Ishigaki-IDS: An Open-Weight Verifier-Aware Model for Information Delivery Specification Drafting in Building Information Modeling
Pith reviewed 2026-06-27 18:23 UTC · model grok-4.3
The pith
An open-weight LLM trained with external validator rewards generates BIM IDS drafts that pass checks at twice the rate of Claude Opus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
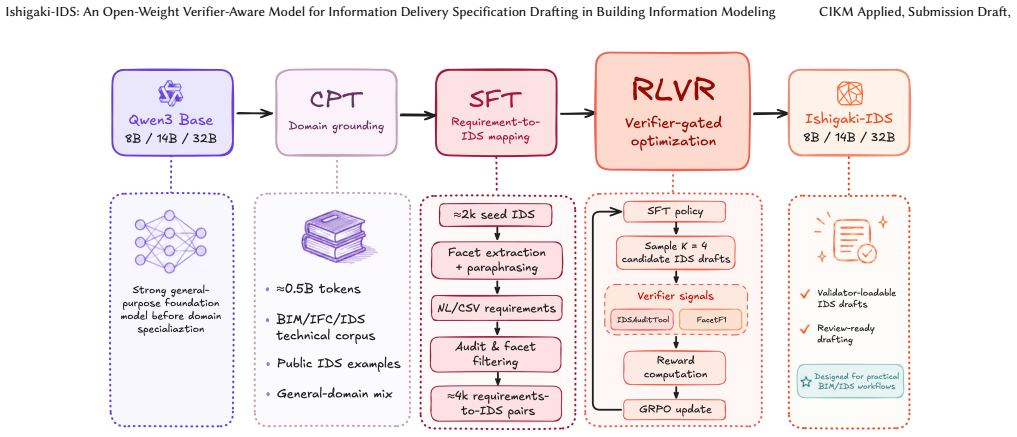
Ishigaki-IDS models are produced by continued pretraining on BIM/IDS data, supervised fine-tuning on information-requirement-to-IDS pairs, and reinforcement learning with rewards from an external validator. On the 166-case Ishigaki-IDS-Bench the 8B, 14B and 32B variants obtain IDSAuditPass scores of 0.651, 0.753 and 0.693, exceeding the 0.331 score of the strongest single-shot baseline evaluated, and they also record Audit-Gated FacetF1 scores of 0.282, 0.392 and 0.369 among validator-passing drafts. In a workflow check the assisted process reduced aggregate practitioner time by 54.7 percent at fixed validation and alignment endpoints.
What carries the argument
Reinforcement learning that supplies rewards from an external IDS validator to guide generation toward conformant and requirement-aligned outputs.
If this is right
- Larger model sizes within the same training recipe produce higher IDSAuditPass and Audit-Gated FacetF1 scores.
- Generated drafts become validator-loadable, allowing practitioners to move from low-level XML editing to review and correction.
- The combination of domain pretraining, supervised fine-tuning, and validator-guided reinforcement learning scales to improved performance on the task.
Where Pith is reading between the lines
- Integration of such models into existing BIM tools could provide interactive draft suggestions during requirements capture.
- Similar verifier-aware reinforcement learning may transfer to other engineering domains that require machine-checkable structured outputs.
- Widespread use would shift practitioner expertise toward high-level validation rather than manual schema construction.
Load-bearing premise
The external validator supplies reliable, unbiased reward signals during reinforcement learning that generalize beyond the 166-case benchmark and six-practitioner study.
What would settle it
A fresh collection of real-world BIM information requirements, never seen in training or the original benchmark, on which Ishigaki-IDS models no longer exceed general LLMs on IDSAuditPass or produce measurable time reductions in practitioner trials.
