Adaptive Loss Balancing for Noise-Robust GRPO in Generative Recommendation
Pith reviewed 2026-06-27 18:52 UTC · model grok-4.3
The pith
AdaGRPO gates the GRPO objective with per-sample diagnostics so that reward guidance applies only when the policy is uncertain and the ranker discriminates well.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
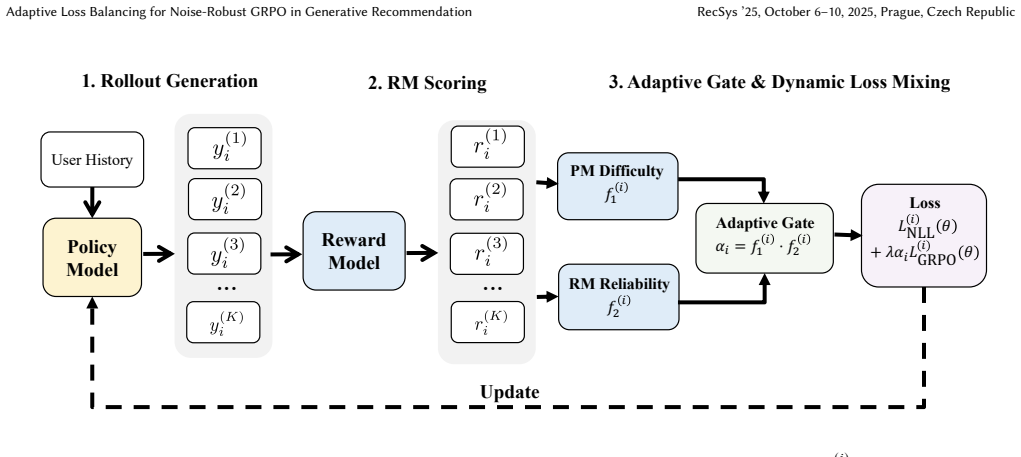
Treating reward-guided optimization as selective admission rather than uniform pressure, AdaGRPO anchors training in supervised negative log-likelihood while gating the GRPO objective by a binary per-sample clip determined by policy-side difficulty and reward discriminability; samples failing either diagnostic receive only the supervised loss.
What carries the argument
Binary per-sample clip from policy-side difficulty and reward discriminability that gates the GRPO objective while defaulting to NLL supervision.
If this is right
- Gradient noise from unreliable reward signals is reduced by excluding problematic samples from the RL term.
- The method maintains stability across training checkpoints while improving the retrieval-validity trade-off.
- Fixed-ratio mixtures of NLL and GRPO are outperformed because the per-sample decision adapts to each instance.
- Production metrics such as click-through rate and dwell time improve when the same selective rule is applied at scale.
Where Pith is reading between the lines
- The same diagnostic-gated pattern could be tested in other RLHF domains where reward models inherit logging bias.
- The diagnostics themselves might serve as a lightweight probe for reward-model quality before full RL training.
- Extending the framework to learned or dynamic thresholds on the two diagnostics is a direct next step.
Load-bearing premise
The two rollout diagnostics correctly identify the samples where the reward signal is beneficial rather than negligible or detrimental.
What would settle it
A controlled experiment on a held-out dataset or task where the selective gating produces no improvement or a regression relative to a fixed NLL-GRPO mixture would falsify the central claim.
