ASTRA-sim 3.0: Next-Level Distributed Machine Learning Simulations via High-Fidelity GPU and Infrastructure Modeling
Pith reviewed 2026-06-27 12:07 UTC · model grok-4.3
The pith
ASTRA-sim 3.0 models distributed ML systems at cache-line granularity with a detailed GPU execution model and InfraGraph infrastructure representation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
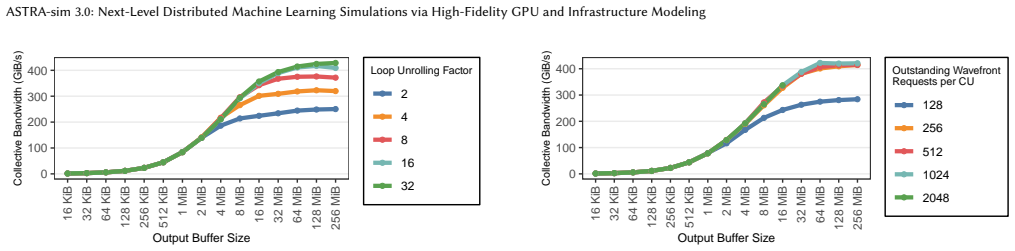
The central claim is that simulation at cache-line-sized load-store granularity combined with a detailed GPU execution model and the InfraGraph representation produces high-fidelity results for distributed ML infrastructure, opening design space explorations for optimized collective algorithms, network requirements, and GPU architectures.
What carries the argument
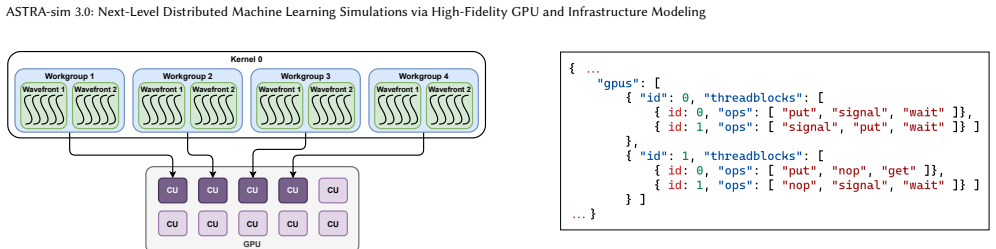
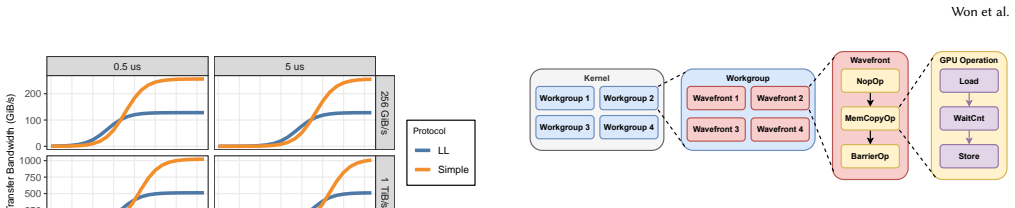
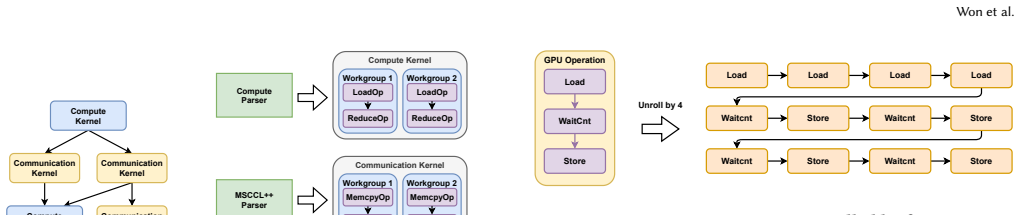
Cache-line-sized load-store granularity simulation together with a detailed GPU execution model and InfraGraph, a standardized representation for capturing distributed ML network infrastructure in detail.
