Wang, “FrameFusion: Combining similarity and importance for video token reduction on large vision language models,” in Proceedings of the IEEE/CVF International Conference on Computer Vision. Los Alamitos, CA, USA: IEEE Computer Society, 2025, pp. 22 654–22 663
2025
-
[19]
Moviechat: From dense token to sparse memory for long video understanding,
E. Song, W. Chai, G. Wang, Y. Zhang, H. Zhou, F. Wu, H. Chi, X. Guo, T. Ye, Y. Zhanget al., “Moviechat: From dense token to sparse memory for long video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, 2024, pp. 18 221–18 232
2024
-
[20]
Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,
B. He, H. Li, Y. K. Jang, M. Jia, X. Cao, A. Shah, A. Shrivastava, and S.-N. Lim, “Ma-lmm: Memory-augmented large multimodal model for long-term video understanding,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 504–13 514
2024
-
[21]
Memory-enhanced retrieval augmentation for long video understanding,
H. Yuan, Z. Liu, M. Qin, H. Qian, Y. Shu, Z. Dou, J.-R. Wen, and N. Sebe, “Memory-enhanced retrieval augmentation for long video understanding,” 2025. [Online]. Available: https://arxiv.org/abs/2503.09149
arXiv 2025
-
[22]
Flash-vstream: Memory-based real-time understanding for long video streams,
H. Zhang, Y. Wang, Y. Tang, Y. Liu, J. Feng, J. Dai, and X. Jin, “Flash-vstream: Memory-based real-time understanding for long video streams,” 2024. [Online]. Available: https: //arxiv.org/abs/2406.08085
arXiv 2024
-
[23]
Streammem: Query-agnostic kv cache memory for streaming video understanding,
Y. Yang, Z. Zhao, S. N. Shukla, A. Singh, S. K. Mishra, L. Zhang, and M. Ren, “Streammem: Query-agnostic kv cache memory for streaming video understanding,” 2025. [Online]. Available: https://arxiv.org/abs/2508.15717
arXiv 2025
-
[24]
Video-r1: Reinforcing video reasoning in mllms,
K. Feng, K. Gong, B. Li, Z. Guo, Y. Wang, T. Peng, J. Wu, X. Zhang, B. Wang, and X. Yue, “Video-r1: Reinforcing video reasoning in mllms,” arXiv preprint arXiv:2503.21776, 2025
Pith/arXiv arXiv 2025
-
[25]
Videorft: In- centivizing video reasoning capability in mllms via reinforced fine-tuning,
Q. Wang, Y. Yu, Y. Yuan, R. Mao, and T. Zhou, “Videorft: In- centivizing video reasoning capability in mllms via reinforced fine-tuning,” arXiv preprint arXiv:2505.12434, 2025
arXiv 2025
-
[26]
Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence,
J. Meng, X. Li, H. Wang, Y. Tan, T. Zhang, L. Kong, Y. Tong, A. Wang, Z. Teng, Y. Wanget al., “Open-o3 video: Grounded video reasoning with explicit spatio-temporal evidence,” arXiv preprint arXiv:2510.20579, 2025
arXiv 2025
-
[27]
Thinking with videos: Multimodal tool- augmented reinforcement learning for long video reasoning,
H. Zhang, X. Gu, J. Li, C. Ma, S. Bai, C. Zhang, B. Zhang, Z. Zhou, D. He, and Y. Tang, “Thinking with videos: Multimodal tool- augmented reinforcement learning for long video reasoning,” arXiv preprint arXiv:2508.04416, 2025
arXiv 2025
-
[28]
Video-language understanding: A survey from model architecture, model training, and data per- spectives,
T. Nguyen, Y. Bin, J. Xiao, L. Qu, Y. Li, J. Z. Wu, C.-D. Nguyen, S. K. Ng, and L. A. Tuan, “Video-language understanding: A survey from model architecture, model training, and data per- spectives,” inFindings of the Association for Computational Lin- guistics: ACL 2024. Stroudsburg, PA, USA: Association for Computational Linguistics, 2024, pp. 3636–3657
