Latent Diffusion Policy: Shaping Latent Spaces for Diffusion-Based Robotic Manipulation
Pith reviewed 2026-06-27 18:26 UTC · model grok-4.3
The pith
Shaping a latent space with a CVAE encoder lets diffusion policies separate scene understanding from trajectory generation for better multi-arm coordination.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
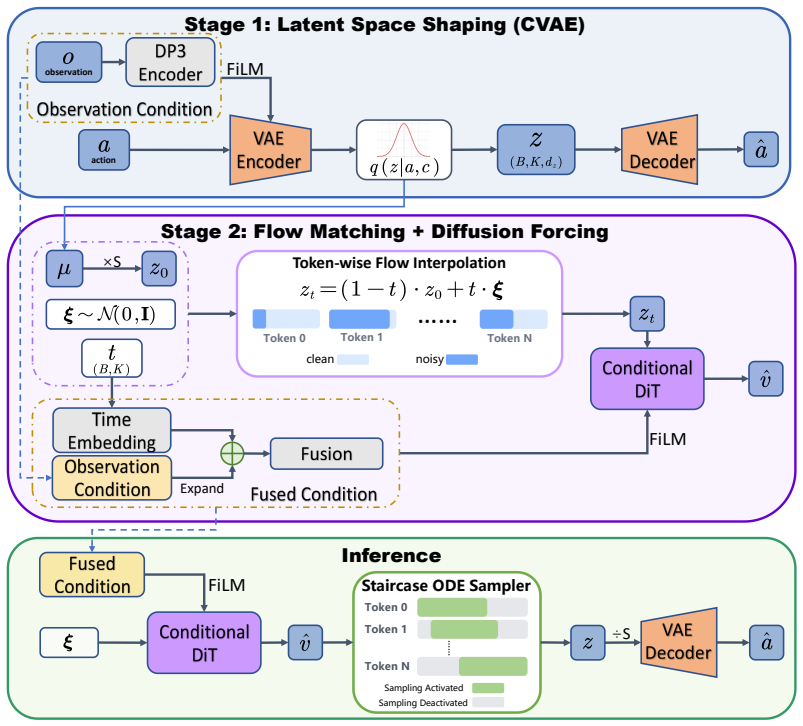
Latent Diffusion Policy (LDP) is a two-stage framework that absorbs scene understanding into an observation-conditioned CVAE encoder to concentrate the conditional distribution, allowing the flow model to generate trajectories within a pre-concentrated space with a smoother velocity field, while using per-token diffusion forcing and staircase inference sampling to capture temporal dependencies among latent tokens.
What carries the argument
The observation-conditioned CVAE encoder that shapes the latent space by concentrating the conditional distribution of each observation for subsequent flow matching.
If this is right
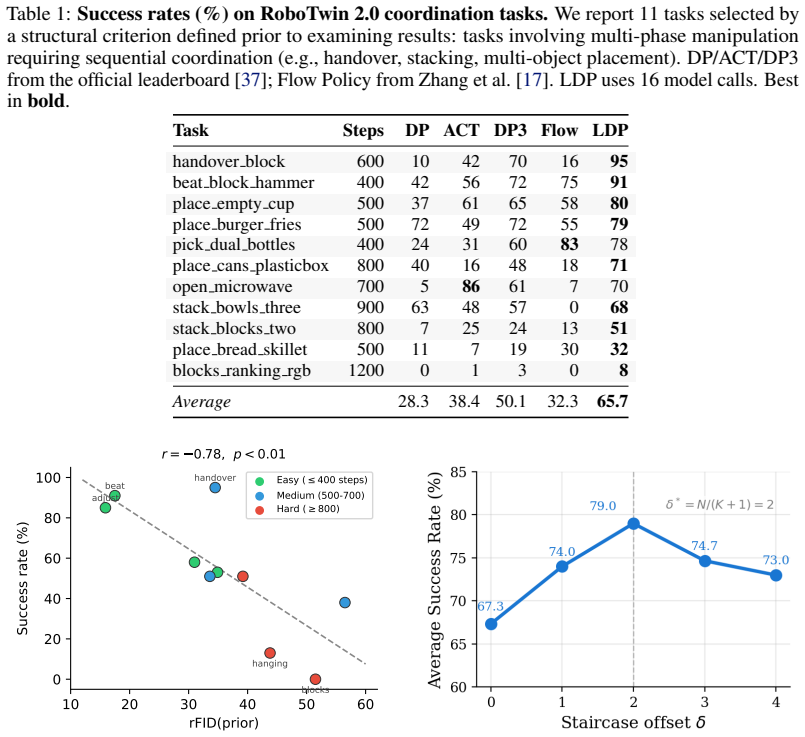
- On coordination-intensive tasks from RoboTwin 2.0, LDP outperforms DP3 by a substantial margin.
- LDP transfers effectively to real-world bimanual deployments.
- rFID serves as a lightweight proxy that predicts downstream task success from latent space statistics alone.
- The framework simplifies learning from limited demonstrations by avoiding the need for the flow model to resolve scene-dependent structures.