If this is right
- Designers can evaluate collective communication algorithms with higher timing accuracy than coarser simulators allow.
- Network requirements for distributed ML workloads can be assessed by varying infrastructure details captured in InfraGraph.
- GPU architecture choices can be compared for their effects on end-to-end ML performance through simulation.
- A shared infrastructure representation supports consistent experiments across different research groups.
Where Pith is reading between the lines
- The same granularity approach might expose communication bottlenecks that appear only under specific data movement patterns.
- InfraGraph could serve as a starting point for automated tools that generate simulation inputs from real cluster descriptions.
- If the fidelity holds, repeated simulation runs could replace some physical benchmarking cycles when exploring new hardware.
Load-bearing premise
Modeling operations at cache-line granularity with a detailed GPU model strikes an effective balance between simulation accuracy and the ability to run large-scale experiments.
What would settle it
Compare predicted collective operation latencies from ASTRA-sim 3.0 against measured latencies on real GPU clusters running the same workloads at the same scale.
Figures




read the original abstract
Distributed machine learning (ML) is a key paradigm for today's large-scale artificial intelligence applications. As model inference arises as an important use case, faithful modeling of latency-sensitive collective communication has never been more important. Capturing the device architecture and modeling control and data paths at high fidelity is therefore a necessity today. Having a common, detailed representation for distributed ML infrastructure is also crucial. We revisit the promising open-source, community-driven simulator: ASTRA-sim. In this work, we identify limitations of the current ASTRA-sim simulator and augment it with new features. To this end, we enable fine-grained, high-fidelity simulation with a standardized infrastructure representation, opening new design space exploration opportunities. We propose the simulation at cache-line-sized load-store granularity, with a detailed graphics processing unit (GPU) execution model, to balance simulation scalability and fidelity. We also introduce InfraGraph, a standardized representation to capture distributed ML network infrastructure in detail. Using the updated ASTRA-sim 3.0 simulator, we showcase interesting design space explorations for designing optimized collective algorithms, network requirements, and GPU architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ASTRA-sim 3.0, an update to the open-source distributed ML simulator. It augments the prior version with cache-line-sized load-store granularity simulation, a detailed GPU execution model, and InfraGraph, a standardized representation of distributed ML network infrastructure. The central claim is that these additions balance simulation scalability and fidelity, thereby enabling new design-space explorations for optimized collective algorithms, network requirements, and GPU architectures.
Significance. If the added fidelity proves accurate, the simulator could provide a shared, high-detail platform for exploring distributed ML systems without physical hardware access, potentially accelerating optimization of collectives and architectures. The introduction of InfraGraph offers a concrete standardization benefit. However, the manuscript supplies no hardware validation or scaling data, so the practical significance remains prospective rather than demonstrated.
major comments (2)
- [Abstract / Modeling Approach] The abstract states that cache-line-sized load-store granularity together with the detailed GPU execution model 'strikes an effective balance between simulation scalability and fidelity,' yet the manuscript presents no quantitative validation (e.g., simulated vs. measured all-reduce latency on real multi-GPU hardware) or wall-clock scaling curves versus system size to support this modeling assumption.
- [Evaluation / Design Space Exploration] The showcased design-space explorations for collective algorithms, network requirements, and GPU architectures are presented as actionable, but without any reported error metrics or hardware correlation in the results, it is impossible to determine whether the new fidelity level produces outputs accurate enough to guide real design decisions.
minor comments (1)
- [Implementation] Clarify the exact interface changes between ASTRA-sim 2.x and 3.0 so that existing users can assess migration effort.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback highlighting the need for validation to support claims about modeling balance and actionable design-space results. We address each major comment below and outline planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Modeling Approach] The abstract states that cache-line-sized load-store granularity together with the detailed GPU execution model 'strikes an effective balance between simulation scalability and fidelity,' yet the manuscript presents no quantitative validation (e.g., simulated vs. measured all-reduce latency on real multi-GPU hardware) or wall-clock scaling curves versus system size to support this modeling assumption.
