Seeing the Hivemind: A Consensus-Aware Interaction Technique for Mitigating AI Homogenization
Pith reviewed 2026-06-27 14:58 UTC · model grok-4.3
The pith
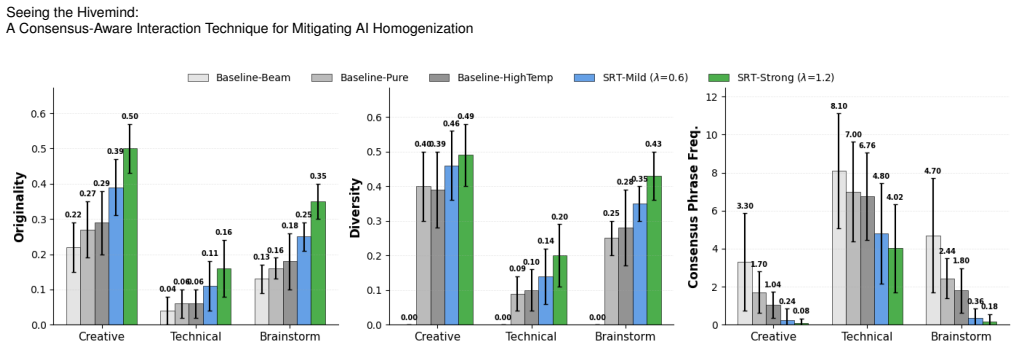
The Semantic Repulsion Technique raises semantic diversity in AI creative outputs by 85-167% and earns higher user ratings for usefulness and coherence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
