Operator learning for the 2D incompressible Navier-Stokes equations: a conformal prediction approach in the data-scarce regime
Pith reviewed 2026-06-27 18:38 UTC · model grok-4.3
The pith
Perturbation-based conformal prediction produces narrower uncertainty bands for neural operators on 2D Navier-Stokes under fixed data budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
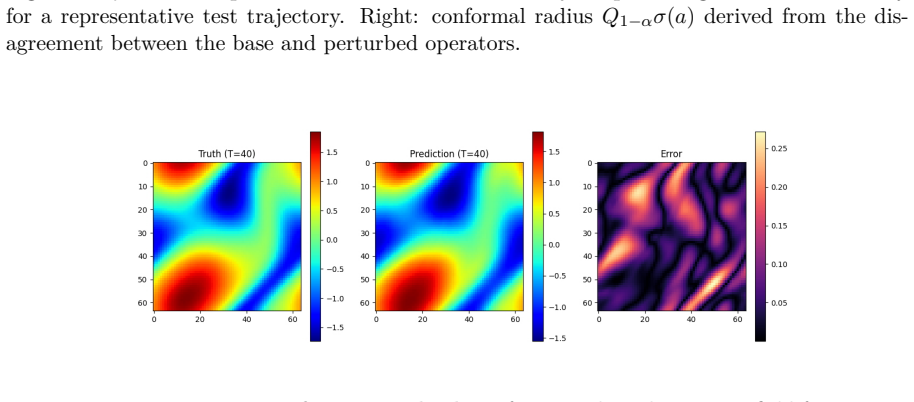
By training one Fourier Neural Operator on the original dataset and another on labels perturbed by small Gaussian noise, the difference in their predictions provides a local uncertainty scale. When this scale is used within split conformal prediction, the resulting intervals maintain the desired coverage but are narrower than those from competing approaches that require splitting the data budget across multiple models, as demonstrated on the 2D incompressible Navier-Stokes equations.
What carries the argument
The perturbation-based local uncertainty scale derived from the prediction difference between two FNOs trained on nearly identical but differently labeled datasets.
If this is right
- The perturbation method maintains target simultaneous coverage on the benchmark.
- It produces substantially narrower conformal bands than existing methods under matched total data budgets.
- Perturbation sensitivity acts as a sample-efficient uncertainty proxy for neural operators.
- The approach is suitable for data-scarce regimes where training separate uncertainty networks divides the data.
Where Pith is reading between the lines
- If the perturbation method generalizes, it could apply to other PDE operator learning tasks with limited data.
- The method might allow for better uncertainty quantification without additional model training overhead.
- Optimal choice of perturbation magnitude could be investigated further for different equations.
Load-bearing premise
Comparing predictions from operators trained on original and perturbed labels yields a valid local uncertainty scale that preserves conformal prediction coverage guarantees without systematic bias.
What would settle it
A test on the 2D Navier-Stokes benchmark where the perturbation-based conformal bands fail to achieve the target coverage level or are wider than those from baseline methods under the same total data budget.
Figures

read the original abstract
In this paper, we propose a perturbation-based conformal prediction framework for uncertainty quantification in operator learning, with a focus on the 2D Navier--Stokes equations. While neural operators provide fast surrogates for expensive PDE solvers, they do not by themselves provide calibrated uncertainty for spatiotemporal field predictions. Our approach wraps a trained Fourier Neural Operator (FNO) with split conformal prediction and constructs the local uncertainty scale by comparing the predictions of two operators trained on nearly identical datasets: one on the original labels and one on labels perturbed by small Gaussian noise. We consider this procedure in the data-scarce regime, where the total label budget is fixed and methods that require a separate uncertainty network must divide training data between multiple models. On the 2D Navier--Stokes benchmark, the perturbation-based method produces substantially narrower conformal bands than existing methods under matched total data budgets while maintaining the target simultaneous coverage. These results suggest that perturbation sensitivity is a practical and sample-efficient uncertainty proxy for conformalized neural operators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a perturbation-based conformal prediction framework for uncertainty quantification in operator learning for the 2D incompressible Navier-Stokes equations. It wraps a Fourier Neural Operator (FNO) with split conformal prediction, constructing local uncertainty scales by comparing predictions from two FNOs trained on original versus small-Gaussian-perturbed labels. In the data-scarce regime with fixed total label budgets, the method is claimed to yield substantially narrower conformal bands than existing approaches while maintaining target simultaneous coverage on the 2D NS benchmark.