Authors: The referee correctly notes the absence of quantitative validation or scaling curves. The manuscript introduces the new features and demonstrates their application through design-space examples, with the balance claim reflecting the intended modeling rationale rather than empirical proof. We will revise the abstract to qualify this as a design objective supported by the granularity choices (cache-line level to capture key memory effects without full byte-level cost) and add a limitations section discussing validation plans. This addresses the concern without misrepresenting the current content. revision: yes
-
Referee: [Evaluation / Design Space Exploration] The showcased design-space explorations for collective algorithms, network requirements, and GPU architectures are presented as actionable, but without any reported error metrics or hardware correlation in the results, it is impossible to determine whether the new fidelity level produces outputs accurate enough to guide real design decisions.
Authors: We agree that without error metrics or hardware correlation, the results cannot be assessed for guiding real decisions. The explorations serve to illustrate the new simulator capabilities for such studies. We will revise the evaluation section to explicitly note this limitation, reframe the results as capability demonstrations rather than validated recommendations, and discuss how the added fidelity enables future validated explorations. This ensures readers interpret the findings in context. revision: yes
- Hardware validation data and error metrics for the new cache-line and GPU models, which are not present in the manuscript and cannot be supplied without additional experiments.
Circularity Check
No circularity: tool-description paper with no derivations or fitted predictions
full rationale
The manuscript describes an updated simulator (ASTRA-sim 3.0) and its new modeling features (cache-line granularity, GPU execution model, InfraGraph). It presents example design-space explorations but contains no equations, parameter fits, predictions derived from data, or uniqueness theorems. The central claim is that the added fidelity enables explorations; this is an engineering claim resting on the modeling choices themselves, not on any reduction of outputs to inputs by construction. No self-citation chains or ansatzes are invoked to justify results. The work is therefore self-contained against external benchmarks and receives score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AMD. [n. d.].AMD CDNA 4 Architecture. Accessed: 2026-04-30. https://www.amd.com/content/dam/amd/en/documents/instinct-tech- docs/white-papers/amd-cdna-4-architecture-whitepaper.pdf
2026
-
[2]
Zixian Cai, Zhengyang Liu, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, and Olli Saarikivi. 2021. Synthesizing optimal collective algorithms. InProc. undefined. 62–75. arXiv:2008.08708 [cs] doi:10.1145/3437801.3441620
-
[3]
Francisco Caravaca, Ángel Cuevas, and Rubén Cuevas. 2025. From Prompts to Power: Measuring the Energy Footprint of LLM Inference.arXiv:2511.05597 [cs.AI](2025). doi:10.48550/arXiv.2511.05597
-
[4]
Xin Chen, Xiaoyang Wang, Ana Colacelli, Matt Lee, and Le Xie. 2025. Electricity Demand and Grid Impacts of AI Data Centers: Challenges and Prospects. (2025). doi:10.48550/arXiv.2509.07218
-
[5]
Ziteng Chen, Xiaohe Hu, Menghao Zhang, Yanmin Jia, Yan Zhang, Mingjun Zhang, Da Liu, Fangzheng Jiao, Jun Chen, He Liu, Aohan Zeng, Shuaixing Duan, Ruya Gu, Yang Jing, Bowen Han, Jiahao Cao, Wei Chen, Wenqi Xie, Jinlong Hou, Yuan Cheng, Bohua Xu, Mingwei Xu, and Chunming Hu. 2025. An Efficient, Reliable and Observable Collective Communication Library in La...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.00991 2025