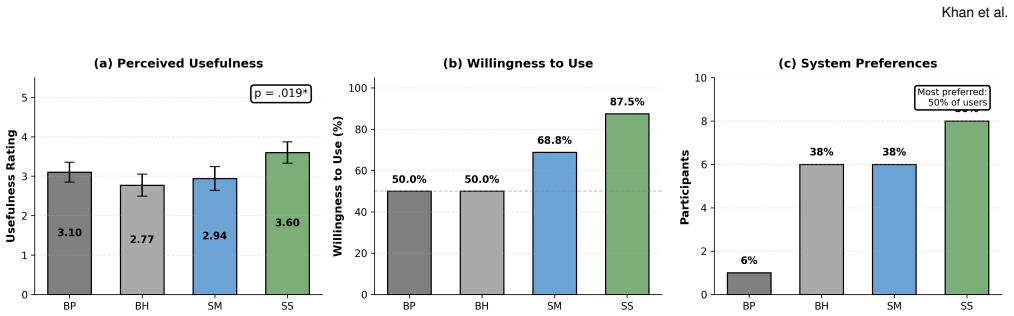
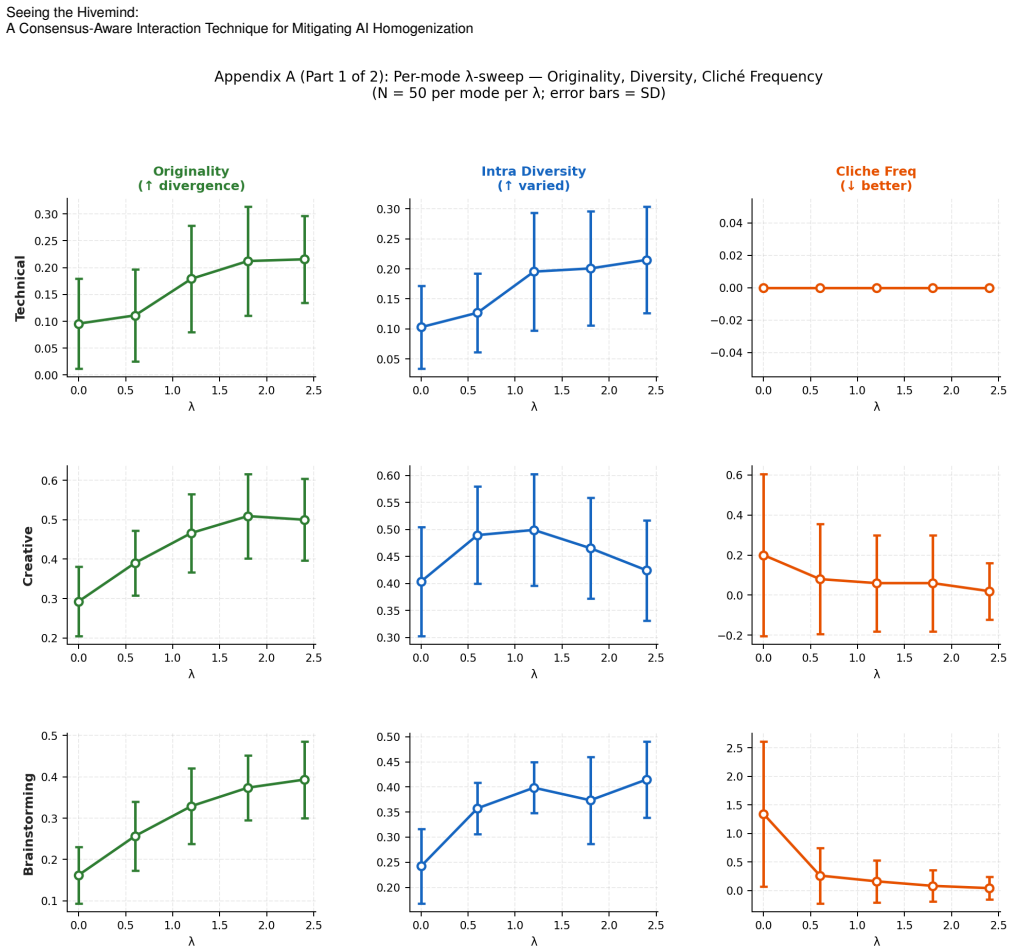
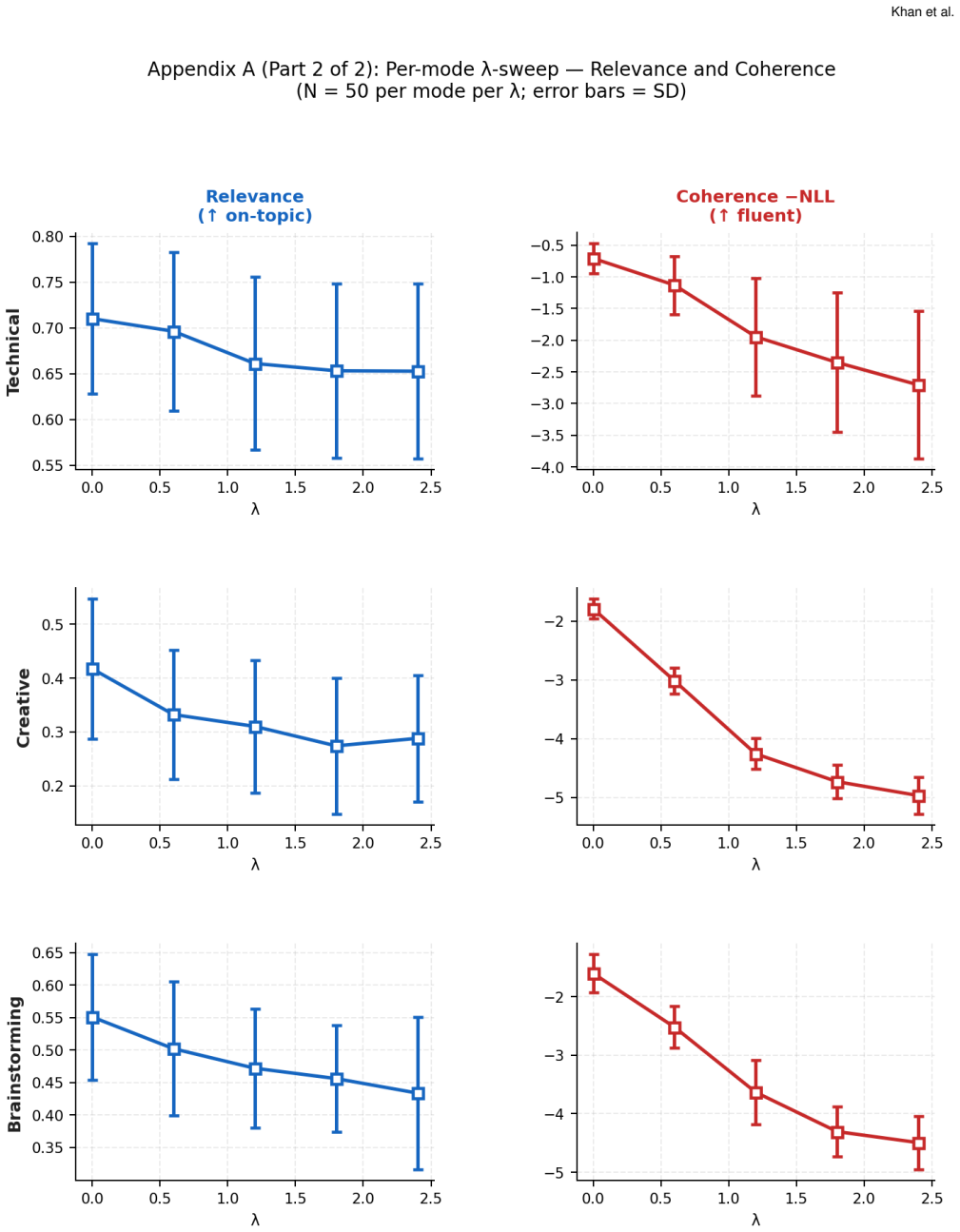
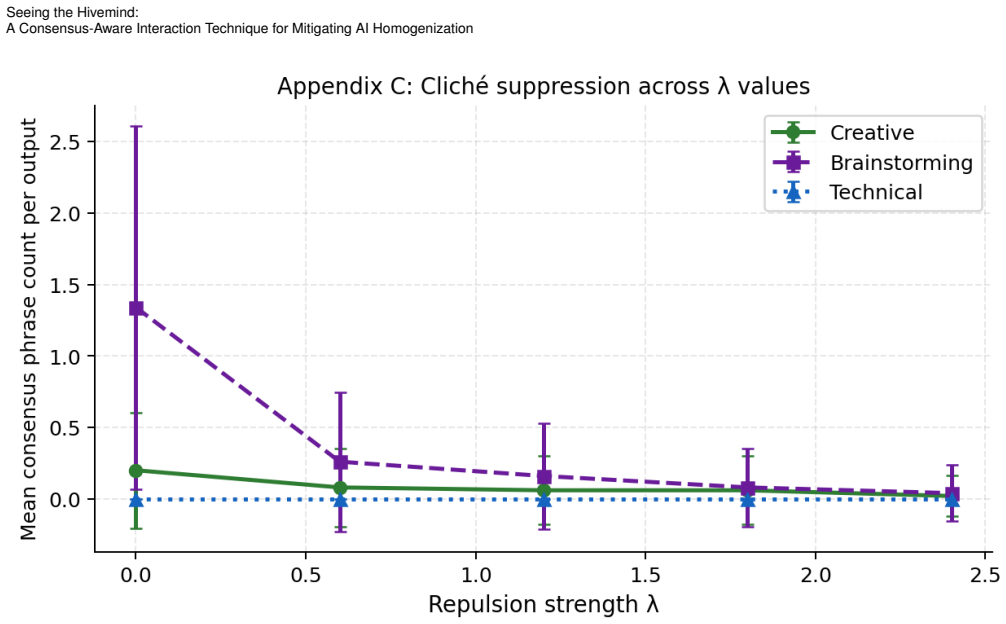
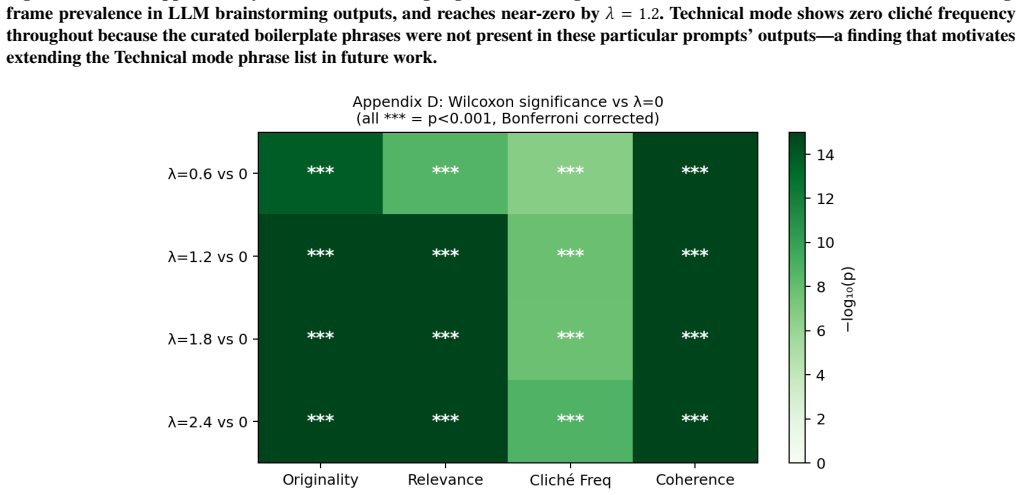
SRT is a consensus-aware interaction method that detects shared phrases across AI responses and applies repulsion to produce more varied text. Tests show it lifts semantic diversity 85-167% and cuts consensus phrases 43-95%. In the study, SRT outputs scored higher on usefulness and coherence, originality and coherence ratings correlated positively, and 68.8% of participants said they would use the strong SRT version for multiple tasks compared with 18.8% for standard baselines.
