TRACER: Token ReAssignment for Concept ERasure in Generative Recommendation
Pith reviewed 2026-06-27 21:02 UTC · model grok-4.3
The pith
TRACER erases target concepts in generative recommenders by reassigning shared semantic IDs to alternative tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
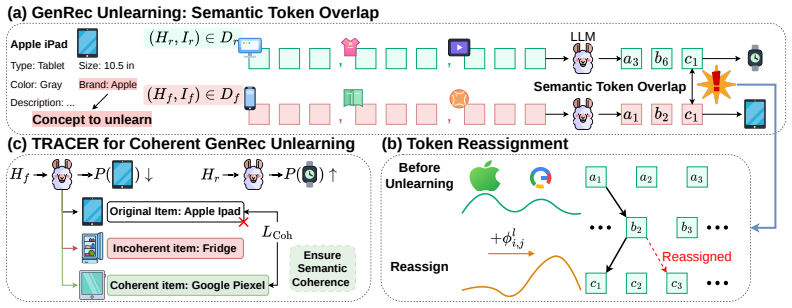
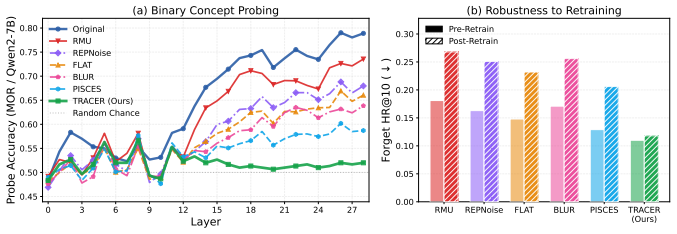
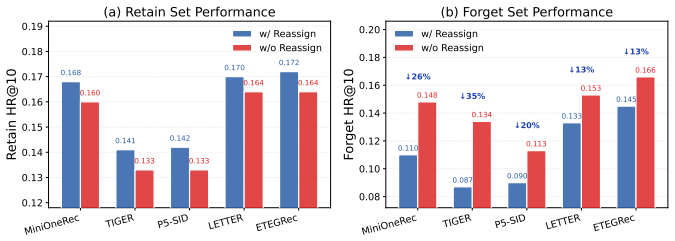
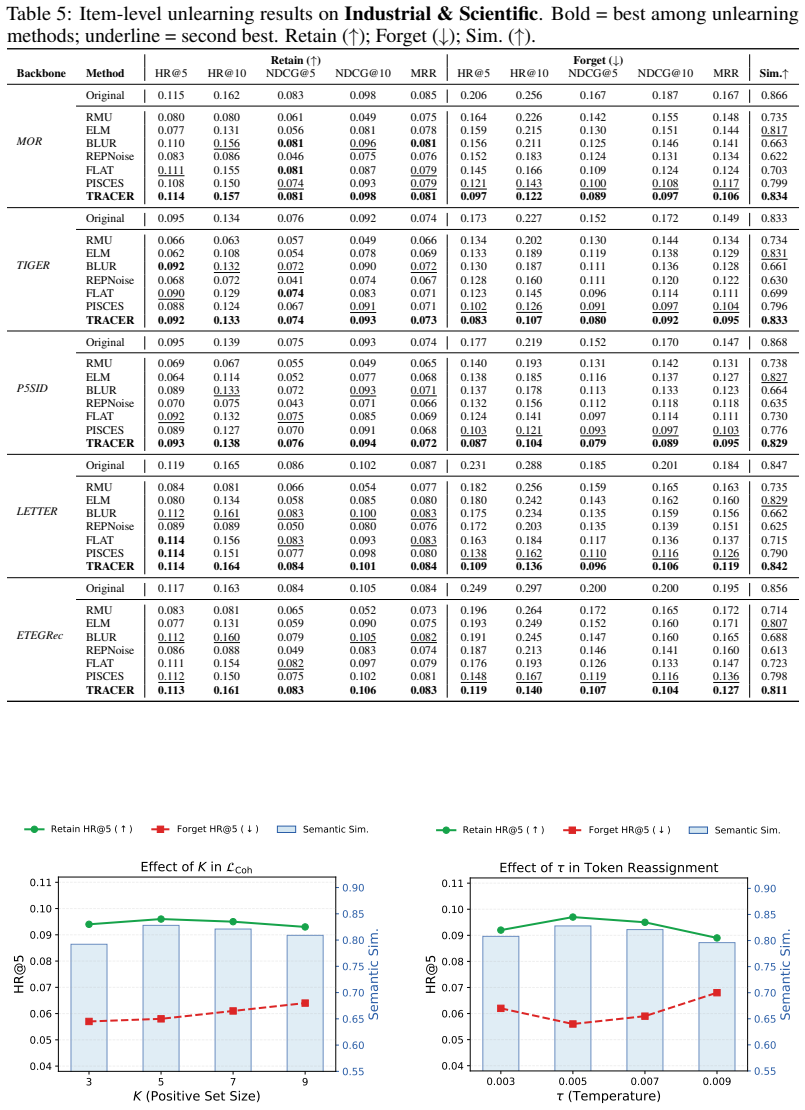
TRACER is an end-to-end unlearning framework that reassigns items associated with a target concept to alternative semantic ID tokens chosen to reduce overlap with retain items, then applies a coherence regularizer during fine-tuning to keep semantic consistency among the retained items; this produces models that no longer generate the forget-set concepts at rates seen before unlearning while recommendation metrics on retain sets remain higher than those achieved by direct suppression baselines.
What carries the argument
Token reassignment of semantic IDs, which moves concept-related items to new identifiers that minimize shared tokens between forget and retain sets.
If this is right
- Target concepts can be removed from the model's generative distribution without direct suppression of shared tokens.
- Recommendation utility on items outside the target concept stays closer to the original model than with existing unlearning methods.
- A coherence regularizer keeps semantic relationships among retained items stable during the reassignment process.
- The framework operates end-to-end on the autoregressive generation objective used in semantic-ID recommenders.
Where Pith is reading between the lines
- The same reassignment idea might reduce interference when multiple concepts must be forgotten sequentially.
- If semantic IDs are learned rather than fixed, the choice of which alternative tokens to assign could itself be optimized as part of the unlearning objective.
- Systems that already use discrete semantic IDs for other generative tasks could adopt the same separation technique to isolate sensitive content.
Load-bearing premise
Reassigning shared semantic IDs to alternative tokens separates the forget set from the retain set enough to allow forgetting without creating new conflicts that degrade generation for retained items.
What would settle it
