Muon Learns More Robust and Transferable Features than Adam
Pith reviewed 2026-06-27 17:06 UTC · model grok-4.3
The pith
Muon optimizer learns features with larger margins and higher effective rank than Adam or SGD.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
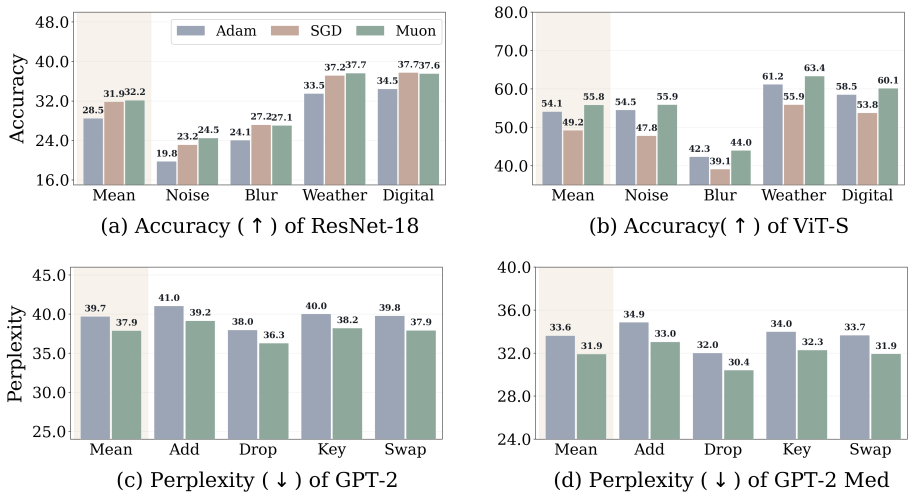
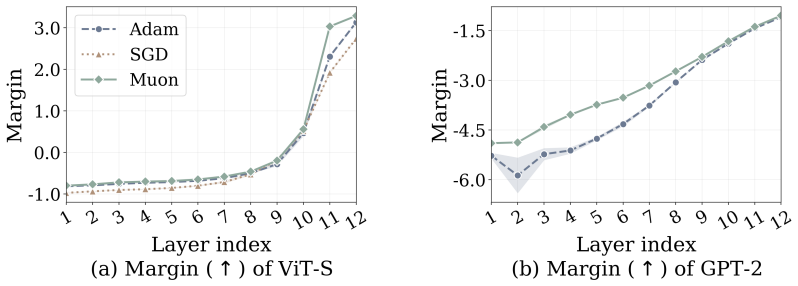
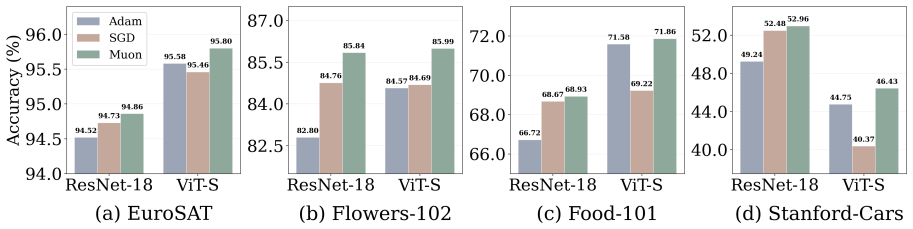
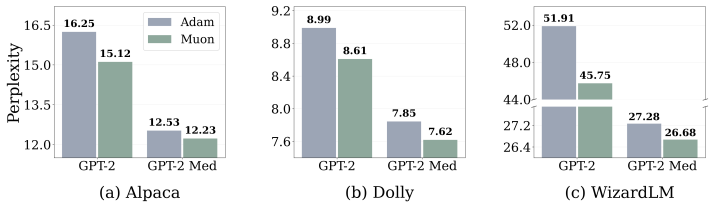
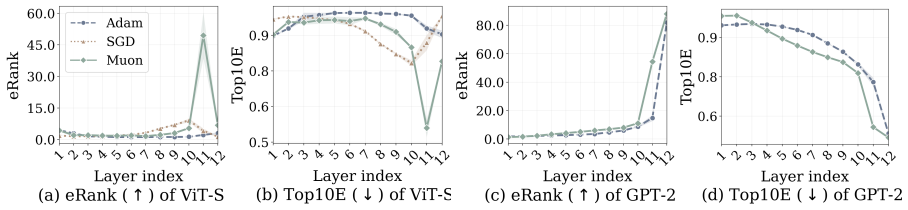
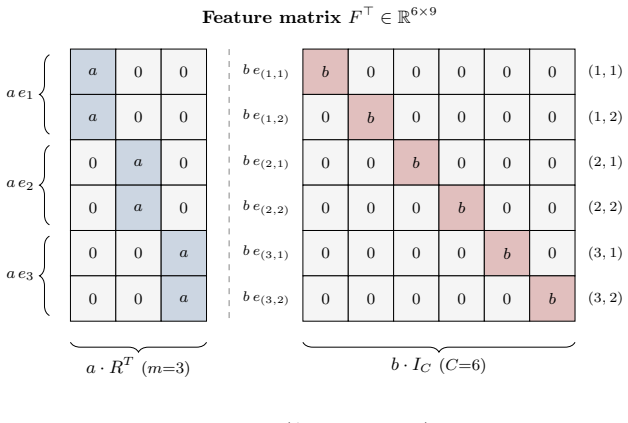
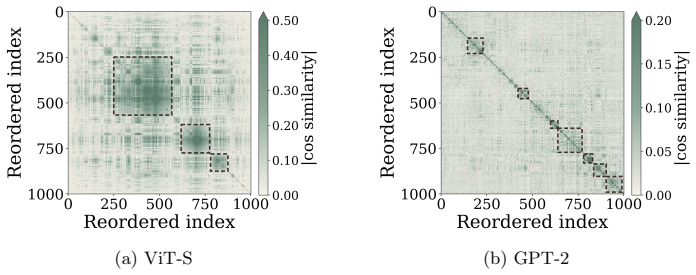
Muon attains larger margins and higher effective rank than Adam and SGD in a representative classification problem with multi-component features, providing theoretical support for the empirical pattern that Muon features are more robust to corruption and transfer more effectively across architectures.
What carries the argument
Logit margins as robustness measure, effective rank as diversity measure, and linear-probe plus fine-tuning accuracy as transfer measure, backed by a theoretical comparison in multi-component classification.
If this is right
- Muon-pretrained models should show higher accuracy than Adam or SGD models when inputs contain corruptions such as noise or occlusions.
- Linear probes on Muon hidden states should reach higher accuracy on new classification tasks than probes on Adam or SGD states.
- Fine-tuning a full model starting from Muon weights should yield higher final accuracy on downstream tasks than starting from Adam or SGD weights.
- Hidden-state matrices from Muon layers should exhibit higher effective rank than those from Adam or SGD layers at corresponding depths.
Where Pith is reading between the lines
- If margin size drives the robustness gain, then Muon might allow training with less aggressive data augmentation while preserving test performance under corruption.
- Higher effective rank could imply that Muon features remain useful even when downstream tasks require many independent directions in representation space.
- The same margin and rank advantage might appear when Muon is compared against other adaptive methods beyond Adam and SGD.
Load-bearing premise
The observed robustness and transferability gains come from Muon's feature-learning behavior rather than from differences in training dynamics, hyperparameter settings, or the specific models tested.
What would settle it
An experiment in which Muon produces no larger logit margins on corrupted test sets or no higher effective rank in the multi-component classification setting.