2024
-
[29]
Video understanding with large language models: A survey,
Y. Tang, J. Bi, S. Xu, L. Song, S. Liang, T. Wang, D. Zhang, J. An, J. Lin, R. Zhu, A. Vosoughi, C. Huang, Z. Zhang, P . Liu, M. Feng, F. Zheng, J.-L. Gaudiot, P . Luo, J. Luo, and C. Xu, “Video understanding with large language models: A survey,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 36, no. 2, pp. 1355–1376, Feb. 2026
2026
-
[30]
A survey on video temporal grounding with multimodal large lan- guage model,
J. Wu, W. Liu, Y. Liu, M. Liu, L. Nie, Z. Lin, and C. W. Chen, “A survey on video temporal grounding with multimodal large lan- guage model,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 48, no. 2, pp. 1521–1541, 2026
2026
-
[31]
Video-LMM post-training: A deep dive into video reasoning with large multimodal models,
Y. Tang, J. Bi, P . Liu, Z. Pan, Z. Tan, Q. Shen, J. Liu, H. Hua, J. Guo, Y. Xiaoet al., “Video-LMM post-training: A deep dive into video reasoning with large multimodal models,” arXiv preprint arXiv:2510.05034, 2025
arXiv 2025
-
[32]
A survey of reinforcement learning for large reasoning models,
K. Zhang, Y. Zuo, B. He, Y. Sun, R. Liu, C. Jiang, Y. Fan, K. Tian, G. Jia, P . Liet al., “A survey of reinforcement learning for large reasoning models,” arXiv preprint arXiv:2509.08827, 2025
Pith/arXiv arXiv 2025
-
[33]
Memory in the age of ai agents,
Y. Hu, S. Liu, Y. Yue, G. Zhang, B. Liu, F. Zhu, J. Lin, H. Guo, S. Dou, Z. Xiet al., “Memory in the age of ai agents,” arXiv preprint arXiv:2512.13564, 2025
Pith/arXiv arXiv 2025
-
[34]
Z. Kong, Y. Li, F. Zeng, L. Xin, S. Messica, X. Lin, P . Zhao, M. Kellis, H. Tang, and M. Zitnik, “Token reduction should go beyond efficiency in generative models–from vision, language to multimodality,” arXiv preprint arXiv:2505.18227, 2025
arXiv 2025
-
[35]
Perception, reason, think, and plan: A survey on large multimodal reasoning models,
Y. Li, Z. Liu, Z. Li, X. Zhang, Z. Xu, X. Chen, H. Shi, S. Jiang, X. Wang, J. Wanget al., “Perception, reason, think, and plan: A survey on large multimodal reasoning models,” arXiv preprint arXiv:2505.04921, 2025
arXiv 2025
-
[36]
Lita: Language instructed temporal- localization assistant,
D.-A. Huang, S. Liao, S. Radhakrishnan, H. Yin, P . Molchanov, Z. Yu, and J. Kautz, “Lita: Language instructed temporal- localization assistant,” inEuropean Conference on Computer Vision (ECCV). Cham, Switzerland: Springer, 2024
2024
-
[37]
Universal video temporal grounding with generative multi-modal large language models,
Z. Li, S. Di, Z. Zhai, W. Huang, Y. Wang, and W. Xie, “Universal video temporal grounding with generative multi-modal large language models,” inAdvances in Neural Information Processing Systems (NeurIPS). Red Hook, NY, USA: Curran Associates, Inc., 2025, affiliations: Shanghai Jiao Tong University; ByteDance Seed
2025
-
[38]
Timelens: Rethinking video temporal grounding with multi- modal llms,
J. Zhang, T. Wang, Y. Ge, Y. Ge, X. Li, Y. Shan, and L. Wang, “Timelens: Rethinking video temporal grounding with multi- modal llms,” arXiv preprint arXiv:2512.14698, 2025, affiliations: Nanjing University; ARC Lab, Tencent PCG; Shanghai AI Lab
arXiv 2025
-
[39]
Towards one-to-many temporal grounding,
Q. Xu, T. Yue, S. Chen, J. Meng, A. Wang, S. Ji, H. Fei, and X. Li, “Towards one-to-many temporal grounding,” inProceedings of the 43rd International Conference on Machine Learning (ICML). Brookline, MA, USA: PMLR, 2026
