IMPACT: Learning Internal-Model Predictive Control for Forceful Robotic Manipulation
Pith reviewed 2026-06-27 13:02 UTC · model grok-4.3
The pith
A learned internal model enables predictive control of forceful robot manipulations without force sensors or per-object tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
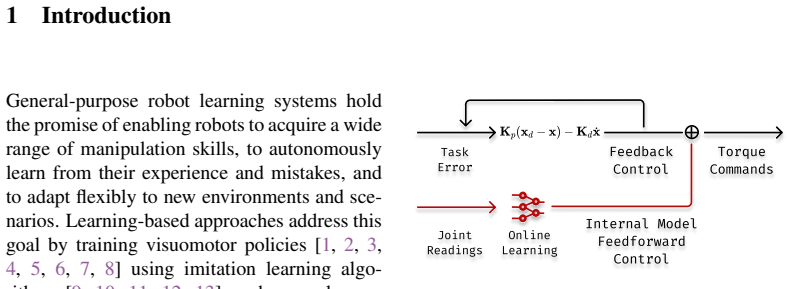
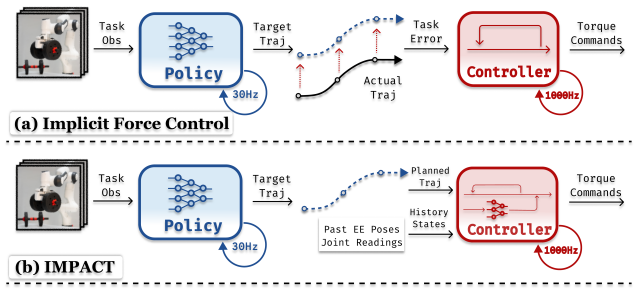
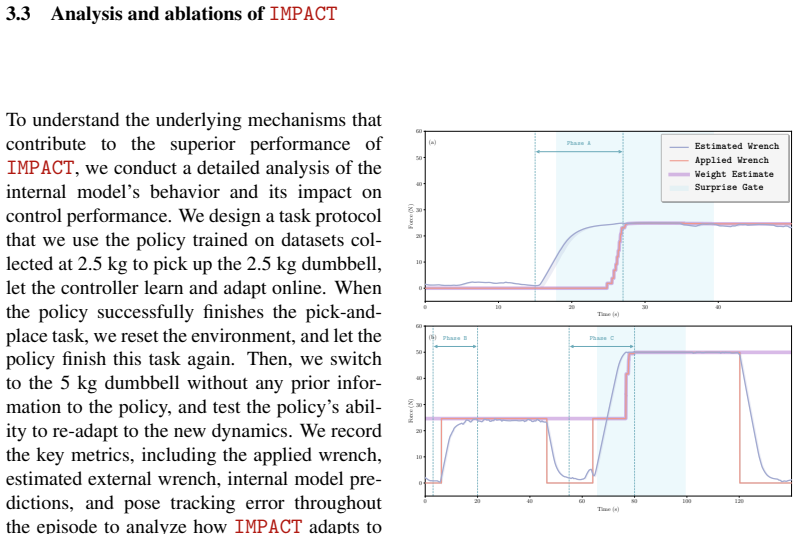
The IMPACT framework decouples forceful robotic manipulation into task-planning and internal-model-based predictive control. An internal model learned from data captures interaction dynamics sufficiently to generate predictions that replace explicit force/torque sensing and post-hoc tuning for each new weight, producing higher success rates, improved generalization to unseen object weights, and gains in safety and energy efficiency.
What carries the argument
The decoupling of task planning from internal-model-based predictive control, where the learned internal model supplies the dynamics predictions needed for forceful contact.
If this is right
- Higher success rates on forceful tasks such as tool use and table wiping.
- Generalization to object weights absent from training data without retraining or manual tuning.
- Lower energy consumption and improved safety margins during contact-rich interactions.
- Elimination of wrist force/torque or tactile sensors from the control architecture.
Where Pith is reading between the lines
- The separation of planning from model-based prediction may reduce overall system complexity for deployment in factories or homes.
- The same internal-model approach could apply to other physical-interaction domains such as locomotion over uneven terrain.
- Performance gains might persist under additional disturbances like friction changes or external pushes not tested in the original experiments.
Load-bearing premise
A data-learned internal model can capture the relevant dynamics of forceful interactions well enough to support reliable predictive control.
What would settle it
An experiment that applies the same tasks with varying unseen weights to both the internal-model controller and a standard impedance baseline and finds no difference in success rate or generalization.
