Summarization is Not Dead Yet
Pith reviewed 2026-06-27 19:58 UTC · model grok-4.3
The pith
Human reference summaries still outperform LLMs in informativeness, faithfulness and factual reliability on reasoning claims.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
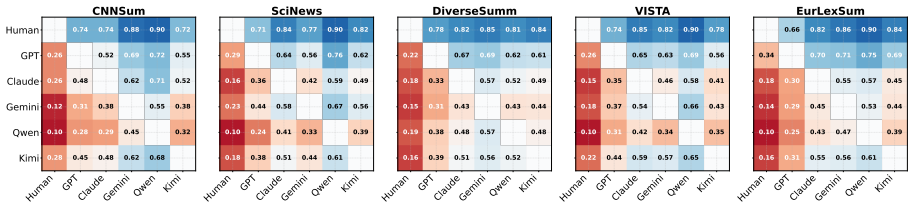
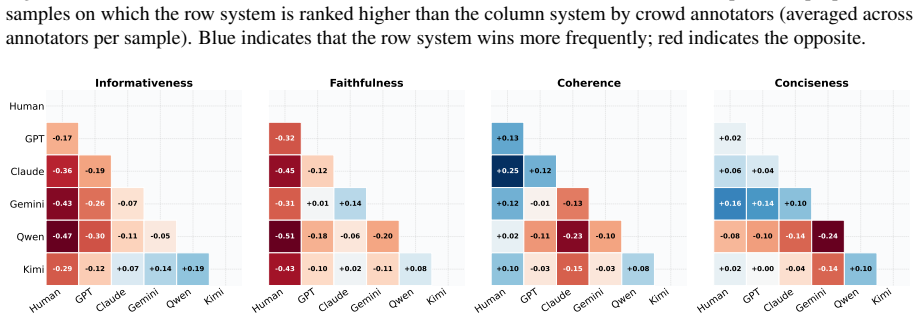
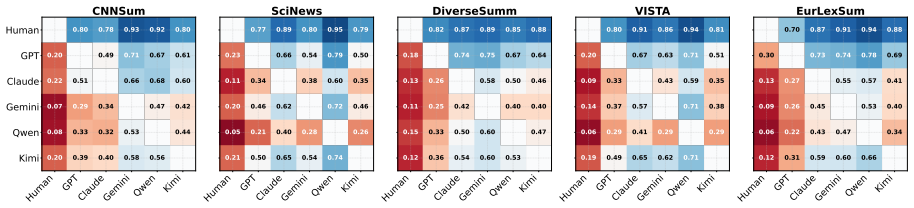
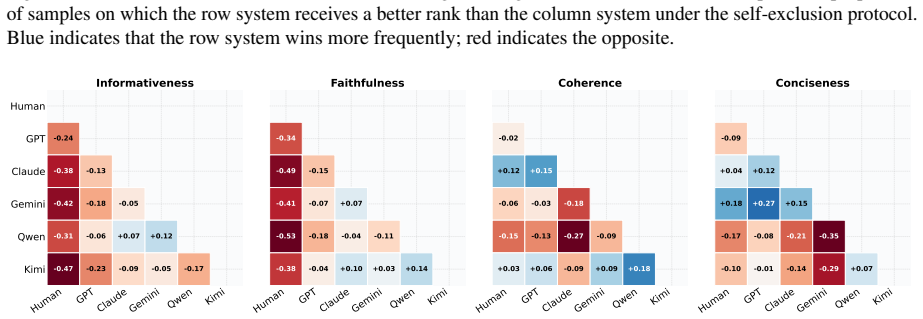
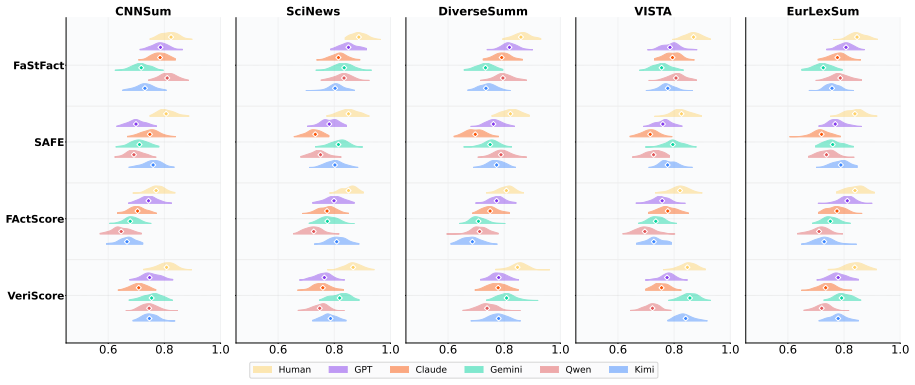
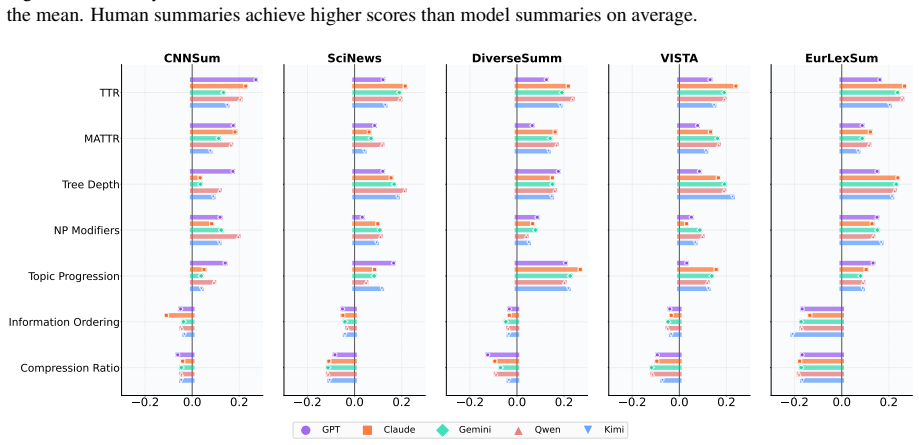
Human reference summaries continue to demonstrate advantages in informativeness and faithfulness, whereas LLM outputs are preferred mainly for surface-level coherence and fluency. Factuality verification indicates that human references remain more reliable, particularly for claims involving reasoning or synthesis, and linguistic