Using Probabilistic Programs to Train Inductive Reasoning in Large Language Models
Pith reviewed 2026-06-29 18:41 UTC · model grok-4.3
The pith
Program-based Posterior Training uses probabilistic programs to generate soft labels that improve LLMs on inductive reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
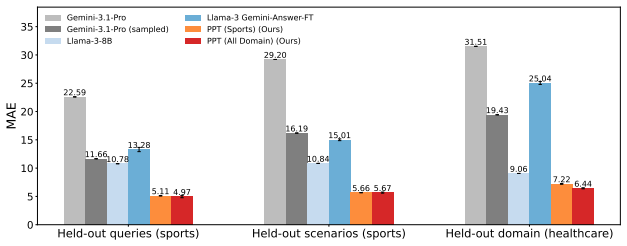
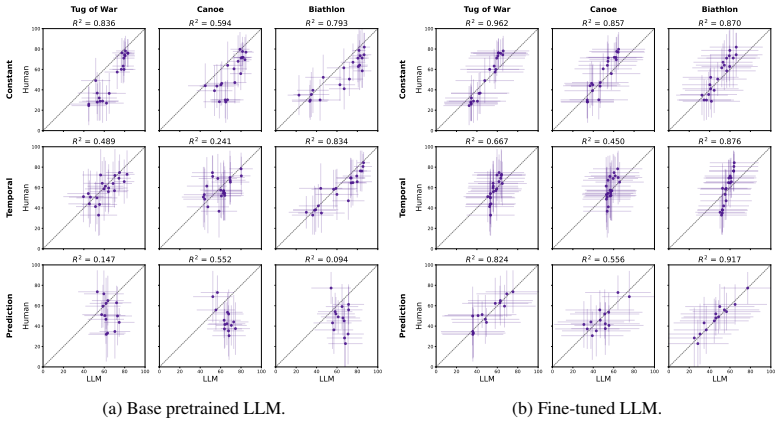
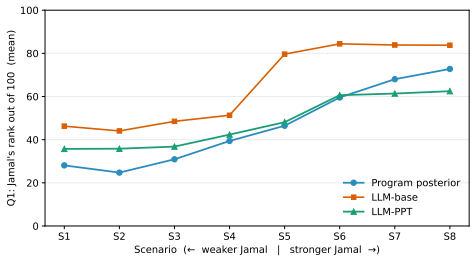
PPT substantially improves estimation accuracy on held-out inductive tasks, increases alignment with human judgments, and transfers to external benchmarks for estimation and calibration. The gains in raw calibration are not subsumed by post-hoc temperature scaling, showing that the models have more deeply internalized uncertainty compared to output rescaling.
What carries the argument
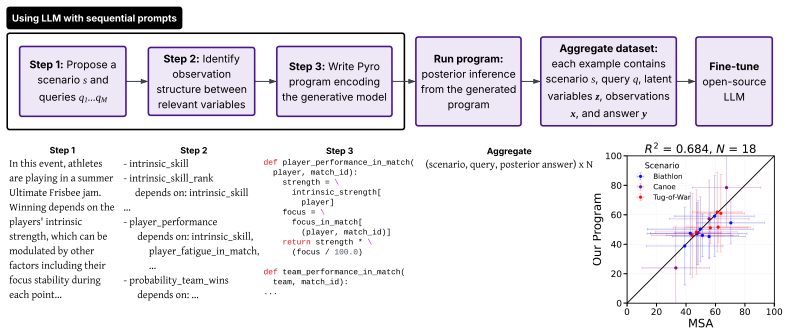
Program-based Posterior Training (PPT), which uses LLMs to generate open-world scenarios as probabilistic programs and runs probabilistic inference to produce distributional target responses for fine-tuning.
If this is right
- Improved performance on held-out inductive reasoning motifs
- Increased alignment with human inductive judgments
- Transfer of gains to external estimation and calibration benchmarks
- Calibration improvements that persist beyond post-hoc temperature scaling
Where Pith is reading between the lines
- Hybrid approaches combining symbolic probabilistic programs with neural fine-tuning could address other forms of uncertain reasoning in AI systems.