Figures

read the original abstract
Building Information Modeling (BIM) projects require information requirements to be described as machine-checkable Information Delivery Specification (IDS) files in order to verify whether building models contain the required attributes. However, IDS authoring remains a practical bottleneck: practitioners must handle domain vocabulary, strict XML schema constraints, and external validator conformance while also checking whether the requirement itself is correctly expressed. We present Ishigaki-IDS, an open-weight LLM specialized for verifier-aware IDS draft generation. The model combines continued pretraining on BIM/IDS corpora, supervised fine-tuning on information-requirement-to-IDS pairs, and reinforcement learning with verifiable rewards from an external validator. The goal is not to replace expert review, but to move IDS authoring from low-level XML and schema repair toward validator-loadable drafts that practitioners can inspect and correct. On the 166-case expert-created Ishigaki-IDS-Bench, Ishigaki-IDS-8B achieves an IDSAuditPass score of 0.651, a validator-pass metric for generated IDS files, substantially outperforming Claude Opus 4.5, the strongest single-shot LLM baseline we evaluated, at 0.331. It also obtains an Audit-Gated FacetF1 of 0.282, which measures requirement-facet alignment among validator-passing drafts. The same recipe scales: 14B and 32B variants reach IDSAuditPass 0.753 / 0.693 and Audit-Gated FacetF1 0.392 / 0.369. In a workflow check with six BIM practitioners, Ishigaki-assisted authoring reduced aggregate work time by 54.7% under the same validation and alignment endpoint. These results suggest that verifier-aware IDS generation can reduce the practical burden of converting BIM information requirements into reviewable IDS drafts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Ishigaki-IDS, an open-weight LLM for generating verifier-aware Information Delivery Specification (IDS) drafts in BIM. It combines continued pretraining on BIM/IDS corpora, supervised fine-tuning on requirement-to-IDS pairs, and RL using rewards from an external validator. On the custom 166-case Ishigaki-IDS-Bench, the 8B model reports IDSAuditPass of 0.651 (vs. Claude Opus 4.5 at 0.331), with 14B/32B variants at 0.753/0.693; it also reports Audit-Gated FacetF1 scores and a 54.7% aggregate work-time reduction in a six-practitioner workflow study. The goal is to produce reviewable drafts rather than replace experts.
Significance. If the benchmark results and time-reduction claim hold under independent scrutiny, the work could reduce a documented practical bottleneck in BIM projects by shifting IDS authoring from XML/schema repair toward validator-loadable drafts. The open-weight release and use of an external verifiable reward signal are concrete strengths that support reproducibility and extension in the AEC domain.
major comments (3)
- [Abstract] Abstract: The headline IDSAuditPass scores (0.651 for 8B, scaling to 0.753 for 14B) rest on the 166-case Ishigaki-IDS-Bench, yet no information is supplied on case selection criteria, domain coverage across BIM subfields, or training-data overlap; this directly affects whether the performance gap versus Claude can be interpreted as general improvement rather than benchmark-specific optimization.
- [Abstract] Abstract: The 54.7% time reduction is reported from a workflow check with n=6 practitioners under the same validation endpoint, but the abstract supplies neither per-practitioner times, variance, experimental design (e.g., counterbalancing, controls), nor statistical tests; with such small N the aggregate figure is load-bearing for the practical-utility claim yet cannot be evaluated for reliability.
- [Abstract] Abstract: Reinforcement learning employs rewards from the identical external validator that defines the IDSAuditPass metric used at test time; without an ablation that decouples training reward from evaluation metric, the reported scores risk reflecting validator-specific conformance rather than independent requirement correctness, which is central to the verifier-aware framing.
minor comments (1)
- [Abstract] Abstract: Model parameter counts (8B/14B/32B) and the three-stage training recipe are mentioned only in passing; a single sentence summarizing the data sources for continued pretraining and SFT would improve readability without lengthening the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on transparency in the benchmark, user study, and RL design. We address each point below with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline IDSAuditPass scores (0.651 for 8B, scaling to 0.753 for 14B) rest on the 166-case Ishigaki-IDS-Bench, yet no information is supplied on case selection criteria, domain coverage across BIM subfields, or training-data overlap; this directly affects whether the performance gap versus Claude can be interpreted as general improvement rather than benchmark-specific optimization.