-
[6]
Jaehong Cho, Hyunmin Choi, Guseul Heo, and Jongse Park. 2026. LLMServ- ingSim 2.0: A Unified Simulator for Heterogeneous and Disaggregated LLM Serv- ing Infrastructure.arXiv:2602.23036 [cs](2026). doi:10.48550/arXiv.2602.23036
-
[7]
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, and Jongse Park. 2024. LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale. InProc. 2024 IEEE International Symposium on Workload Char- acterization (IISWC). 15–29. doi:10.1109/IISWC63097.2024.00012
-
[8]
Sanghun Cho, Hyojun Son, and John Kim. 2023. Logical/Physical Topology- Aware Collective Communication in Deep Learning Training. InProc. 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). 56–68. doi:10.1109/HPCA56546.2023.10071117
-
[9]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. MSCCLang: Microsoft collective communication language. InProc. 28th ACM International Conference on Architectural Support for Programming Lan- guages and Operating Systems (ASPLOS). 502–514. doi:10.1145/3575693.3575724
-
[10]
2026.DeepSeek-V4: Towards Highly Efficient Million-Token Con- text Intelligence
DeepSeek-AI. 2026.DeepSeek-V4: Towards Highly Efficient Million-Token Con- text Intelligence. Accessed: 2026-05-01. https://huggingface.co/deepseek- ai/DeepSeek-V4-Pro/blob/main/DeepSeek_V4.pdf
2026
-
[11]
2023.Arcadia: An end-to-end AI system performance sim- ulator
Engineering at Meta. 2023.Arcadia: An end-to-end AI system performance sim- ulator. Accessed: 2026-05-20. https://engineering.fb.com/2023/09/07/data- ASTRA-sim 3.0: Next-Level Distributed Machine Learning Simulations via High-Fidelity GPU and Infrastructure Modeling infrastructure/arcadia-end-to-end-ai-system-performance-simulator/
2023
-
[12]
Epoch AI. [n. d.].Trends in Artificial Intelligence. Accessed: 2026-05-01. https: //epoch.ai/trends
2026
-
[13]
William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch Transform- ers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. arXiv:2101.03961 [cs](2022). doi:10.48550/arXiv.2101.03961
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.03961 2022
-
[14]
gem5. [n. d.].gem5: Interconnection network. Accessed: 2026-05-06. https://www. gem5.org/documentation/general_docs/ruby/interconnection-network/
2026
-
[15]
Prasun Gera, Hyojong Kim, Hyesoon Kim, Sunpyo Hong, Vinod George, and Chi-Keung Luk. 2018. Performance Characterisation and Simulation of Intel’s Integrated GPU Architecture. InProc. 2018 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 139–148. doi:10.1109/ ISPASS.2018.00027
arXiv 2018
-
[16]
Google Cloud. [n. d.].What is a GPU & Its Importance for AI. Accessed: 2026-05-16. https://cloud.google.com/discover/gpu-for-ai
2026
-
[17]
GPGPU-Sim. [n. d.].GPGPU-Sim. Accessed: 2026-05-21. https://gpgpu-sim.org/
2026
-
[18]
Thomas R Henderson, Mathieu Lacage, and George F Riley. 2008. Network Simulations with the ns-3 Simulator. InProc. Special Interest Group on Data Communication Conference (SIGCOMM)
2008
-
[19]
Roger W. Hockney. 1994. The Communication Challenge for MPP: Intel Paragon and Meiko CS-2.Parallel Comput.20 (1994), 389–398. https://api.semanticscholar. org/CorpusID:22986998
1994
-
[20]
Jiayi Huang, Pritam Majumder, Sungkeun Kim, Abdullah Muzahid, Ki Hwan Yum, and Eun Jung Kim. 2021. Communication algorithm-architecture co-design for distributed deep learning. InProc. 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA). 181–194. doi:10.1109/ISCA52012. 2021.00023
-
[21]
Mikhail Isaev, Nic McDonald, Larry Dennison, and Richard Vuduc. 2023. Calculon: A Methodology and Tool for High-Level Co-Design of Systems and Large Lan- guage Models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’23). Association for Computing Machinery, New York, NY, USA, Article 71, ...