Figures

read the original abstract
Muon has recently emerged as a state-of-the-art optimizer for pretraining Large Language Models (LLMs) and vision classifiers. Despite its efficiency advantage over Adam and SGD, the feature-learning advantage of Muon remains unclear. This paper investigates Muon's feature-learning advantage through the lens of robustness and transferability. First, by evaluating pretrained models on corrupted images and texts, we show that features learned by Muon are consistently more robust than those learned by Adam and SGD across different architectures, including transformers and Convolutional Neural Networks (CNNs). Using trained layer-wise probes, we further show that this robustness advantage is reflected in larger logit margins across layers. Second, by training linear classifiers or fine-tuning full models from pretrained parameters on downstream tasks, we demonstrate that Muon-learned features transfer more effectively than those learned by Adam and SGD. This transferability advantage is further supported by the diversity of hidden states across layers, as measured by effective rank. Finally, in a representative classification problem with multi-component features, we prove that Muon attains larger margins and higher effective rank than Adam and SGD, providing theoretical support for our empirical findings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the Muon optimizer learns more robust and transferable features than Adam or SGD. This is demonstrated empirically through superior performance on corrupted-image/text evaluations, larger logit margins from layer-wise probes, better downstream transfer via linear probes and full fine-tuning, and higher effective rank of hidden states, across transformers and CNNs. A theoretical proof in a representative multi-component feature classification problem is presented to show that Muon attains larger margins and higher effective rank than Adam and SGD, offered as support for the empirical observations.
Significance. If the results hold, the work would provide both broad empirical evidence and a theoretical foundation for Muon's advantages in feature learning during pretraining, helping explain its state-of-the-art performance on LLMs and vision models. The inclusion of a mathematical proof in a representative problem is a strength that supplies a concrete, falsifiable basis for the margin and rank claims.
major comments (2)
- [Theoretical section] Theoretical section (the representative classification problem): The proof establishes larger margins and higher effective rank for Muon only in a simplified multi-component classification setting; the manuscript provides no analysis or ablation showing that this multi-component structure or the identified margin/rank mechanism appears in the trained layers of the deep networks used for the corrupted-data, probe, and fine-tuning experiments.
- [Empirical evaluation sections] Empirical sections on robustness and transferability: The advantages are attributed directly to Muon's feature-learning properties, yet the experiments do not include controls or ablations that isolate this from potential confounds such as optimizer-specific training dynamics, hyperparameter schedules, or architecture interactions.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive assessment of the work's significance. We address each major comment below and outline planned revisions.
read point-by-point responses
-
Referee: [Theoretical section] Theoretical section (the representative classification problem): The proof establishes larger margins and higher effective rank for Muon only in a simplified multi-component classification setting; the manuscript provides no analysis or ablation showing that this multi-component structure or the identified margin/rank mechanism appears in the trained layers of the deep networks used for the corrupted-data, probe, and fine-tuning experiments.
Authors: The multi-component classification problem is presented as a representative toy model chosen to isolate the margin and rank mechanisms that we hypothesize explain the empirical trends. We agree that an explicit bridge to the deep-network experiments would be valuable. In the revision we will add a dedicated discussion paragraph relating the theoretical margin/rank predictions to the layer-wise logit-margin and effective-rank measurements already reported in Sections 4 and 5. revision: partial
-
Referee: [Empirical evaluation sections] Empirical sections on robustness and transferability: The advantages are attributed directly to Muon's feature-learning properties, yet the experiments do not include controls or ablations that isolate this from potential confounds such as optimizer-specific training dynamics, hyperparameter schedules, or architecture interactions.
