Deploying Speech-Driven 3D Facial Animation in Unreal Engine for Production-Ready Digital Humans
Pith reviewed 2026-06-27 10:59 UTC · model grok-4.3
The pith
Speech-driven 3D facial animation works directly in Unreal Engine after converting existing datasets to ARKit blendshapes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
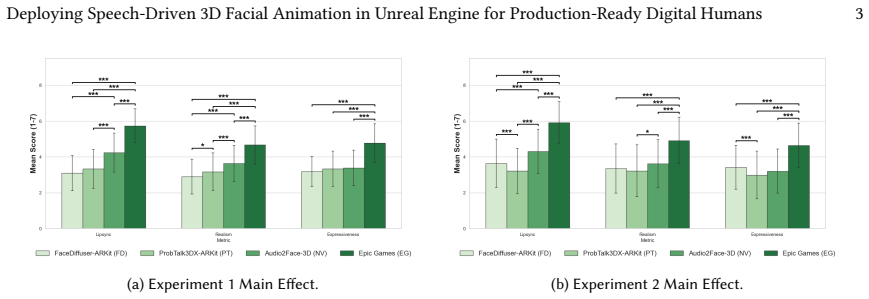
We construct a dataset by converting the MEAD corpus into ARKit-compatible blendshape sequences using MediaPipe, retrain FaceDiffuser and ProbTalk3D-X on it, and integrate them via a modular plugin in Unreal Engine that allows model selection and parameter control. Perceptual studies compare the generated animations to commercial solutions, highlighting the value of cross-pipeline evaluations.
What carries the argument
The modular Unreal Engine plugin with Python backend that integrates the retrained models on the converted dataset and allows selection and control of animation parameters.
Load-bearing premise
The MediaPipe conversion of the MEAD corpus creates blendshape sequences that retain sufficient motion quality and emotional content for retrained models to produce animations suitable for production comparison.
What would settle it
A follow-up perceptual study in which participants rate the system's animations as significantly less natural or expressive than those from the commercial tools across multiple speech inputs.
Figures



read the original abstract
Speech-driven 3D facial animation research has shown promising results, but most methods rely on representations that are not compatible with production pipelines. In this work, we present a deployable system that bridges this gap by enabling speech-driven 3D facial animation directly in Unreal Engine (UE) using ARKit-compatible representations. We construct 3DMEAD-ARKit dataset by converting the MEAD corpus into blendshape sequences using MediaPipe, and retrain FaceDiffuser and ProbTalk3D-X to generate stochastic and emotion controllable animations. We further develop a modular UE plugin with a Python backend that supports model selection, and parameter control. We compare the results to two existing commercial tools: Epic Games' MetaHuman speech-driven animator and Nvidia Audio2Face with a perceptual user study. The results highlight the importance of comparisons among academic and commercial pipelines. We recommend watching the supplementary video. We also plan to do live demonstrations of our work at Siggraph 2026 conference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to bridge academic and commercial pipelines by presenting a deployable speech-driven 3D facial animation system in Unreal Engine using ARKit-compatible blendshapes. It constructs the 3DMEAD-ARKit dataset by converting the MEAD corpus via MediaPipe, retrains FaceDiffuser and ProbTalk3D-X for stochastic and emotion-controllable outputs, develops a modular UE plugin with Python backend, and evaluates against MetaHuman and Audio2Face via a perceptual user study, asserting that such comparisons are important for production-ready digital humans.
Significance. If the MediaPipe conversion of MEAD preserves motion quality and emotion fidelity sufficiently for valid retraining and if the user study is rigorously designed, the work would offer a practical contribution by enabling direct UE deployment of academic models and providing a template for academic-commercial benchmarking in facial animation pipelines.
major comments (2)
- [Abstract] Abstract: The construction of 3DMEAD-ARKit relies on MediaPipe conversion of MEAD to ARKit blendshapes, yet no quantitative metrics (e.g., blendshape error, landmark accuracy, or emotion classification preservation) or discussion of MediaPipe limitations on extreme expressions are provided. This directly undermines the validity of retraining FaceDiffuser and ProbTalk3D-X and the fairness of comparisons to MetaHuman and Audio2Face.
- [Abstract] Abstract: The perceptual user study is presented as demonstrating the importance of academic-commercial comparisons, but supplies no sample size, participant criteria, statistical tests, exclusion rules, or quantitative metrics (e.g., preference scores or significance levels). Without these, the central claim that the results 'highlight the importance' cannot be evaluated.
minor comments (1)
- [Abstract] Abstract: The statement 'We recommend watching the supplementary video' would benefit from an explicit link or DOI reference for accessibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional rigor is needed to support our claims about the dataset conversion and user study. We address each point below and commit to revisions that strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The construction of 3DMEAD-ARKit relies on MediaPipe conversion of MEAD to ARKit blendshapes, yet no quantitative metrics (e.g., blendshape error, landmark accuracy, or emotion classification preservation) or discussion of MediaPipe limitations on extreme expressions are provided. This directly undermines the validity of retraining FaceDiffuser and ProbTalk3D-X and the fairness of comparisons to MetaHuman and Audio2Face.