-
[22]
2019.Massively Scale Your Deep Learning Training with NCCL 2.4
Sylvain Jeaugey. 2019.Massively Scale Your Deep Learning Training with NCCL 2.4. Accessed: 2026-05-06. https://developer.nvidia.com/blog/massively-scale- deep-learning-training-nccl-2-4/
2019
-
[23]
Chelsea Maria John, Stepan Nassyr, Carolin Penke, and Andreas Herten. 2024. Performance and Power: Systematic Evaluation of AI Workloads on Accelera- tors with CARAML. InProc. SC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1164–1176. doi:10.1109/SCW63240.2024.00158
-
[24]
Mahmoud Khairy, Zhesheng Shen, Tor M. Aamodt, and Timothy G. Rogers. 2020. Accel-Sim: An Extensible Simulation Framework for Validated GPU Modeling. InProc. 47th Annual International Symposium on Computer Architecture (ISCA). 473–486. doi:10.1109/ISCA45697.2020.00047
-
[25]
Heehoon Kim, Junyeol Ryu, and Jaejin Lee. 2024. TCCL: Discovering better communication paths for pcie GPU clusters. InProc. 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS). 999–1015. doi:10.1145/3620666.3651362
-
[26]
Sabuj Laskar, Pranati Majhi, Sungkeun Kim, Farabi Mahmud, Abdullah Muzahid, and Eun Jung Kim. 2024. Enhancing collective communication in MCM acceler- ators for deep learning training. InProc. 2024 IEEE International Symposium on High-Performance Computer Architecture (HPCA). doi:10.1109/HPCA57654.2024. 00069
-
[27]
Ying Li, Yuhui Bao, Gongyu Wang, Xinxin Mei, Pranav Vaid, Anandaroop Ghosh, Adwait Jog, Darius Bunandar, Ajay Joshi, and Yifan Sun. 2025. TrioSim: A Light- weight Simulator for Large-Scale DNN Workloads on Multi-GPU Systems. In Proceedings of the 52nd Annual International Symposium on Computer Architec- ture (ISCA ’25). Association for Computing Machinery...
-
[28]
Xuting Liu, Behnaz Arzani, Siva Kesava Reddy Kakarla, Liangyu Zhao, Vincent Liu, Miguel Castro, Srikanth Kandula, and Luke Marshall. 2024. Rethinking Ma- chine Learning Collective Communication as a Multi-Commodity Flow Problem. InProc. Special Interest Group on Data Communication Conference (SIGCOMM). 16–37. doi:10.1145/3651890.3672249
-
[29]
Jason Lowe-Power, Abdul Mutaal Ahmad, Ayaz Akram, Mohammad Alian, Rico Amslinger, Matteo Andreozzi, Adrià Armejach, Nils Asmussen, Brad Beckmann, Srikant Bharadwaj, Gabe Black, Gedare Bloom, Bobby R. Bruce, Daniel Rodrigues Carvalho, Jeronimo Castrillon, Lizhong Chen, Nicolas Derumigny, Stephan Di- estelhorst, Wendy Elsasser, Carlos Escuin, Marjan Faribor...
-
[30]
Junchao Ma, Dezun Dong, Cunlu Li, Ke Wu, and Liquan Xiao. 2021. PAARD: Proximity-Aware All-Reduce Communication for Dragonfly Networks. InProc. 2021 IEEE Intl. Conf. on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, So- cial Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom)...