Authors: All reported comparisons use the same architectures, datasets, and evaluation protocols; hyperparameters for each optimizer were selected via standard grid search on the pre-training task. Nevertheless, we acknowledge that additional controls would further isolate optimizer effects. In revision we will add a short subsection reporting hyper-parameter sensitivity sweeps and confirming that the robustness/transfer gaps persist under matched training budgets. revision: partial
Circularity Check
No significant circularity; proof and empirics remain independent
full rationale
The paper's central theoretical step is an explicit proof (not a fit) that Muon yields larger margins and higher effective rank in a simplified multi-component classification problem. This is presented separately from the empirical measurements of robustness (corrupted-data eval) and transferability (linear probes, fine-tuning, effective rank on real models). No equations reduce the proof to the empirical quantities by construction, no parameters are fitted on the target data and then relabeled as predictions, and no load-bearing self-citation chain is invoked to justify the optimizer comparison. The derivation chain is therefore self-contained against external benchmarks; the toy-model proof stands or falls on its own assumptions rather than recycling the deep-net results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Muon is Scalable for LLM Training
Muon is scalable for llm training , author=. arXiv preprint arXiv:2502.16982 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
arXiv preprint arXiv:2601.19156 , year=
Convergence of muon with newton-schulz , author=. arXiv preprint arXiv:2601.19156 , year=
-
[3]
arXiv preprint arXiv:2407.07972 , year=
Deconstructing what makes a good optimizer for language models , author=. arXiv preprint arXiv:2407.07972 , year=
-
[4]
2009 IEEE conference on computer vision and pattern recognition , pages=
Imagenet: A large-scale hierarchical image database , author=. 2009 IEEE conference on computer vision and pattern recognition , pages=. 2009 , organization=
2009
-
[5]
HuggingFace
FineWeb: decanting the web for the finest text data at scale , author=. HuggingFace. Accessed: Jul , volume=
-
[6]
arXiv preprint arXiv:2510.22980 , year=
How Muon's Spectral Design Benefits Generalization: A Study on Imbalanced Data , author=. arXiv preprint arXiv:2510.22980 , year=
-
[7]
arXiv preprint arXiv:2509.23106 , year=
Effective Quantization of Muon Optimizer States , author=. arXiv preprint arXiv:2509.23106 , year=
-
[8]
To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters
To Use or not to Use Muon: How Simplicity Bias in Optimizers Matters , author=. arXiv preprint arXiv:2603.00742 , year=
work page internal anchor Pith review arXiv
-
[9]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[10]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Momentum contrast for unsupervised visual representation learning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[11]
A Large-scale Study of Representation Learning with the Visual Task Adaptation Benchmark
A large-scale study of representation learning with the visual task adaptation benchmark , author=. arXiv preprint arXiv:1910.04867 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
Benchmarking neural network robustness to common corruptions and perturbations , author=. arXiv preprint arXiv:1903.12261 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1903
-
[13]
International conference on machine learning , pages=
Wilds: A benchmark of in-the-wild distribution shifts , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[14]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[15]
Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
GLUE: A multi-task benchmark and analysis platform for natural language understanding , author=. Proceedings of the 2018 EMNLP workshop BlackboxNLP: Analyzing and interpreting neural networks for NLP , pages=
2018
-
[16]
A structural probe for finding syntax in word representations , author=. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages=
2019
-
[17]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
Beyond accuracy: Behavioral testing of NLP models with CheckList , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[18]
The 57th Annual Meeting of the Association for Computational Linguistics (ACL) , address =
Combating Adversarial Misspellings with Robust Word Recognition , author=. The 57th Annual Meeting of the Association for Computational Linguistics (ACL) , address =
-
[19]
Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages=
CAT: Customized Adversarial Training for Improved Robustness , author=. Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence , pages=. 2022 , organization=
2022
-
[20]
International Conference on Learning Representations , year=
MMA Training: Direct Input Space Margin Maximization through Adversarial Training , author=. International Conference on Learning Representations , year=
-
[21]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2007 15th European signal processing conference , pages=