analysis uncovers a pattern of stylistic homogeneity across different models. These observations suggest that current LLMs have raised the floor of summarization quality, but the ceiling of their performance remains below human capabilities.
What carries the argument
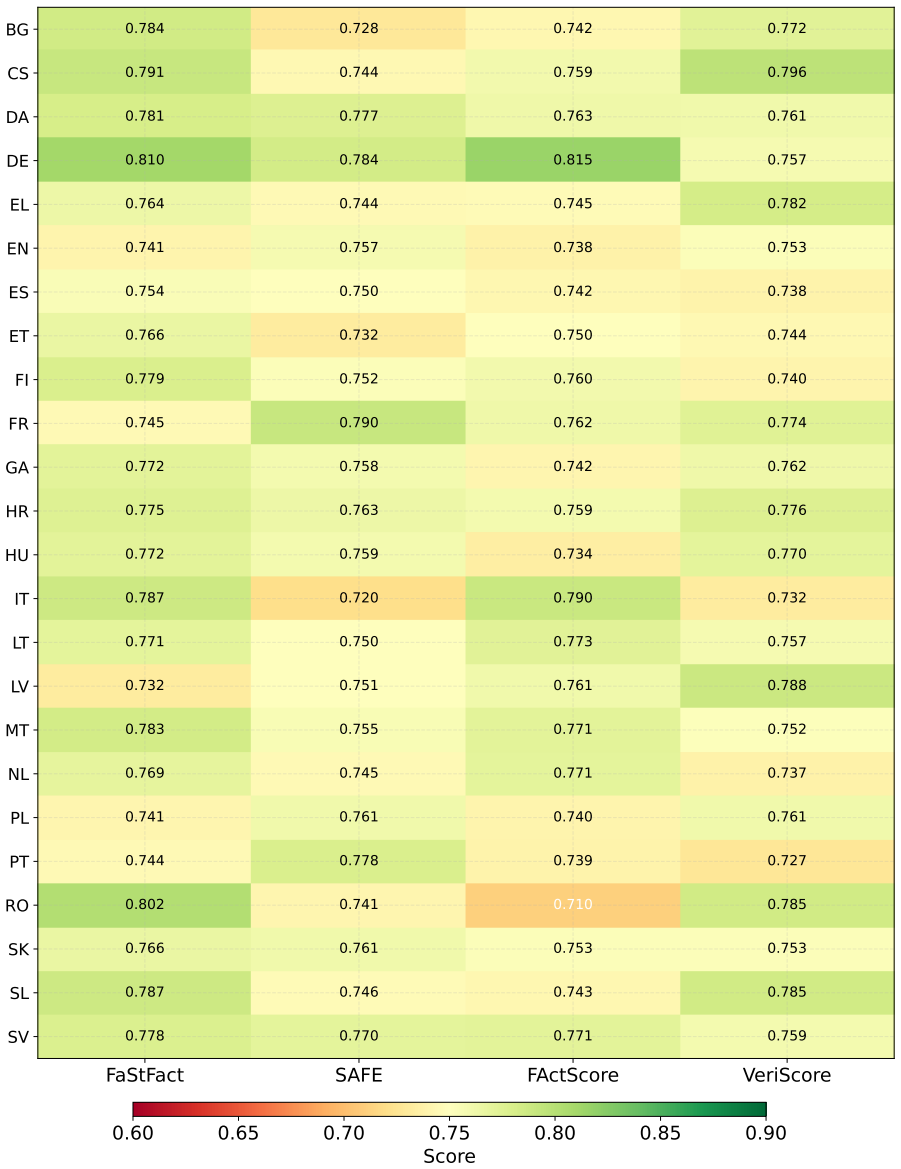
Multi-track evaluation that combines controlled human assessment, bias-mitigated LLM-as-Judge scoring, external factuality verification against knowledge sources, and corpus-level linguistic analysis.
If this is right
- Summarization remains an open problem that requires continued research on depth and factual synthesis.
- LLM training can exploit existing strengths in fluency while targeting gaps in reasoning and faithfulness.
- Human references continue to set a higher standard that current models do not meet.
- Stylistic homogeneity in LLM outputs may limit output variety across different domains.
Where Pith is reading between the lines
- Hybrid human-LLM pipelines could combine model fluency with human-level reliability for high-stakes use cases.
- The observed stylistic uniformity suggests that diversity objectives may need explicit training signals beyond standard objectives.
- Scaling alone may not close the gaps unless new methods specifically address synthesis and reasoning claims.
Load-bearing premise
The combination of human ratings, LLM judges, factuality checks, and linguistic metrics on five datasets gives an unbiased picture of quality differences.
What would settle it
A follow-up study on held-out datasets in which independent human raters consistently score LLM summaries higher than human references on both informativeness and faithfulness.