work page doi:10.1109/ispa-bdcloud-socialcom-sustaincom52081.2021.00045 2021
-
[31]
Changhai Man, Joongun Park, Hanjiang Wu, Huan Xu, Srinivas Sridharan, and Tushar Krishna. 2025. STAGE: A Symbolic Tensor grAph GEnerator for dis- tributed AI system co-design.arXiv:2511.10480 [cs](2025). doi:10.48550/arXiv. 2511.10480
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[32]
2025.MPI: A Message-Passing Interface Stan- dard
Message Passing Interface Forum. 2025.MPI: A Message-Passing Interface Stan- dard. Accessed: 2026-05-18. https://www.mpi-forum.org/docs/mpi-5.0/mpi50- report.pdf
2025
-
[33]
NVIDIA. [n. d.].Pascal Tuning Guide - Pascal Tuning Guide 13.2 documentation. Accessed: 2026-05-20. https://docs.nvidia.com/cuda/pascal-tuning-guide/index. html
2026
-
[34]
James O’Donnell and Casey Crownhart. [n. d.].We did the math on AI’s energy footprint. Here’s the story you haven’t heard.MIT Technology Review. Accessed: 2026-05-14. https://www.technologyreview.com/2025/05/20/1116327/ai-energy- usage-climate-footprint-big-tech/
2026
-
[35]
2026.Introducing Stargate Norway
OpenAI. 2026.Introducing Stargate Norway. Accessed: 2026-05-14. https: //openai.com/index/introducing-stargate-norway/
2026
-
[36]
2022.The Real Price of AI: Pre-Training Vs
Ankur Patel. 2022.The Real Price of AI: Pre-Training Vs. Inference Costs. Ac- cessed: 2026-05-13. https://www.ankursnewsletter.com/p/the-real-price-of-ai- pre-training
2022
-
[37]
Jianxing Qin, Jingrong Chen, Xinhao Kong, Yongji Wu, Tianjun Yuan, Liang Luo, Zhaodong Wang, Ying Zhang, Tingjun Chen, Alvin R. Lebeck, and Danyang Zhuo. 2025. Phantora: Maximizing Code Reuse in Simulation-based Machine Learning System Performance Estimation.arXiv:2505.01616 [cs.DC](2025). doi:10. 48550/arXiv.2505.01616
arXiv 2025
-
[38]
Saeed Rashidi, Pallavi Shurpali, Srinivas Sridharan, Naader Hassani, Dheevatsa Mudigere, Krishnakumar Nair, Misha Smelyanski, and Tushar Krishna. 2020. Scalable Distributed Training of Recommendation Models: An ASTRA-SIM + NS3 case-study with TCP/IP transport. InProc. 2020 IEEE Symposium on High- Performance Interconnects (HOTI). 33–42. doi:10.1109/HOTI51...
-
[39]
Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna
-
[40]
ASTRA-SIM: Enabling SW/HW Co-Design Exploration for Distributed DL Training Platforms. InProc. 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 81–92. doi:10.1109/ISPASS48437.2020. 00018
-
[41]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musu- vathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL: Guiding Collective Algorithm Synthesis using Communication Sketches. InProc. USENIX Symposium on Networked Systems Design and Implementation (NSDI)
2023
-
[42]
Aashaka Shah, Abhinav Jangda, Binyang Li, Caio Rocha, Changho Hwang, Jithin Jose, Madan Musuvathi, Olli Saarikivi, Peng Cheng, Qinghua Zhou, Roshan Dathathri, Saeed Maleki, and Ziyue Yang. 2025. MSCCL++: Rethinking GPU communication abstractions for cutting-edge AI applications.arXiv:2504.09014 [cs](2025). doi:10.48550/arXiv.2504.09014
-
[43]
Siyuan Shen, Tommaso Bonato, Zhiyi Hu, Pasquale Jordan, Tiancheng Chen, and Torsten Hoefler. 2025. ATLAHS: An Application-centric Network Simulator Toolchain for AI, HPC, and Distributed Storage.arXiv:2505.08936 [cs.DC](2025). doi:10.48550/arXiv.2505.08936
-
[44]
Srinivas Sridharan, Taekyung Heo, Louis Feng, Zhaodong Wang, Matt Bergeron, Wenyin Fu, Shengbao Zheng, Brian Coutinho, Saeed Rashidi, Changhai Man, and Tushar Krishna. 2023. Chakra: Advancing Performance Benchmarking and Co-design using Standardized Execution Traces.arXiv:2305.14516 [cs](2023)
arXiv 2023
-
[45]
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. 2005. Optimization of Collective Communication Operations in MPICH.The International Journal of High Performance Computing Applications19, 1 (2005), 49–66. doi:10.1177/ 1094342005051521
2005
-
[46]
Guanhua Wang, Shivaram Venkataraman, Amar Phanishayee, Jorgen Thelin, Nikhil Devanur, and Ion Stoica. 2019. Blink: Fast and Generic Collectives for Distributed ML. InProc. Conference on Systems and Machine Learning (SysML)
2019
-
[47]
Haonan Wang, Xuxin Xiao, Mingyu Yan, Zhuoyuan Zhu, Dengke Han, Duo Wang, Wenming Li, Xiaochun Ye, Cunchen Hu, Hongyang Chen, and Guangyu Sun
-
[48]
A Systematic Characterization of LLM Inference on GPUs.arXiv:2512.01644 [cs](2025). doi:10.48550/arXiv.2512.01644
-
[49]
Xizheng Wang, Qingxu Li, Yichi Xu, Gang Lu, Dan Li, Li Chen, Heyang Zhou, Linkang Zheng, Sen Zhang, Yikai Zhu, Yang Liu, Pengcheng Zhang, Kun Qian, Kunling He, Jiaqi Gao, Ennan Zhai, Dennis Cai, and Binzhang Fu. 2025. SimAI: Won et al. unifying architecture design and performance tuning for large-scale large lan- guage model training with scalability and ...