Figures

read the original abstract
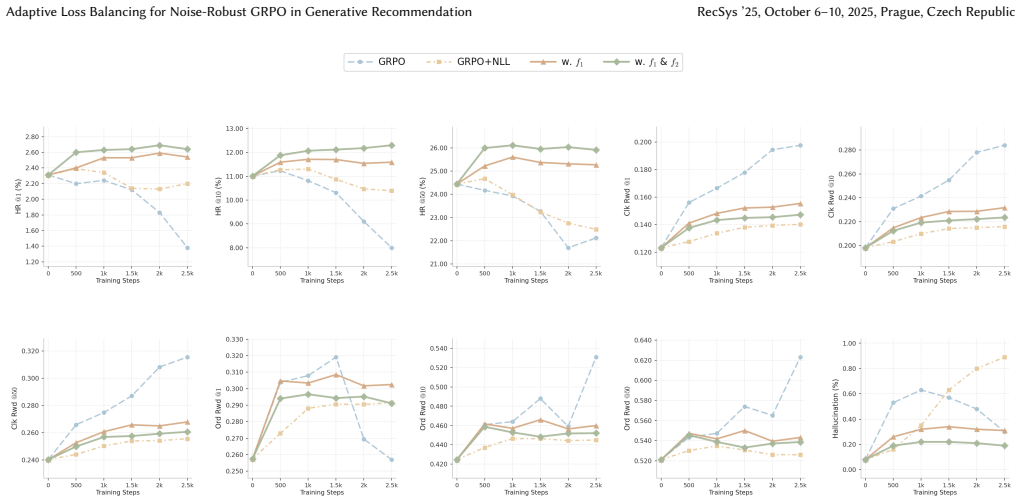
Reinforcement learning (RL) presents a promising avenue for enhancing generative recommendation beyond supervised imitation, leveraging reward signals to guide policy improvement. However, its efficacy is critically contingent on the trustworthiness of the reward model for the samples it evaluates. In practice, production rankers, the widely adopted reward models, are trained on exposure-biased logs, leading to sample-dependent inaccuracies that violate this assumption. Our stratified analysis uncovers a consistent pattern: reward guidance is most beneficial when the policy exhibits uncertainty and the ranker can effectively discriminate the ground-truth item from rollout negatives. On other samples, the reward signal is either negligible or detrimental, highlighting the risk of uniform RL application. To address such an issue, we introduce AdaGRPO, a novel framework that treats reward-guided optimization as selective admission rather than uniform pressure. Training is anchored in supervised negative log-likelihood, while the GRPO objective is gated by a binary, per-sample clip determined by two rollout diagnostics: policy-side difficulty and reward discriminability. Instances failing either diagnostic default to pure supervision, ensuring stability and mitigating the amplification of noisy gradients. We validate AdaGRPO on a large-scale e-commerce dataset. At the best intermediate checkpoint, it elevates HR@10 from 11.01% to 12.18% while constraining hallucination below 0.22%, and maintains robustness at the final checkpoint (HR@10 11.63%, hallucination 0.27%), outperforming fixed NLL--GRPO mixtures across the retrieval--validity frontier. In production A/B tests, AdaGRPO achieves statistically significant gains in click-through rate and dwell time, confirming its practical utility.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaGRPO for generative recommendation, anchoring training in supervised negative log-likelihood while selectively gating the GRPO objective on a per-sample basis. Gating uses two rollout diagnostics (policy-side difficulty and reward discriminability); samples failing either default to pure supervision. The approach is motivated by a stratified analysis showing reward guidance is beneficial only when the policy is uncertain and the ranker discriminates well. On a large-scale e-commerce dataset, AdaGRPO improves HR@10 (11.01% to 12.18% at best checkpoint, 11.63% at final) with hallucination below 0.27%, outperforming fixed NLL-GRPO mixtures, and yields statistically significant gains in production A/B tests on CTR and dwell time.
Significance. If the empirical results and diagnostics hold under broader conditions, the selective-admission framing could meaningfully improve robustness of reward-guided optimization in production generative recommenders where ranker rewards are exposure-biased. The production A/B test provides direct evidence of practical utility beyond offline metrics.
major comments (3)
- [Abstract / Method] Abstract and method description: the exact computation formulas or pseudocode for the two rollout diagnostics (policy-side difficulty and reward discriminability) are not supplied, which is load-bearing because the central claim that these diagnostics correctly identify the subset where reward is beneficial (rather than negligible or detrimental) rests on their precise definitions and thresholds.
- [Experiments] Results: the reported HR@10 lifts (11.01% o 12.18%) and hallucination bounds lack error bars, confidence intervals, or the number of runs; without these, it is impossible to assess whether the outperformance over fixed NLL-GRPO mixtures is statistically reliable or sensitive to checkpoint selection.
- [Experiments] Experiments: no implementation details (rollout count, temperature, exact GRPO formulation, or how the binary clip is applied in the loss) are given, preventing reproduction or verification that the method indeed defaults to supervision on the claimed fraction of samples.
minor comments (2)
- [Abstract] The abstract refers to 'stratified analysis' without indicating the number of strata, sample sizes per stratum, or statistical test used to establish the 'consistent pattern.'
- [Method] Notation for the binary clip and the two diagnostics should be introduced with symbols in the method section for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights important aspects of clarity and reproducibility. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the exact computation formulas or pseudocode for the two rollout diagnostics (policy-side difficulty and reward discriminability) are not supplied, which is load-bearing because the central claim that these diagnostics correctly identify the subset where reward is beneficial (rather than negligible or detrimental) rests on their precise definitions and thresholds.
Authors: We agree that the precise definitions are necessary to substantiate the selective-admission claim. The current manuscript describes the diagnostics at a conceptual level only. We will add the exact formulas, threshold values, and pseudocode to Section 3 in the revised version. revision: yes
-
Referee: [Experiments] Results: the reported HR@10 lifts (11.01% to 12.18%) and hallucination bounds lack error bars, confidence intervals, or the number of runs; without these, it is impossible to assess whether the outperformance over fixed NLL-GRPO mixtures is statistically reliable or sensitive to checkpoint selection.