Authors: We agree that quantitative validation of the MediaPipe conversion step is essential for establishing dataset quality. The current manuscript describes the conversion process at a high level but does not report the requested metrics. In the revised version we will add a dedicated subsection on dataset construction that includes blendshape error, landmark accuracy, and emotion classification preservation metrics computed against ground-truth ARKit data. We will also discuss MediaPipe limitations on extreme expressions and their potential impact on retraining. These additions will directly support the validity of the retrained models and the fairness of the commercial comparisons. revision: yes
-
Referee: [Abstract] Abstract: The perceptual user study is presented as demonstrating the importance of academic-commercial comparisons, but supplies no sample size, participant criteria, statistical tests, exclusion rules, or quantitative metrics (e.g., preference scores or significance levels). Without these, the central claim that the results 'highlight the importance' cannot be evaluated.
Authors: We acknowledge that the abstract and current presentation of the user study lack the methodological details required for rigorous evaluation. The full manuscript contains a user-study section, yet it does not report sample size, participant criteria, statistical tests, exclusion rules, or quantitative results with significance levels. In the revision we will expand both the abstract and the methods/results sections to include these elements (e.g., participant count, recruitment criteria, preference scores, p-values, and exclusion criteria). This will allow readers to properly assess the strength of our claim that the comparisons highlight the importance of academic-commercial benchmarking. revision: yes
Circularity Check
No circularity in derivation chain; applied systems paper
full rationale
This is an applied systems and deployment paper with no mathematical derivations, equations, or first-principles results. The workflow consists of dataset conversion (MEAD via MediaPipe to ARKit blendshapes), retraining of externally published models (FaceDiffuser, ProbTalk3D-X), plugin development, and perceptual comparison to commercial tools. None of the six enumerated circularity patterns apply: there are no self-definitional quantities, fitted inputs relabeled as predictions, load-bearing self-citations, imported uniqueness theorems, smuggled ansatzes, or renamed known results. The central claims rest on engineering implementation and user-study outcomes rather than any reduction to the authors' own prior definitions or fits. The work is therefore self-contained against external benchmarks with a circularity score of 0.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MediaPipe conversion accurately maps MEAD corpus motions to ARKit blendshape sequences without loss of emotion or timing information
- domain assumption Retraining FaceDiffuser and ProbTalk3D-X on the converted dataset produces stochastic and emotion-controllable animations of production quality
Reference graph
Works this paper leans on
-
[1]
Hejia Chen, Haoxian Zhang, Shoulong Zhang, Xiaoqiang Liu, Sisi Zhuang, zhangyuan, Pengfei Wan, Di ZHANG, and Shuai Li. 2025. Cafe-Talk: Generating 3D Talking Face Animation with Multimodal Coarse- and Fine-grained Control. InICLR 2025, Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu (Eds.), Vol. 2025. 17529–17549
2025
-
[2]
2024.ARKit 52 Facial Blendshapes: The Ultimate Guide with Anatomy References for Artists
Pooya Deperson and Melinda Ozel. 2024.ARKit 52 Facial Blendshapes: The Ultimate Guide with Anatomy References for Artists. https://pooyadeperson. com/the-ultimate-guide-to-creating-arkits-52-facial-blendshapes/ Accessed: June 1, 2026
2024
-
[3]
Friesen, and Joseph C
Paul Ekman, Wallace V. Friesen, and Joseph C. Hager. 2002.Facial Action Coding System: The Manual on CD ROM. A Human Face, Salt Lake City, UT. Network Information Research Corp
2002
-
[4]
2022.Live Link Face Importer
Epic Games. 2022.Live Link Face Importer. https://dev.epicgames.com/
2022
-
[5]
Kazi Injamamul Haque, Alkiviadis Pavlou, and Zerrin Yumak. 2025. “Wild West” of Evaluating Speech-Driven 3D Facial Animation Synthesis: A Benchmark Study.Computer Graphics Forum44, 2 (2025), e70073. doi:10.1111/cgf.70073
-
[6]
Kazi Injamamul Haque, Sichun Wu, and Zerrin Yumak. 2025. ProbTalk3D-X: Prosody enhanced non-deterministic emotion controllable speech-driven 3D facial animation synthesis.Computers & Graphics132 (2025), 104358. doi:10.1016/j.cag.2025.104358
-
[7]
Kazi Injamamul Haque and Zerrin Yumak. 2023. FaceXHuBERT: Text-less Speech-driven E(X)pressive 3D Facial Animation Synthesis Using Self-Supervised Speech Representation Learning. InICMI ’23(Paris, France). ACM, New York, NY, USA, 10 pages. doi:10.1145/3577190.3614157
-
[8]
Camillo Lugaresi, Jiuqiang Tang, Hadon Nash, Chris McClanahan, Esha Uboweja, Michael Hays, Fan Zhang, Chuo-Ling Chang, Ming Yong, Juhyun Lee, Wan-Teh Chang, Wei Hua, Manfred Georg, and Matthias Grundmann. 2019. MediaPipe: A Framework for Perceiving and Processing Reality. In Third Workshop on Computer Vision for AR/VR at IEEE Computer Vision and Pattern R...
