Alignment Collapse Under KV Cache Quantization: Diagnosis and Mitigation
Pith reviewed 2026-06-28 15:35 UTC · model grok-4.3
The pith
KV cache quantization destroys LLM safety alignment because safety features occupy a low-dimensional subspace far more vulnerable to quantization noise than spaces measured by perplexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
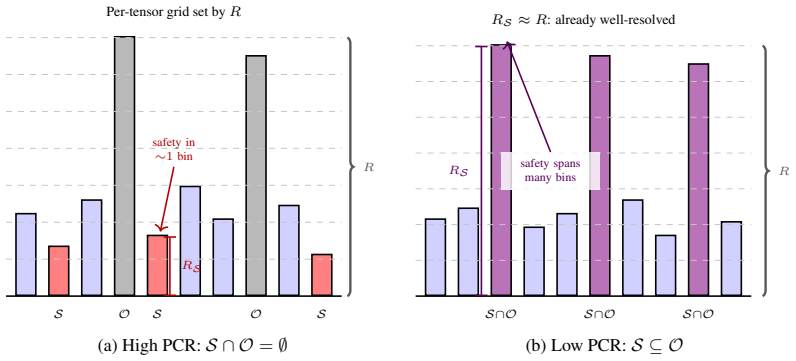
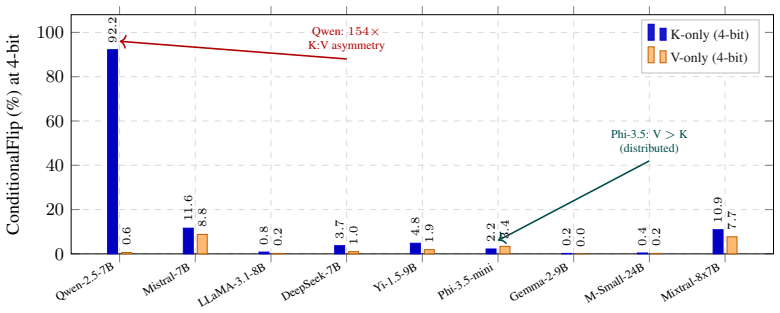
Safety features occupy a low-dimensional activation subspace 10^2-10^3x more vulnerable to quantization noise than the full representation space perplexity averages over. This produces alignment collapse under KV cache quantization that is invisible to standard metrics, with sharp model-specific phase transitions and no universal safe bit-width. Per-Channel Reduction classifies each model into one of three failure modes (outlier-crushes-safety, outlier-as-safety, multi-layer dilution) and predicts the correct mitigation, recovering up to 97% of lost alignment across primary models, a held-out model, and production quantizers including KIVI and FP8.
What carries the argument
Per-Channel Reduction (PCR), a diagnostic that classifies each model into one of three mechanistic failure modes based on how safety features interact with outlier channels using twenty calibration prompts.
If this is right
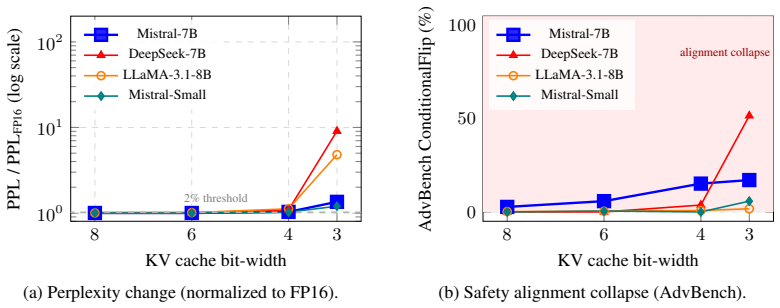
- Low-bit quantization destroys safety alignment at negligible perplexity cost, such as 15.2% refusal loss at 1.03x perplexity in Mistral-7B.
- No universal safe bit-width exists, with sharp model-specific phase transitions invisible to perplexity and accuracy.