Authors: We agree that the abstract omits key benchmark details. The full manuscript describes the 166 cases as expert-created from real BIM projects. We will revise the experimental setup section (and reference it from the abstract) to specify case selection criteria, domain coverage across architectural/structural/MEP disciplines, and confirmation of no training-data overlap via project-level splits and manual review. This will allow readers to better assess generalizability versus optimization. revision: yes
-
Referee: [Abstract] Abstract: The 54.7% time reduction is reported from a workflow check with n=6 practitioners under the same validation endpoint, but the abstract supplies neither per-practitioner times, variance, experimental design (e.g., counterbalancing, controls), nor statistical tests; with such small N the aggregate figure is load-bearing for the practical-utility claim yet cannot be evaluated for reliability.
Authors: The reported figure derives from a preliminary within-subjects workflow check. We will expand the relevant section to include per-practitioner times, variance, design details (counterbalancing of assisted vs. unassisted tasks), and an explicit statement that no formal statistical tests were performed due to small N. The claim will be qualified as preliminary evidence of utility rather than a definitive result. revision: yes
-
Referee: [Abstract] Abstract: Reinforcement learning employs rewards from the identical external validator that defines the IDSAuditPass metric used at test time; without an ablation that decouples training reward from evaluation metric, the reported scores risk reflecting validator-specific conformance rather than independent requirement correctness, which is central to the verifier-aware framing.
Authors: The shared validator is by design to optimize for the practical goal of producing validator-passing drafts. We acknowledge that this leaves open the possibility of validator-specific behavior rather than fully independent correctness. No ablation with a held-out validator was performed. We will add a limitations discussion noting this risk and proposing future multi-validator experiments, while noting that Audit-Gated FacetF1 offers a partial check on requirement alignment. revision: partial
Circularity Check
No circularity; results rest on external benchmark comparisons and practitioner study
full rationale
The paper trains via continued pretraining, SFT on requirement-to-IDS pairs, and RL with rewards from an external validator, then reports IDSAuditPass (validator-pass rate) and Audit-Gated FacetF1 on a separate 166-case expert-created benchmark, plus time savings from a six-practitioner workflow check. These are direct empirical measurements against baselines (e.g., Claude Opus) that lack the RL stage; no equation, definition, or self-citation reduces the reported scores or time reduction to the training inputs by construction. The derivation chain is self-contained against the stated external validator and held-out cases.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An external IDS validator can supply reliable and generalizable reward signals for reinforcement learning on schema-constrained generation.
Reference graph
Works this paper leans on
-
[1]
Chunyan An, Yuying Huang, Qiang Yang, Siyu Yuan, and Zhixu Li. 2025. LLM- Powered Information Extraction for the Dairy Financial Domain: Tackling Data Scarcity and Ambiguity. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. Association for Computing Machinery, New York, NY, USA, 55–64. doi:10.1145/3746252.3761030
-
[2]
Anand Brahmbhatt, Mohith Pokala, Rishi Saket, and Aravindan Raghuveer. 2024. LLP-Bench: A Large Scale Tabular Benchmark for Learning from Label Propor- tions. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management. Association for Computing Machinery, New York, NY, USA, 4374–4381. doi:10.1145/3627673.3680032
-
[3]
buildingSMART International. 2024. IDSAuditTool. https://github.com/ buildingSMART/IDS-Audit-tool. Official buildingSMART tool for auditing IDS files. Accessed: 2026-05-17
2024
-
[4]
buildingSMART International. 2026. Industry Foundation Classes (IFC). https://www.buildingsmart.org/standards/bsi-standards/industry-foundation- classes/. Accessed: 2026-05-08
2026
-
[5]
buildingSMART International. 2026. Information Delivery Specification (IDS). https://www.buildingsmart.org/standards/bsi-standards/information- delivery-specification-ids/. Accessed: 2026-05-08
2026
-
[6]
Tomo Cerovšek and Mohamed Omar. 2025. Advancing Semantic Enrichment Compliance in BIM: An Ontology-Based Framework and IDS Evaluation.Build- ings15, 15 (2025), 2621. doi:10.3390/buildings15152621
-
[7]
Giancarlo de Marco, Cinzia Slongo, and Dietmar Siegele. 2024. Enriching Build- ing Information Modeling Models through Information Delivery Specification. Buildings14, 7 (2024), 2206. doi:10.3390/buildings14072206
-
[8]
Li Dong and Mirella Lapata. 2016. Language to Logical Form with Neural Atten- tion. InProceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, Berlin, Germany, 33–43. doi:10.18653/v1/P16-1004
-
[9]
Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen
Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, and Tianqi Chen. 2024. XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models. arXiv:2411.15100. doi:10.48550/arXiv.2411. 15100
-
[10]
2018.BIM Hand- book: A Guide to Building Information Modeling for Owners, Designers, Engineers, Contractors, and Facility Managers(3 ed.)