The effective rank: A measure of effective dimensionality , author=. 2007 15th European signal processing conference , pages=. 2007 , organization=
2007
-
[23]
arXiv preprint arXiv:2304.13960 , year=
Noise is not the main factor behind the gap between sgd and adam on transformers, but sign descent might be , author=. arXiv preprint arXiv:2304.13960 , year=
-
[24]
Improving Generalization Performance by Switching from Adam to SGD
Improving generalization performance by switching from adam to sgd , author=. arXiv preprint arXiv:1712.07628 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[26]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Eliciting latent predictions from transformers with the tuned lens , author=. arXiv preprint arXiv:2303.08112 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Free dolly: Introducing the world’s first truly open instructiontuned llm , author=
-
[28]
WizardLM: Empowering large pre-trained language models to follow complex instructions
Wizardlm: Empowering large language models to follow complex instructions , author=. arXiv preprint arXiv:2304.12244 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Decoupled Weight Decay Regularization
Decoupled weight decay regularization , author=. arXiv preprint arXiv:1711.05101 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Implicit Bias of AdamW:
Xie, Shuo and Li, Zhiyuan , journal=. Implicit Bias of AdamW:
-
[32]
Journal of Machine Learning Research , volume=
The implicit bias of gradient descent on separable data , author=. Journal of Machine Learning Research , volume=
-
[33]
arXiv preprint arXiv:2405.13698 , year=
How to set AdamW's weight decay as you scale model and dataset size , author=. arXiv preprint arXiv:2405.13698 , year=
-
[34]
Advances in neural information processing systems , volume=
The marginal value of adaptive gradient methods in machine learning , author=. Advances in neural information processing systems , volume=
-
[35]
On the Convergence of Adam and Beyond
On the convergence of adam and beyond , author=. arXiv preprint arXiv:1904.09237 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[36]
arXiv preprint arXiv:2502.04664 , year=
Implicit bias of spectral descent and muon on multiclass separable data , author=. arXiv preprint arXiv:2502.04664 , year=
-
[37]
Advances in neural information processing systems , volume=
How transferable are features in deep neural networks? , author=. Advances in neural information processing systems , volume=
-
[38]
International conference on machine learning , pages=
Leep: A new measure to evaluate transferability of learned representations , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[39]
International conference on machine learning , pages=
Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav) , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[40]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2019 , publisher=
2019
-
[41]
2008 Sixth Indian conference on computer vision, graphics & image processing , pages=
Automated flower classification over a large number of classes , author=. 2008 Sixth Indian conference on computer vision, graphics & image processing , pages=. 2008 , organization=
2008
-
[42]
European conference on computer vision , pages=
Food-101--mining discriminative components with random forests , author=. European conference on computer vision , pages=. 2014 , organization=
2014
-
[43]
Proceedings of the IEEE international conference on computer vision workshops , pages=
3d object representations for fine-grained categorization , author=. Proceedings of the IEEE international conference on computer vision workshops , pages=
-
[44]
On the Convergence of A Class of Adam-Type Algorithms for Non-Convex Optimization
On the convergence of a class of adam-type algorithms for non-convex optimization , author=. arXiv preprint arXiv:1808.02941 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
arXiv preprint arXiv:1808.05671 , year=
On the convergence of adaptive gradient methods for nonconvex optimization , author=. arXiv preprint arXiv:1808.05671 , year=
-
[46]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
A sufficient condition for convergences of adam and rmsprop , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[47]
arXiv preprint arXiv:2003.02395 , year=
A simple convergence proof of adam and adagrad , author=. arXiv preprint arXiv:2003.02395 , year=
-
[48]
Advances in neural information processing systems , volume=
Adam can converge without any modification on update rules , author=. Advances in neural information processing systems , volume=
-
[49]
Advances in Neural Information Processing Systems , volume=
Convergence of adam under relaxed assumptions , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
Advances in Neural Information Processing Systems , volume=
Heavy-tailed class imbalance and why adam outperforms gradient descent on language models , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
Advances in neural information processing systems , volume=