Run the generative model after TRACER training on a held-out test set containing both forget and retain items and measure whether the rate of generating forget-set items remains near the pre-unlearning level or whether NDCG and recall on retain items fall below the levels reported for the strongest baseline.
Figures


read the original abstract
Generative recommendation formulates next-item prediction as autoregressive generation over semantic ID (SID) sequences derived from users' historical interactions, making modern recommender systems structurally similar to large language models (LLMs). As privacy and safety concerns grow, these systems increasingly require concept unlearning to remove sensitive or harmful concepts associated with items. However, existing LLM unlearning methods cannot be directly applied to generative recommendation. Unlike word tokens with explicit semantics, SIDs are abstract identifiers that are often shared by both forget and retain items, leading to severe conflicts between concept removal and recommendation utility preservation. To address this challenge, we propose TRACER, an end-to-end concept unlearning framework based on token reassignment. Rather than directly suppressing shared SIDs, TRACER reassigns concept-related items to alternative tokens that better facilitate forgetting while minimizing side effects on retained items. We further introduce a coherence regularizer to preserve semantic consistency among retain items during unlearning. Experiments on real-world recommendation datasets demonstrate that TRACER effectively removes target concepts while substantially better preserving recommendation utility than existing unlearning baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TRACER, an end-to-end concept unlearning framework for generative recommendation systems that model next-item prediction as autoregressive generation over semantic ID (SID) sequences. It identifies the core problem that SIDs are often shared between forget-set and retain-set items, creating conflicts that prevent direct application of LLM unlearning techniques. TRACER instead reassigns concept-related items to alternative tokens chosen to facilitate forgetting while minimizing side effects, and adds a coherence regularizer to preserve semantic consistency among retain items. The central claim is that this token-reassignment approach removes target concepts while substantially better preserving recommendation utility than existing unlearning baselines, as demonstrated on real-world recommendation datasets.