- PCR predicts the correct mitigation direction on all nine primary models and one held-out model from an independent family.
- The training-free protocol recovers up to 97.2% of lost alignment at minimal memory overhead and succeeds where attention-based allocation fails.
- PCR generalizes across unseen prompts, models, and production quantizers including KIVI and FP8 KV cache in vLLM serving.
Where Pith is reading between the lines
- Production serving frameworks may need to run the twenty-prompt PCR check before enabling low-bit KV cache on each new model to avoid silent safety loss.
- The subspace-vulnerability observation could be tested on weight quantization or pruning to see whether the same low-dimensional sensitivity appears.
- Safety benchmarks could add a quantization stress test as a standard reporting requirement to surface these failures earlier.
- The low calibration cost suggests the method could be integrated into automated model-deployment pipelines for quick per-model safety configuration.
Load-bearing premise
The safety degradation is caused by the identified low-dimensional geometric vulnerability of the safety subspace rather than benchmark artifacts, prompt selection, or other unmeasured factors.
What would settle it
Measuring the quantization noise level specifically inside the identified safety subspace versus the full space on a held-out model and checking whether the vulnerability ratio predicts the exact refusal-rate drop observed under the same quantizer.
Figures






read the original abstract
Key-value (KV) cache quantization is widely used to reduce Large Language Model (LLM) inference memory, yet existing evaluations solely focus on measuring perplexity and accuracy without assessing the safety impact. In this study, we explore alignment preservation under KV cache quantization. Across eleven instruction-tuned models (3.8B-72B) and five benchmarks (1,894 prompts), we find that low-bit quantization can silently destroy safety alignment: Mistral-7B loses 15.2% of its refusals at only 1.03x perplexity, and no universal safe bit-width exists, with sharp model-specific phase transitions invisible to standard metrics. We identify that the root cause is geometric: safety features occupy a low-dimensional activation subspace 10^2-10^3x more vulnerable to quantization noise than the full representation space perplexity averages over. Inspired by this observation, we propose Per-Channel Reduction (PCR), a diagnostic that classifies each model into one of three mechanistic failure modes: outlier-crushes-safety, where safety lives in non-outlier channels collaterally damaged by outlier-driven scale factors; outlier-as-safety, where safety overlaps outlier channels and finer granularity cannot rescue it; and multi-layer dilution, where safety is distributed across many layers and per-layer fixes fail. PCR predicts the correct mitigation direction on all nine primary models and one held-out model from an independent family using 20 calibration prompts. PCR generalizes across unseen prompts, models, and production quantizers, including KIVI with up to 97.2% recovery, succeeding where attention-based allocation methods fail. The resulting training-free protocol, requiring approximately 35 GPU-minutes, recovers up to 97% of lost alignment at minimal memory overhead, addressing vulnerabilities confirmed in production vLLM serving with FP8 KV cache on NVIDIA GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that KV cache quantization can silently destroy safety alignment in instruction-tuned LLMs, with examples such as Mistral-7B losing 15.2% of refusals at only 1.03x perplexity increase. It identifies the root cause as safety features occupying a low-dimensional activation subspace far more vulnerable to quantization noise than the full space averaged by perplexity. The authors introduce Per-Channel Reduction (PCR) as a diagnostic that classifies models into three mechanistic failure modes (outlier-crushes-safety, outlier-as-safety, multi-layer dilution) using 20 calibration prompts, which correctly predicts mitigation directions on nine primary models plus one held-out model and generalizes to unseen prompts and quantizers like KIVI, recovering up to 97.2% of lost alignment in a training-free protocol.