What carries the argument
Semantic Repulsion Technique (SRT), which detects consensus phrases in AI-generated text and steers new outputs away from them to increase variety while preserving readability.
If this is right
- AI writing systems equipped with SRT can deliver outputs rated more useful and coherent than current baselines.
- Divergence from consensus need not reduce readability, since originality and coherence ratings rise together.
- Most users in the study expressed willingness to adopt SRT-Strong for repeated creative tasks.
- The same repulsion approach can be applied across different creative writing task modes.
Where Pith is reading between the lines
- If SRT scales, mainstream AI writing assistants could incorporate it by default to slow the spread of uniform phrasing in education and publishing.
- Similar consensus-repulsion logic might extend to image or code generation tools where output sameness is also a concern.
- Over longer periods, widespread SRT use could preserve more distinct voices in collaborative or iterative writing projects.
- Testing SRT in group settings rather than solo tasks would show whether it reduces convergence when multiple people share the same AI.
Load-bearing premise
Short-term gains in diversity metrics and preference ratings from a small study will translate into reduced homogenization of creative output at individual or societal scale.
What would settle it
A multi-month field study that measures the actual range of ideas and phrasing in users' published or shared writing before and after switching to SRT versus standard AI.
Figures


read the original abstract
People are increasingly using AI for creative tasks such as writing. While adoption continues to grow, this form of use risks undermining individual creativity locally and reducing the heterogeneity of creative output at scale. In response, we introduce the Semantic Repulsion Technique (SRT) and evaluate it both computationally and through a study with 16 participants who regularly use AI for creative tasks. Our computational assessment reveals that SRT increases semantic diversity by 85--167\% while reducing consensus phrases by 43--95\% across task modes. In the user study, SRT outputs received higher usefulness ($p = .019$, $W = .208$) and coherence ratings ( $p = .006$, $W = .260$); 68.8\% of participants were willing to use SRT-Strong for multiple tasks versus 18.8\% for baselines. Originality and coherence ratings were positively correlated across all systems ($\rho = +.40$ to $+.67$), suggesting that divergence need not compromise readability. Taken together, these preliminary findings can inform the design of AI systems that aim to support everyday creativity without contributing to homogenization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Semantic Repulsion Technique (SRT), a consensus-aware interaction method for AI-assisted creative tasks such as writing. It claims that SRT mitigates AI-driven homogenization by increasing semantic diversity (85--167%) and reducing consensus phrases (43--95%) in computational assessments across task modes, while a 16-participant user study shows SRT outputs rated higher on usefulness (p = .019, W = .208) and coherence (p = .006, W = .260), with 68.8% of participants willing to reuse SRT-Strong versus 18.8% for baselines. Originality and coherence ratings correlate positively ( ho = +.40 to +.67). The authors position these preliminary results as informing the design of AI systems that support creativity without contributing to homogenization.