2026
-
[40]
Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos,
H. Yuan, X. Li, T. Zhang, Y. Sun, Z. Huang, S. Xu, S. Ji, Y. Tong, L. Qi, J. Fenget al., “Sa2va: Marrying sam2 with llava for dense grounded understanding of images and videos,” arXiv preprint arXiv:2501.04001, 2025. IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 25
Pith/arXiv arXiv 2025
-
[41]
Sama: Towards multi-turn referential grounded video chat with large language models,
Y. Sun, H. Zhang, H. Ding, T. Zhang, X. Ma, and Y.-G. Jiang, “Sama: Towards multi-turn referential grounded video chat with large language models,” inAdvances in Neural Information Pro- cessing Systems. Red Hook, NY, USA: Curran Associates, Inc., 2025
2025
-
[42]
Streaming dense video captioning,
G. Zhou, X. Xiong, A. Bhattacharyya, and J. J. Corso, “Streaming dense video captioning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Los Alamitos, CA, USA: IEEE Computer Society, 2024, pp. 18 486–18 496
2024
-
[43]
Do you remember? dense video captioning with cross-modal memory retrieval,
M. Kim, H. B. Kim, J. Moon, J. Choi, and S. T. Kim, “Do you remember? dense video captioning with cross-modal memory retrieval,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Los Alamitos, CA, USA: IEEE Computer Society, 2024, pp. 13 894–13 904
2024
-
[44]
Dibs: Enhancing dense video captioning with unlabeled videos via pseudo boundary en- richment and online refinement,
H. Wu, H. Liu, Y. Qiao, and X. Sun, “Dibs: Enhancing dense video captioning with unlabeled videos via pseudo boundary en- richment and online refinement,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition. Los Alamitos, CA, USA: IEEE Computer Society, 2024, pp. 18 699–18 708
2024
-
[45]
PLLaVA: Parameter-free LLaVA extension from images to videos for video dense captioning,
L. Xu, Y. Huang, S. Xie, W. Wei, T. Li, B. Pan, Y. Zhao, and J. Yuan, “PLLaVA: Parameter-free LLaVA extension from images to videos for video dense captioning,” arXiv preprint arXiv:2404.16994, 2024
Pith/arXiv arXiv 2024
-
[46]
AuroraCap: Efficient, performant video detailed captioning and a new benchmark,
W. Chai, E. Song, Y. Du, C. Meng, V . Madhavan, O. Bar-Tal, J.- N. Hwang, S. Xie, and C. D. Manning, “AuroraCap: Efficient, performant video detailed captioning and a new benchmark,” arXiv preprint arXiv:2410.03051, 2024
arXiv 2024
-
[47]
L. Yuan, J. Wang, H. Sun, Y. Zhang, and Y. Lin, “Tarsier2: Advancing large vision-language models from detailed video de- scription to comprehensive video understanding,” arXiv preprint arXiv:2501.07888, 2025
arXiv 2025
-
[48]
Baichuan-omni technical report,
Y. Li, H. Sun, M. Lin, T. Li, G. Dong, T. Zhang, B. Ding, W. Song, Z. Cheng, Y. Huoet al., “Baichuan-omni technical report,” arXiv preprint arXiv:2410.08565, 2024
arXiv 2024
-
[49]
Ming-omni: A unified mul- timodal model for perception and generation,
I. AI, B. Gong, C. Zou, C. Zheng, C. Zhou, C. Yan, C. Jin, C. Shen, D. Zheng, F. Wanget al., “Ming-omni: A unified mul- timodal model for perception and generation,” arXiv preprint arXiv:2506.09344, 2025
arXiv 2025
-
[50]
Llama- omni: Seamless speech interaction with large language models,
Q. Fang, S. Guo, Y. Zhou, Z. Ma, S. Zhang, and Y. Feng, “Llama- omni: Seamless speech interaction with large language models,” arXiv preprint arXiv:2409.06666, 2024
arXiv 2024
-
[51]
