VoLo: A Physical Orchestrator for Open-Vocabulary Long-Horizon Manipulation
Pith reviewed 2026-06-27 21:38 UTC · model grok-4.3
The pith
A VLM orchestrates robot capabilities as interruptible tools to manage open-vocabulary long-horizon manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
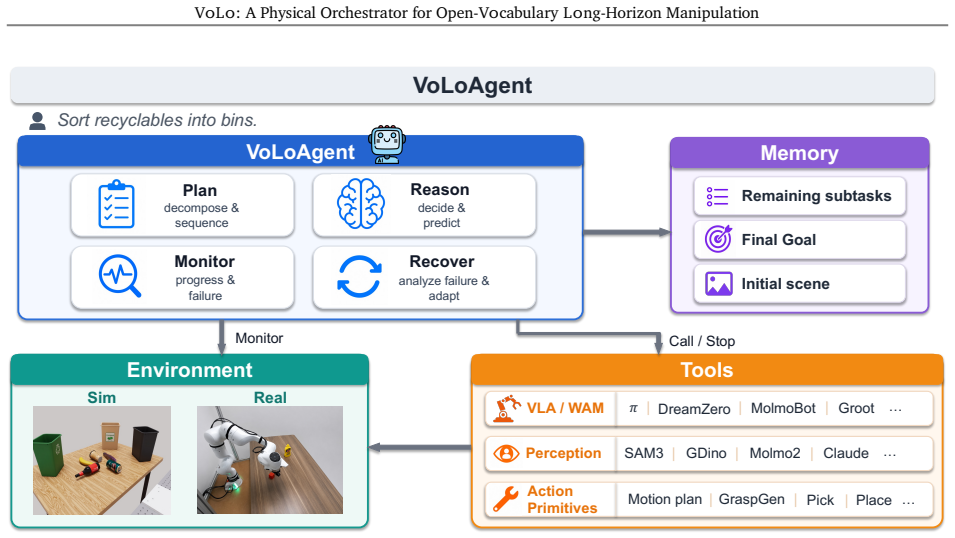
VoLoAgent uses a VLM to plan, monitor, and recover by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. This addresses open-vocabulary long-horizon manipulation in a physical world where the timing of decisions, actions, and tool calls matters because the environment does not pause for reasoning.
What carries the argument
Physical Orchestration: the closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools, enabling adaptive planning and recovery when timing is critical.
If this is right
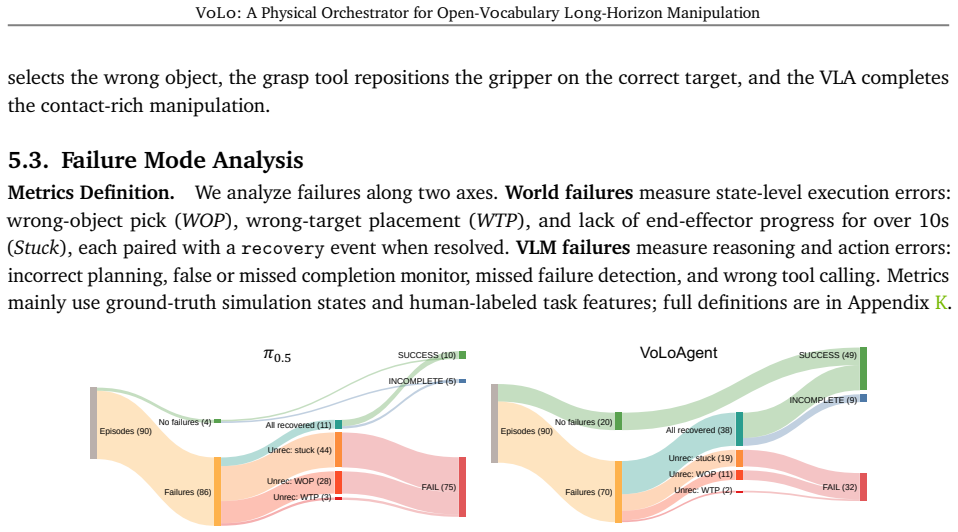
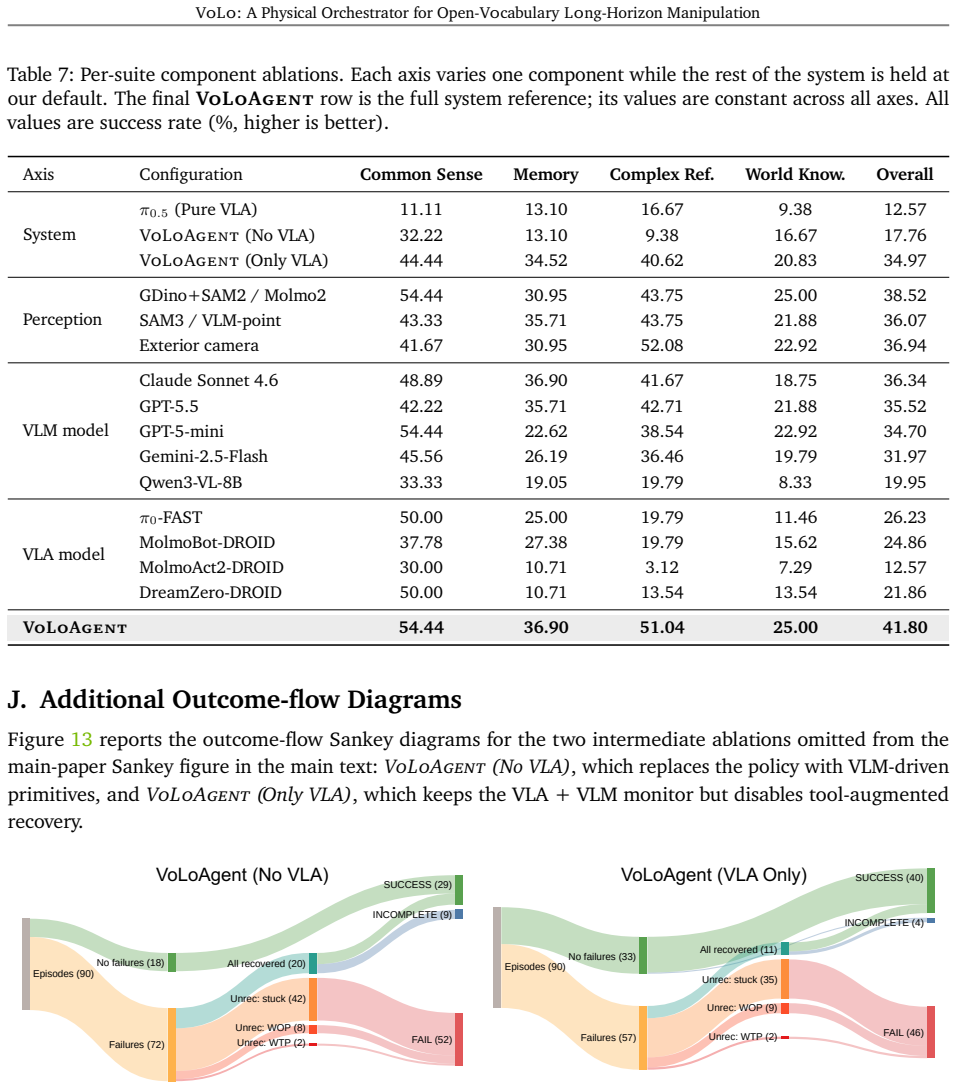
- VoLoAgent substantially outperforms single VLA/VLM or tool-based systems on long-horizon open-vocabulary tasks.
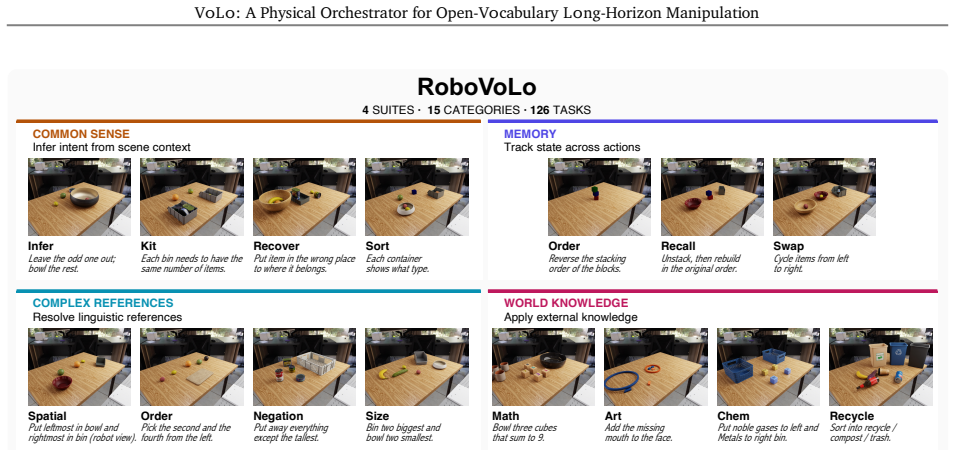
- The RoboVoLo benchmark supplies both task-level success rates and failure-mode diagnostics across common sense, memory/state tracking, complex references, and world knowledge.
- Real-robot experiments confirm the method works outside simulation for physical manipulation.
- The interruptible-tool design supports recovery from failures during multi-object, flexible-instruction sequences.
Where Pith is reading between the lines
- The same orchestration pattern could be tested on tasks that combine manipulation with navigation where timing between subtasks is equally strict.
- Adding more vision primitives as tools might reduce specific failure modes the benchmark already flags.
- The approach leaves open whether the VLM needs explicit training on timing constraints or can learn them from the tool interface alone.
Load-bearing premise
A VLM can reliably plan, monitor, and recover by treating a VLA as an interruptible tool it steers mid-rollout alongside other models in a physical setting where timing of actions matters.
What would settle it
A set of RoboVoLo tasks or real-robot trials in which VoLoAgent shows no improvement over single VLA or VLM baselines on metrics for memory tracking or complex reference resolution.