Where Pith is reading between the lines
- This latent shaping approach could reduce the number of demonstrations needed for training effective policies on new tasks.
- The separation of concerns might extend to other diffusion-based models in robotics or sequential decision making.
- Staircase inference sampling could be tested on other models that use per-token diffusion to see if it resolves similar mismatches.
- rFID might be useful as an evaluation metric in other latent space learning setups for robotics.
Load-bearing premise
The observation-conditioned CVAE encoder can absorb scene understanding such that the conditional distribution is sufficiently concentrated to produce a smoother velocity field without losing information needed for precise trajectory generation.
What would settle it
A direct comparison on RoboTwin 2.0 coordination tasks showing no substantial outperformance by LDP over DP3 would falsify the central performance claim.
Figures


read the original abstract
Diffusion-based visuomotor policies operating directly in raw action spaces conflate scene comprehension with trajectory generation within a single denoising process. The resulting velocity field must simultaneously encode scene information and generate precise trajectories, increasing learning complexity and limiting performance on tasks demanding precise temporal coordination across multiple arms. To simplify this joint learning problem, we introduce Latent Diffusion Policy (LDP), a two-stage framework performing flow matching in a deliberately shaped latent space. By absorbing scene understanding into an observation-conditioned CVAE encoder, LDP concentrates the conditional distribution of each observation. Consequently, the flow model avoids implicitly resolving scene-dependent structures; instead, it generates within a pre-concentrated distribution featuring a smoother velocity field, simplifying learning from limited demonstrations. Furthermore, to capture temporal dependencies among latent tokens, LDP trains with per-token diffusion forcing and employs staircase inference sampling to resolve the resulting distributional mismatch. We also propose reconstruction FID (rFID) as a lightweight proxy predicting downstream task success solely from latent space statistics. On coordination-intensive tasks from RoboTwin 2.0, LDP outperforms DP3 by a substantial margin and transfers effectively to real-world bimanual deployments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Latent Diffusion Policy (LDP), a two-stage framework for diffusion-based robotic manipulation policies. It performs flow matching in a latent space shaped by an observation-conditioned CVAE encoder that absorbs scene understanding to concentrate the conditional distribution and produce a smoother velocity field. Additional components include per-token diffusion forcing and staircase inference sampling to address temporal dependencies and distributional mismatch among latent tokens. A new proxy metric, reconstruction FID (rFID), is introduced to predict downstream task success from latent statistics alone. The central empirical claim is that LDP substantially outperforms DP3 on coordination-intensive tasks from RoboTwin 2.0 and transfers effectively to real-world bimanual deployments.
Significance. If the empirical gains prove robust and the information-preservation assumption holds, the approach of decoupling scene comprehension from trajectory generation via latent-space shaping could improve sample efficiency and performance for multi-arm visuomotor policies on complex coordination tasks.
major comments (2)
- [Abstract] Abstract: the claim that LDP 'outperforms DP3 by a substantial margin' on RoboTwin 2.0 coordination tasks is presented without any quantitative numbers, ablation results, error bars, or implementation details, so the magnitude and statistical reliability of the reported improvement cannot be assessed.
- [Abstract] Abstract and method description: the load-bearing assumption that the observation-conditioned CVAE concentrates the conditional distribution 'without loss of information required for precise trajectory generation' is stated but unsupported by any reported reconstruction metrics, correlation between rFID and coordination error, or ablation isolating the CVAE contribution from per-token diffusion forcing and staircase sampling.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract and the central modeling assumption. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that LDP 'outperforms DP3 by a substantial margin' on RoboTwin 2.0 coordination tasks is presented without any quantitative numbers, ablation results, error bars, or implementation details, so the magnitude and statistical reliability of the reported improvement cannot be assessed.
Authors: We agree that the abstract should contain quantitative support for the performance claim. In the revised manuscript we will update the abstract to report the specific success rates (with standard deviations) on the RoboTwin 2.0 coordination tasks, note the number of evaluation seeds, and briefly reference the key ablation findings and implementation details that appear in the experimental section. revision: yes
-
Referee: [Abstract] Abstract and method description: the load-bearing assumption that the observation-conditioned CVAE concentrates the conditional distribution 'without loss of information required for precise trajectory generation' is stated but unsupported by any reported reconstruction metrics, correlation between rFID and coordination error, or ablation isolating the CVAE contribution from per-token diffusion forcing and staircase sampling.
