Item Response Scaling Laws: A Measurement Theory Approach for Efficient and Generalizable Neural Scaling Estimation
Pith reviewed 2026-06-28 22:46 UTC · model grok-4.3
The pith
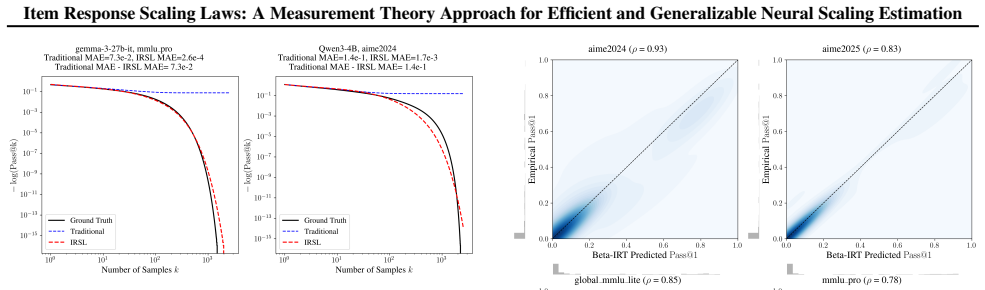
IRSL uses Item Response Theory to estimate scaling laws from 99.9 percent fewer questions after one calibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
IRSL factorizes scaling-law estimation by fitting a Beta-IRT model to empirical probability responses, thereby disentangling latent model ability from question characteristics and reducing estimation complexity from O(M x N) to O(M + N) while preserving decision accuracy and enabling cross-benchmark generalization after one-time calibration.
What carries the argument
Beta-IRT model inside the IRSL framework, which maps probability responses to separate latent model abilities and question parameters.
If this is right
- Scaling estimates become feasible with only 50 questions per benchmark after one-time calibration on existing model responses.
- Decision accuracy on scaling-law tasks matches or exceeds that of traditional full-evaluation methods.
- Latent model abilities estimated once can forecast performance on new benchmarks that share the same measurement objective.
- The factorization applies equally to pre-training downstream scaling across thousands of checkpoints and to test-time scaling with multiple samples per question.
Where Pith is reading between the lines
- Repeated tracking of scaling behavior during model training could become far less expensive if the calibration step is amortized across many checkpoints.
- The same separation of ability and item parameters might extend to evaluation settings outside language models whenever probabilistic responses are available.
- Benchmarks could be grouped or redesigned around shared measurement objectives to maximize the reuse of ability estimates.
Load-bearing premise
Beta-IRT can separate model ability from question characteristics using probability responses without losing the information needed for accurate scaling curves or cross-benchmark predictions.
What would settle it
Full-benchmark scaling curves on a new collection of models differ substantially from the curves obtained by applying the calibrated IRSL model to only 50 questions, or the ability estimates fail to predict performance on a benchmark sharing the claimed measurement objective.