Figures









read the original abstract
Open-vocabulary long-horizon manipulation requires robots to reason over flexible instructions and complex multi-object scenes while adaptively planning, executing, monitoring, and recovering from failures. We address these demands with a closed agent loop in which a VLM orchestrates heterogeneous robot capabilities as interruptible tools. Unlike in virtual AI agents, the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning. We refer to this setting as Physical Orchestration, and propose VoLoAgent, a VLM that plans, monitors, and recovers by treating a VLA/WAM as an interruptible tool it steers mid-rollout alongside vision models and action primitives. To evaluate these long-horizon capabilities, we introduce RoboVoLo, a high-fidelity benchmark for open-vocabulary long-horizon manipulation across common sense, memory/state tracking, complex references, and world knowledge, with both task-level success and failure-mode diagnostics. Experiments show VoLoAgent substantially outperforms single VLA/VLM or tool-based systems, with validation on real-robot experiments. Project page: https://chicychen.github.io/VoLo/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VoLoAgent, a closed-loop VLM agent for open-vocabulary long-horizon manipulation. It treats a VLA/WAM as an interruptible tool that the VLM steers mid-rollout, together with vision models and action primitives, under the framing of 'Physical Orchestration' where timing of decisions and tool calls matters because the physical world does not pause. The paper also presents the RoboVoLo benchmark covering common-sense reasoning, memory/state tracking, complex references, and world knowledge, with both task success metrics and failure-mode diagnostics. Experiments are reported to show substantial outperformance versus single VLA/VLM or tool-based baselines, with real-robot validation.
Significance. If the empirical claims are supported by the full methods and diagnostics, the work would contribute a concrete integration strategy for high-level VLM reasoning with low-level robot execution in long-horizon settings. The benchmark's inclusion of failure-mode analysis is a constructive addition for the robotics community. The explicit attention to physical timing distinguishes the setting from virtual agents and is a relevant direction.
major comments (1)
- [Abstract / Approach] Abstract and approach description: the manuscript states that 'the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning' and that the VLM steers the VLA 'mid-rollout', yet no concrete synchronization mechanism (decision frequency, latency bounds, state buffering, or safety interlocks) is supplied. This assumption is load-bearing for both the Physical Orchestration claim and the real-robot outperformance results.
minor comments (1)
- [Abstract] The project page is referenced but no information is given on benchmark release, code, or exact task definitions needed for independent verification.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and positive evaluation of the work's potential. We respond to the single major comment below.
read point-by-point responses
-
Referee: [Abstract / Approach] Abstract and approach description: the manuscript states that 'the timing of decisions, actions and tool calls is important in a physical world that does not pause for reasoning' and that the VLM steers the VLA 'mid-rollout', yet no concrete synchronization mechanism (decision frequency, latency bounds, state buffering, or safety interlocks) is supplied. This assumption is load-bearing for both the Physical Orchestration claim and the real-robot outperformance results.
Authors: We agree that explicit details on synchronization are necessary to fully support the Physical Orchestration framing and the real-robot claims. The manuscript presents the high-level concept and empirical outcomes but does not specify decision frequency, latency bounds, state buffering, or safety interlocks. In revision we will add a new subsection (likely under Implementation or Experimental Setup) that documents the closed-loop timing parameters used, including VLM invocation rate, buffering of visual state during VLA rollouts, observed latencies on the real platform, and any interlocks applied to prevent unsafe interruptions. These additions will directly address the load-bearing nature of the timing assumption. revision: yes
Circularity Check
Empirical system comparison with no derivations or self-referential reductions
full rationale
The manuscript describes an empirical agent architecture (VoLoAgent) for physical orchestration of VLMs, VLAs, and primitives, evaluated via the RoboVoLo benchmark and real-robot trials. No equations, first-principles derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims reduce to experimental outperformance against baselines rather than any closed mathematical chain, satisfying the default expectation of non-circularity for empirical systems.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ClaudeOpus4.7systemcard
Anthropic. ClaudeOpus4.7systemcard. https://www.anthropic.com/system-cards, 2026. Anthropic technical report. Also covers Claude Opus 4.6 and Claude Sonnet 4.6. 7
2026
-
[2]
RT-2: Vision-language-action models transfer web knowledge to robotic control
Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov...
2023
-
[3]
Brown, T
Lawrence D. Brown, T. Tony Cai, and Anirban DasGupta. Interval estimation for a binomial proportion. Statistical Science, 16(2):101–133, 2001. 30
2001
-
[4]
Enabling failure recovery for on-the-move mobile manipulation
Ben Burgess-Limerick, Chris Lehnert, Jürgen Leitner, and Peter Corke. Enabling failure recovery for on-the-move mobile manipulation. InIEEE ICRA Workshop on Robotic Perception and Mapping: Frontier Vision and Learning Techniques, 2023. ICRA 2023 Workshop on Robot Failures; arXiv:2305.08351. 4
arXiv 2023
-
[5]
SAM 3: Segment anything with concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
Pith/arXiv arXiv 2025
-
[6]
Chi-Lam Cheang, Guangzeng Chen, Ya Jing, Tao Kong, Hang Li, Yifeng Li, Yuxiao Liu, Hongtao Wu, Jiafeng Xu, Yichu Yang, Hanbo Zhang, and Minzhao Zhu. GR-2: A generative video-language-action model with web-scale knowledge for robot manipulation.arXiv preprint arXiv:2410.06158, 2024. 2, 3
Pith/arXiv arXiv 2024
-
[7]
Lingling Chen, Zongyao Lyu, and William J. Beksi. Reconvla: An uncertainty-guided and failure-aware vision-language-action framework for robotic control.arXiv preprint arXiv:2604.16677, 2026. 3
Pith/arXiv arXiv 2026
-
[8]
SpaceTools: Tool-augmented spatial reasoning via double interactive rl.CVPR, 2026
Siyi Chen, Mikaela Angelina Uy, Chan Hee Song, Faisal Ladhak, Adithyavairavan Murali, Qing Qu, Stan Birchfield, Valts Blukis, and Jonathan Tremblay. SpaceTools: Tool-augmented spatial reasoning via double interactive rl.CVPR, 2026. 2, 19
2026
-
[9]
Tianxing Chen, Yuran Wang, Mingleyang Li, Yan Qin, Hao Shi, Zixuan Li, Yifan Hu, Yingsheng Zhang, Kaixuan Wang, Yue Chen, Hongcheng Wang, Renjing Xu, Ruihai Wu, Yao Mu, Yaodong Yang, Hao Dong, and Ping Luo. RMBench: Memory-dependent robotic manipulation benchmark with insights into policy design.arXiv preprint arXiv:2603.01229, 2026. 3 10 VoLo: A Physical...