Stream-omni: Simultaneous multimodal interactions with large language- vision-speech model,
S. Zhang, S. Guo, Q. Fang, Y. Zhou, and Y. Feng, “Stream-omni: Simultaneous multimodal interactions with large language- vision-speech model,” arXiv preprint arXiv:2506.13642, 2025
arXiv 2025
-
[52]
Omnicaptioner: One captioner to rule them all,
Y. Lu, J. Yuan, Z. Li, S. Zhao, Q. Qin, X. Li, L. Zhuo, L. Wen, D. Liu, Y. Caoet al., “Omnicaptioner: One captioner to rule them all,” arXiv preprint arXiv:2504.07089, 2025
arXiv 2025
-
[53]
Omnivinci: Enhancing ar- chitecture and data for omni-modal understanding llm,
H. Ye, C.-H. H. Yang, A. Goel, W. Huang, L. Zhu, Y. Su, S. Lin, A.-C. Cheng, Z. Wan, J. Tianet al., “Omnivinci: Enhancing ar- chitecture and data for omni-modal understanding llm,” arXiv preprint arXiv:2510.15870, 2025
arXiv 2025
-
[54]
Q-Frame: Query- aware frame selection and multi-resolution adaptation for video- LLMs,
S. Zhang, J. Yang, J. Yin, Z. Luo, and J. Luan, “Q-Frame: Query- aware frame selection and multi-resolution adaptation for video- LLMs,” arXiv preprint arXiv:2506.22139, 2025
arXiv 2025
-
[55]
DyCoke: Dynamic compression of tokens for fast video large language models,
K. Tao, C. Qin, H. You, Y. Sui, and H. Wang, “DyCoke: Dynamic compression of tokens for fast video large language models,” in Proceedings of the Computer Vision and Pattern Recognition Confer- ence. Los Alamitos, CA, USA: IEEE Computer Society, 2025, pp. 18 992–19 001
2025
-
[56]
Videonsa: Native sparse attention scales video un- derstanding,
E. Song, W. Chai, S. Yang, E. Armand, X. Shan, H. Xu, J. Xie, and Z. Tu, “Videonsa: Native sparse attention scales video un- derstanding,” arXiv preprint arXiv:2510.02295, 2025
arXiv 2025
-
[57]
Vtimellm: Empower llm to grasp video moments,
B. Huang, X. Wang, H. Chen, Z. Song, and W. Zhu, “Vtimellm: Empower llm to grasp video moments,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Los Alamitos, CA, USA: IEEE Computer Society, 2024
2024
-
[58]
Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,
Y. Guo, J. Liu, M. Li, D. Cheng, X. Tang, D. Sui, Q. Liu, X. Chen, and K. Zhao, “Vtg-llm: Integrating timestamp knowledge into video llms for enhanced video temporal grounding,” inProceed- ings of the AAAI Conference on Artificial Intelligence. Palo Alto, CA, USA: AAAI Press, 2025
2025
-
[59]
Distime: Distribution-based time representation for video large language models,
Y. Zeng, Z. Huang, Y. Zhong, C. Feng, J. Hu, L. Ma, and Y. Liu, “Distime: Distribution-based time representation for video large language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). Los Alamitos, CA, USA: IEEE Computer Society, 2025
2025
-
[60]
Self-chained image- language model for video localization and question answering,
S. Yu, J. Cho, P . Yadav, and M. Bansal, “Self-chained image- language model for video localization and question answering,” inAdvances in Neural Information Processing Systems (NeurIPS). Red Hook, NY, USA: Curran Associates, Inc., 2023, affiliation: UNC Chapel Hill
2023
-
[61]
Llava-mr: Large language-and-vision assistant for video moment retrieval,
W. Lu, J. Li, A. Yu, M.-C. Chang, S. Ji, and M. Xia, “Llava-mr: Large language-and-vision assistant for video moment retrieval,” arXiv preprint arXiv:2411.14505, 2024, affiliations: Peking Univer- sity; Tencent Youtu; University at Albany; Zhejiang University. (* indicates corresponding author in the paper.)