Significance. If the empirical results hold, the work would be significant for privacy and safety in generative recommenders, a setting that structurally resembles LLMs but cannot use standard unlearning methods because of the abstract, shared nature of SIDs. The targeted reassignment strategy plus coherence regularizer constitutes a concrete, domain-specific solution rather than a generic adaptation, and the paper correctly frames the shared-SID conflict as the load-bearing obstacle. Credit is due for identifying this incompatibility and for grounding the method in the generative-recommendation pipeline.
major comments (2)
- [Abstract] Abstract: the central claim of 'substantially better preserving recommendation utility than existing unlearning baselines' is stated without any quantitative metrics, dataset names, ablation results, or implementation details. Because the soundness of the contribution rests entirely on these unreported experiments, the claim cannot be evaluated from the provided text.
- [Abstract] The weakest assumption identified in the stress-test note—that reassigning shared SIDs to alternative tokens can separate forget and retain sets without introducing new conflicts or degrading the generative process for retained items—is treated as solved by construction in the abstract, but no derivation, algorithm, or preliminary analysis is supplied to show that the reassignment procedure is guaranteed to avoid such conflicts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that it can be strengthened with more concrete details on results and the method. We will revise the abstract in the next version. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of 'substantially better preserving recommendation utility than existing unlearning baselines' is stated without any quantitative metrics, dataset names, ablation results, or implementation details. Because the soundness of the contribution rests entirely on these unreported experiments, the claim cannot be evaluated from the provided text.
Authors: We agree the abstract lacks quantitative support. The full manuscript reports these results in Sections 4 and 5 on real-world datasets (including metrics such as NDCG and HR improvements over baselines, plus ablations). We will revise the abstract to include key quantitative findings, dataset names, and references to the experimental setup so the central claim can be evaluated from the abstract. revision: yes
-
Referee: [Abstract] The weakest assumption identified in the stress-test note—that reassigning shared SIDs to alternative tokens can separate forget and retain sets without introducing new conflicts or degrading the generative process for retained items—is treated as solved by construction in the abstract, but no derivation, algorithm, or preliminary analysis is supplied to show that the reassignment procedure is guaranteed to avoid such conflicts.
Authors: The abstract is a high-level summary. Section 3 details the token reassignment algorithm, including the selection criterion for alternative tokens that minimizes overlap with retain-set items and the coherence regularizer that prevents degradation. Section 5 provides empirical analysis showing no new conflicts are introduced. We will revise the abstract to reference these design elements explicitly rather than implying the issue is solved by construction. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical method (TRACER) for concept unlearning via token reassignment and a coherence regularizer in generative recommendation. The abstract and description contain no equations, fitted parameters called predictions, self-definitional loops, or load-bearing self-citations that reduce any claimed result to its inputs by construction. The central claims rest on experiments on real-world datasets, which constitute external validation rather than internal reduction. This is a standard applied ML contribution without the derivation patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic IDs are abstract identifiers often shared by both forget-set and retain-set items