Significance. If the coverage guarantee is preserved, the approach would provide a practical, sample-efficient uncertainty proxy for neural operators that avoids allocating separate data for an uncertainty network, which is valuable for high-dimensional spatiotemporal PDE surrogates where data is expensive. The empirical demonstration on a standard benchmark under matched budgets is a concrete strength.
major comments (2)
- [Abstract] Abstract: the central claim that the perturbation-based method maintains the target simultaneous coverage while producing narrower bands lacks any derivation, proof sketch, or experimental controls showing that the perturbation step preserves the conformal guarantee. The nonconformity scores (absolute differences between the two FNO predictions) are constructed from operators trained on nearly identical datasets, which risks violating the exchangeability assumption required for split conformal prediction marginal coverage.
- [Method] Method section (description of local scale construction): the local uncertainty scale is defined as the absolute difference between predictions of two FNOs trained on original and perturbed labels; no analysis is provided demonstrating that this scale is independent of the perturbation magnitude or that the resulting scores on calibration points remain exchangeable with test points, which is load-bearing for the coverage claim.
minor comments (2)
- [Abstract] The abstract refers to 'simultaneous coverage' without specifying whether this is marginal or joint over the spatiotemporal field; clarify the exact coverage statement and the quantile computation procedure.
- [Method] Notation for the perturbation variance and the two training sets should be introduced with explicit symbols to avoid ambiguity when describing the scale construction.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. The concerns regarding the lack of theoretical justification for coverage preservation and exchangeability are valid points that we address below. We indicate revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the perturbation-based method maintains the target simultaneous coverage while producing narrower bands lacks any derivation, proof sketch, or experimental controls showing that the perturbation step preserves the conformal guarantee. The nonconformity scores (absolute differences between the two FNO predictions) are constructed from operators trained on nearly identical datasets, which risks violating the exchangeability assumption required for split conformal prediction marginal coverage.
Authors: We agree that the manuscript provides no formal derivation or proof sketch establishing that the perturbation step preserves the conformal guarantee. The approach applies the standard split conformal prediction procedure with the nonconformity score defined as the absolute difference between the two FNO predictions. The small Gaussian perturbation is intended to yield a sensitivity-based scale while keeping the two training distributions close. We acknowledge the risk of a mild exchangeability violation due to correlated training sets. In revision we will add a paragraph to the abstract and a short discussion subsection in Methods that supplies a heuristic argument for approximate exchangeability when perturbation variance is small, together with new experiments that vary the perturbation magnitude and report empirical coverage. revision: partial
-
Referee: [Method] Method section (description of local scale construction): the local uncertainty scale is defined as the absolute difference between predictions of two FNOs trained on original and perturbed labels; no analysis is provided demonstrating that this scale is independent of the perturbation magnitude or that the resulting scores on calibration points remain exchangeable with test points, which is load-bearing for the coverage claim.
Authors: The manuscript indeed contains no explicit analysis of dependence on perturbation magnitude or of exchangeability between calibration and test scores. We will revise the Method section to add a sensitivity study that varies the Gaussian perturbation variance, reports resulting coverage rates and band widths, and includes a brief theoretical remark on the conditions under which approximate exchangeability holds for small perturbations. These additions will be supported by additional numerical results on the 2D Navier-Stokes benchmark. revision: yes
- A complete, non-approximate theoretical proof that the perturbation exactly maintains the finite-sample coverage guarantee of split conformal prediction without relaxing the exchangeability assumption.
Circularity Check
No significant circularity; derivation relies on standard conformal prediction applied to an independent perturbation scale.