- This method might reduce the need for expensive human-labeled data in training for real-world decision making under uncertainty.
- Further work could test if the approach generalizes to more complex or domain-specific inductive problems beyond the generated scenarios.
Load-bearing premise
The distributional targets produced by the LLM-generated probabilistic programs and inference are faithful representations of real-world inductive reasoning rather than artifacts of the generation process.
What would settle it
If fine-tuning on PPT labels shows no improvement over baselines when evaluated on a set of inductive tasks constructed entirely from human-authored scenarios without LLM generation.
Figures

read the original abstract
Post-training Large Language Models (LLMs) for reasoning typically focuses on deductive tasks such as mathematics and coding where correctness is verifiable. Yet, many real-world reasoning problems are inductive: agents must infer uncertain beliefs from sparse, ambiguous observations. There are challenges to using standard fine-tuning methods for inductive reasoning, including difficulties in curating large-scale, high-quality labeled datasets and in handling targets that are inherently distributional. In this work, we introduce a novel approach, called Program-based Posterior Training (PPT), to address these limitations: we use an LLM to generate diverse open-world scenarios as probabilistic programs, run probabilistic inference to produce distributional target responses to queries, and then fine-tune on these probabilistic soft labels. Using this approach, we fine-tune LLMs on 10,000 programmatically generated scenarios and evaluate on held-out motifs, human-labeled judgments, and external benchmarks. Overall, PPT substantially improves estimation accuracy on held-out inductive tasks, increases alignment with human judgments, and transfers to external benchmarks for estimation and calibration. Additionally, the gains in raw calibration are not subsumed by post-hoc temperature scaling, showing that the models have more deeply internalized uncertainty compared to output rescaling. Together, these results suggest that probabilistic-program-mediated fine-tuning is a promising approach for post-training LLMs to reliably perform approximate inductive inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Program-based Posterior Training (PPT): an LLM generates diverse open-world scenarios as probabilistic programs, probabilistic inference produces distributional soft labels for queries, and the LLM is fine-tuned on 10k such labels. Evaluation on held-out motifs, human judgments, and external benchmarks is claimed to show substantial gains in estimation accuracy, human alignment, and calibration that are not explained by post-hoc temperature scaling.
Significance. If the central claims are substantiated, PPT offers a scalable route to distributional training targets for inductive reasoning without manual curation of labels, addressing a key limitation of standard fine-tuning on deductive tasks. The separation of program generation from inference and the demonstration that calibration gains exceed temperature scaling would be notable contributions to post-training methods for uncertainty-aware reasoning.
major comments (2)
- [Abstract] Abstract: the claims that PPT 'substantially improves estimation accuracy on held-out inductive tasks' and 'increases alignment with human judgments' are presented without any quantitative results, confidence intervals, statistical tests, or ablation controls. This is load-bearing for the central claim because the abstract supplies the only evidence summary available for assessing whether the data support the reported gains.
- [Abstract] Abstract (PPT pipeline description): the method assumes that inference over LLM-generated probabilistic programs yields distributional targets faithful to real-world inductive reasoning rather than artifacts of the generator LLM or program syntax. No validation of program correctness, coverage of ambiguity, or calibration against independent human data is described; if the programs systematically encode the generator's priors, measured improvements could reflect learning of those idiosyncrasies rather than general inductive inference.
minor comments (1)
- [Abstract] The abstract refers to 'held-out motifs' and 'external benchmarks' without naming them or citing the specific datasets or prior work they come from.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims that PPT 'substantially improves estimation accuracy on held-out inductive tasks' and 'increases alignment with human judgments' are presented without any quantitative results, confidence intervals, statistical tests, or ablation controls. This is load-bearing for the central claim because the abstract supplies the only evidence summary available for assessing whether the data support the reported gains.