Reference graph
Works this paper leans on
-
[1]
Lucas Bourtoule, Varun Chandrasekaran, Christopher A Choquette-Choo, Hengrui Jia, Adelin Travers, Baiwu Zhang, David Lie, and Nicolas Papernot. 2021. Machine unlearning. InIEEE Symposium on Security and Privacy (SP)
2021
-
[2]
Pengfei Cao, Chenhao Wang, Zhitao He, Hongbang Yuan, Jiachun Li, Yubo Chen, Kang Liu, Jun Zhao, et al. 2024. Rwku: Benchmarking real-world knowledge unlearning for large language models.Advances in Neural Information Processing Systems37 (2024), 98213–98263
2024
-
[3]
Yinzhi Cao and Junfeng Yang. 2015. Towards making systems forget with machine unlearning. InProceedings of the IEEE Symposium on Security and Privacy
2015
-
[4]
Chong Chen, Fei Sun, Min Zhang, and Bolin Ding. 2022. Recommendation unlearning. In Proceedings of the ACM web conference 2022. 2768–2777
2022
-
[5]
Ziheng Chen, Jiali Cheng, Hadi Amiri, Kaushiki Nag, Lu Lin, Sijia Liu, Gabriele Tolomei, and Xiangguo Sun. 2025. FROG: Fair Removal on Graph. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 415–424
2025
-
[6]
Ziheng Chen, Jiali Cheng, Zezhong Fan, Hadi Amiri, Yunzhi Yao, Xiangguo Sun, and Yang Zhang. 2026. CURE: Circuit-Aware Unlearning for LLM-based Recommendation.arXiv preprint arXiv:2604.04982(2026)
Pith/arXiv arXiv 2026
-
[7]
Ziheng Chen, Jin Huang, Jiali Cheng, Yuchan Guo, Mengjie Wang, Lalitesh Morishetti, Kaushiki Nag, and Hadi Amiri. 2025. FUTURE: Flexible Unlearning for Tree Ensemble. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 4680– 4684
2025
-
[8]
Jiali Cheng and Hadi Amiri. 2024. MU-bench: A multitask multimodal benchmark for machine unlearning.arXiv preprint arXiv:2406.14796(2024)
arXiv 2024
-
[9]
Jiali Cheng and Hadi Amiri. 2025. MultiDelete for Multimodal Machine Unlearning. In Computer Vision – ECCV 2024, Aleš Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol (Eds.). Springer Nature Switzerland, Cham, 165–184
2025
-
[10]
Jiali Cheng and Hadi Amiri. 2025. Speech Unlearning. InInterspeech 2025. 3209–3213. doi:10.21437/Interspeech.2025-2412
-
[11]
Jiali Cheng and Hadi Amiri. 2025. Tool Unlearning for Tool-Augmented LLMs. InForty-second International Conference on Machine Learning
2025
-
[12]
2026.Machine Unlearning Across Tasks and Modalities
Jiali Cheng and Hadi Amiri. 2026.Machine Unlearning Across Tasks and Modalities. Springer Nature Switzerland, Cham, 227–240. doi:10.1007/978-3-032-17282-2_15
-
[13]
Jiali Cheng, Ziheng Chen, Chirag Agarwal, and Hadi Amiri. 2026. Toward Understanding Unlearning Difficulty: A Mechanistic Perspective and Circuit-Guided Difficulty Metric.arXiv preprint arXiv:2601.09624(2026). 10
arXiv 2026
-
[14]
Jiali Cheng, George Dasoulas, Huan He, Chirag Agarwal, and Marinka Zitnik. 2023. GN- NDelete: A General Strategy for Unlearning in Graph Neural Networks. InThe Eleventh International Conference on Learning Representations. https://openreview.net/forum? id=X9yCkmT5Qrl
2023
-
[15]
Jiali Cheng, Rui Pan, and Hadi Amiri. 2026. Investigating Tool-Memory Conflicts in Tool- Augmented LLMs.arXiv preprint arXiv:2601.09760(2026)
arXiv 2026
-
[16]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965(2025)
Pith/arXiv arXiv 2025
-
[17]
Ronen Eldan and Mark Russinovich. 2023. Who’s harry potter? approximate unlearning in llms.arXiv preprint arXiv:2310.02238(2023)
arXiv 2023
-
[18]
Chongyu Fan, Jinghan Jia, Yihua Zhang, Anil Ramakrishna, Mingyi Hong, and Sijia Liu
-
[19]