2025
-
[50]
William Won, Midhilesh Elavazhagan, Sudarshan Srinivasan, Swati Gupta, and Tushar Krishna. 2024. TACOS: topology-aware collective algorithm synthesizer for distributed machine learning. InProc. 57th IEEE/ACM International Symposium on Microarchitecture (MICRO). 856–870. doi:10.1109/MICRO61859.2024.00068
-
[51]
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudarshan Srinivasan, and Tushar Krishna. 2023. ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale. In Proc. 2023 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 283–294. doi:10.1109/ISPASS57527.2023.00035
-
[52]
xAI. [n. d.].Colossus: The World’s Largest AI Supercomputer. Accessed: 2026-05-06. https://x.ai/colossus
2026
-
[53]
Srihas Yarlagadda, Amey Agrawal, Elton Pinto, Hakesh Darapaneni, Mitali Mer- atwal, Shivam Mittal, Pranavi Bajjuri, Srinivas Sridharan, and Alexey Tumanov
-
[54]
Maya: Optimizing Deep Learning Training Workloads using GPU Runtime Emulation. InProc. 21st European Conference on Computer Systems (EuroSys). 1738–1758. doi:10.1145/3767295.3769366
-
[55]
2025.Meta’s Infrastructure Evolution and the Advent of AI
Yee Jiun Song and Kaushik Veeraraghavan. 2025.Meta’s Infrastructure Evolution and the Advent of AI. Accessed: 2026-05-06. https://engineering.fb.com/2025/09/ 29/data-infrastructure/metas-infrastructure-evolution-and-the-advent-of-ai/
2025
-
[56]
Jinsun Yoo, ChonLam Lao, Lianjie Cao, Bob Lantz, Minlan Yu, Tushar Krishna, and Puneet Sharma. 2025. Towards Easy and Realistic Network Infrastructure Testing for Large-scale Machine Learning.arXiv:2504.20854 [cs](2025). doi:10. 48550/arXiv.2504.20854
arXiv 2025
-
[57]
Jinsun Yoo, William Won, Meghan Cowan, Nan Jiang, Benjamin Klenk, Srinivas Sridharan, and Tushar Krishna. 2024. Towards a Standardized Representation for Deep Learning Collective Algorithms. InProc. 2024 IEEE Symposium on High- Performance Interconnects (HOTI). 33–36. doi:10.1109/HOTI63208.2024.00017
-
[58]
Haidong Zhao and Nikolaos Georgantas. 2025. ML Inference Scheduling with Pre- dictable Latency. InProc. Proceedings of the Middleware for Autonomous AIoT Sys- tems in the Computing Continuum (MAIoT). 25–30. doi:10.1145/3774901.3778066
-
[59]
Liangyu Zhao, Saeed Maleki, Yuanhong Wang, Zezhou Wang, Ziyue Yang, Hossein Pourreza, and Arvind Krishnamurthy. 2026. ForestColl: Throughput- Optimal Collective Communications on Heterogeneous Network Fabrics. InProc. USENIX Symposium on Networked Systems Design and Implementation (NSDI). arXiv:2402.06787
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.