arXiv 2024
-
[62]
Timesuite: Improving mllms for long video understanding via grounded tuning,
X. Zeng, K. Li, C. Wang, X. Li, T. Jiang, Z. Yan, S. Li, Y. Shi, Z. Yue, Y. Wang, Y. Wang, Y. Qiao, and L. Wang, “Timesuite: Improving mllms for long video understanding via grounded tuning,” inInternational Conference on Learning Representations (ICLR). Online: OpenReview.net, 2025
2025
-
[63]
Scanning only once: An end-to-end framework for fast temporal grounding in long videos,
Y. Pan, X. He, B. Gong, Y. Lv, Y. Shen, Y. Peng, and D. Zhao, “Scanning only once: An end-to-end framework for fast temporal grounding in long videos,” inProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision (ICCV). Los Alamitos, CA, USA: IEEE Computer Society, 2023, affiliations: Alibaba Group; Wangxuan Institute of Computer Technolog...
2023
-
[64]
Trace: Temporal grounding video llm via causal event modeling,
Y. Guo, J. Liu, M. Li, Q. Liu, X. Chen, and X. Tang, “Trace: Temporal grounding video llm via causal event modeling,” in International Conference on Learning Representations (ICLR). On- line: OpenReview.net, 2025, affiliations: School of Science and Engineering, The Chinese University of Hong Kong, Shenzhen; Tencent PCG; Shenzhen Institute of Artificial I...
2025
-
[65]
Tar-tvg: Enhancing vlms with timestamp anchor-constrained reasoning for temporal video grounding,
C. Guo, X. Mo, Y. Nie, X. Xu, C. Xu, F. Yu, and C. Long, “Tar-tvg: Enhancing vlms with timestamp anchor-constrained reasoning for temporal video grounding,” arXiv preprint arXiv:2508.07683, 2025
arXiv 2025
-
[66]
Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models,
H. Wang, Z. Xu, Y. Cheng, S. Diao, Y. Zhou, Y. Cao, Q. Wang, W. Ge, and L. Huang, “Grounded-videollm: Sharpening fine- grained temporal grounding in video large language models,” arXiv preprint arXiv:2410.03290, 2024
arXiv 2024
-
[67]
Momentor: Advancing video large language model with fine-grained temporal reasoning,
L. Qian, J. Li, Y. Wu, Y. Ye, H. Fei, T.-S. Chua, Y. Zhuang, and S. Tang, “Momentor: Advancing video large language model with fine-grained temporal reasoning,” inProceedings of the 41st International Conference on Machine Learning (ICML). Brookline, MA, USA: PMLR, 2024
2024
-
[68]
F. Zhao, L. Zhang, D. Shi, Y. Gao, C. Ye, Y. Cai, J. Gao, and D. Yan, “Videoperceiver: Enhancing fine-grained temporal perception in video multimodal large language models,” arXiv preprint arXiv:2511.18823, 2025
arXiv 2025
-
[69]
Time-r1: Post-training large vision language model for temporal video grounding,
Y. Wang, Z. Wang, B. Xu, Y. Du, K. Lin, Z. Xiao, Z. Yue, J. Ju, L. Zhang, D. Yanget al., “Time-r1: Post-training large vision language model for temporal video grounding,” arXiv preprint arXiv:2503.13377, 2025
Pith/arXiv arXiv 2025
-
[70]
J. Li, H. Yin, H. Xu, B. Xu, W. Tan, Z. He, J. Ju, Z. Luo, and J. Luan, “Video-opd: Efficient post-training of multimodal large language models for temporal video grounding via on-policy distillation,” arXiv preprint arXiv:2602.02994, 2026
Pith/arXiv arXiv 2026
-
[71]
Videozoomer: Reinforcement-learned temporal focusing for long video reason- ing,