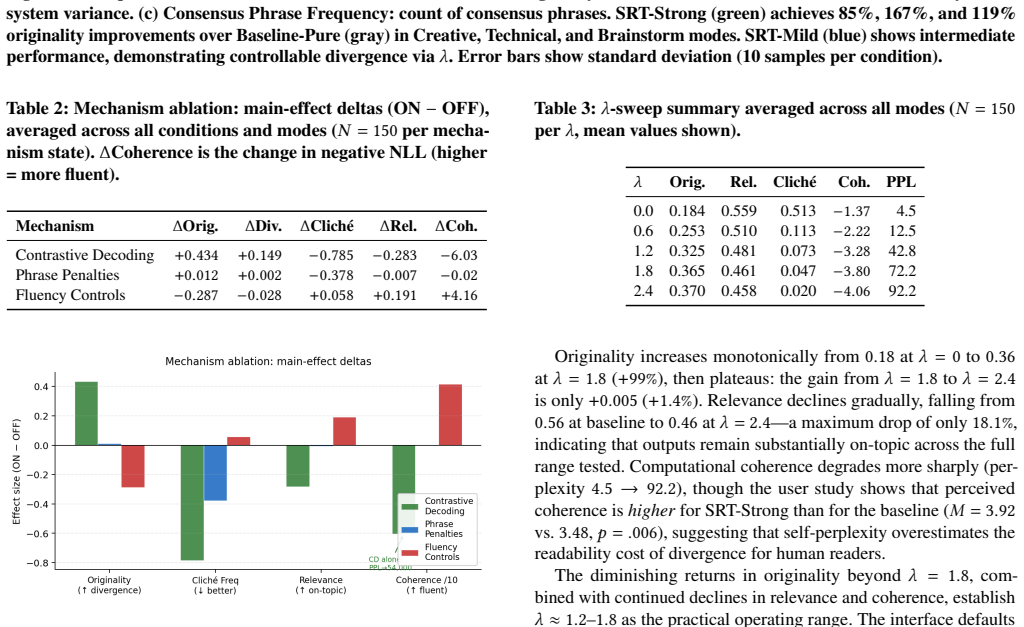
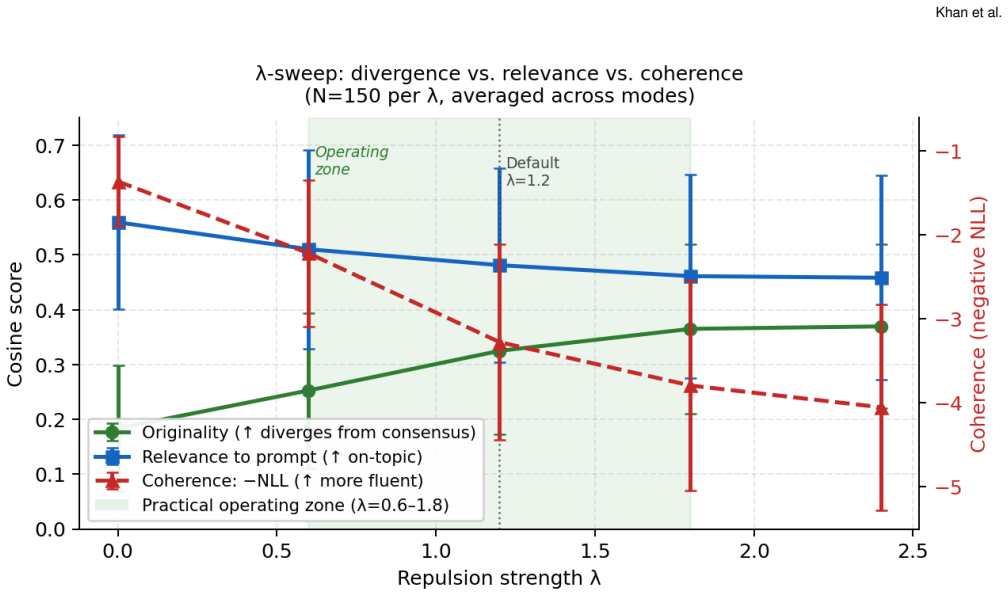
Significance. If the reported effects hold under more rigorous evaluation, the work provides an actionable technique for increasing output diversity in AI creative tools while preserving or improving perceived quality metrics. The correlation between originality and coherence is a constructive observation that challenges assumptions about trade-offs in divergence. This could be relevant for HCI research on creativity support tools. The significance remains limited, however, because the evidence addresses only single-output diversity and immediate preferences rather than longitudinal or aggregate homogenization effects.
major comments (2)
- [Abstract] Abstract: The central claim that SRT mitigates homogenization of creative output at individual or societal scale rests on an untested causal mapping; the computational metrics and user study establish only per-output diversity gains and short-term preference, with no longitudinal tracking of individual creative trajectories or aggregation across users.
- [User study] User study results: The reported statistical outcomes (p = .019, W = .208; p = .006, W = .260) and reuse willingness percentages (68.8% vs 18.8%) are presented as support for the homogenization-mitigation claim, yet the 16-participant sample, unspecified baselines, and absence of method details prevent verification that these local preference gains translate to reduced homogenization.
minor comments (2)
- [Abstract] Abstract: The ranges 85--167% and 43--95% should be accompanied by the specific task modes or conditions measured to allow readers to interpret the computational assessment.
- The manuscript would benefit from an explicit limitations paragraph addressing the gap between single-output metrics and scale-level homogenization effects.