full rationale
The paper constructs the local uncertainty scale via an external perturbation operation (training a second FNO on Gaussian-perturbed labels and taking the absolute difference) and then applies split conformal prediction in the usual way. This scale is not defined in terms of the calibration residuals or the target coverage quantile, nor is any prediction or coverage claim reduced by construction to a fitted parameter from the same data. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core procedure. The method is therefore self-contained against the external benchmark of exchangeable nonconformity scores under split conformal prediction; any questions about whether the perturbation preserves exchangeability are matters of correctness, not circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- perturbation noise variance
axioms (1)
- domain assumption Perturbation sensitivity between two nearly identical operators supplies a valid local scale for conformal prediction bands
Reference graph
Works this paper leans on
-
[1]
A. N. Angelopoulos and S. Bates. Conformal prediction: A gentle introduction.Founda- tions and Trends in Machine Learning, 16(4):494–591, 2023. arXiv:2107.07511
Pith/arXiv arXiv 2023
-
[2]
R. F. Barber, E. J. Candès, A. Ramdas, and R. J. Tibshirani. Conformal prediction beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023. arXiv:2202.13415
arXiv 2023
-
[3]
C. M. Bishop. Training with noise is equivalent to Tikhonov regularization.Neural Com- putation, 7(1):108–116, 1995
1995
-
[4]
N. Boullé and A. Townsend. A mathematical guide to operator learning. InHandbook of Numerical Analysis, volume 25, pages 83–125. Elsevier, 2024. arXiv:2312.14688
arXiv 2024
- [5]
-
[6]
E. Daxberger, A. Kristiadi, A. Immer, R. Eschenhagen, M. Bauer, and P. Hennig. Laplace Redux—effortless Bayesian deep learning. InAdvances in Neural Information Processing Systems, volume 34, pages 20089–20103, 2021. arXiv:2106.14806
arXiv 2021
-
[7]
Thelimitsofdistribution- free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2):455–482, 2021
R.FoygelBarber, E.J.Candès, A.Ramdas, andR.J.Tibshirani. Thelimitsofdistribution- free conditional predictive inference.Information and Inference: A Journal of the IMA, 10(2):455–482, 2021. 12
2021
-
[8]
Gal and Z
Y. Gal and Z. Ghahramani. Dropout as a Bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Ma- chine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1050–1059. PMLR, 2016
2016
-
[9]
V. Gopakumar, A. Gray, L. Zanisi, T. Nunn, D. Giles, M. Kusner, S. Pamela, and M. P. Deisenroth. Calibrated physics-informed uncertainty quantification. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 20103–20141. PMLR, 2025. arXiv:2502.04406
arXiv 2025
- [10]
-
[11]
Oncalibrationofmodernneuralnetworks
C.Guo, G.Pleiss, Y.Sun, andK.Q.Weinberger. Oncalibrationofmodernneuralnetworks. InProceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 1321–1330. PMLR, 2017
2017
-
[12]
D. Hendrycks and K. Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016
Pith/arXiv arXiv 2016
-
[13]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InInternational Conference on Learning Representations, 2015. arXiv:1412.6980
Pith/arXiv arXiv 2015
-
[14]
N. B. Kovachki, Z. Li, B. Liu, K. Azizzadenesheli, K. Bhattacharya, A. M. Stuart, and A. Anandkumar. Neural operator: Learning maps between function spaces.Journal of Machine Learning Research, 24(89):1–97, 2023. arXiv:2108.08481
arXiv 2023
-
[15]
N. B. Kovachki, S. Lanthaler, and A. M. Stuart. Operator learning: Algorithms and analysis. InHandbook of Numerical Analysis, volume 25, pages 419–467. Elsevier, 2024
2024
-
[16]
Lakshminarayanan, A
B. Lakshminarayanan, A. Pritzel, and C. Blundell. Simple and scalable predictive uncer- tainty estimation using deep ensembles. InAdvances in Neural Information Processing Systems, volume 30, pages 6402–6413, 2017
2017
-
[17]
Lei and L
J. Lei and L. Wasserman. Distribution-free prediction bands for non-parametric regression. Journal of the Royal Statistical Society: Series B, 76(1):71–96, 2014
2014
-
[18]
J. Lei, M. G’Sell, A. Rinaldo, R. J. Tibshirani, and L. Wasserman. Distribution- free predictive inference for regression.Journal of the American Statistical Association, 113(523):1094–1111, 2018
2018
-
[19]
R. J. LeVeque.Finite Volume Methods for Hyperbolic Problems. Cambridge Texts in Applied Mathematics. Cambridge University Press, Cambridge, 2002
2002
-
[20]
Z. Li, N. B. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. M. Stuart, and A. Anandkumar. Fourier neural operator for parametric partial differential equations. In International Conference on Learning Representations, 2021
2021
-
[21]