Figures







read the original abstract
Real-world robotic manipulation tasks often involve forceful interactions with the environment, such as using tools of varying weights, transporting objects with different masses, and performing contact-rich tasks like table wiping. Previous learning-based approaches typically employ imitation learning policies that output target end-effector poses tracked by low-level impedance controllers. In these systems, forceful interactions are either implicitly realized through steady-state tracking errors or explicitly commanded using wrist force/torque or tactile sensors. However, implicit approaches generalize poorly across object weights, while explicit approaches require specialized hardware and increase system complexity. In this work, we propose IMPACT, a framework that decouples these forceful tasks into task-planning and internal-model-based predictive control. Extensive simulation and real-world experiments demonstrate that the proposed framework achieves higher success rates and improved generalization to unseen object weights, as well as better safety and energy efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IMPACT, a framework for forceful robotic manipulation that learns an internal model to enable predictive control, decoupling it from task planning. This avoids reliance on force/torque sensors or per-object tuning. Through simulation and real-world experiments, it demonstrates higher success rates, better generalization to unseen object weights, improved safety, and energy efficiency compared to prior imitation learning approaches with impedance controllers.
Significance. If the claims hold, this work is significant for advancing learning-based methods in contact-rich robotic tasks. It provides a way to handle varying dynamics without additional hardware. The combination of simulation and real experiments, along with the decoupling approach, offers a practical contribution. Strengths include the experimental validation supporting the generalization claims.
minor comments (3)
- [Abstract] The abstract claims higher success rates and improved generalization but does not provide any quantitative results or specific comparisons. Including key metrics would make the summary more informative.
- [Experiments] Ensure that all experimental setups, including the range of unseen weights tested and the exact baselines used, are described with sufficient detail for replication.
- Check for consistency in notation between the method description and the results tables.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our IMPACT framework and the recommendation for minor revision. The summary accurately reflects the paper's contributions regarding decoupling task planning from internal-model predictive control, along with the reported gains in success rate, generalization, safety, and efficiency.
Circularity Check
No significant circularity
full rationale
The provided abstract and context describe a learning-based framework for robotic control without any equations, fitted parameters presented as predictions, or self-citation chains. No derivation steps are visible that reduce by construction to inputs. The central claim rests on empirical simulation and real-world results for success rates and generalization, which are externally falsifiable and not internally forced by definition or renaming. This is the expected self-contained case for a methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 44(10-11):1684–1704, 2025
2025
-
[2]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.arXiv preprint arXiv:2403.03954, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Goal-conditioned imi- tation learning using score-based diffusion policies,
M. Reuss, M. Li, X. Jia, and R. Lioutikov. Goal-conditioned imitation learning using score- based diffusion policies.arXiv preprint arXiv:2304.02532, 2023
-
[4]
R. Wolf, Y . Shi, S. Liu, and R. Rayyes. Diffusion models for robotic manipulation: A survey. Frontiers in Robotics and AI, 12:1606247, 2025
2025
-
[5]
H. Chen, J. Xu, H. Chen, K. Hong, B. Huang, C. Liu, J. Mao, Y . Li, Y . Du, and K. Driggs- Campbell. Multi-modal manipulation via multi-modal policy consensus.arXiv preprint arXiv:2509.23468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[7]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
S. H. Høeg, A. Vaaler, C. Liu, O. Egeland, and Y . Du. Hybrid diffusion for simultaneous symbolic and continuous planning, 2025. URLhttps://arxiv.org/abs/2509.21983
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Hussein, M
A. Hussein, M. M. Gaber, E. Elyan, and C. Jayne. Imitation learning: A survey of learning methods.ACM Computing Surveys (CSUR), 50(2):1–35, 2017
2017
-
[10]
H. Chen, C. Zhu, S. Liu, Y . Li, and K. R. Driggs-Campbell. Tool-as-interface: Learning robot policies from observing human tool use. In3rd RSS Workshop on Dexterous Manipulation: Learning and Control with Diverse Data, 2025