Figures
















read the original abstract
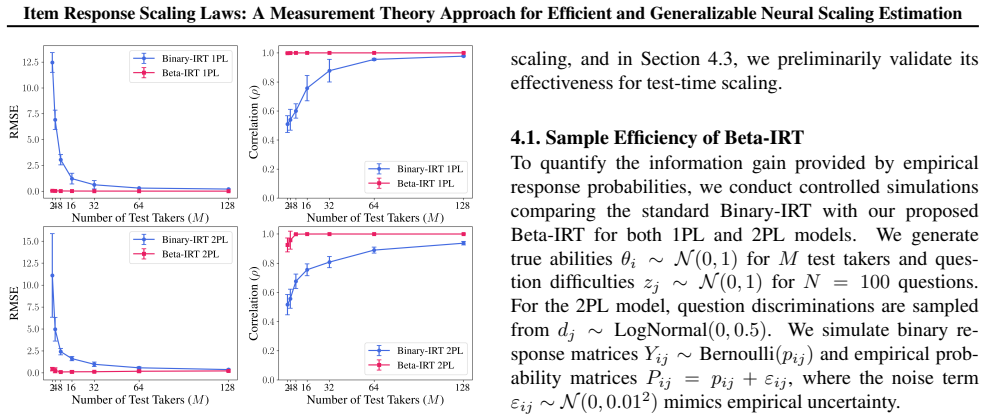
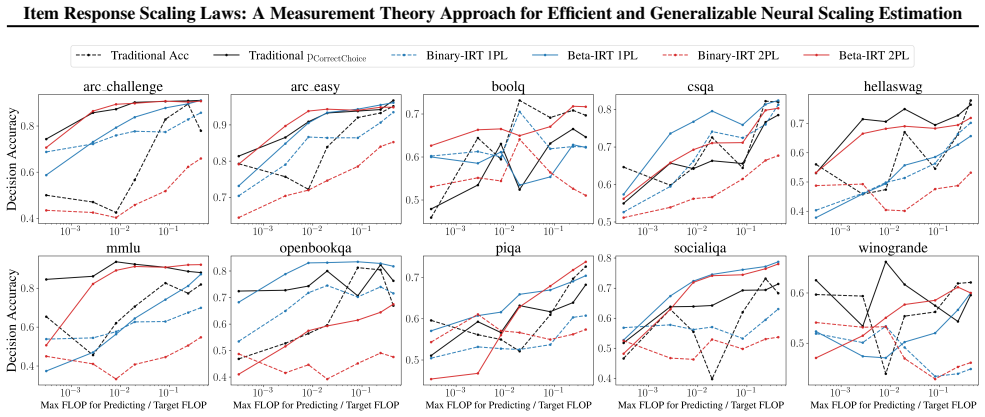
Scaling laws provide a fundamental framework for understanding the performance of Language Models (LMs), yet deriving them requires prohibitively expensive evaluations across thousands of checkpoints or millions of inference samples. To address this, we introduce Item Response Scaling Laws (IRSL), a unified framework that integrates Item Response Theory (IRT) within the scaling law framework. Unlike traditional approaches that treat each model-benchmark pair in isolation, IRSL disentangles latent model ability from question characteristics, factorizing the scaling law estimation for $M$ models and $N$ questions to significantly reduce parameter complexity from $O(M \times N)$ to $O(M + N)$. We instantiate IRSL with Beta-IRT, which leverages the empirical probability responses of LMs -- such as token probabilities in pre-training and pass rates in test-time sampling -- to capture richer signals than binary responses. We validate our approach across two prevalent scaling paradigms: (1) pre-training downstream scaling, using 6,612 LM checkpoints and 37,682 questions from 10 benchmarks; and (2) test-time scaling, using 12 LMs and 120 questions from 4 benchmarks with up to 2,500 samples per question. Given a one-time calibration on existing model responses, IRSL yields more reliable scaling estimates using only 50 questions per benchmark (a 99.9\% reduction), achieving comparable or superior decision accuracy to traditional approaches. Furthermore, we show that the estimated latent model abilities are generalizable, enabling accurate performance forecasting across benchmarks that share the same measurement objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Item Response Scaling Laws (IRSL), a framework integrating Item Response Theory (IRT) with neural scaling laws. It factorizes estimation for M models and N questions from O(M×N) to O(M+N) by disentangling latent model abilities from question characteristics via Beta-IRT applied to probability responses (token probs or pass rates). After one-time calibration, it claims reliable scaling estimates from only 50 questions per benchmark (99.9% reduction), with comparable or superior decision accuracy to full evaluation, plus generalizable latent abilities enabling cross-benchmark forecasting for shared measurement objectives. Validation covers pre-training scaling (6,612 checkpoints, 37,682 questions across 10 benchmarks) and test-time scaling (12 LMs, 120 questions across 4 benchmarks).