Chuck Eastman, Paul Teicholz, Rafael Sacks, and Ghang Lee. 2018.BIM Hand- book: A Guide to Building Information Modeling for Owners, Designers, Engineers, Contractors, and Facility Managers(3 ed.). Wiley, Hoboken, NJ, USA
2018
-
[11]
Simon Fischer, Harald Urban, Christian Schranz, and Gerhard Zucker. 2025. Bridging the Gap Between Tabular Information Requirements and the Infor- mation Delivery Specification (IDS).Buildings15, 7 (2025), 1017. doi:10.3390/ buildings15071017
2025
-
[12]
Forestry Agency, Ministry of Agriculture, Forestry and Fisheries of Japan. 2025. Wooden BIM Model Parameter Guide: Explanation of How to Assign Information to Object Data in Wooden Design BIM Models. https://www.rinya.maff.go.jp/j/ mokusan/attach/pdf/bim-19.pdf. In Japanese. Accessed: 2026-05-17
2025
-
[13]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, et al. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645 (2025), 633–638. doi:10.1038/s41586-025- 09422-z
-
[14]
IfcOpenShell Contributors. 2026. IfcOpenShell. https://docs.ifcopenshell.org/ ifcopenshell.html. Open source IFC library and geometry engine. Accessed: 2026-05-17
2026
-
[15]
Yuhe Ji, Yilun Liu, Feiyu Yao, Minggui He, Shimin Tao, Xiaofeng Zhao, Chang Su, Xinhua Yang, Weibin Meng, Yuming Xie, Boxing Chen, Shenglin Zhang, and Yongqian Sun. 2025. Adapting Large Language Models to Log Analysis with Interpretable Domain Knowledge. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. Associ...
-
[16]
Ryo Kanazawa, Koyo Hidaka, Tomoki Ando, Chenguang Wang, Dayuan Jiang, and Daiho Nishioka. 2026. ONESTRUCTION/Ishigaki-IDS-8B. https://huggingface. co/ONESTRUCTION/Ishigaki-IDS-8B. doi:10.57967/hf/8871 Model card and weights. Accessed: 2026-05-20
-
[17]
Ryo Kanazawa, Koyo Hidaka, Teppei Miyamoto, Takayuki Kato, Tomoki Ando, Chenguang Wang, Dayuan Jiang, Naofumi Fujita, Shuhei Saitoh, Atomu Kondo, Koki Arakawa, and Daiho Nishioka. 2026. Ishigaki-IDS-Bench. doi:10.57967/hf/ 8873 Hugging Face dataset. Accessed: 2026-05-21
-
[18]
Ryo Kanazawa, Koyo Hidaka, Teppei Miyamoto, Takayuki Kato, Tomoki Ando, Chenguang Wang, Dayuan Jiang, Naofumi Fujita, Shuhei Saitoh, Atomu Kondo, Koki Arakawa, and Daiho Nishioka. 2026. Ishigaki-IDS-Bench: A Benchmark for Generating Information Delivery Specification from BIM Information Require- ments. arXiv:2605.22079 [cs.CL] https://arxiv.org/abs/2605.22079
Pith/arXiv arXiv 2026
-
[19]
Ryo Kanazawa, Koyo Hidaka, Teppei Miyamoto, Takayuki Kato, Tomoki Ando, Chenguang Wang, Dayuan Jiang, Naofumi Fujita, Shuhei Saitoh, Atomu Kondo, Koki Arakawa, and Daiho Nishioka. 2026. Ishigaki-IDS-Bench: Evaluation Code and Reproducibility Repository. doi:10.5281/zenodo.20362616 GitHub repository release v1.0.0. Accessed: 2026-05-24
-
[20]
Hwang, Jiangjiang Yang, Ro- nan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivi- son, Faeze Brahman, Lester James Validad Miranda, Alisa Liu, Nouha Dziri, Xinxi Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ro- nan Le Bras, Oyvind Tafjord, Christopher Wilhelm, Luca Soldaini, Noah A. Smith, et al. 2025. Tulu 3: Pushing Frontiers...