arXiv 2026
-
[10]
Christopher Clark, Jieyu Zhang, Zixian Ma, Jae Sung Park, Mohammadreza Salehi, Rohun Tripathi, Sangho Lee, Zhongzheng Ren, Chris Dongjoo Kim, Yinuo Yang, Vincent Shao, Yue Yang, Weikai Huang, Ziqi Gao, Taira Anderson, Jianrui Zhang, Jitesh Jain, George Stoica, Winson Han, Ali Farhadi, and Ranjay Krishna. Molmo2: Open weights and data for vision-language m...
Pith/arXiv arXiv 2026
-
[11]
Yinpei Dai, Jayjun Lee, Nima Fazeli, and Joyce Chai. RACER: Rich language-guided failure recovery policies for imitation learning.arXiv preprint arXiv:2409.14674, 2024. 3
arXiv 2024
-
[12]
Smith, Hannaneh Hajishirzi, Ross Girshick, Ali Farhadi, and Aniruddha Kembhavi
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, Andrew Head, Rose Hendrix, Favyen Bastani, Eli VanderBilt, Nathan Lambert, Yvon...
Pith/arXiv arXiv 2024
-
[13]
Abhay Deshpande, Maya Guru, Rose Hendrix, Snehal Jauhri, Ainaz Eftekhar, Rohun Tripathi, Max Argus, Jordi Salvador, Haoquan Fang, Matthew Wallingford, Wilbert Pumacay, Yejin Kim, Quinn Pfeifer, Ying- Chun Lee, Piper Wolters, Omar Rayyan, Mingtong Zhang, Jiafei Duan, Karen Farley, Winson Han, Eli VanderBilt, Dieter Fox, Ali Farhadi, Georgia Chalvatzaki, Dh...
arXiv 2026
-
[14]
Manipulate-anything: Automating real-world robots using vision-language models
Jiafei Duan, Wentao Yuan, Wilbert Pumacay, Yi Ru Wang, Kiana Ehsani, Dieter Fox, and Ranjay Krishna. Manipulate-anything: Automating real-world robots using vision-language models. InCoRL, 2024. 3
2024
-
[15]
AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation
Jiafei Duan, Wilbert Pumacay, Nishanth Kumar, Yi Ru Wang, Shulin Tian, Wentao Yuan, Ranjay Krishna, Dieter Fox, Ajay Mandlekar, and Yijie Guo. AHA: A vision-language-model for detecting and reasoning over failures in robotic manipulation. InICLR, 2025. 3
2025
-
[16]
Edgington and Patrick Onghena.Randomization Tests
Eugene S. Edgington and Patrick Onghena.Randomization Tests. Chapman and Hall/CRC, Boca Raton, FL, 4 edition, 2007. 7, 27
2007
-
[17]
MolmoAct2: Action reasoning models for real-world deployment.arXiv preprint arXiv:2605.02881, 2026
Haoquan Fang, Jiafei Duan, Donovan Clay, Sam Wang, Shuo Liu, Weikai Huang, Xiang Fan, Wei-Chuan Tsai, Shirui Chen, Yi Ru Wang, Shanli Xing, Jaemin Cho, Jae Sung Park, Ainaz Eftekhar, Peter Sushko, Karen Farley, Angad Wadhwa, Cole Harrison, Winson Han, Ying-Chun Lee, Eli VanderBilt, Rose Hendrix, Suveen Ellawela, Lucas Ngoo, Joyce Chai, Zhongzheng Ren, Ali...