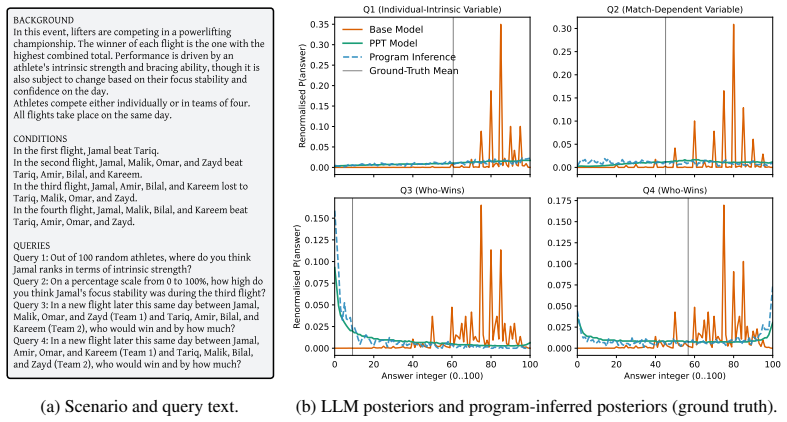
Authors: We agree that the abstract would be strengthened by including quantitative results. In the revised manuscript we will update the abstract to report specific metrics (e.g., accuracy gains, alignment scores) with confidence intervals and references to the statistical comparisons performed in the main text. revision: yes
-
Referee: [Abstract] Abstract (PPT pipeline description): the method assumes that inference over LLM-generated probabilistic programs yields distributional targets faithful to real-world inductive reasoning rather than artifacts of the generator LLM or program syntax. No validation of program correctness, coverage of ambiguity, or calibration against independent human data is described; if the programs systematically encode the generator's priors, measured improvements could reflect learning of those idiosyncrasies rather than general inductive inference.
Authors: The manuscript reports evaluation on held-out motifs and human-labeled judgments, which directly tests generalization and alignment with independent human data. These results provide evidence that performance gains are not limited to artifacts of the generator. We will add a brief discussion of program-generation limitations and any additional checks on program validity in the revision. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes generating 10k scenarios as probabilistic programs via LLM, running inference to obtain distributional soft labels, and fine-tuning on those labels, with evaluation on held-out motifs, human judgments, and external benchmarks. No equations, definitions, or steps in the abstract reduce any claimed prediction or result to the inputs by construction (e.g., no self-definitional terms, no fitted parameter renamed as prediction, no load-bearing self-citation chain). The probabilistic inference step and independent external evaluations keep the chain self-contained; any dependence on the generator LLM is not exhibited as a formal equivalence in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM can generate diverse open-world scenarios as probabilistic programs that are suitable for inference
- domain assumption Probabilistic inference on those programs yields distributional targets that improve inductive reasoning when used for fine-tuning
Reference graph
Works this paper leans on
-
[1]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, Red Hook, NY , USA, 2022
2022
-
[2]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[3]
Bayesian models of cognition
Thomas L Griffiths, Charles Kemp, and Joshua B Tenenbaum. Bayesian models of cognition. InCambridge Handbook of Computational Cognitive Sciences. Cambridge University Press, 2008
2008
-
[4]
How to grow a mind: statistics, structure, and abstraction.Science, 331(6022):1279–1285, 2011
Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. How to grow a mind: statistics, structure, and abstraction.Science, 331(6022):1279–1285, 2011
2011
-
[5]
David M. Blei. Build, compute, critique, repeat: Data analysis with latent variable models. In Annual Review of Statistics and Its Application, 2014
2014
-
[6]
Bishop.Pattern Recognition and Machine Learning (Information Science and Statistics)
Christopher M. Bishop.Pattern Recognition and Machine Learning (Information Science and Statistics). Springer, 2006
2006
-
[7]
Human-like category learning by injecting ecological priors from large language models into neural networks
Akshay Kumar Jagadish, Julian Coda-Forno, Mirko Thalmann, Eric Schulz, and Marcel Binz. Human-like category learning by injecting ecological priors from large language models into neural networks. InForty-first International Conference on Machine Learning
-
[8]