Simulated Author's Rebuttal
Thank you for the constructive review. We address the major comments point by point below, acknowledging the preliminary nature of the evidence and proposing targeted revisions for clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that SRT mitigates homogenization of creative output at individual or societal scale rests on an untested causal mapping; the computational metrics and user study establish only per-output diversity gains and short-term preference, with no longitudinal tracking of individual creative trajectories or aggregation across users.
Authors: We agree that the work provides no longitudinal or aggregate-scale evidence and does not test causal effects beyond per-output metrics. The abstract already qualifies the results as 'preliminary findings' that 'can inform the design' rather than claiming proven mitigation at scale. To prevent misinterpretation, we will revise the abstract to explicitly state the absence of longitudinal tracking and the per-output focus of the reported gains. revision: yes
-
Referee: [User study] User study results: The reported statistical outcomes (p = .019, W = .208; p = .006, W = .260) and reuse willingness percentages (68.8% vs 18.8%) are presented as support for the homogenization-mitigation claim, yet the 16-participant sample, unspecified baselines, and absence of method details prevent verification that these local preference gains translate to reduced homogenization.
Authors: The n=16 study is described as preliminary in the manuscript. We will expand the methods section with explicit baseline descriptions (standard AI prompting without SRT) and additional procedural details to improve verifiability. The reported statistics and reuse rates demonstrate user preference for SRT outputs on usefulness and coherence; these are presented separately from the computational diversity results. We will revise the discussion to clarify that preference data do not directly demonstrate long-term homogenization reduction. revision: partial
- Absence of longitudinal tracking of individual creative trajectories or aggregation across users to support claims of mitigation at individual or societal scale
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces SRT as a technique and supports its claims solely through direct computational metrics on generated outputs (semantic diversity, consensus phrases) plus a separate 16-participant user study reporting preference ratings. No equations, parameters, or uniqueness theorems are defined in terms of the target outcomes; no fitted inputs are relabeled as predictions; no self-citations form the load-bearing justification. The mapping from per-output statistics to reduced homogenization is an interpretive claim about external validity, not a definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. 2024. Homog- enization Effects of Large Language Models on Human Creative Ideation. In Proceedings of the 16th Conference on Creativity & Cognition(Chicago, IL, USA)(C&C ’24). Association for Computing Machinery, New York, NY , USA, 413–425. doi:10.1145/3635636.3656204
-
[2]
Anthropic. 2024. Claude 3 Haiku: our fastest model yet. (2024). https://www. anthropic.com/news/claude-3-haiku Accessed: 2025-12-17
2024
-
[3]
Virginia Braun and Victoria Clarke. 2006. Using thematic analy- sis in psychology.Qualitative Research in Psychology3, 2 (2006), 77–101. arXiv:https://doi.org/10.1191/1478088706qp063oa doi:10.1191/ 1478088706qp063oa
-
[4]
Ricardo Campos, Vítor Mangaravite, Arian Pasquali, Alípio Jorge, Célia Nunes, and Adam Jatowt. 2020. YAKE! Keyword extraction from single documents using multiple local features.Information Sciences509 (2020), 257–289
2020
-
[5]
Liuqing Chen, Yaxuan Song, Chunyuan Zheng, Qianzhi Jing, Preben Hansen, and Lingyun Sun. 2025. Understanding Design Fixation in Generative AI. arXiv:2502.05870 [cs.HC] https://arxiv.org/abs/2502.05870
arXiv 2025
-
[6]
Anil R. Doshi and Oliver P. Hauser. 2024. Generative AI en- hances individual creativity but reduces the collective diversity of novel content.Science Advances10, 28 (2024), eadn5290. arXiv:https://www.science.org/doi/pdf/10.1126/sciadv.adn5290 doi:10.1126/ sciadv.adn5290
-
[7]
near” and “far