Pith/arXiv arXiv 2026
-
[18]
Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation
Yunhai Feng, Jiaming Han, Zhuoran Yang, Xiangyu Yue, Sergey Levine, and Jianlan Luo. Reflective planning: Vision-language models for multi-stage long-horizon robotic manipulation. InConference on Robot Learning (CoRL), 2025. arXiv:2502.16707. 3
arXiv 2025
-
[19]
Barry, Kris Kitani, and George Konidaris
Jiahui Fu, Junyu Nan, Lingfeng Sun, Hongyu Li, Jianing Qian, Jennifer L. Barry, Kris Kitani, and George Konidaris. NovaPlan: Zero-shot long-horizon manipulation via closed-loop video language planning. arXiv preprint arXiv:2602.20119, 2026. 3
arXiv 2026
-
[20]
Max Fu, Justin Yu, Karim El-Refai, Ethan Kou, Haoru Xue, Huang Huang, Wenli Xiao, Guanzhi Wang, Fei-Fei Li, Guanya Shi, et al. CaP-X: A framework for benchmarking and improving coding agents for robot manipulation.arXiv preprint arXiv:2603.22435, 2026. 2, 3, 7 11 VoLo: A Physical Orchestrator for Open-VocabularyLong-Horizon Manipulation
arXiv 2026
-
[21]
Shenyuan Gao, William Liang, Kaiyuan Zheng, Ayaan Malik, Seonghyeon Ye, Sihyun Yu, Wei-Cheng Tseng, Yuzhu Dong, Kaichun Mo, Chen-Hsuan Lin, Qianli Ma, Seungjun Nah, Loic Magne, Jiannan Xiang, Yuqi Xie, Ruijie Zheng, Dantong Niu, You Liang Tan, K. R. Zentner, George Kurian, Suneel Indupuru, Pooya Jannaty, Jinwei Gu, Jun Zhang, Jitendra Malik, Pieter Abbeel...
Pith/arXiv arXiv 2026
-
[22]
Qiao Gu, Yuanliang Ju, Shengxiang Sun, Igor Gilitschenski, Haruki Nishimura, Masha Itkina, and Florian Shkurti. SAFE: Multitask failure detection for vision-language-action models.arXiv preprint arXiv:2506.09937, 2025. 3
arXiv 2025
-
[23]
RoboCerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation
Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, and Si Liu. RoboCerebra: A large-scale benchmark for long-horizon robotic manipulation evaluation. InNeurIPS, 2025. 3, 31, 32
2025
-
[24]
LIBERO+: Robust language-image foundation models for robotic manipulation
Senthooran Huang and LIBERO-Plus contributors. LIBERO+: Robust language-image foundation models for robotic manipulation. arXiv preprint, 2025. Language-rephrasing eval suite for LIBERO. 31
2025
-
[25]
Inner monologue: Embodied reasoning through planning with language models
Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, and Brian Ichter. Inner monologue: Embodied reasoning through planning with language models. InCoRL, 2022. 3
2022
-
[26]
arXiv preprint arXiv:2511.14759, 2025
Physical Intelligence, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Kevin Black, Ken Conley, Grace Connors, James Darpinian, Karan Dhabalia, Jared DiCarlo, et al.𝜋* 0.6: a VLA that learns from experience. arXiv preprint arXiv:2511.14759, 2025. 2, 3
Pith/arXiv arXiv 2025
-
[27]
2, 3, 5, 7, 25
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al.𝜋0.5: a vision-language-action model with open-world generalization.arXiv preprint, 2025. 2, 3, 5, 7, 25
2025
-
[28]
Physical Intelligence, Bo Ai, Ali Amin, Raichelle Aniceto, Ashwin Balakrishna, Greg Balke, Kevin Black, George Bokinsky, Shihao Cao, Thomas Charbonnier, et al.𝜋0.7: a steerable generalist robotic foundation model with emergent capabilities.arXiv preprint arXiv:2604.15483, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[29]
Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020. 3
2020
-
[30]
VIMA: General robot manipulation with multimodal prompts
Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, and Linxi Fan. VIMA: General robot manipulation with multimodal prompts. InICML, 2023. 3
2023
-
[31]
DROID: A large-scale in-the-wild robot manipulation dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, et al. DROID: A large-scale in-the-wild robot manipulation dataset. InRobotics: Science and Systems (RSS), 2024. 6, 24, 31, 32
2024
-
[32]
OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. 3
Pith/arXiv arXiv 2024
-
[33]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, and Jinwei Gu. Cosmos Policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026. 2, 3 12 VoLo: A Physical Orchestrator for Open-VocabularyLong-Horizon Manipulation
Pith/arXiv arXiv 2026
-
[34]
MolmoSpaces: A large-scale open ecosystem for robot navigation and manipulation, 2026
Yejin Kim, Wilbert Pumacay, Omar Rayyan, Max Argus, Winson Han, Eli VanderBilt, Jordi Salvador, Abhay Deshpande, Rose Hendrix, Snehal Jauhri, Shuo Liu, Nur Muhammad Mahi Shafiullah, Maya Guru, Arjun Guru, Ainaz Eftekhar, Karen Farley, Donovan Clay, Jiafei Duan, Piper Wolters, Alvaro Herrasti, Ying-Chun Lee, Georgia Chalvatzaki, Yuchen Cui, Ali Farhadi, Di...