Q. Li, M. Oprea, L. Wang, and Y. Yang. Stochastic inverse problem: Stability, regulariza- tion and Wasserstein gradient flow.arXiv preprint arXiv:2410.00229, 2024
arXiv 2024
-
[22]
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators.Nature Machine Intelligence, 3(3):218–229, 2021
2021
-
[23]
Z. Ma, D. Pitt, K. Azizzadenesheli, and A. Anandkumar. Calibrated uncertainty quantifi- cation for operator learning via conformal prediction.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. URLhttps://openreview.net/forum?id=cGpegxy12T. 13
2024
-
[24]
D. J. C. MacKay. A practical Bayesian framework for backpropagation networks.Neural Computation, 4(3):448–472, 1992
1992
-
[25]
E. Magnani, N. Krämer, R. Eschenhagen, L. Rosasco, and P. Hennig. Approximate Bayesian neural operators: Uncertainty quantification for parametric PDEs.Transactions on Machine Learning Research, 2025. arXiv:2208.01565
arXiv 2025
-
[26]
A. J. Majda and A. L. Bertozzi.Vorticity and Incompressible Flow. Cambridge Texts in Applied Mathematics. Cambridge University Press, Cambridge, 2002
2002
-
[27]
D. Millard, L. Lindemann, and A. Baheri. Split conformal prediction in the function space with neural operators.arXiv preprint arXiv:2509.04623, 2025
arXiv 2025
-
[28]
R. Molinaro, Y. Yang, B. Engquist, and S. Mishra. Neural inverse operators for solving PDE inverse problems. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 25105–25139. PMLR, 2023. arXiv:2301.11167
arXiv 2023
-
[29]
C. Moya, A. Mollaali, Z. Zhang, L. Lu, and G. Lin. Conformalized-DeepONet: A distribution-free framework for uncertainty quantification in deep operator networks.Phys- ica D: Nonlinear Phenomena, 471:134418, 2025. arXiv:2402.15406
arXiv 2025
-
[30]
N. H. Nelsen and A. M. Stuart. Operator learning using random features: A tool for scientific computing.SIAM Review, 66(3):535–571, 2024
2024
-
[31]
N. H. Nelsen and Y. Yang. Operator learning meets inverse problems: A probabilistic perspective. To appear inHandbook of Numerical Analysis, volume 27:Machine Learning Solutions for Inverse Problems (Part B), Elsevier, 2026. arXiv:2508.20207
arXiv 2026
-
[32]
Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. V. Dillon, B. Lakshmi- narayanan, and J. Snoek. Can you trust your model’s uncertainty? Evaluating predictive uncertainty under dataset shift. InAdvances in Neural Information Processing Systems, volume 32, 2019. arXiv:1906.02530
arXiv 2019
-
[33]
Papadopoulos, K
H. Papadopoulos, K. Proedrou, V. Vovk, and A. Gammerman. Inductive confidence ma- chines for regression. InMachine Learning: ECML 2002, volume 2430 ofLecture Notes in Computer Science, pages 345–356. Springer, 2002
2002
-
[34]
Quarteroni, R
A. Quarteroni, R. Sacco, and F. Saleri.Numerical Mathematics. Texts in Applied Mathe- matics, volume 37. Springer, Berlin, 2000
2000
-
[35]
Ritter, A
H. Ritter, A. Botev, and D. Barber. A scalable Laplace approximation for neural networks. InInternational Conference on Learning Representations, 2018
2018
-
[36]
Conformalizedquantileregression
Y.Romano, E.Patterson, andE.J.Candès. Conformalizedquantileregression. InAdvances in Neural Information Processing Systems, volume 32, 2019. arXiv:1905.03222
Pith/arXiv arXiv 2019
-
[37]
U. Subedi and A. Tewari. Controlling statistical, discretization, and truncation errors in learning Fourier linear operators.Transactions on Machine Learning Research, 2025. arXiv:2408.09004
arXiv 2025
-
[38]
U. Subedi and A. Tewari. Operator learning: A statistical perspective.Annual Review of Statistics and Its Application, 13:123–148, 2026. arXiv:2504.03503
arXiv 2026
-
[39]
Temam.Navier–Stokes Equations: Theory and Numerical Analysis
R. Temam.Navier–Stokes Equations: Theory and Numerical Analysis. AMS Chelsea Publishing, Providence, RI, 2001. Reprint of the 1984 edition. 14
2001
-
[40]
R. J. Tibshirani, R. Foygel Barber, E. J. Candès, and A. Ramdas. Conformal prediction under covariate shift. InAdvances in Neural Information Processing Systems, volume 32,
-
[41]
L. N. Trefethen.Spectral Methods in MATLAB. SIAM, Philadelphia, 2000
2000
-
[42]
T. van Leeuwen and Y. Yang. An analysis of constraint-relaxation in PDE-based inverse problems.Inverse Problems, 41(2):025009, 2025. arXiv:2403.15292
arXiv 2025
-
[43]
V. Vovk, A. Gammerman, and G. Shafer.Algorithmic Learning in a Random World. Springer, New York, 2005
2005
-
[44]
N. Winovich, M. Daneker, L. Lu, and G. Lin. Active operator learning with predictive un- certaintyquantificationforpartialdifferentialequations.Journal of Computational Physics, 555:114791, 2026. arXiv:2503.03178
arXiv 2026
-
[45]
Y. Yu, C. H. Ho, and Y. Wang. A conformal prediction framework for uncertainty quan- tification in physics-informed neural networks.arXiv preprint arXiv:2509.13717, 2025. 15
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.