Katherine Fu, Joel Chan, Jonathan Cagan, Kenneth Kotovsky, Christian Schunn, and Kristin Wood. 2013. The meaning of “near” and “far”: the impact of struc- turing design databases and the effect of distance of analogy on design output. Journal of Mechanical Design135, 2 (2013), 021007
2013
-
[8]
Xijin Ge. 2025. DataMap: A Portable Application for Visualizing High- Dimensional Data. arXiv:2504.08875 [q-bio.QM] https://arxiv.org/abs/2504. 08875
arXiv 2025
-
[9]
Kazjon Grace and Mary Lou Maher. 2019. Expectation-based models of novelty for evaluating computational creativity. InComputational creativity: The philoso- phy and engineering of autonomously creative systems. Springer, 195–209
2019
-
[10]
Nitin Gupta, Yoonhee Jang, Sara C Mednick, and David E Huber. 2012. The road not taken: Creative solutions require avoidance of high-frequency responses. Psychological science23, 3 (2012), 288–294
2012
-
[11]
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. 2019. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751(2019)
Pith/arXiv arXiv 2019
-
[12]
Liwei Jiang, Yuanjun Chai, Margaret Li, Mickel Liu, Raymond Fok, Nouha Dziri, Yulia Tsvetkov, Maarten Sap, Alon Albalak, and Yejin Choi. 2025. Artificial Hivemind: The Open-Ended Homogeneity of Language Models (and Beyond). arXiv:2510.22954 [cs.CL] https://arxiv.org/abs/2510.22954
arXiv 2025
-
[13]
Jingoog Kim and Mary Lou Maher. 2023. The effect of AI-based inspiration on human design ideation.International Journal of Design Creativity and Innovation 11, 2 (2023), 81–98
2023
-
[14]
Taewook Kim, Matthew Kay, Yuqian Sun, Melissa Roemmele, Max Kreminski, and John Joon Young Chung. 2025. Scaffolding Recursive Divergence and Convergence in Story Ideation. arXiv:2507.03307 [cs.HC] https://arxiv.org/abs/ 2507.03307
arXiv 2025
-
[15]
Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori B Hashimoto, Luke Zettlemoyer, and Mike Lewis. 2023. Contrastive decoding: Open-ended text generation as optimization. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: Long papers). 12286–12312
2023
-
[16]
Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. 2021. DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts. arXiv:2105.03023 [cs.CL] https: //arxiv.org/abs/2105.03023
arXiv 2021
-
[17]
Shusen Liu, Dan Maljovec, Bei Wang, Peer-Timo Bremer, and Valerio Pascucci
-
[18]
Visualizing high-dimensional data: Advances in the past decade.IEEE transactions on visualization and computer graphics23, 3 (2016), 1249–1268
2016
-
[19]
Leland McInnes, John Healy, and James Melville. 2018. Umap: Uniform man- ifold approximation and projection for dimension reduction.arXiv preprint arXiv:1802.03426(2018)
Pith/arXiv arXiv 2018
-
[20]
Leland McInnes, John Healy, Nathaniel Saul, and Lukas Großberger. 2018. UMAP: Uniform Manifold Approximation and Projection.Journal of Open Source Software3, 29 (2018), 861. doi:10.21105/joss.00861
-
[21]
Meta. 2024. Llama 3. https://arxiv.org/abs/2407.21783 Accessed: 2025-12-17
Pith/arXiv arXiv 2024
-
[22]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774 (2023)
Pith/arXiv arXiv 2023
-
[23]
Janet Rafner, Blanka Zana, Ida Bang Hansen, Simon Ceh, Jacob Sherson, Mathias Benedek, and Izabela Lebuda. 2025. Agency in Human-AI Col- laboration for Image Generation and Creative Writing: Preliminary Insights from Think-Aloud Protocols.Creativity Research Journal0, 0 (2025), 1–24. arXiv:https://doi.org/10.1080/10400419.2025.2587803 doi:10.1080/10400419...
-
[24]
Ben Shneiderman. 2007. Creativity support tools: accelerating discovery and innovation.Commun. ACM50, 12 (Dec. 2007), 20–32. doi:10.1145/1323688. 1323689
-
[25]
Taylor Sorensen, Jared Moore, Jillian Fisher, Mitchell Gordon, Niloofar Mireshghallah, Christopher Michael Rytting, Andre Ye, Liwei Jiang, Ximing Lu, Nouha Dziri, Tim Althoff, and Yejin Choi. 2024. A Roadmap to Pluralistic Alignment. arXiv:2402.05070 [cs.AI] https://arxiv.org/abs/2402.05070
Pith/arXiv arXiv 2024
-
[26]
Sangho Suh, Meng Chen, Bryan Min, Toby Jia-Jun Li, and Haijun Xia. 2024. Luminate: Structured Generation and Exploration of Design Space with Large Language Models for Human-AI Co-Creation. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems(Honolulu, HI, USA)(CHI ’24). Association for Computing Machinery, New York, NY , USA, Ar...