Significance. If the empirical patterns and PCR predictive power hold, the work is significant for LLM deployment because it surfaces a safety risk invisible to standard perplexity/accuracy metrics and supplies a lightweight diagnostic plus mitigation that succeeds where attention-based methods fail. The breadth across 11 models (3.8B-72B), 1894 prompts, five benchmarks, multiple quantizers, and a held-out model test, together with reported generalization, supports practical utility in production settings such as vLLM with FP8 KV cache.
major comments (2)
- [Abstract / Experimental results] Abstract and experimental results: the reported percentages (e.g., 15.2% refusal loss) and phase-transition claims are presented without any mention of statistical tests, error bars, data-exclusion criteria, or controls for prompt-selection confounds, which is load-bearing for verifying that the observed alignment collapse is robust rather than artifactual.
- [PCR method and held-out validation] PCR classification and validation: the assertion that the 20-prompt PCR reliably identifies the correct failure mode and mitigation across models rests on the untested assumption that the low-dimensional subspace vulnerability is causal rather than correlated with benchmark artifacts; an ablation ruling out prompt sensitivity or alternative explanations would be required to support the mechanistic claim.
minor comments (1)
- [PCR diagnostic] The description of the three PCR modes would benefit from an explicit table mapping each mode to the observed quantization behavior and chosen mitigation for the nine primary models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater statistical rigor and mechanistic validation. We address each major comment below and commit to revisions that strengthen the empirical claims without altering the core findings.
read point-by-point responses
-
Referee: [Abstract / Experimental results] Abstract and experimental results: the reported percentages (e.g., 15.2% refusal loss) and phase-transition claims are presented without any mention of statistical tests, error bars, data-exclusion criteria, or controls for prompt-selection confounds, which is load-bearing for verifying that the observed alignment collapse is robust rather than artifactual.
Authors: We agree that explicit statistical reporting is necessary to confirm robustness. In the revision we will add bootstrap-derived 95% confidence intervals for all reported refusal-loss percentages (computed over 1000 resamples of the 1,894-prompt pool) and will state the exact prompt-selection protocol together with any exclusion criteria. Phase-transition bit-widths will be accompanied by the same intervals across the five benchmarks. These additions directly address concerns about artifactual results. revision: yes
-
Referee: [PCR method and held-out validation] PCR classification and validation: the assertion that the 20-prompt PCR reliably identifies the correct failure mode and mitigation across models rests on the untested assumption that the low-dimensional subspace vulnerability is causal rather than correlated with benchmark artifacts; an ablation ruling out prompt sensitivity or alternative explanations would be required to support the mechanistic claim.
Authors: We recognize that demonstrating causality beyond correlation strengthens the mechanistic interpretation. The revision will include an ablation that (i) recomputes PCR classifications on five disjoint 20-prompt calibration sets drawn from the same distribution and (ii) compares PCR-guided mitigation against a random-channel baseline of equal dimensionality. Results on the nine primary models plus the held-out model will be reported; any degradation in predictive accuracy will be quantified. This ablation directly tests prompt sensitivity and rules out simple correlation with benchmark artifacts. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper reports only empirical measurements of alignment degradation under KV cache quantization across 11 models and 1894 prompts, identifies geometric subspace vulnerability as an observed pattern, and validates the resulting PCR diagnostic through direct testing on primary and held-out models with multiple quantizers. No equations, derivations, or self-citations are present that reduce any claim to fitted parameters or prior self-referential results; all central findings remain independently testable via the described experiments and generalization checks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Quantization noise impacts low-dimensional subspaces more than high-dimensional averages
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2412.19442 , year=
A survey on large language model acceleration based on kv cache management , author=. arXiv preprint arXiv:2412.19442 , year=
-
[2]
2023 , eprint =
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. 2023 , eprint =
2023
-
[3]
and Solla, Sara A
LeCun, Yann and Denker, John S. and Solla, Sara A. , title =. Advances in Neural Information Processing Systems , year =
-
[4]
, title =
Hassibi, Babak and Stork, David G. , title =. Advances in Neural Information Processing Systems , year =
-
[5]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Jacob, Benoit and Kligys, Skirmantas and Chen, Bo and Zhu, Menglong and Tang, Matthew and Howard, Andrew and Adam, Hartwig and Kalenichenko, Dmitry , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =. 1712.05877 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
2018 , eprint =
Choi, Jungwook and Wang, Zhuo and Venkataramani, Swagath and Chuang, Pierce I. 2018 , eprint =
2018
-
[7]
Esser, Steven K. and McKinstry, Jeffrey L. and Bablani, Deepika and Appuswamy, Rathinakumar and Modha, Dharmendra S. , title =. International Conference on Learning Representations , year =. 1902.08153 , archivePrefix =
-
[8]
2016 , eprint =
Zhou, Shuchang and Ni, Zekun and Zhou, Xinyu and Wen, He and Wu, Yuxin and Zou, Yuheng , title =. 2016 , eprint =
2016
-
[9]
Improving Neural Network Quantization without Retraining using Outlier Channel Splitting
Zhao, Ritchie and Hu, Yuwei and Dotzel, Jordan and De Sa, Christopher and Zhang, Zhiru , title =. International Conference on Machine Learning , year =. 1901.09504 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1901
-
[10]
LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , title =. Advances in Neural Information Processing Systems , year =. 2208.07339 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Machine Learning , year =
Xiao, Guangxuan and Lin, Ji and Seznec, Mickael and Wu, Hao and Demouth, Julien and Han, Song , title =. International Conference on Machine Learning , year =. 2211.10438 , archivePrefix =
-
[12]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, Elias and Alistarh, Dan , title =. International Conference on Learning Representations , year =. 2210.17323 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei. Proceedings of Machine Learning and Systems , year =. 2306.00978 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2023 , eprint =
Chee, Jerry and Cai, Yaohui and Kuleshov, Volodymyr and De Sa, Christopher , title =. 2023 , eprint =
2023
-
[15]
2024 , eprint =
Tseng, Albert and others , title =. 2024 , eprint =
2024
-
[16]
arXiv preprint arXiv:2306.03078 , year=
Dettmers, Tim and Svirschevski, Ruslan and Egiazarian, Vage and Kuznedelev, Denis and Frantar, Elias and Ashkboos, Saleh and Borzunov, Alexander and Hoefler, Torsten and Alistarh, Dan , title =. International Conference on Learning Representations , year =. 2306.03078 , archivePrefix =
-
[17]
Advances in Neural Information Processing Systems , year =
Yao, Zhewei and Yazdani Aminabadi, Reza and Zhang, Minjia and Wu, Xiaoxia and Li, Conglong and He, Yuxiong , title =. Advances in Neural Information Processing Systems , year =. 2206.01861 , archivePrefix =
-
[18]
2023 , eprint =