Akshay K Jagadish, Mirko Thalmann, Julian Coda-Forno, Marcel Binz, and Eric Schulz. Meta- learning ecological priors from large language models explains human learning and decision making.arXiv preprint arXiv:2509.00116, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.Transactions on Machine Learning Research (TMLR), 2025
Prateek Chhikara. Mind the confidence gap: Overconfidence, calibration, and distractor effects in large language models.Transactions on Machine Learning Research (TMLR), 2025
2025
-
[10]
Generating computational cognitive models using large language models.Advances in Neural Information Processing Systems, 38:87796–87833, 2025
Milena Rmus, Akshay Kumar Jagadish, Marvin Mathony, Tobias Ludwig, and Eric Schulz. Generating computational cognitive models using large language models.Advances in Neural Information Processing Systems, 38:87796–87833, 2025
2025
-
[11]
Modeling open-world cognition as on-demand synthesis of probabilistic models
Lionel Wong, Katherine M Collins, Lance Ying, Cedegao E Zhang, Adrian Weller, Tobias Ger- stenberg, Timothy O’Donnell, Alexander K Lew, Jacob D Andreas, Joshua B Tenenbaum, and Tyler Brooke-Wilson. Modeling open-world cognition as on-demand synthesis of probabilistic models. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 47, 2025
2025
-
[12]
OpenEstimate: Evaluating LLMs on reasoning under uncertainty with real-world data
Alana Marzoev, Jillian Ross, Michael Cafarella, and Jacob Andreas. OpenEstimate: Evaluating LLMs on reasoning under uncertainty with real-world data. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
WinoGrande: an adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, August 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. WinoGrande: an adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, August 2021
2021
-
[14]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. InInternational Conference on Learning Representations, 2021
2021
-
[15]
TruthfulQA: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland, May 2022. Association for Computational Linguistics
2022
-
[16]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019. 11
2019
-
[17]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC, the AI2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[18]
Bayesian teaching enables probabilistic reasoning in large language models.Nature Communications, 17(1):1238, 2026
Linlu Qiu, Fei Sha, Kelsey Allen, Yoon Kim, Tal Linzen, and Sjoerd van Steenkiste. Bayesian teaching enables probabilistic reasoning in large language models.Nature Communications, 17(1):1238, 2026
2026
-
[19]
On calibration of modern neural networks
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning, pages 1321–1330, 2017
2017
-
[20]
Lake, Ruslan Salakhutdinov, and Joshua B
Brenden M. Lake, Ruslan Salakhutdinov, and Joshua B. Tenenbaum. Human-level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
2015
-
[21]
Lew, Noah D
Lionel Wong, Gabriel Grand, Alexander K. Lew, Noah D. Goodman, Vikash K. Mansinghka, Jacob Andreas, and Joshua B. Tenenbaum. From word models to world models: Translating from natural language to the probabilistic language of thought, 2023
2023
-
[22]
Concepts in a probabilistic language of thought
Noah D Goodman, Joshua B Tenenbaum, and Tobias Gerstenberg. Concepts in a probabilistic language of thought. InIn Proceedings of the 36th Annual Conference of the Cognitive Science Society, 2014
2014
-
[23]
Hypothesis search: Inductive reasoning with language models
Ruocheng Wang, Eric Zelikman, Gabriel Poesia, Yewen Pu, Nick Haber, and Noah Goodman. Hypothesis search: Inductive reasoning with language models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[24]
Language models as inductive reasoners
Zonglin Yang, Li Dong, Xinya Du, Hao Cheng, Erik Cambria, Xiaodong Liu, Jianfeng Gao, and Furu Wei. Language models as inductive reasoners. In Yvette Graham and Matthew Purver, editors,Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 209–225. Association for Computat...