Towards llm unlearning resilient to relearning attacks: A sharpness-aware minimization perspective and beyond.arXiv preprint arXiv:2502.05374(2025)
arXiv 2025
-
[20]
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. 2024. SalUn: Empowering Machine Unlearning via Gradient-based Weight Saliency in Both Image Classifi- cation and Generation. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=gn0mIhQGNM
2024
-
[21]
Rohit Gandikota, Sheridan Feucht, Samuel Marks, and David Bau. 2024. Erasing conceptual knowledge from language models.arXiv preprint arXiv:2410.02760(2024)
arXiv 2024
-
[22]
Rohit Gandikota, Joanna Materzy´nska, Jaden Fiotto-Kaufman, and David Bau. 2023. Erasing Concepts from Diffusion Models. InProceedings of the 2023 IEEE International Conference on Computer Vision
2023
-
[23]
Aditya Golatkar, Alessandro Achille, and Stefano Soatto. 2020. Eternal sunshine of the spotless net: Selective forgetting in deep networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 9304–9312
2020
-
[24]
Chuan Guo, Tom Goldstein, Awni Hannun, and Laurens Van Der Maaten. 2019. Certified data removal from machine learning models.arXiv preprint arXiv:1911.03030(2019)
arXiv 2019
-
[25]
Gupta, Vittorio Orlandi, Chia-Rui Chang, Tianyu Wang, Marco Morucci, Pritam Dey, Thomas J
Neha R. Gupta, Vittorio Orlandi, Chia-Rui Chang, Tianyu Wang, Marco Morucci, Pritam Dey, Thomas J. Howell, Xian Sun, Angikar Ghosal, Sudeepa Roy, Cynthia Rudin, and Alexander V olfovsky. 2025. dame-flame: A Python Package Providing Fast Interpretable Matching for Causal Inference.Journal of Statistical Software113, 2 (2025), 1–26. doi: 10.18637/jss. v113.i02
-
[26]
Yoav Gur-Arieh, Clara Haya Suslik, Yihuai Hong, Fazl Barez, and Mor Geva. 2025. Precise in-parameter concept erasure in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 18997–19017
2025
-
[27]
Ruidong Han, Bin Yin, Shangyu Chen, He Jiang, Fei Jiang, Xiang Li, Chi Ma, Mincong Huang, Xiaoguang Li, Chunzhen Jing, et al. 2025. Mtgr: Industrial-scale generative recommendation framework in meituan. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. 5731–5738
2025
-
[28]
Joel Jang, Dongkeun Yoon, Sohee Yang, Sungmin Cha, Moontae Lee, Lajanugen Logeswaran, and Minjoon Seo. 2023. Knowledge unlearning for mitigating privacy risks in language models. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 14389–14408
2023
-
[29]
Jinghan Jia, Yihua Zhang, Yimeng Zhang, Jiancheng Liu, Bharat Runwal, James Diffender- fer, Bhavya Kailkhura, and Sijia Liu. 2024. SOUL: Unlocking the Power of Second-Order Optimization for LLM Unlearning.arXiv preprint arXiv:2404.18239(2024). 11
arXiv 2024
-
[30]
Xiaoyu Kong, Leheng Sheng, Junfei Tan, Yuxin Chen, Jiancan Wu, An Zhang, Xiang Wang, and Xiangnan He. 2025. Minionerec: An open-source framework for scaling generative recommendation.arXiv preprint arXiv:2510.24431(2025)
arXiv 2025
-
[31]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregres- sive image generation using residual quantization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition. 11523–11532
2022
-
[32]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D Li, Ann-Kathrin Dombrowski, Shashwat Goel, Long Phan, et al. 2024. The wmdp benchmark: Measuring and reducing malicious use with unlearning.arXiv preprint arXiv:2403.03218 (2024)
Pith/arXiv arXiv 2024
-
[33]
Luyun Lin, Lixing Lin, Zhen Zhang, Moxuan Zheng, and Yiqing Wang. 2026. A V olume-Price- Adjusted MACD Trading Strategy with Sensitivity Calibration for US Equity Indices.arXiv preprint arXiv:2604.26063(2026)
Pith/arXiv arXiv 2026
-
[34]
Luyun Lin and Yiqing Wang. 2025. Shap stability in credit risk management: A case study in credit card default model.Risks13, 12 (2025), 238
2025
-
[35]