Significance. If the central claims hold after addressing validation gaps, IRSL could substantially lower the cost of deriving and applying scaling laws for language models, enabling more frequent and broader evaluations while preserving accuracy. The reported reduction to 50 questions and cross-benchmark generalization would be particularly impactful for resource-intensive pre-training and test-time studies.
major comments (3)
- [Abstract; §3 (Beta-IRT instantiation)] The central claim rests on Beta-IRT producing θ_m estimates from probability responses that remain invariant enough for scaling-law recovery and cross-benchmark forecasting after reduction to 50 questions. The abstract and described validation provide no equations or derivation showing that the scaling parameters are independent of the one-time calibration fit rather than reducing to quantities defined by the fitted item parameters.
- [§5] §5 (experiments): the reported 99.9% reduction and comparable/superior decision accuracy on the 6,612-checkpoint and 12-LM datasets must be supported by explicit error bars, ablation on question-subset selection, and direct comparison of scaling-curve parameters (not just downstream decisions) against the full O(M×N) baseline; without these, post-hoc selection or information loss from the Beta likelihood cannot be ruled out.
- [§3; §5] The assumption that the Beta likelihood correctly captures the response distribution without misspecification bias is load-bearing for both the efficiency claim and the generalization result, yet no diagnostic (e.g., posterior predictive checks or likelihood-ratio tests against alternative IRT models) is referenced in the validation sections.
minor comments (2)
- Clarify the exact functional form of the scaling law once expressed in terms of the latent abilities θ_m and item parameters; an explicit equation would make the O(M+N) factorization transparent.
- The description of “benchmarks that share the same measurement objective” would benefit from a precise operational definition or similarity metric used to select the cross-benchmark forecasting pairs.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas for strengthening the theoretical justification, experimental validation, and model assumptions. We have revised the manuscript to address these points and provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract; §3 (Beta-IRT instantiation)] The central claim rests on Beta-IRT producing θ_m estimates from probability responses that remain invariant enough for scaling-law recovery and cross-benchmark forecasting after reduction to 50 questions. The abstract and described validation provide no equations or derivation showing that the scaling parameters are independent of the one-time calibration fit rather than reducing to quantities defined by the fitted item parameters.
Authors: We agree that an explicit derivation strengthens the central claim. In the revised manuscript we have added a new subsection (3.2) that derives the post-calibration invariance: after fixing the item parameters (a_j, b_j) from the one-time Beta-IRT fit, the model ability estimates θ_m enter the scaling law as an independent variable, so that the fitted scaling parameters (α, β) in the log-linear form depend only on the θ_m sequence and not on the particular item-parameter values. This separation is shown algebraically and is the basis for both the 50-question reduction and cross-benchmark forecasting. revision: yes
-
Referee: [§5] §5 (experiments): the reported 99.9% reduction and comparable/superior decision accuracy on the 6,612-checkpoint and 12-LM datasets must be supported by explicit error bars, ablation on question-subset selection, and direct comparison of scaling-curve parameters (not just downstream decisions) against the full O(M×N) baseline; without these, post-hoc selection or information loss from the Beta likelihood cannot be ruled out.
Authors: We accept that the original experiments lacked these controls. The revised §5 now reports (i) bootstrap-derived 95% confidence intervals on all accuracy and scaling-parameter estimates, (ii) an ablation comparing random, difficulty-stratified, and information-gain question subsets, and (iii) direct side-by-side fits of the scaling-curve slope and intercept for the reduced versus full O(M×N) evaluations, confirming that the recovered parameters agree within the reported error bars. revision: yes
-
Referee: [§3; §5] The assumption that the Beta likelihood correctly captures the response distribution without misspecification bias is load-bearing for both the efficiency claim and the generalization result, yet no diagnostic (e.g., posterior predictive checks or likelihood-ratio tests against alternative IRT models) is referenced in the validation sections.