Authors: The reported metrics come from a single training run on the large-scale dataset. We will rerun the key experiments with multiple random seeds, report means with standard deviations or confidence intervals, and clarify the number of runs in the revised results section. revision: yes
-
Referee: [Experiments] Experiments: no implementation details (rollout count, temperature, exact GRPO formulation, or how the binary clip is applied in the loss) are given, preventing reproduction or verification that the method indeed defaults to supervision on the claimed fraction of samples.
Authors: We will expand the experimental setup and method sections to include rollout count, temperature, the precise GRPO objective used, and the exact application of the per-sample binary clip within the combined loss. This will also document the observed fraction of samples routed to pure supervision. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's central mechanism anchors training in supervised NLL and gates the GRPO objective via per-sample binary decisions derived from two rollout diagnostics (policy difficulty and reward discriminability). These diagnostics are computed externally from rollouts rather than being fitted to or defined by the target performance metric itself. No equations, self-citations, or ansatzes are shown that reduce the claimed improvement to a tautological fit or imported uniqueness result. The description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM conference on recommender systems. 1007–1014
2023
-
[2]
Stephen Casper, Xander Davies, Claudia Shi, Thomas Krendl Gilbert, Jérémy Scheurer, Javier Rando, Rachel Freedman, Tomasz Korbak, David Lindner, Pedro Freire, et al. 2023. Open problems and fundamental limitations of reinforcement learning from human feedback.arXiv preprint arXiv:2307.15217(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions. ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[4]
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. 2019. Behavior sequence transformer for e-commerce recommendation in alibaba. InProceedings of the 1st international workshop on deep learning practice for high-dimensional sparse data. 1–4
2019
-
[5]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Leo Gao, John Schulman, and Jacob Hilton. 2023. Scaling laws for reward model overoptimization. InInternational Conference on Machine Learning. PMLR, 10835– 10866
2023
-
[7]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
-
[8]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al . 2025. DeepSeek-R1 in- centivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (2025), 633–638
2025
- [9]
-
[10]
Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased learning-to-rank with biased feedback. InProceedings of the tenth ACM interna- tional conference on web search and data mining. 781–789
2017
-
[11]
Jiacheng Li, Ming Wang, Jin Li, Jinmiao Fu, Xin Shen, Jingbo Shang, and Julian McAuley. 2023. Text is all you need: Learning language representations for sequential recommendation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 1258–1267
2023
-
[12]
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, and Weinan Zhang. 2024. Rella: Retrieval-enhanced large language models for lifelong sequential behavior comprehension in recom- mendation. InProceedings of the ACM Web Conference 2024. 3497–3508
2024
-
[13]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems35 (2022), 27730–27744
2022
- [14]
-
[15]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741
2023
-
[16]
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan Hulikal Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Tran, Jonah Samost, Maciej Kula, Ed Chi, and Maheswaran Sathiamoorthy. 2023. Recommender Systems with Generative Retrieval. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, an...
2023
-
[17]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[18]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Yuxuan Tong, Xiwen Zhang, Rui Wang, Ruidong Wu, and Junxian He. 2024. Dart-math: Difficulty-aware rejection tuning for mathematical problem-solving. Advances in Neural Information Processing Systems37 (2024), 7821–7846
2024
- [21]
- [22]
-
[23]
Jixiao Zhang and Chunsheng Zuo. 2025. Grpo-lead: A difficulty-aware reinforce- ment learning approach for concise mathematical reasoning in language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 5642–5665
2025
-
[24]
Zhe Zhao, Lichan Hong, Li Wei, Jilin Chen, Aniruddh Nath, Shawn Andrews, Aditee Kumthekar, Maheswaran Sathiamoorthy, Xinyang Yi, and Ed Chi. 2019. Recommending what video to watch next: a multitask ranking system. InPro- ceedings of the 13th ACM conference on recommender systems. 43–51
2019
-
[25]
Zhi Zheng, Wenshuo Chao, Zhaopeng Qiu, Hengshu Zhu, and Hui Xiong. 2024. Harnessing large language models for text-rich sequential recommendation. In Proceedings of the ACM Web Conference 2024. 3207–3216
2024
- [26]
-
[27]
Yanyan Zou, Junbo Qi, Lunsong Huang, Yu Li, Kewei Xu, Jiabao Gao, Bin- glei Zhao, Xuanhua Yang, Sulong Xu, and Shengjie Li. 2026. GenRec: A Preference-Oriented Generative Framework for Large-Scale Recommendation. arXiv:2604.14878 [cs.IR] https://arxiv.org/abs/2604.14878
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.