2024
-
[25]
Foundation posteriors for approximate probabilistic inference
Mike Wu and Noah Goodman. Foundation posteriors for approximate probabilistic inference. InAdvances in Neural Information Processing Systems, 2022
2022
-
[26]
The design and implementation of probabilistic programming languages.http://dippl.org, 2014
Noah D Goodman and Andreas Stuhlmüller. The design and implementation of probabilistic programming languages.http://dippl.org, 2014
2014
-
[27]
An explanation of in-context learning as implicit Bayesian inference
Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. An explanation of in-context learning as implicit Bayesian inference. InInternational Conference on Learning Representations, 2022
2022
-
[28]
Liyi Zhang, Michael Y . Li, R. Thomas McCoy, Theodore Sumers, Jian-Qiao Zhu, and Thomas L. Griffiths. What should embeddings embed? Autoregressive models represent latent generating distributions.Transactions on Machine Learning Research, 2025. Featured Certification
2025
-
[29]
Amortizing intractable inference in large language models
Edward J Hu, Moksh Jain, Eric Elmoznino, Younesse Kaddar, Guillaume Lajoie, Yoshua Bengio, and Nikolay Malkin. Amortizing intractable inference in large language models. In International Conference on Learning Representations, 2024
2024
-
[30]
Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
Noah Hollmann, Samuel Müller, Lennart Purucker, Arjun Krishnakumar, Max Körfer, Shi Bin Hoo, Robin Tibor Schirrmeister, and Frank Hutter. Accurate predictions on small data with a tabular foundation model.Nature, 637(8045):319–326, 2025
2025
-
[31]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InEmpirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[32]
Wornell, and Soumya Ghosh
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory W. Wornell, and Soumya Ghosh. Thermometer: Towards universal calibration for large language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference ...
2024
-
[33]
Chen, Martin Jankowiak, Fritz Obermeyer, Neeraj Pradhan, Theofanis Karaletsos, Rohit Singh, Paul Szerlip, Paul Horsfall, and Noah D
Eli Bingham, Jonathan P. Chen, Martin Jankowiak, Fritz Obermeyer, Neeraj Pradhan, Theofanis Karaletsos, Rohit Singh, Paul Szerlip, Paul Horsfall, and Noah D. Goodman. Pyro: Deep Universal Probabilistic Programming.Journal of Machine Learning Research, 20:1–6, 2019
2019
-
[34]
A Study of LLMs' Preferences for Libraries and Programming Languages
Lukas Twist, Jie M Zhang, Mark Harman, Don Syme, Joost Noppen, and Detlef Nauck. LLMs love Python: A study of LLMs’ bias for programming languages and libraries.arXiv preprint arXiv:2503.17181, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022
2022
-
[36]
The llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
2024
-
[37]
Qwen2 technical report, 2024
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren 13 Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, ...
2024
-
[38]
R Thomas McCoy, Shunyu Yao, Dan Friedman, Matthew Hardy, and Thomas L Griffiths. Embers of autoregression: Understanding large language models through the problem they are trained to solve.arXiv preprint arXiv:2309.13638, 2023
-
[39]
A beat B
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InInternational Conference on Learning Representations, 2019. 14 A Technical appendices and supplementary material A.1 Implementational details HyperparametersHere we detail the experimental setup used in our experiments. We use PyTorch with Torchtune to fine-tune LLAMA-3-8B-INSTRUCT...
2019
-
[40]
out of 100 athletes, where do they rank?
Estimating an athlete’s intrinsic strength as a distribution or percentile rank (e.g., “out of 100 athletes, where do they rank?”)
-
[41]
Inferring a latent match factor on a 0–100 scale for a specific match (effort / teamwork / fatigue / etc.)
-
[42]
surprising
Predicting outcomes of 1–2 hypothetical future matches, including *who wins* and *by how much* qualitatively (or as a probability), while acknowledging uncertainty. Important: each query should be answerable by one number. Wrong examples: 1) explicitly asking for verbal justification; 2) asking about two players’ intrinsic strengths within one query. Howe...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.