Lixing Lin, Juli You, Yue Li, Luyun Lin, Yiqing Wang, Zhen Zhang, and Moxuan Zheng
-
[36]
Reflect-Guard: Enhancing LLM Safeguards against Adversarial Prompts via Logical Self-Reflection.arXiv preprint arXiv:2605.24834(2026)
Pith/arXiv arXiv 2026
-
[37]
Enze Liu, Bowen Zheng, Cheng Ling, Lantao Hu, Han Li, and Wayne Xin Zhao. 2025. Gen- erative recommender with end-to-end learnable item tokenization. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 729–739
2025
-
[38]
Sijia Liu, Yuanshun Yao, Jinghan Jia, Stephen Casper, Nathalie Baracaldo, Peter Hase, Yuguang Yao, Chris Yuhao Liu, Xiaojun Xu, Hang Li, et al. 2024. Rethinking machine unlearning for large language models.arXiv preprint arXiv:2402.08787(2024)
arXiv 2024
-
[39]
Yue Liu, Zhiyuan Cheng, and Longying Lai. 2026. Improving the Completeness and Compara- bility of Segment Disclosures: A Large Language Model Approach. arXiv:2605.23924 [cs.CL] https://arxiv.org/abs/2605.23924
Pith/arXiv arXiv 2026
-
[40]
Zhanyu Liu, Shiyao Wang, Xingmei Wang, Rongzhou Zhang, Jiaxin Deng, Honghui Bao, Jinghao Zhang, Wuchao Li, Pengfei Zheng, Xiangyu Wu, et al. 2025. Onerec-think: In-text reasoning for generative recommendation.arXiv preprint arXiv:2510.11639(2025)
arXiv 2025
-
[41]
Ana Lucic, Harrie Oosterhuis, Hinda Haned, and Maarten De Rijke. 2022. FOCUS: Flexi- ble optimizable counterfactual explanations for tree ensembles. InProceedings of the AAAI conference on artificial intelligence, V ol. 36. 5313–5322
2022
-
[42]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research21, 140 (2020), 1–67
2020
-
[43]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, et al . 2023. Recommender systems with generative retrieval.Advances in Neural Information Processing Systems36 (2023), 10299–10315
2023
-
[44]
Hadi Reisizadeh, Jinghan Jia, Zhiqi Bu, Bhanukiran Vinzamuri, Anil Ramakrishna, Kai-Wei Chang, V olkan Cevher, Sijia Liu, and Mingyi Hong. 2026. Blur: A bi-level optimization approach for llm unlearning. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers). 7043–7058
2026
-
[45]
Domenic Rosati, Jan Wehner, Kai Williams, Łukasz Bartoszcze, David Atanasov, Robie Gon- zales, Subhabrata Majumdar, Carsten Maple, Hassan Sajjad, and Frank Rudzicz. 2024. Rep- resentation noising: A defence mechanism against harmful finetuning.Advances in Neural Information Processing Systems37 (2024), 12636–12676. 12
2024
-
[46]
Smith, and Chiyuan Zhang
Weijia Shi, Jaechan Lee, Yangsibo Huang, Sadhika Malladi, Jieyu Zhao, Ari Holtzman, Daogao Liu, Luke Zettlemoyer, Noah A. Smith, and Chiyuan Zhang. 2025. MUSE: Machine Unlearning Six-Way Evaluation for Language Models. InThe Thirteenth International Conference on Learning Representations.https://openreview.net/forum?id=TArmA033BU
2025
-
[47]
Anvith Thudi, Gabriel Deza, Varun Chandrasekaran, and Nicolas Papernot. 2022. Unrolling sgd: Understanding factors influencing machine unlearning. In2022 IEEE 7th European Symposium on Security and Privacy (EuroS&P). IEEE, 303–319
2022
-
[48]
Wenjie Wang, Honghui Bao, Xinyu Lin, Jizhi Zhang, Yongqi Li, Fuli Feng, See-Kiong Ng, and Tat-Seng Chua. 2024. Learnable item tokenization for generative recommendation. InProceed- ings of the 33rd ACM International Conference on Information and Knowledge Management. 2400–2409
2024
-
[49]
Yaxuan Wang, Jiaheng Wei, Chris Yuhao Liu, Jinlong Pang, Quan Liu, Ankit Shah, Yujia Bao, Yang Liu, and Wei Wei. 2024. Llm unlearning via loss adjustment with only forget data. InThe Thirteenth International Conference on Learning Representations
2024
-
[50]
Yaxuan Wang, Jiaheng Wei, Chris Yuhao Liu, Jinlong Pang, Quan Liu, Ankit Parag Shah, Yujia Bao, Yang Liu, and Wei Wei. [n. d.]. Llm unlearning via loss adjustment with only forget data, 2024.URL https://arxiv. org/abs/2410.11143([n. d.])