Authors: The referee correctly identifies that the current manuscript does not supply the requested supporting analyses. We will add (i) quantitative reconstruction metrics for the CVAE, (ii) a correlation study between rFID and observed coordination error, and (iii) an ablation that isolates the CVAE stage from per-token diffusion forcing and staircase sampling. These additions will be placed in the experimental section and referenced from the abstract and method description. revision: yes
Circularity Check
No circularity: new two-stage architecture with independent CVAE shaping and rFID proxy
full rationale
The derivation chain introduces a structural separation (CVAE encoder for scene absorption followed by flow matching in the resulting latent space) plus per-token diffusion forcing, staircase sampling, and the novel rFID metric. These are presented as design choices rather than reductions of prior results to fitted parameters or self-citations. No equations equate a claimed prediction to its own input by construction, and the outperformance claim on RoboTwin 2.0 is framed as an empirical outcome, not a tautology. The central assumption about information preservation is acknowledged as unverified in the skeptic note but does not trigger any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Flow matching in a CVAE-compressed latent space produces a smoother velocity field than direct action-space diffusion
invented entities (1)
-
reconstruction FID (rFID)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023
2023
-
[2]
Y . Ze, G. Yan, Y . Wu, A. Macaluso, Y . Ge, J. Ye, N. Hansen, L. E. Li, and X. Xu. 3D diffusion policy: Generalizable visuomotor policy learning via simple 3d representations. InRobotics: Science and Systems (RSS), 2024
2024
-
[3]
Janner, Y
M. Janner, Y . Du, J. Tenenbaum, and S. Levine. Planning with diffusion for flexible behavior synthesis. InInternational Conference on Machine Learning (ICML), 2022
2022
-
[4]
A. Ajay, Y . Du, A. Gupta, J. Tenenbaum, T. Jaakkola, and P. Agrawal. Is conditional gener- ative modeling all you need for decision making? InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[5]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[6]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson. Implicit behavioral cloning. InConference on Robot Learning (CoRL), 2022
2022
-
[7]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[8]
Heusel, H
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium, 2018
2018
-
[9]
B. Chen, D. Marti Monso, Y . Du, M. Simchowitz, R. Tedrake, and V . Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffusion. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[10]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[11]
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[12]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[13]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023
2023
-
[14]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS), 2024
2024
-
[15]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. RDT-1B: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[16]
Prasad, K
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation. InRobotics: Science and Systems (RSS), 2024. 9
2024
-
[17]
Zhang, Z
Q. Zhang, Z. Liu, H. Fan, G. Liu, B. Zeng, and S. Liu. Flowpolicy: Enabling fast and robust 3D flow-based policy via consistency flow matching for robot manipulation. InAAAI Conference on Artificial Intelligence, volume 39, pages 14754–14762, 2025
2025
-
[18]
J. Zhang, Z. Zhou, H. Li, W. Xia, H. Song, Y . Gong, Y . Lai, and J. Mei. Hydra-DP3: Frequency-aware right-sizing of 3D diffusion policies for visuomotor control.arXiv preprint arXiv:2605.01581, 2026
Pith/arXiv arXiv 2026
-
[19]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023
2023
-
[20]
S. Lee, Y . Wang, H. Erickson, B. Eysenbach, and C. Finn. Behavior generation with latent actions. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[21]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems (NeurIPS), 2017
2017
-
[22]
T.-W. Ke, N. Gkanatsios, and K. Fragkiadaki. 3D diffuser actor: Policy diffusion with 3D scene representations. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[23]
V osylius and W
V . V osylius and W. W. Mayol-Cuevas. Render and diffuse: Aligning image and action spaces for diffusion-based behaviour cloning. InRobotics: Science and Systems (RSS), 2024
2024
-
[24]
S. Wang, J. Zheng, Y . Park, K. Pertsch, and S. Levine. Latent action pretraining from videos. arXiv preprint arXiv:2410.11758, 2024
Pith/arXiv arXiv 2024
-
[25]
J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[26]
Y . Song, P. Dhariwal, M. Chen, and I. Sutskever. Consistency models. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[27]
Reuss, M
M. Reuss, M. Li, X. Jia, and R. Lioutikov. Goal-conditioned imitation learning using score-based diffusion policies. InRobotics: Science and Systems (RSS), 2023
2023
-
[28]
S. S. Sahoo, M. Arriola, D. Schuurmans, and M. Kazemi. Simple and effective masked diffusion language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[29]
Y . Du, B. Chen, M. Simchowitz, R. Tedrake, and V . Sitzmann. Mercury: A code-efficient approach to discrete diffusion language modeling.arXiv preprint arXiv:2502.01672, 2025
arXiv 2025
-
[30]
D. A. Pomerleau. Efficient training of artificial neural networks for autonomous navigation. Neural Computation, 3(1):88–97, 1991
1991
-
[31]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots. InRobotics: Science and Systems (RSS), 2024
2024
-
[32]
Lipman, R
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[33]
X. Liu, C. Gong, and Q. Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[34]
Y . Lipman, R. T. Chen, H. Ben-Hamu, and M. Nickel. Flow matching guide and code.arXiv preprint arXiv:2412.06264, 2024
Pith/arXiv arXiv 2024
-
[35]
C. R. Qi, L. Yi, H. Su, and L. J. Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. InAdvances in Neural Information Processing Systems (NeurIPS), 2017. 10
2017
-
[36]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[37]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Q. Liang, Z. Li, X. Lin, Y . Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025. A Implementation Details A.1 CV AE Architecture Table 4: CV AE hyperparameters. Parameter Value Act...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.