Figures



















read the original abstract
The progress of large language models (LLMs) has fueled claims that model-generated summaries rival or even surpass human-written references, raising questions about whether summarization remains an open research problem. We re-examine this narrative through a multi-track evaluation covering five diverse datasets and five state-of-the-art LLMs, combining controlled human assessment, bias-mitigated LLM-as-Judge protocols, factuality verification against external knowledge, and corpus-level linguistic analysis. Our findings reveal a more nuanced landscape in which human reference summaries continue to demonstrate advantages in informativeness and faithfulness, whereas LLM outputs are preferred mainly for surface-level coherence and fluency. Factuality verification indicates that human references remain more reliable, particularly for claims involving reasoning or synthesis, and linguistic analysis uncovers a pattern of stylistic homogeneity across different models. These observations suggest that current LLMs have raised the floor of summarization quality, but the ceiling of their performance remains below human capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper re-examines whether LLM-generated summaries have surpassed human references by performing a multi-track evaluation across five diverse datasets and five state-of-the-art LLMs. The protocol combines controlled human assessment, bias-mitigated LLM-as-Judge methods, factuality verification against external knowledge sources, and corpus-level linguistic analysis. Key findings are that human references retain advantages in informativeness and faithfulness, LLMs are preferred for surface coherence and fluency, human summaries are more reliable on reasoning/synthesis claims, and LLM outputs exhibit stylistic homogeneity.
Significance. If the multi-track results hold after full methodological scrutiny, the work supplies a timely, evidence-based counterpoint to narratives that summarization is solved, while crediting LLMs with raising baseline quality. The combination of human evaluation, external factuality checks, and linguistic analysis offers a template that could reduce reliance on single-metric or LLM-only judgments in future summarization research.
minor comments (2)
- [Abstract] The abstract states that the evaluation covers 'five diverse datasets' and 'five state-of-the-art LLMs' but does not name them; adding the specific dataset and model identifiers in the abstract or §1 would improve immediate readability.
- [Abstract] The phrase 'bias-mitigated LLM-as-Judge protocols' is used without a brief parenthetical example of the mitigation technique (e.g., prompt randomization or majority voting); a short clarification would help readers assess the claim without consulting later sections.
Simulated Author's Rebuttal
We thank the referee for their positive evaluation of the manuscript, accurate summary of our multi-track protocol, and recommendation of minor revision. The referee correctly identifies the core contribution as a nuanced counterpoint to claims that summarization is solved. No major comments were provided in the report, so we have no specific points requiring rebuttal or revision.
Circularity Check
No significant circularity
full rationale
The paper is a purely empirical study that compares LLM summaries to human references via controlled human assessments, LLM-as-judge protocols, external factuality checks, and linguistic analysis across five datasets. No equations, fitted parameters, derivations, or self-citations appear as load-bearing elements in the abstract or described methods. All claims reduce directly to observable data from external sources rather than to any internal construction or prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Controlled human assessment and external factuality verification provide reliable signals of summary quality
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 7626–7639, Abu Dhabi, United Arab Emirates
EUR-lex-sum: A multi- and cross-lingual dataset for long-form summarization in the legal do- main. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 7626–7639, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics. Nishant Balepur, Alexa Siu, Nedim Lipka, Franck Der- noncourt, Tong Sun, Jo...
2022
-
[2]
InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5291–5324, Albuquerque, New Mexico
From single to multi: How LLMs hallucinate in multi-document summarization. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 5291–5324, Albuquerque, New Mexico. Association for Computational Linguistics. Yoav Benjamini and Yosef Hochberg. 1995. Control- ling the false discovery rate: A practical and pow- erful approach to mul...
2025
-
[3]
In The Twelfth International Conference on Learning Representations
Booookscore: A systematic exploration of book-length summarization in the era of LLMs. In The Twelfth International Conference on Learning Representations. George Chrysostomou, Zhixue Zhao, Miles Williams, and Nikolaos Aletras. 2024. Investigating hallucina- tions in pruned large language models for abstractive summarization.Transactions of the Associatio...
2024
-
[4]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Evaluation metrics on text summarization: comprehensive survey.Knowledge and Information Systems, 66(12):7717–7738. Yue Dong, John Wieting, and Pat Verga. 2022. Faithful to the document or to the world? mitigating hal- lucinations via entity-linked knowledge in abstrac- tive summarization. InFindings of the Association for Computational Linguistics: EMNLP...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
LLM evaluators recognize and favor their own generations. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Pinelopi Papalampidi and Mirella Lapata. 2023. Hier- archical3D adapters for long video-to-text summa- rization. InFindings of the Association for Compu- tational Linguistics: EACL 2023, pages 1297–1320, Dubrovnik, Croa...