Shao, Wenqi and Chen, Mengzhao and Zhang, Zhaoyang and Xu, Peng and Zhao, Lirui and Li, Zhiqian and Zhang, Kaipeng and Gao, Peng and Qiao, Yu and Luo, Ping , title =. 2023 , eprint =
2023
-
[19]
HAQ: Hardware-Aware Automated Quantization with Mixed Precision
Wang, Kuan and Liu, Zhijian and Lin, Yujun and Lin, Ji and Han, Song , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =. 1811.08886 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
and Keutzer, Kurt , title =
Dong, Zhen and Yao, Zhewei and Gholami, Amir and Mahoney, Michael W. and Keutzer, Kurt , title =. 2019 , eprint =
2019
-
[21]
Dong, Zhen and Yao, Zhewei and Cai, Yaohui and Arfeen, Daiyaan and Gholami, Amir and Mahoney, Michael W. and Keutzer, Kurt , title =. Advances in Neural Information Processing Systems , year =. 1911.03852 , archivePrefix =
-
[22]
2021 , eprint =
Li, Yuhang and Gong, Ruihao and Tan, Xu and Yang, Yang and Hu, Peng and Zhang, Qi and Yu, Fengwei and Wang, Wei and Gu, Shi , title =. 2021 , eprint =
2021
-
[23]
Shen, Sheng and Dong, Zhen and Ye, Ji and Ma, Lin and Yao, Zhewei and Gholami, Amir and Mahoney, Michael W. and Keutzer, Kurt , title =. AAAI Conference on Artificial Intelligence , year =. 1909.05840 , archivePrefix =
-
[24]
International Conference on Learning Representations , year =
Dettmers, Tim and Lewis, Mike and Shleifer, Sam and Zettlemoyer, Luke , title =. International Conference on Learning Representations , year =. 2110.02861 , archivePrefix =
-
[25]
Advances in Neural Information Processing Systems , year =
Li, Bingrui and others , title =. Advances in Neural Information Processing Systems , year =. 2309.01507 , archivePrefix =
-
[26]
QLoRA: Efficient Finetuning of Quantized LLMs
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , title =. Advances in Neural Information Processing Systems , year =. 2305.14314 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2022 , eprint =
Micikevicius, Paulius and Stosic, Dusan and Burgess, Neil and Cornea, Marius and Dubey, Pradeep and Grisenthwaite, Richard and Ha, Sangwon and Heinecke, Alexander and Judd, Patrick and Kamalu, John and Mellempudi, Naveen and Oberman, Stuart and Shoeybi, Mohammad and Siu, Michael and Wu, Hao , title =. 2022 , eprint =
2022
-
[28]
2020 , eprint =
Wu, Hao and Judd, Patrick and Zhang, Xiaojie and Isaev, Michael and Micikevicius, Paulius , title =. 2020 , eprint =
2020
-
[29]
Advances in Neural Information Processing Systems , year =
Liu, Xiang and Tang, Zhenheng and Dong, Peijie and Li, Zeyu and Liu, Yue and Li, Bo and Hu, Xuming and Chu, Xiaowen , title =. Advances in Neural Information Processing Systems , year =
-
[30]
and Yun, Sangdoo and Song, Hyun Oh , title =
Kim, Jang-Hyun and Kim, Jinuk and Kwon, Sangwoo and Lee, Jae W. and Yun, Sangdoo and Song, Hyun Oh , title =. Advances in Neural Information Processing Systems , year =
-
[31]
Kevin , title =
Feng, Yuan and Lv, Junlin and Cao, Yukun and Xie, Xike and Zhou, S. Kevin , title =. Advances in Neural Information Processing Systems , year =
-
[32]
Advances in Neural Information Processing Systems , year =
Wang, Ao and Chen, Hui and Tan, Jianchao and Zhang, Kefeng and Cai, Xunliang and Lin, Zijia and Han, Jungong and Ding, Guiguang , title =. Advances in Neural Information Processing Systems , year =
-
[33]
Advances in Neural Information Processing Systems , year =
Zhao, Yi and Peng, Yajuan and Nguyen, Cam-Tu and Li, Zuchao and Wang, Xiaoliang and Zhao, Hai and Fu, Xiaoming , title =. Advances in Neural Information Processing Systems , year =
-
[34]
and Goel, Raghavv and Lee, Mingu and Lott, Chris , title =
Park, Junyoung and Jones, Dalton and Morse, Matthew J. and Goel, Raghavv and Lee, Mingu and Lott, Chris , title =. Advances in Neural Information Processing Systems , year =
-
[35]
Advances in Neural Information Processing Systems , year =
Sengupta, Ayan and Chaudhary, Siddhant and Chakraborty, Tanmoy , title =. Advances in Neural Information Processing Systems , year =
-
[36]