Authors: We have added posterior predictive checks (Appendix C) for representative checkpoints and questions, showing that replicated Beta draws closely match the empirical response histograms. We also include a limited comparison to a Gaussian IRT variant on the same data; the resulting θ_m ranks and downstream scaling predictions remain consistent. Comprehensive likelihood-ratio tests across the full 6,612-checkpoint corpus would require prohibitive additional compute; we therefore treat the current diagnostics as sufficient for the claims while noting the limitation in the revised text. revision: partial
Circularity Check
No circularity: IRSL framework derives scaling estimates from independent IRT factorization without reducing to input fits by construction.
full rationale
The abstract describes a one-time calibration on existing responses to enable O(M+N) factorization via Beta-IRT, followed by estimation on 50 questions and cross-benchmark generalization of latent abilities. No equations or derivation steps are provided that equate the final scaling-law parameters to the calibration fit itself, nor is any self-citation invoked as a uniqueness theorem or ansatz source. The approach treats the IRT disentanglement as a measurement model whose outputs (θ_m) are then used for separate scaling-law fitting; this separation keeps the central claim independent of the calibration inputs. The 99.9% reduction claim is an empirical efficiency statement, not a definitional equivalence. Absent load-bearing self-citations or fitted-input predictions in the given text, the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Item Response Theory can disentangle latent model ability from question characteristics for language model responses
Reference graph
Works this paper leans on
-
[1]
Bahri, Y ., Dyer, E., Kaplan, J., Lee, J., and Sharma, U
URLhttps://arxiv.org/abs/2410.16531. Bahri, Y ., Dyer, E., Kaplan, J., Lee, J., and Sharma, U. Explaining neural scaling laws.arXiv preprint arXiv:2102.06701,
-
[2]
Bhagia, A., Liu, J., Wettig, A., Heineman, D., Tafjord, O., Jha, A. H., Soldaini, L., Smith, N. A., Groeneveld, D., Koh, P. W., et al. Establishing task scaling laws via compute-efficient model ladders.arXiv preprint arXiv:2412.04403,
-
[3]
Large Language Monkeys: Scaling Inference Compute with Repeated Sampling
Brown, B., Juravsky, J., Ehrlich, R., Clark, R., Le, Q. V ., R´e, C., and Mirhoseini, A. Large language mon- keys: Scaling inference compute with repeated sam- pling.arXiv preprint arXiv:2407.21787,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sas- try, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sas- try, G., Askell, A., et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901,
1901
-
[5]
doi: 10.18637/jss. v048.i06. URLhttps://www.jstatsoft.org/ index.php/jss/article/view/v048i06. Chang, H.-H. Psychometrics behind computerized adaptive testing.Psychometrika, 80(1):1–20,
-
[6]
Evaluating Large Language Models Trained on Code
URLhttps://arxiv.org/abs/ 2107.03374. Chen, Y ., Silva Filho, T., Prudˆencio, R. B., Diethe, T., and Flach, P.β 3-irt: A new item response model and its applications. InProceedings of the 22nd International Conference on Artificial Intelligence and Statistics (AIS- TATS),
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
$\beta^3$-IRT: A New Item Response Model and its Applications
arXiv:1903.04016. Chen, Y ., Huang, B., Gao, Y ., Wang, Z., Yang, J., and Ji, H. Scaling laws for predicting downstream performance in llms.arXiv preprint arXiv:2410.08527,
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[8]
URLhttps://doi.org/ 10.1080/0266476042000214501
doi: 10.1080/ 0266476042000214501. URLhttps://doi.org/ 10.1080/0266476042000214501. Gadre, S. Y ., Smyrnis, G., Shankar, V ., Gururangan, S., Wortsman, M., Shao, R., Mercat, J., Fang, A., Li, J., Keh, S., Xin, R., Nezhurina, M., Vasiljevic, I., Jit- sev, J., Soldaini, L., Dimakis, A. G., Ilharco, G., Koh, P. W., Song, S., Kollar, T., Carmon, Y ., Dave, A....