Why transformers need adam: A hessian perspective , author=. Advances in neural information processing systems , volume=
-
[52]
arXiv preprint arXiv:2306.00204 , year=
Toward understanding why adam converges faster than sgd for transformers , author=. arXiv preprint arXiv:2306.00204 , year=
-
[53]
2024 , url =
Keller Jordan and Yuchen Jin and Vlado Boza and Jiacheng You and Franz Cesista and Laker Newhouse and Jeremy Bernstein , title =. 2024 , url =
2024
-
[54]
arXiv preprint arXiv:2509.26030 , year=
Muon outperforms Adam in tail-end associative memory learning , author=. arXiv preprint arXiv:2509.26030 , year=
-
[55]
On the Convergence Analysis of Muon
On the convergence analysis of muon , author=. arXiv preprint arXiv:2505.23737 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[57]
Advances in neural information processing systems , volume=
Symbolic discovery of optimization algorithms , author=. Advances in neural information processing systems , volume=
-
[58]
Advances in neural information processing systems , volume=
On the convergence rate of training recurrent neural networks , author=. Advances in neural information processing systems , volume=
-
[59]
Advances in neural information processing systems , volume=
Adaptive methods for nonconvex optimization , author=. Advances in neural information processing systems , volume=
-
[60]
arXiv preprint arXiv:1908.03265 , year=
On the variance of the adaptive learning rate and beyond , author=. arXiv preprint arXiv:1908.03265 , year=
-
[61]
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
Large batch optimization for deep learning: Training bert in 76 minutes , author=. arXiv preprint arXiv:1904.00962 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[62]
International conference on machine learning , pages=
Adafactor: Adaptive learning rates with sublinear memory cost , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[63]
Adaptive Federated Optimization
Adaptive federated optimization , author=. arXiv preprint arXiv:2003.00295 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[64]
Riemannian Adaptive Optimization Methods
Riemannian adaptive optimization methods , author=. arXiv preprint arXiv:1810.00760 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
arXiv preprint arXiv:1806.06763 , year=
Closing the generalization gap of adaptive gradient methods in training deep neural networks , author=. arXiv preprint arXiv:1806.06763 , year=
-
[66]
International Conference on Machine Learning , pages=
Dissecting adam: The sign, magnitude and variance of stochastic gradients , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[67]
arXiv preprint arXiv:2207.14484 , year=
Adaptive gradient methods at the edge of stability , author=. arXiv preprint arXiv:2207.14484 , year=
-
[68]
arXiv preprint arXiv:2402.07114 , year=
Towards quantifying the preconditioning effect of adam , author=. arXiv preprint arXiv:2402.07114 , year=
-
[69]
International Conference on Machine Learning , pages=
The implicit bias for adaptive optimization algorithms on homogeneous neural networks , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[70]
arXiv preprint arXiv:2108.11371 , year=
Understanding the generalization of adam in learning neural networks with proper regularization , author=. arXiv preprint arXiv:2108.11371 , year=
-
[71]
Kimi K2: Open Agentic Intelligence
Kimi k2: Open agentic intelligence , author=. arXiv preprint arXiv:2507.20534 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2510.16981 , year=
Muonbp: Faster muon via block-periodic orthogonalization , author=. arXiv preprint arXiv:2510.16981 , year=
-
[73]
arXiv preprint arXiv:2510.05491 , year=
NorMuon: Making Muon more efficient and scalable , author=. arXiv preprint arXiv:2510.05491 , year=
-
[74]
MUON+: Towards More Effective Muon via One Additional Normalization Step for LLM Pre-training
Muon+: Towards Better Muon via One Additional Normalization Step , author=. arXiv preprint arXiv:2602.21545 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[75]
arXiv preprint arXiv:2601.14603 , year=
Variance-Adaptive Muon: Accelerating LLM Pretraining with NSR-Modulated and Variance-Scaled Momentum , author=. arXiv preprint arXiv:2601.14603 , year=
-
[76]
Muon$^2$: Boosting Muon via Adaptive Second-Moment Preconditioning
Muon ^2 : Boosting Muon via Adaptive Second-Moment Preconditioning , author=. arXiv preprint arXiv:2604.09967 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
arXiv preprint arXiv:2601.23261 , year=
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training , author=. arXiv preprint arXiv:2601.23261 , year=
-
[78]
arXiv preprint arXiv:2603.00416 , year=
MuonRec: Shifting the Optimizer Paradigm Beyond Adam in Scalable Generative Recommendation , author=. arXiv preprint arXiv:2603.00416 , year=
-
[79]
arXiv e-prints , pages=
A note on the convergence of muon and further , author=. arXiv e-prints , pages=
-
[80]
arXiv preprint arXiv:2503.12645 , year=
Understanding gradient orthogonalization for deep learning via non-euclidean trust-region optimization , author=. arXiv preprint arXiv:2503.12645 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.