Advances in Neural Information Processing Systems , year =
Mu, Junlin and Huang, Hantao and Zhang, Jihang and Yu, Minghui and Wang, Tao and Li, Yidong , title =. Advances in Neural Information Processing Systems , year =
-
[37]
Advances in Neural Information Processing Systems , year =
Son, Donghyun and Choi, Euntae and Yoo, Sungjoo , title =. Advances in Neural Information Processing Systems , year =
-
[38]
Advances in Neural Information Processing Systems , year =
Wu, Songhao and Lv, Ang and Feng, Xiao and Zhang, Yufei and Zhang, Xun and Yin, Guojun and Lin, Wei and Yan, Rui , title =. Advances in Neural Information Processing Systems , year =
-
[39]
Advances in Neural Information Processing Systems , year =
Yang, Qingyue and Wang, Jie and Li, Xing and Wang, Zhihai and Chen, Chen and Chen, Lei and Yu, Xianzhi and Liu, Wulong and Hao, Jianye and Yuan, Mingxuan and Li, Bin , title =. Advances in Neural Information Processing Systems , year =
-
[40]
, title =
Lancucki, Adrian and Staniszewski, Konrad and Nawrot, Piotr and Ponti, Edoardo M. , title =. Advances in Neural Information Processing Systems , year =
-
[41]
Advances in Neural Information Processing Systems , year =
Ma, Xinyin and Yu, Runpeng and Fang, Gongfan and Wang, Xinchao , title =. Advances in Neural Information Processing Systems , year =
-
[42]
2023 , eprint =
Instruction-Following Evaluation for Large Language Models , author =. 2023 , eprint =
2023
-
[43]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
Mazeika, Mantas and Phan, Long and Yin, Xuwang and Zou, Andy and Wang, Zifan and Mu, Norman and Sakhaee, Elham and Li, Nathaniel and Basart, Steven and Li, Bo and Forsyth, David and Hendrycks, Dan , year =. 2402.04249 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , booktitle =
-
[45]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and Khabsa, Madian , year =. Llama Guard:. 2312.06674 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
H$_2$O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R. Advances in Neural Information Processing Systems , year =. 2306.14048 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Efficient Streaming Language Models with Attention Sinks
Xiao, Guangxuan and Tian, Yuandong and Chen, Beidi and Han, Song and Lewis, Mike , title =. International Conference on Learning Representations , year =. 2309.17453 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , title =. International Conference on Machine Learning , year =. 2402.02750 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Hooper, Coleman and Kim, Sehoon and Mohammadi, Hiva and Mahoney, Michael W. and Shao, Yakun Sophia and Keutzer, Kurt and Gholami, Amir , title =. Advances in Neural Information Processing Systems , year =. 2401.18079 , archivePrefix =
-
[50]
2023 , howpublished =
Gerganov, Georgi , title =. 2023 , howpublished =
2023
-
[51]
Training language models to follow instructions with human feedback
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and others , title =. Advances in Neural Information Processing Systems , year =. 2203.02155 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
XSTest: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models
R. arXiv preprint arXiv:2308.01263 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Advances in Neural Information Processing Systems , year =
Arditi, Andy and Obeso, Oscar and Syed, Aaquib and Paleka, Daniel and Panickssery, Nina and Gurnee, Wes and Nanda, Neel , title =. Advances in Neural Information Processing Systems , year =
-
[54]
International Conference on Machine Learning , year =
Pan, Wenbo and Liu, Zhichao and Chen, Qiguang and Zhou, Xiangyang and Yu, Haining and Jia, Xiaohua , title =. International Conference on Machine Learning , year =
-
[55]
International Conference on Learning Representations , year =
Qi, Xiangyu and Panda, Ashwinee and Lyu, Kaifeng and Ma, Xiao and Roy, Subhrajit and Beirami, Ahmad and Mittal, Prateek and Henderson, Peter , title =. International Conference on Learning Representations , year =