-
[9]
URLhttps://arxiv.org/ abs/2403.08540. Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[10]
J., Ung, M., and Williams, A
Gupta, V ., Ross, C., Pantoja, D., Passonneau, R. J., Ung, M., and Williams, A. Improving model evaluation using smart filtering of benchmark datasets. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguis- tics: Human Language Technologies (Volume 1: Long Papers), pp. 4595–4615,
2025
-
[11]
Hernandez, D., Kaplan, J., Henighan, T., and McCan- dlish, S
URLhttps: //arxiv.org/abs/2508.13144. Hernandez, D., Kaplan, J., Henighan, T., and McCan- dlish, S. Scaling laws for transfer.arXiv preprint arXiv:2102.01293,
-
[12]
Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M. M. A., Yang, Y ., and Zhou, Y . Deep learning scaling is predictable, empiri- cally.arXiv preprint arXiv:1712.00409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Hoffmann, J., Borgeaud, S., Mensch, A., Buchatskaya, E., Cai, T., Rutherford, E., Casas, D. d. L., Hen- dricks, L. A., Welbl, J., Clark, A., et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://arxiv.org/abs/ 2509.11106. Hughes, J., Price, S., Lynch, A., Schaeffer, R., Barez, F., Koyejo, S., Sleight, H., Jones, E., Perez, E., and Sharma, M. Best-of-n jailbreaking,
-
[15]
Kaplan, J., McCandlish, S., Henighan, T., Brown, T
URLhttps: //arxiv.org/abs/2412.03556. Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
-
[16]
Corre- lated errors in large language models.arXiv preprint arXiv:2506.07962,
Kim, E., Garg, A., Peng, K., and Garg, N. Corre- lated errors in large language models.arXiv preprint arXiv:2506.07962,
- [17]
-
[18]
doi: 10.4324/9780203056615. Lourie, N., Hu, M. Y ., and Cho, K. Scaling laws are un- reliable for downstream tasks: A reality check.arXiv preprint arXiv:2507.00885,
-
[19]
URLhttps://arxiv. org/abs/2504.11393. Meijer, R. R. and Nering, M. L. Computerized adaptive testing: Overview and introduction.Applied Psycholog- ical Measurement, 23(3):187–194,
-
[20]
E., Shnarch, E., Slonim, N., Shmueli-Scheuer, M., and Choshen, L