-
[6]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Sin- gapore
NLP evaluation in trouble: On the need to mea- sure LLM data contamination for each benchmark. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 10776–10787, Sin- gapore. Association for Computational Linguistics. Alessandro Scirè, Karim Ghonim, and Roberto Navigli
2023
-
[7]
InFindings of the Association for Compu- tational Linguistics: ACL 2024, pages 14148–14161, Bangkok, Thailand
FENICE: Factuality evaluation of summariza- tion based on natural language inference and claim extraction. InFindings of the Association for Compu- tational Linguistics: ACL 2024, pages 14148–14161, Bangkok, Thailand. Association for Computational Linguistics. Hwanjun Song, Hang Su, Igor Shalyminov, Jason Cai, and Saab Mansour. 2024a. FineSurE: Fine-grain...
2024
-
[8]
ArchRAG: Attributed Community-based Hierarchical Retrieval-Augmented Generation
Benchmarking LLM faithfulness in RAG with evolving leaderboards. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing: Industry Track, pages 799–811, Suzhou (China). Association for Computational Lin- guistics. Liyan Tang, Igor Shalyminov, Amy Wong, Jon Burnsky, Jake Vincent, Yu’an Yang, Siffi Singh, Song Feng, Hwanju...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
InThe Thirty-eighth Annual Conference on Neural Information Processing Systems
Long-form factuality in large language models. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems. Lingxiao Wei, He Yan, Lu Xiangju, Junmin Zhu, Jun Wang, and Wei Zhang. 2025. CNNSum: Explor- ing long-context summarization with large language models in Chinese novels. InFindings of the Asso- ciation for Computational Linguistic...
2025
-
[10]
InProceedings of The 5th New Frontiers in Summarization Workshop, pages 48–58, Hybrid
Beyond paraphrasing: Analyzing summariza- tion abstractiveness and reasoning. InProceedings of The 5th New Frontiers in Summarization Workshop, pages 48–58, Hybrid. Association for Computational Linguistics. Yuheng Zha, Yichi Yang, Ruichen Li, and Zhiting Hu
-
[11]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada
AlignScore: Evaluating factual consistency with a unified alignment function. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11328–11348, Toronto, Canada. Association for Computational Linguistics. Haopeng Zhang, Philip S. Yu, and Jiawei Zhang. 2025a. A systematic survey of text sum...
-
[12]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Benchmarking large language models for news summarization.Transactions of the Association for Computational Linguistics, 12:39–57. Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025c. Qwen3 embedding: Advancing text embedding and reranking through f...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 5172–5189, Vienna, Austria
MoC: Mixtures of text chunking learners for retrieval-augmented generation system. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 5172–5189, Vienna, Austria. Associa- tion for Computational Linguistics. Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yongh...
2023
-
[14]
Excl.” (self-exclusion, main protocol) and “Incl
Fairness or fluency? an investigation into language bias of pairwise llm-as-a-judge.Preprint, arXiv:2601.13649. A Models, Datasets, and Sample Counts Table 1 lists the full model identifiers and API ac- cess dates for all five evaluated LLMs. Throughout the paper, we use abbreviated names for simplicity. Abbreviation Full Model Identifier GPTGPT-5.4-2026-...
-
[15]
Claude shows the smallest gap . . . followed by GPT
at a nominal level ofα= 0.05 . Scores within each track are pooled across the five datasets before testing. Table 11 summarizes the outcomes, with ∗∗ marking p <0.01 after correction, ∗ marking 0.01≤p <0.05 after correction, and n.s. marking p≥0.05 . The sign of each gap is not encoded in the table and should be read from the main text. H Case Study We su...