arXiv 2026
-
[35]
MolmoAct: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025
Jason Lee, Jiafei Duan, Haoquan Fang, Yuquan Deng, Shuo Liu, Boyang Li, Bohan Fang, Jieyu Zhang, Yi Ru Wang, Sangho Lee, Winson Han, Wilbert Pumacay, Angelica Wu, Rose Hendrix, Karen Farley, Eli VanderBilt, Ali Farhadi, Dieter Fox, and Ranjay Krishna. MolmoAct: Action reasoning models that can reason in space.arXiv preprint arXiv:2508.07917, 2025. 3
Pith/arXiv arXiv 2025
-
[36]
Towards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models
Zixing Lei, Changxing Liu, Yichen Xiong, Minhao Xiong, Yuanzhuo Ding, Zhipeng Zhang, Weixin Li, and Siheng Chen. Towards Long-horizon Embodied Agents with Tool-Aligned Vision-Language-Action Models. arXiv preprint arXiv:2605.13119, 2026. 3
Pith/arXiv arXiv 2026
-
[37]
BEHAVIOR-1K: A benchmark for embodied AI with 1,000 everyday activities and realistic simulation
Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, et al. BEHAVIOR-1K: A benchmark for embodied AI with 1,000 everyday activities and realistic simulation. InConference on Robot Learning (CoRL), 2022. 3
2022
-
[38]
Towards efficient and robust manipulation via multi-frame vision-language-action modeling
Hao Li, Shuai Yang, Yilun Chen, Xinyi Chen, Xiaoda Yang, Yang Tian, Hanqing Wang, Tai Wang, Feng Zhao, Dahua Lin, and Jiangmiao Pang. Towards efficient and robust manipulation via multi-frame vision-language-action modeling. InProceedings of the AAAI Conference on Artificial Intelligence, 2026. Oral. arXiv:2506.19816. 3
arXiv 2026
-
[39]
Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[40]
Evaluating real-world robot manipulation policies in simulation
Xuanlin Li, Kyle Hsu, Jiayuan Gu, Karl Pertsch, Oier Mees, Homer Rich Walke, Chuyuan Fu, Ishikaa Lunawat, Isabel Sieh, Sean Kirmani, Sergey Levine, Jiajun Wu, Chelsea Finn, Hao Su, Quan Vuong, and Ted Xiao. Evaluating real-world robot manipulation policies in simulation. InCoRL, 2024. 3
2024
-
[41]
HAMSTER: Hierarchical action models for open-world robot manipulation, 2025
Yi Li, Yuquan Deng, Jesse Zhang, Joel Jang, Marius Memmel, Raymond Yu, Caelan Reed Garrett, Fabio Ramos, Dieter Fox, Anqi Li, Abhishek Gupta, and Ankit Goyal. HAMSTER: Hierarchical action models for open-world robot manipulation, 2025. 2, 3
2025
-
[42]
Code as policies: Language model programs for embodied control
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, and Andy Zeng. Code as policies: Language model programs for embodied control. InICRA, 2023. 2, 3
2023
-
[43]
Zijun Lin, Jiafei Duan, Haoquan Fang, Dieter Fox, Ranjay Krishna, Cheston Tan, and Bihan Wen. FailSafe: Reasoning and recovery from failures in vision-language-action models.arXiv preprint arXiv:2510.01642,
-
[44]
LIBERO: Bench- marking knowledge transfer for lifelong robot learning
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. LIBERO: Bench- marking knowledge transfer for lifelong robot learning. InAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. 2, 3, 31
2023
-
[45]
Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InECCV, 2024. 5, 19
2024
-
[46]
RDT-1B: a diffusion foundation model for bimanual manipulation
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation. InICLR, 2025. 3 13 VoLo: A Physical Orchestrator for Open-VocabularyLong-Horizon Manipulation
2025
-
[47]
Zhen Liu, Xinyu Ning, Zhe Hu, Xinxin Xie, Weize Li, Zhipeng Tang, Chongyu Wang, Zejun Yang, Hanlin Wang, Yitong Liu, and Zhongzhu Pu. Goal2Skill: Long-horizon manipulation with adaptive planning and reflection.arXiv preprint arXiv:2604.13942, 2026. 2, 3
Pith/arXiv arXiv 2026
-
[48]
Weijia Liufu, Xiaoyu Guo, Ruiyi Chen, Jingzhi Liu, Kaidong Zhang, Xiwen Liang, Jianqi Lin, Dawei Sun, Yuze Wang, Rongtao Xu, Bingqian Lin, Bowen Yang, Tongtong Cao, Bowen Peng, Dongyu Zhang, Guangrun Wang, Min Wang, Liang Lin, and Xiaodan Liang. Repo-vla: Recovery-driven policy optimization for vision-language-action models.arXiv preprint arXiv:2605.09410...