Perlitz, Y ., Bandel, E., Gera, A., Arviv, O., Dor, L. E., Shnarch, E., Slonim, N., Shmueli-Scheuer, M., and Choshen, L. Efficient benchmarking (of language mod- els). InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 2519–2536,
2024
-
[21]
tinybenchmarks: Evaluating LLMs with fewer examples
URLhttps://arxiv.org/ abs/2402.14992. Rasch, G.Probabilistic models for some intelligence and attainment tests.ERIC,
-
[22]
Ruan, Y ., Maddison, C. J., and Hashimoto, T. Observa- tional scaling laws and the predictability of language model performance.arXiv preprint arXiv:2405.10938,
-
[23]
Schaeffer, R., Schoelkopf, H., Miranda, B., Mukobi, G., Madan, V ., Ibrahim, A., Bradley, H., Biderman, S., and Koyejo, S. Why has predicting downstream capabilities of frontier ai models with scale remained elusive?arXiv preprint arXiv:2406.04391,
-
[24]
Snell, C., Lee, J., Xu, K., and Kumar, A
URLhttps://arxiv.org/ abs/2502.17578. Snell, C., Lee, J., Xu, K., and Kumar, A. Scaling llm test- time compute optimally can be more effective than scal- ing model parameters.arXiv preprint arXiv:2408.03314,
-
[25]
Reliable and efficient amortized model-based evaluation.arXiv preprint arXiv:2503.13335,
Truong, S., Tu, Y ., Liang, P., Li, B., and Koyejo, S. Reliable and efficient amortized model-based evaluation.arXiv preprint arXiv:2503.13335,
-
[26]
Wu, M., Davis, R. L., Domingue, B. W., Piech, C., and Goodman, N. Variational item response the- ory: Fast, accurate, and expressive.arXiv preprint arXiv:2002.00276,
-
[27]
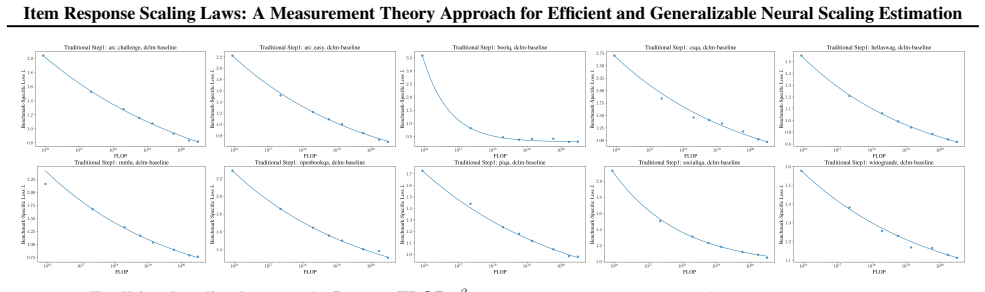
(2024), we fit step 1 only on final checkpoints for each model size, as the learning rate schedule prevents accurate FLOP estimation on intermediate checkpoints
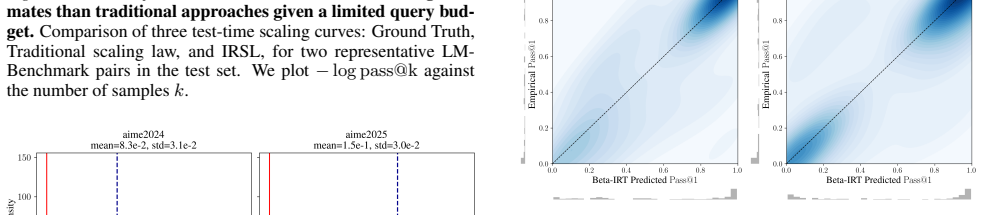
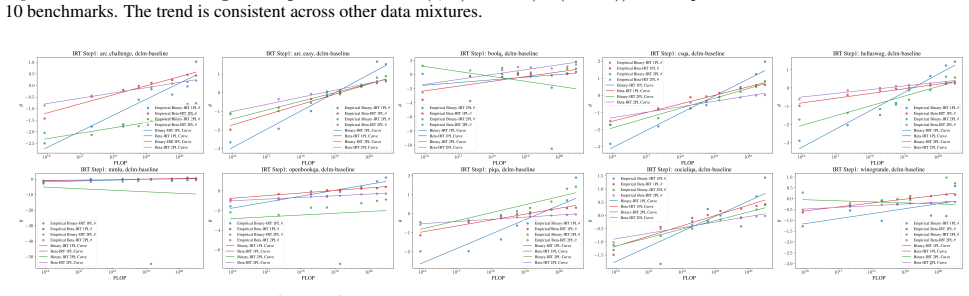
Following Bhagia et al. (2024), we fit step 1 only on final checkpoints for each model size, as the learning rate schedule prevents accurate FLOP estimation on intermediate checkpoints. Figure 16 shows the correlation between Beta-IRT 1PL predictedp Correct Choice and empiricalp Correct Choice. Figure 17 and 18 show the Beta-IRT curve on a randomly sample...