Y. Ding, Y. Zhang, X. Lai, R. Chu, and Y. Yang, “Videozoomer: Reinforcement-learned temporal focusing for long video reason- ing,” arXiv preprint arXiv:2512.22315, 2025
arXiv 2025
-
[72]
Datasets and recipes for video temporal grounding via reinforcement learning,
R. Chen, T. Luo, Z. Fan, H. Zou, Z. Feng, G. Xie, H. Zhang, Z. Wang, Z. Liu, and Z. Huaijian, “Datasets and recipes for video temporal grounding via reinforcement learning,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track. Stroudsburg, PA, USA: Association for Computational Linguistics, 2025, pp. 983–992
2025
-
[73]
Museg: Reinforc- ing video temporal understanding via timestamp-aware multi- segment grounding,
F. Luo, S. Lou, C. Chen, Z. Wang, C. Li, W. Shen, J. Guo, P . Li, M. Yan, J. Zhang, F. Huang, and Y. Liu, “Museg: Reinforc- ing video temporal understanding via timestamp-aware multi- segment grounding,” arXiv preprint arXiv:2505.20715, 2025
Pith/arXiv arXiv 2025
-
[74]
Detect anything via next point prediction,
Q. Jiang, J. Huo, X. Chen, Y. Xiong, Z. Zeng, Y. Chen, T. Ren, J. Yu, and L. Zhang, “Detect anything via next point prediction,” arXiv preprint arXiv:2510.12798, 2025
arXiv 2025
-
[75]
X. Gu, H. Zhang, Q. Fan, J. Niu, Z. Zhang, L. Zhang, G. Chen, F. Chen, L. Wen, and S. Zhu, “Thinking with bounding boxes: Enhancing spatio-temporal video grounding via reinforcement fine-tuning,” arXiv preprint arXiv:2511.21375, 2025
arXiv 2025
-
[76]
Universal instance perception as object discovery and retrieval,
B. Yan, Y. Jiang, J. Wu, D. Wang, Z. Yuan, P . Luo, and H. Lu, IEEE TRANSACTIONS ON PATTERN ANAL YSIS AND MACHINE INTELLIGENCE 26 “Universal instance perception as object discovery and retrieval,” inCVPR. Los Alamitos, CA, USA: IEEE Computer Society, 2023
2023
-
[77]
Multimodal referring segmentation: A survey,
H. Ding, S. Tang, S. He, C. Liu, Z. Wu, and Y.-G. Jiang, “Multimodal referring segmentation: A survey,” arXiv preprint arXiv:2508.00265, 2025
arXiv 2025
-
[78]
Deformable detr: Deformable transformers for end-to-end object detection,
X. Zhu, W. Su, L. Lu, B. Li, X. Wang, and J. Dai, “Deformable detr: Deformable transformers for end-to-end object detection,” arXiv preprint arXiv:2010.04159, 2020
Pith/arXiv arXiv 2010
-
[79]
Lisa: Reasoning segmentation via large language model,
X. Lai, Z. Tian, Y. Chen, Y. Li, Y. Yuan, S. Liu, and J. Jia, “Lisa: Reasoning segmentation via large language model,” inCVPR. Los Alamitos, CA, USA: IEEE Computer Society, 2024
2024
-
[80]
Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding,
T. Zhang, X. Li, H. Fei, H. Yuan, S. Wu, S. Ji, C. L. Chen, and S. Yan, “Omg-llava: Bridging image-level, object-level, pixel-level reasoning and understanding,” inNeurIPS. Red Hook, NY, USA: Curran Associates, Inc., 2024
2024
-
[81]
Generalizable entity grounding via assistance of large language model,
L. Qi, Y.-W. Chen, L. Yang, T. Shen, X. Li, W. Guo, Y. Xu, and M.- H. Yang, “Generalizable entity grounding via assistance of large language model,” arXiv preprint arXiv:2402.02555, 2024
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.