2025
-
[21]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s Verify Step by Step. arXiv:2305.20050. doi:10.48550/arXiv.2305.20050
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.20050 2023
-
[22]
Gang Luo, Julien Han, Hayreddin Ceker, and Karim Bouyarmane. 2025. Using Large Language Models to Improve Product Information in E-commerce Catalogs. InProceedings of the 34th ACM International Conference on Information and Knowledge Management. Association for Computing Machinery, New York, NY, USA, 6873–6874. doi:10.1145/3746252.3761437
-
[23]
Soumya Madireddy, Lu Gao, Zia Ud Din, Kinam Kim, Ahmed Senouci, Zhe Han, and Yunpeng Zhang. 2025. Large Language Model-Driven Code Compliance Checking in Building Information Modeling.Electronics14, 11 (2025), 2146. doi:10.3390/electronics14112146
-
[24]
NVIDIA Corporation. 2026. NVIDIA NeMo Framework. https://docs.nvidia.com/ nemo-framework/user-guide/latest/overview.html. Documentation. Accessed: 2026-05-21
2026
-
[25]
Guilherme Penedo, Hynek Kydlíček, Vinko Sabolčec, Bettina Messmer, Negar Foroutan, Amir Hossein Kargaran, Colin Raffel, Martin Jaggi, Leandro Von Werra, and Thomas Wolf. 2025. FineWeb2: One Pipeline to Scale Them All – Adapting Pre-Training Data Processing to Every Language. arXiv:2506.20920. doi:10.48550/ arXiv.2506.20920
arXiv 2025
-
[26]
Maxim Rabinovich, Mitchell Stern, and Dan Klein. 2017. Abstract Syntax Net- works for Code Generation and Semantic Parsing. InProceedings of the 55th An- nual Meeting of the Association for Computational Linguistics. Association for Com- putational Linguistics, Vancouver, Canada, 1139–1149. doi:10.18653/v1/P17-1105
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. DeepSeek- Math: Pushing the Limits of Mathematical Reasoning in Open Language Models. arXiv:2402.03300. doi:10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[28]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. HybridFlow: A Flexible and Efficient RLHF Framework. arXiv:2409.19256. doi:10.48550/arXiv.2409.19256
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.19256 2024
-
[29]
vLLM Team. 2026. Structured Outputs. https://docs.vllm.ai/usage/structured_ outputs.html. vLLM documentation. Accessed: 2026-05-17
2026
-
[30]
Efficient Guided Generation for Large Language Models
Brandon T. Willard and Rémi Louf. 2023. Efficient Guided Generation for Large Language Models. arXiv:2307.09702. doi:10.48550/arXiv.2307.09702
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.09702 2023
-
[31]
An Yang et al. 2025. Qwen3 Technical Report. arXiv:2505.09388. doi:10.48550/ arXiv.2505.09388
Pith/arXiv arXiv 2025
-
[32]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Proces...
-
[33]
Chunting Zhou, Pengfei Liu, Puxin Xu, Srini Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, Susan Zhang, Gargi Ghosh, Mike Lewis, Luke Zettlemoyer, and Omer Levy. 2023. LIMA: Less Is More for Alignment. arXiv:2305.11206. doi:10.48550/arXiv.2305.11206
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.11206 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.