2024
-
[28]
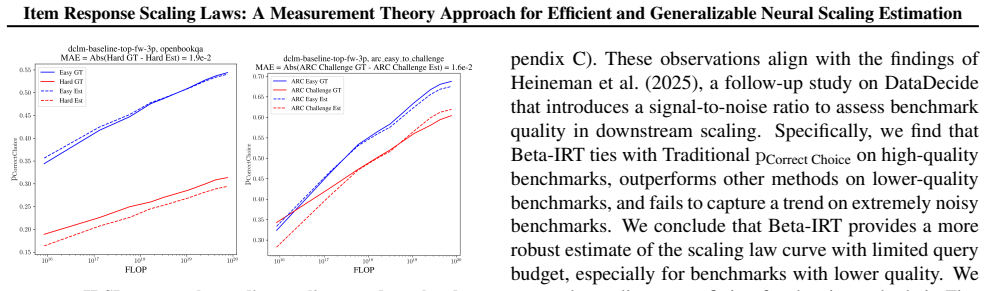
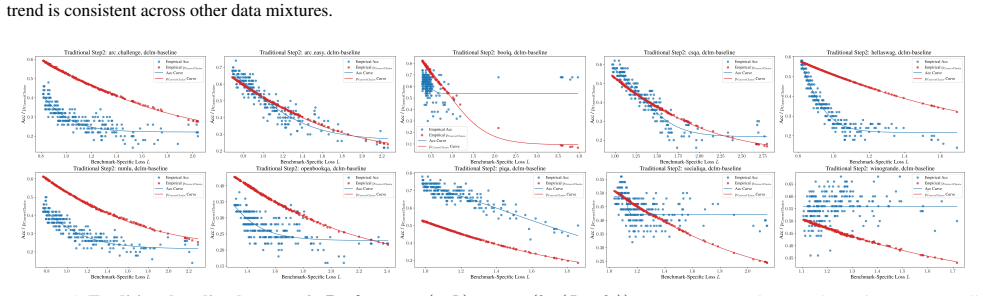
We therefore view this not as a limitation of IRSL, but as a property of the benchmarks themselves
exhibits a pronounced peak. We therefore view this not as a limitation of IRSL, but as a property of the benchmarks themselves. IRSL is most effective when evaluation items are sufficiently diverse and informative, and we believe this finding itself contributes toward more 15 Item Response Scaling Laws: A Measurement Theory Approach for Efficient and Gene...
2024
-
[29]
This aligns with findings from Kipnis et al
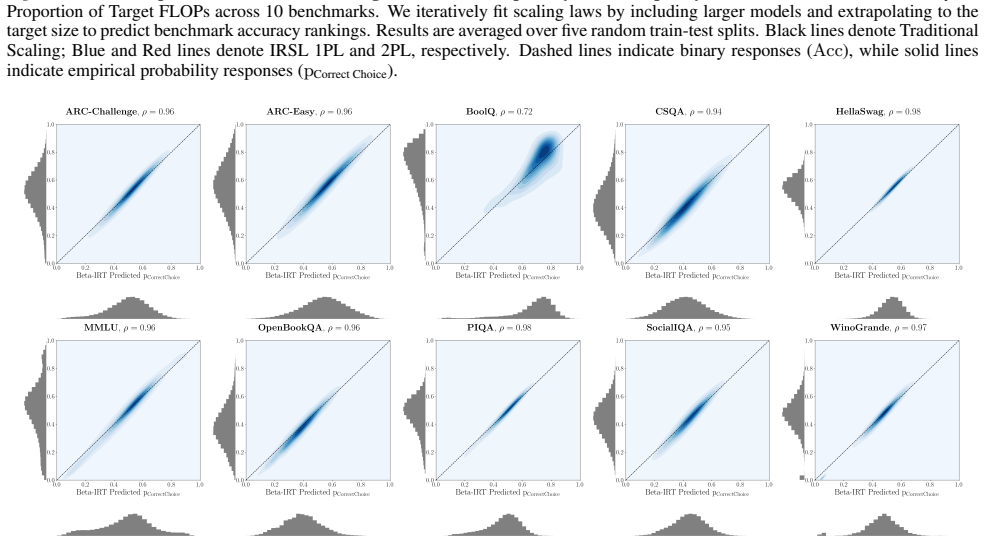
The full correlation heatmap shows that most of the 10 pre-training benchmarks exhibit high pairwiseθcorrelations, with BoolQ as the notable exception (BoolQ is known to have a low signal-to-noise ratio as a two-choice benchmark (Heineman et al., 2025)). This aligns with findings from Kipnis et al. (2025) that a single common factor underlies most benchma...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.