-
[27]
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. 2019. Neural Text Generation with Unlikelihood Training. arXiv:1908.04319 [cs.LG] https://arxiv.org/abs/1908.04319
arXiv 2019
-
[28]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tianyi T...
Pith/arXiv arXiv 2025
-
[29]
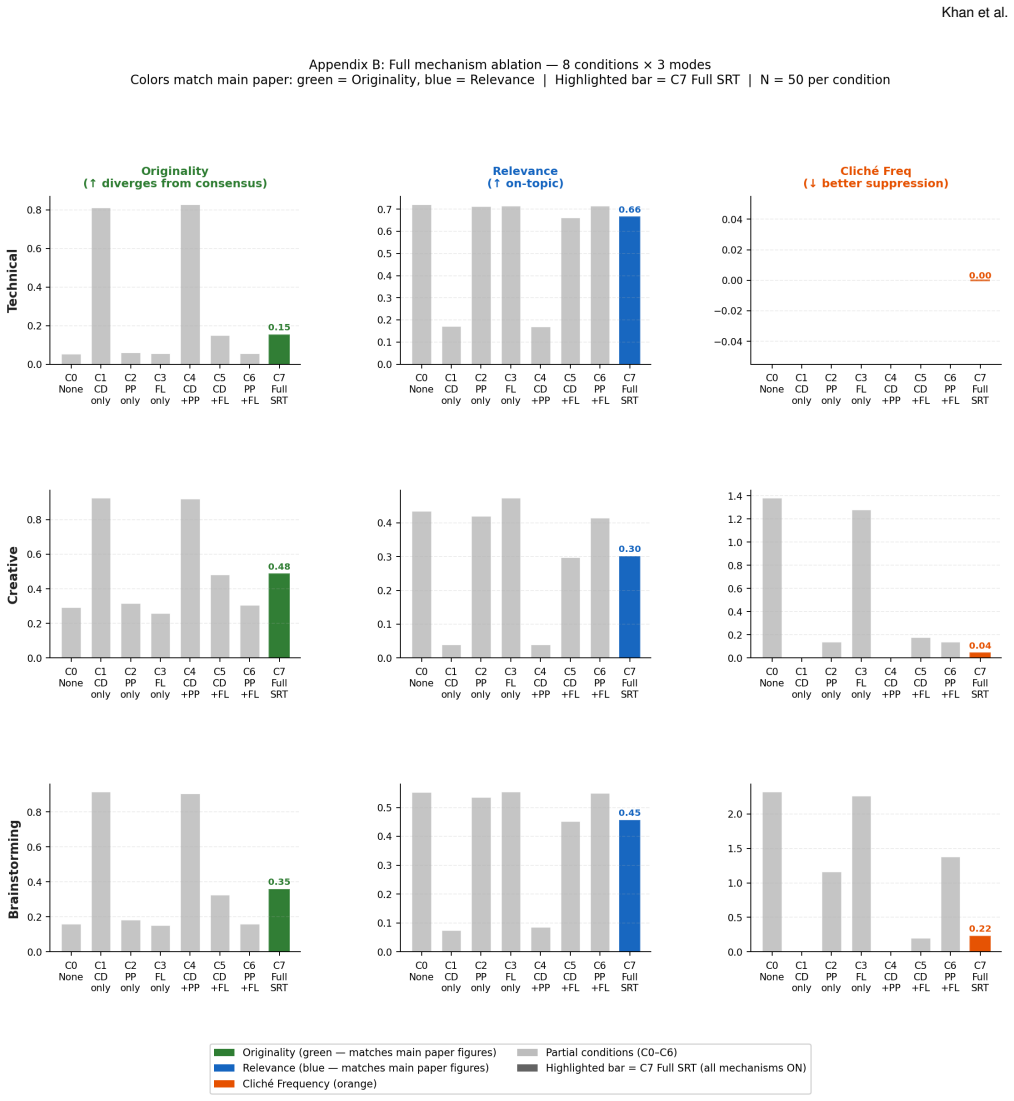
Jiayi Zhang, Simon Yu, Derek Chong, Anthony Sicilia, Michael R. Tomz, Christo- pher D. Manning, and Weiyan Shi. 2025. Verbalized Sampling: How to Mit- igate Mode Collapse and Unlock LLM Diversity. arXiv:2510.01171 [cs.CL] https://arxiv.org/abs/2510.01171 A Experiment 2: Full Ablation Results This appendix reports the complete 8-condition ablation results ...
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.