2019
-
[9]
NVIDIA:, Chaeyeon Chung, Ilya Fedorov, Michael Huang, Aleksey Karmanov, Dmitry Korobchenko, Roger Ribera, and Yeongho Seol. 2025. Audio2Face-3D: Audio-driven Realistic Facial Animation For Digital Avatars. doi:10.48550/ARXIV.2508.16401
-
[10]
Ziqiao Peng, Haoyu Wu, Zhenbo Song, Hao Xu, Xiangyu Zhu, Hongyan Liu, Jun He, and Zhaoxin Fan. 2023. EmoTalk: Speech-Driven Emotional Disentanglement for 3D Face Animation. InProceedings of the IEEE/CVF international conference on computer vision. Deploying Speech-Driven 3D Facial Animation in Unreal Engine for Production-Ready Digital Humans 5
2023
-
[11]
Stefan Stan, Kazi Injamamul Haque, and Zerrin Yumak. 2023. FaceDiffuser: Speech-Driven 3D Facial Animation Synthesis Using Diffusion. InACM SIGGRAPH MIG ’23, November 15–17, 2023, Rennes, France(Rennes, France). ACM, New York, NY, USA, 11 pages. doi:10.1145/3623264.3624447
-
[12]
Sarah Taylor, Salvador Medina, Jonathan Windle, Erica Alcusa Sáez, and Iain Matthews. 2025. xADA: Controllable and Expressive Audio-Driven Animation. InProceedings of SIGGRAPH 2025 Conference Papers. ACM, New York, NY, USA, Article 52, 11 pages. doi:10.1145/3721238.3730711
-
[13]
Kaisiyuan Wang, Qianyi Wu, Linsen Song, Zhuoqian Yang, Wayne Wu, Chen Qian, Ran He, Yu Qiao, and Chen Change Loy. 2020. MEAD: A Large-scale Audio-visual Dataset for Emotional Talking-face Generation. InECCV
2020
-
[14]
Sichun Wu, Kazi Injamamul Haque, and Zerrin Yumak. 2024. ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE. InACM SIGGRAPH MIG ’24(Arlington, VA, USA)(MIG ’24). Association for Computing Machinery, New York, NY, USA, Article 15, 12 pages. doi:10.1145/3677388.3696320 6 Busacchi, Haque and Yumak (a) ...
-
[15]
Cartoon Young Boy Rigged
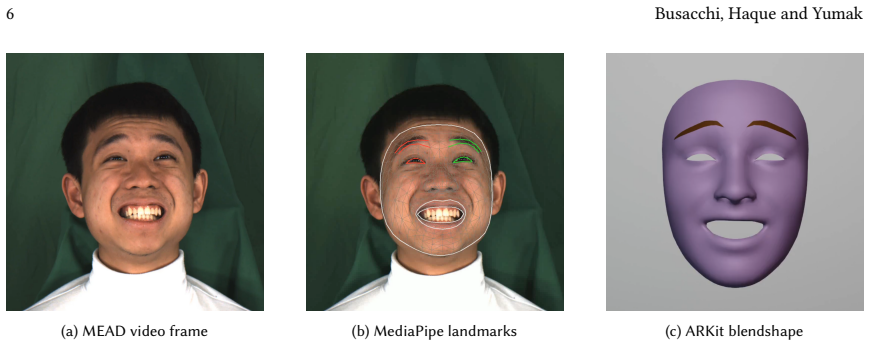
to process the frame-wise video data into frame-wise ARKit blendshape coefficients. The RGB frames are passed to MediaPipe that first detects 3D facial landmarks and then the detected 3D landmarks are regressed into ARKit blendshape coefficients. Fig. 3 demonstrates how an RGB frame (Fig. 3a) is used for detecting facial landmarks (Fig. 3b) that are used ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.