-
[56]
Advances in Neural Information Processing Systems , year =
Egashira, Kazuki and Vero, Mark and Staab, Robin and He, Jingxuan and Vechev, Martin , title =. Advances in Neural Information Processing Systems , year =
-
[57]
International Conference on Machine Learning , year =
Chen, Kejia and Zhang, Jiawen and Hu, Jiacong and Wang, Yu and Lou, Jian and Feng, Zunlei and Song, Mingli , title =. International Conference on Machine Learning , year =
-
[58]
Advances in Neural Information Processing Systems , year =
Ashkboos, Saleh and Mohtashami, Amirkeivan and Croci, Maximilian and Li, Bo and Cameron, Pashmina and Jaggi, Martin and Alistarh, Dan and Hoefler, Torsten and Hensman, James , title =. Advances in Neural Information Processing Systems , year =
-
[59]
International Conference on Learning Representations , year =
Liu, Zechun and Zhao, Changsheng and Fedorov, Igor and Soran, Bilge and Choudhary, Dhruv and Krishnamoorthi, Raghuraman and Chandra, Vikas and Tian, Yuandong and Blankevoort, Tijmen , title =. International Conference on Learning Representations , year =
-
[60]
Advances in Neural Information Processing Systems , year =
Zhang, Tianyi and Yi, Jonah and Xu, Zhaozhuo and Shrivastava, Anshumali , title =. Advances in Neural Information Processing Systems , year =
-
[61]
International Conference on Machine Learning , year =
Li, Xing and Xing, Zeyu and Li, Yiming and Qu, Linping and Zhen, Hui-Ling and Liu, Wulong and Yao, Yiwu and Pan, Sinno Jialin and Yuan, Mingxuan , title =. International Conference on Machine Learning , year =
-
[62]
and Ermon, Stefano and Rudra, Atri and R
Dao, Tri and Fu, Daniel Y. and Ermon, Stefano and Rudra, Atri and R. Advances in Neural Information Processing Systems , year =
-
[63]
International Conference on Machine Learning , year =
Leviathan, Yaniv and Kalman, Matan and Matias, Yossi , title =. International Conference on Machine Learning , year =
-
[64]
Jiang, Albert Q. and Sablayrolles, Alexandre and Mensch, Arthur and Bamford, Chris and Chaplot, Devendra Singh and de Las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lavaud, L. Mistral 7B , journal =
-
[65]
Jiang, Albert Q. and Sablayrolles, Alexandre and Roux, Antoine and Mensch, Arthur and Savary, Blanche and Bamford, Chris and Chaplot, Devendra Singh and de Las Casas, Diego and Bressand, Florian and Lengyel, Gianna and Lample, Guillaume and Saulnier, Lucile and Lachaux, Marie-Anne and Stock, Pierre and Subramanian, Sandeep and Le Scao, Teven and Lavril, T...
-
[66]
Yang, An and Yang, Baosong and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Li, Chengyuan and Liu, Dayiheng and Huang, Fei and Lin, Junyang and others , title =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[67]
Yi: Open Foundation Models by 01.AI
Young, Alex and Chen, Bei and Li, Chao and Huang, Chengen and Zhang, Ge and Zhang, Guanwei and Li, Heng and Zhu, Jiangcheng and Chen, Jianqun and others , title =. arXiv preprint arXiv:2403.04652 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
Bi, Xiao and Chen, Deli and Chen, Guanting and Chen, Shanhuang and Dai, Damai and Deng, Chengqi and Ding, Honghui and Dong, Kai and Du, Qiushi and Fu, Zhe and others , title =. arXiv preprint arXiv:2401.02954 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[69]
Grattafiori, Aaron and others , title =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Gemma 2: Improving Open Language Models at a Practical Size , journal =
-
[71]
Mistral Small 3 , year =
-
[72]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Abdin, Marah and Jacobs, Sam Ade and Awan, Ammar Ahmad and Aneja, Jyoti and Awadallah, Ahmed and Awadalla, Hany and Bach, Nguyen and Bahree, Amit and Bakhtiari, Arash and others , title =. arXiv preprint arXiv:2404.14219 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[73]
2. arXiv preprint arXiv:2501.00656 , year =
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.