arXiv 2024
-
[51]
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu
-
[52]
Knowledge conflicts for llms: A survey.arXiv preprint arXiv:2403.08319(2024)
arXiv 2024
-
[53]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[54]
Shuai Yuan, Xian Sun, Hannah Kim, Shuzhi Yu, and Carlo Tomasi. 2022. Optical Flow Training under Limited Label Budget via Active Learning. InEuropean Conference on Computer Vision (ECCV). Springer, 410–427
2022
-
[55]
Zhang, Gaoyuan Du, Qianyi Sun, Shiqi Wang, Jiaxuan Li, and Xian Sun
Johnny R. Zhang, Gaoyuan Du, Qianyi Sun, Shiqi Wang, Jiaxuan Li, and Xian Sun. 2026. Carbon-Aware Compute–Power Scheduling for AI Data Centers with Microgrid Prosumer Operations. arXiv:2605.03751 [cs.CE]https://arxiv.org/abs/2605.03751
Pith/arXiv arXiv 2026
-
[56]
Yunqi Zhang and Shaileshh Bojja Venkatakrishnan. 2023. Kadabra: Adapting kademlia for the decentralized web. InInternational Conference on Financial Cryptography and Data Security. Springer, 327–345
2023
-
[57]
Yunqi Zhang and Shaileshh Bojja Venkatakrishnan. 2025. Honeybee: Byzantine Tolerant Decentralized Peer Sampling with Verifiable Random Walks. InProceedings of the Twenty-sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing. 321–330
2025
-
[58]
Yunqi Zhang and Shaileshh Bojja Venkatakrishnan. 2023. Rethinking incentive in payment channel networks. In2023 IEEE 43rd International Conference on Distributed Computing Systems Workshops (ICDCSW). IEEE, 61–66
2023
-
[59]
Guorui Zhou, Jiaxin Deng, Jinghao Zhang, Kuo Cai, Lejian Ren, Qiang Luo, Qianqian Wang, Qigen Hu, Rui Huang, Shiyao Wang, et al. 2025. OneRec Technical Report.arXiv preprint arXiv:2506.13695(2025)
arXiv 2025
-
[60]
Chunzheng Zhu, Jianxin Lin, Guanghua Tan, Ningbo Zhu, Kenli Li, Chunlian Wang, and Shengli Li. 2024. Advancing Ultrasound Medical Continuous Learning with Task-Specific Generalization and Adaptability. In2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 3019–3025
2024
-
[61]
Chunzheng Zhu, Yangfang Lin, Shen Chen, Yijun Wang, and Jianxin Lin. 2026. Medeyes: Learning dynamic visual focus for medical progressive diagnosis. InProceedings of the AAAI Conference on Artificial Intelligence, V ol. 40. 13916–13924. 13
2026
-
[62]
Chunzheng Zhu, Yangfang Lin, Jialin Shao, Jianxin Lin, and Yijun Wang. 2025. Pathology- Aware Prototype Evolution via LLM-Driven Semantic Disambiguation for Multicenter Diabetic Retinopathy Diagnosis. InProceedings of the 33rd ACM International Conference on Multime- dia. 9196–9205. 14 A Broader Impact This work addresses the growing need formachine unlea...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.