Pith/arXiv arXiv 2026
-
[49]
Guoqing Ma, Siheng Wang, Zeyu Zhang, Shan Yu, and Hao Tang. Generalvla: Generalizable vision– language–action models with knowledge-guided trajectory planning.arXiv preprint arXiv:2602.04315,
-
[50]
CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022. 3
2022
-
[51]
Aoran Mei, Guo-Niu Zhu, Huaxiang Zhang, and Zhongxue Gan. ReplanVLM: Replanning robotic tasks with visual language models.arXiv preprint arXiv:2407.21762, 2024. 3
arXiv 2024
-
[52]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Mayank Mittal, Pascal Roth, James Tigue, Antoine Richard, Octi Zhang, Peter Du, Antonio Serrano-Muñoz, Xinjie Yao, René Zurbrügg, Nikita Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi-modal robot learning.arXiv preprint arXiv:2511.04831, 2025. doi: 10.48550/arXiv.2511.04831. URLhttps://arxiv.org/abs/2511.04831. 4, 24
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.04831 2025
-
[53]
Adithyavairavan Murali, Balakumar Sundaralingam, Yu-Wei Chao, Wentao Yuan, Jun Yamada, Mark Carlson, Fabio Ramos, Stan Birchfield, Dieter Fox, and Clemens Eppner. GraspGen: A diffusion-based framework for 6-DoF grasping with on-generator training.arXiv preprint arXiv:2507.13097, 2025. 5, 7, 19
arXiv 2025
-
[54]
RoboCasa: Large-scale simulation of everyday tasks for generalist robots
Soroush Nasiriany, Abhiram Maddukuri, Lance Zhang, Adeet Parikh, Aaron Lo, Abhishek Joshi, Ajay Mandlekar, and Yuke Zhu. RoboCasa: Large-scale simulation of everyday tasks for generalist robots. In Robotics: Science and Systems (RSS), 2024. 3
2024
-
[55]
Closed loop interactive embodied reasoning for robot manipulation
Michal Nazarczuk, Jan Kristof Behrens, Karla Stepanova, Matej Hoffmann, and Krystian Mikolajczyk. Closed loop interactive embodied reasoning for robot manipulation. InIEEE International Conference on Robotics and Automation (ICRA), 2025. 4
2025
-
[56]
Svyatoslav Pchelintsev, Maxim Patratskiy, Anatoly Onishchenko, Alexandr Korchemnyi, Aleksandr Medvedev, Uliana Vinogradova, Ilya Galuzinsky, Aleksey Postnikov, Alexey K. Kovalev, and Aleksandr I. Panov. LERa: Replanning with visual feedback in instruction following.arXiv preprint arXiv:2507.05135,
-
[57]
Karl Pertsch, Kyle Stachowicz, Brian Ichter, Danny Driess, Suraj Nair, Quan Vuong, Oier Mees, Chelsea Finn, and Sergey Levine. FAST: Efficient action tokenization for vision-language-action models.arXiv preprint arXiv:2501.09747, 2025. 7
Pith/arXiv arXiv 2025
-
[58]
Belinda Phipson and Gordon K. Smyth. Permutation p-values should never be zero: calculating exact p-values when permutations are randomly drawn.Statistical Applications in Genetics and Molecular Biology, 9(1):Article 39, 2010. 29
2010
-
[59]
SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. SAM 2: Segment anything in images and videos.arXiv preprint arXiv:2408.007...
Pith/arXiv arXiv 2024
-
[60]
Hierarchical vision-language planning for multi-step humanoid manipulation
André Schakkal, Ben Zandonati, Zhutian Yang, and Navid Azizan. Hierarchical vision-language planning for multi-step humanoid manipulation. InRobotics: Science and Systems (RSS) Workshop on Robot Planning in the Era of Foundation Models, 2025. arXiv:2506.22827. 3
arXiv 2025
-
[61]
William Shen, Nishanth Kumar, Sahit Chintalapudi, Jie Wang, Christopher Watson, Edward Hu, Jing Cao, Dinesh Jayaraman, Leslie Pack Kaelbling, and Tomás Lozano-Pérez. TiPToP: A modular open-vocabulary planning system for robotic manipulation.arXiv preprint arXiv:2603.09971, 2026. 3, 7
arXiv 2026
-
[62]
Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation
Hao Shi, Bin Xie, Yingfei Liu, Lin Sun, Fengrong Liu, Tiancai Wang, Erjin Zhou, Haoqiang Fan, Xi- angyu Zhang, and Gao Huang. Memoryvla: Perceptual-cognitive memory in vision-language-action models for robotic manipulation. InInternational Conference on Learning Representations (ICLR), 2026. arXiv:2508.19236. 3
Pith/arXiv arXiv 2026
-
[63]
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liyiming Ke, Karl Pertsch, Quan Vuong, James Tanner, Anna Walling, Haohuan Wang, Niccolo Fusai, Adrian Li-Bell, Danny Driess, Lachy Groom, Sergey Levine, and Chelsea Finn. Hi robot: Open-ended instruction following with hierarchical vision-language-action models.arXiv preprint arXiv:2502.19417, 2025. 2, 3
Pith/arXiv arXiv 2025
-
[64]
ProgPrompt: Generating situated robot task plans using large language models
Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, and Animesh Garg. ProgPrompt: Generating situated robot task plans using large language models. InICRA, 2023. 2, 3
2023
-
[65]
RePLan: Robotic replanning with perception and language models.arXiv preprint arXiv:2401.04157, 2024
Marta Skreta, Zihan Zhou, Jia Lin Yuan, Kourosh Darvish, Alán Aspuru-Guzik, and Animesh Garg. RePLan: Robotic replanning with perception and language models.arXiv preprint arXiv:2401.04157, 2024. 3
arXiv 2024
-
[66]
Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, Yulin Liu, Tse-kai Chan, Yuan Gao, Xuanlin Li, Tongzhou Mu, Nan Xiao, Arnav Gurha, Zhiao Huang, Roberto Calandra, Rui Chen, Shan Luo, and Hao Su. ManiSkill3: GPU parallelized robotics simulation and rendering for generalizable embodied AI.arXiv preprint ...