-
[16]
Summarize the paper’s motivation, methodology, key findings, and conclusions
-
[17]
Preserve the technical terminology and quantitative details reported in the paper
-
[18]
Do not paraphrase quantities in a way that changes their precision or meaning
-
[19]
Do not introduce interpretations or claims that go beyond what the paper explicitly states
-
[20]
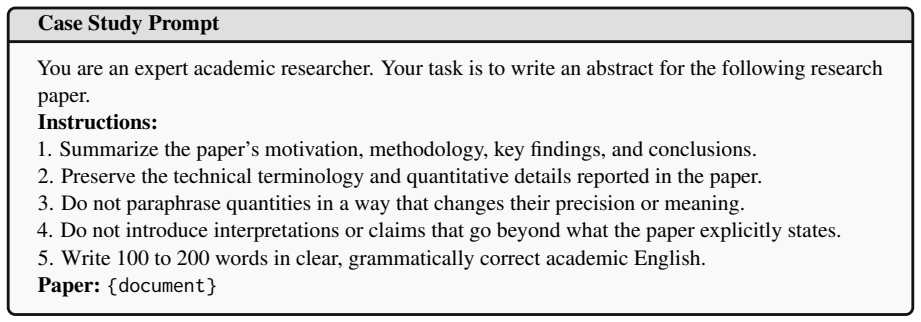
Paper:{document} Figure 16: Prompt template used for the case study in Appendix H
Write 100 to 200 words in clear, grammatically correct academic English. Paper:{document} Figure 16: Prompt template used for the case study in Appendix H. Human Reference The progress of large language models (LLMs) has fueled claims that model-generated summaries rival or even surpass human-written references, raising questions about whether summarizati...
-
[21]
核心要素覆盖。梗概须涵盖以下要素: (a) 主角的身份、出身背景与核心目标或动 机;(b) 与情节直接相关的世界观设定(如特殊力量体系、社会结构、地理环境); (c) 贯穿全篇的主线情节及其阶段性发展脉络; (d) 不少于两个关键转折点或高潮事件,并简 要说明其对人物处境与故事走向的影响; (e) 主要配角的身份、立场及其与主角的关系演 变;(f)故事的最终结局或走向(若原文已完结)。
-
[22]
叙事顺序与结构。按故事内时间顺序叙述,确保因果链条清晰;多线叙事时以主线为 骨架串联,支线信息在与主线交汇处简要带过,避免线索断裂。
-
[23]
客观性约束。严格不得加入原文未出现的情节、人物、地点、时间或因果关系,不得 添加任何主观评价、文学赏析、情感感叹或对结局的推测,不得使用任何评论性词汇。
-
[24]
the authors suggest
语言规范。使用规范的中文书面语,避免口语化、网络流行语与作者点评式语气。人 名、地名、特殊术语及专有名词须与原文用字完全一致,不得替换为常见同义词。 小说正文:{document} Figure 23: Prompt template for CNNSum (Chinese novel summarization). 32 SciNews Summarization Prompt (English) You are an expert science communicator with experience translating peer-reviewed research for general audiences. Your task is to write a lay summary of the...
-
[25]
A recorded scientific conference presentation video, including the speaker’s slides and any on-screen demonstrations
-
[26]
A verbatim or near-verbatim transcript of the same presentation. Instructions: 1.Abstract structure.Organize the summary around five elements in order: (a) the scientific motivation, framed as an existing limitation or open question; (b) the proposed approach, model, or experimental design, including any architectural or methodological innovations; (c) th...
-
[27]
Each rank must be used exactly once; ties are not permitted
to best (rank 6). Each rank must be used exactly once; ties are not permitted. 4.Bias mitigation.Score each summary on its own content, not its position in the list (A through F) or its surface style. Do not let stylistic familiarity favor one summary over another. Do not let your impression of an earlier summary anchor your scores for later ones. 5.Dimen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.