arXiv 2024
-
[67]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.Journal of the American Statistical Association, 22(158):209–212, 1927. 30
1927
-
[68]
Tianshuo Yang, Guanyu Chen, Yutian Chen, Zhixuan Liang, Yitian Liu, Zanxin Chen, Chunpu Xu, Haotian Liang, Jiangmiao Pang, Yao Mu, and Ping Luo. Hivla: A visual-grounded-centric hierarchical embodied manipulation system.arXiv preprint arXiv:2604.14125, 2026. 3
Pith/arXiv arXiv 2026
-
[69]
RoboLab: A high-fidelity simulation benchmark for analysis of task generalist policies
Xuning Yang, Rishit Dagli, Alex Zook, Hugo Hadfield, Ankit Goyal, Stan Birchfield, Fabio Ramos, and Jonathan Tremblay. RoboLab: A high-fidelity simulation benchmark for analysis of task generalist policies. RSS, 2026. 2, 3, 4, 6, 24, 34
2026
-
[70]
Fpc-vla: A vision-language-action framework with a supervisor for failure prediction and correction.Expert Systems with Applications, 316:131742,
Yifan Yang, Zhixiang Duan, Tianshi Xie, Fuyu Cao, Pinxi Shen, Peili Song, Chenyang Zhao, Piaopiao Jin, Guokang Sun, Shaoqing Xu, Yangwei You, and Jingtai Liu. Fpc-vla: A vision-language-action framework with a supervisor for failure prediction and correction.Expert Systems with Applications, 316:131742,
-
[71]
Zhejian Yang, Yongchao Chen, Xueyang Zhou, Jiangyue Yan, Dingjie Song, Yinuo Liu, Yuting Li, Yu Zhang, Pan Zhou, Hechang Chen, and Lichao Sun. Agentic robot: A brain-inspired framework for vision-language- action models in embodied agents.arXiv preprint arXiv:2505.23450, 2025. 2, 3
arXiv 2025
-
[72]
Zhutian Yang, Caelan Garrett, Dieter Fox, Tomás Lozano-Pérez, and Leslie Pack Kaelbling. Guiding long-horizon task and motion planning with vision language models.arXiv preprint arXiv:2410.02193,
-
[73]
3 15 VoLo: A Physical Orchestrator for Open-VocabularyLong-Horizon Manipulation
-
[74]
World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, Ayaan Malik, Kyungmin Lee, William Liang, Nadun Ranawaka, Jiasheng Gu, Yinzhen Xu, Guanzhi Wang, Fengyuan Hu, Avnish Narayan, Johan Bjorck, Jing Wang, Gwanghyun Kim, Dantong Niu, Ruijie Zheng, Yuqi Xie, Jimmy Wu, Qi ...
Pith/arXiv arXiv 2026
-
[75]
Zewei Ye, Weifeng Lu, Minghao Ye, Tao Lin, Shuo Yang, Junchi Yan, and Bo Zhao. RoboFAC: A compre- hensive framework for robotic failure analysis and correction.arXiv preprint arXiv:2505.12224, 2025. 3
arXiv 2025
-
[76]
Pengfei Yi, Yingjie Ma, Wenjiang Xu, Yanan Hao, Shuai Gan, Wanting Li, and Shanlin Zhong. Critic in the loop: A tri-system VLA framework for robust long-horizon manipulation.arXiv preprint arXiv:2603.05185,
-
[77]
HiRT: Enhancing robotic control with hierarchical robot transformers
Jianke Zhang, Yanjiang Guo, Xiaoyu Chen, Yen-Jen Wang, Yucheng Hu, Chengming Shi, and Jianyu Chen. HiRT: Enhancing robotic control with hierarchical robot transformers. InCoRL, 2024. 3
2024
-
[78]
Shiduo Zhang, Zhe Xu, Peiju Liu, Xiaopeng Yu, Yuan Li, Qinghui Gao, Zhaoye Fei, Zhangyue Yin, Zuxuan Wu, Yu-Gang Jiang, and Xipeng Qiu. VLABench: A large-scale benchmark for language-conditioned robotics manipulation with long-horizon reasoning tasks.arXiv preprint arXiv:2412.18194, 2024. 3, 31, 32
arXiv 2024
-
[79]
Closed-loop open-vocabulary mobile manipulation with GPT-4V
Peiyuan Zhi, Zhiyuan Zhang, Yu Zhao, Muzhi Han, Zeyu Zhang, Zhitian Li, Ziyuan Jiao, Baoxiong Jia, and Siyuan Huang. Closed-loop open-vocabulary mobile manipulation with GPT-4V. InICRA, 2025. 3, 4
2025
-
[80]
Yuke Zhu, Josiah Wong, Ajay Mandlekar, Roberto Martín-Martín, Abhishek Joshi, Kevin Lin, Abhiram Maddukuri, Soroush Nasiriany, and Yifeng Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020. 2, 3 16 VoLo: A Physical Orchestrator for Open-VocabularyLong-Horizon Manipulation Appendix We provi...
Pith/arXiv arXiv 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.