2025
-
[11]
M. Zare, P. M. Kebria, A. Khosravi, and S. Nahavandi. A survey of imitation learning: Algo- rithms, recent developments, and challenges.IEEE Transactions on Cybernetics, 2024
2024
- [12]
-
[13]
C. Liu, H. Chen, S. H. Høeg, S. Yao, Y . Li, K. Hauser, and Y . Du. Flexible multitask learning with factorized diffusion policy.arXiv preprint arXiv:2512.21898, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
O’Neill, A
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, et al. Open x-embodiment: Robotic learning datasets and rt-x models: Open x-embodiment collaboration 0. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6892–6903. IEEE, 2024. 9
2024
-
[17]
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song. Universal manipulation interface: In-the-wild robot teaching without in-the-wild robots.arXiv preprint arXiv:2402.10329, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [18]
- [19]
- [20]
-
[21]
Y . Hou, Z. Liu, C. Chi, E. Cousineau, N. Kuppuswamy, S. Feng, B. Burchfiel, and S. Song. Adaptive compliance policy: Learning approximate compliance for diffusion guided control. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4829–
-
[22]
Zhang, L
X. Zhang, L. Sun, Z. Kuang, and M. Tomizuka. Learning variable impedance control via inverse reinforcement learning for force-related tasks.IEEE Robotics and Automation Letters, 6(2):2225–2232, 2021
2021
-
[23]
Portela, G
T. Portela, G. B. Margolis, Y . Ji, and P. Agrawal. Learning force control for legged manip- ulation. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 15366–15372. IEEE, 2024
2024
- [24]
-
[25]
E. Todorov. Optimality principles in sensorimotor control.Nature neuroscience, 7(9):907–915, 2004
2004
-
[26]
D. Marr. A theory of cerebellar cortex.The Journal of physiology, 202(2):437–470, 1969
1969
-
[27]
D. M. Wolpert, R. C. Miall, and M. Kawato. Internal models in the cerebellum.Trends in cognitive sciences, 2(9):338–347, 1998
1998
-
[28]
Imamizu and M
H. Imamizu and M. Kawato. Cerebellar internal models: implications for the dexterous use of tools.The Cerebellum, 11(2):325–335, 2012
2012
-
[29]
D. W. Franklin, E. Burdet, K. P. Tee, R. Osu, C.-M. Chew, T. E. Milner, and M. Kawato. Cns learns stable, accurate, and efficient movements using a simple algorithm.Journal of neuroscience, 28(44):11165–11173, 2008
2008
-
[30]
D. W. Franklin, G. Liaw, T. E. Milner, R. Osu, E. Burdet, and M. Kawato. Endpoint stiffness of the arm is directionally tuned to instability in the environment.Journal of Neuroscience, 27 (29):7705–7716, 2007
2007
-
[31]
A. J. Bastian. Learning to predict the future: the cerebellum adapts feedforward movement control.Current opinion in neurobiology, 16(6):645–649, 2006
2006
-
[32]
Pisotta and M
I. Pisotta and M. Molinari. Cerebellar contribution to feedforward control of locomotion. Frontiers in human neuroscience, 8:475, 2014
2014
-
[33]
Burdet, R
E. Burdet, R. Osu, D. W. Franklin, T. E. Milner, and M. Kawato. The central nervous system stabilizes unstable dynamics by learning optimal impedance.Nature, 414(6862):446–449, 2001. 10
2001
-
[34]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. InIROS, pages 5026–5033. IEEE, 2012. ISBN 978-1-4673-1737-5. URLhttp://dblp.uni-trier. de/db/conf/iros/iros2012.html#TodorovET12
2012
-
[35]
M. H. Raibert and J. J. Craig. Hybrid position/force control of manipulators.Journal of dynamic systems, measurement, and control, 103(2):126–133, 1981
1981
-
[36]
N. Hogan. Impedance control: An approach to manipulation. In1984 American control conference, pages 304–313. IEEE, 1984
1984
-
[37]
M. T. Mason. Compliance and force control for computer controlled manipulators.IEEE Transactions on Systems, Man, and Cybernetics, 11(6):418–432, 2007
2007
-
[38]
Yoshikawa
T. Yoshikawa. Dynamic hybrid position/force control of robot manipulators–description of hand constraints and calculation of joint driving force.IEEE Journal on Robotics and Automa- tion, 3(5):386–392, 2003
2003
-
[39]
Siciliano and L
B. Siciliano and L. Villani.Robot force control. Springer Science & Business Media, 1999
1999
-
[40]
Yashinski
M. Yashinski. Performing forceful robot manipulation tasks.Science Robotics, 9(87): eado8051, 2024
2024
-
[41]
Holladay, T
R. Holladay, T. Lozano-P ´erez, and A. Rodriguez. Robust planning for multi-stage forceful manipulation.The International Journal of Robotics Research, 43(3):330–353, 2024
2024
-
[42]
Holladay, T
R. Holladay, T. Lozano-P ´erez, and A. Rodriguez. Planning for multi-stage forceful manip- ulation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 6556–6562. IEEE, 2021
2021
-
[43]
Holladay, T
R. Holladay, T. Lozano-P ´erez, and A. Rodriguez. Force-and-motion constrained planning for tool use. In2019 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 7409–7416. IEEE, 2019
2019
-
[44]
A. Pasricha, J. Koh, J. Vakil, and A. Roncone. Dynamics-compliant trajectory diffusion for super-nominal payload manipulation.arXiv preprint arXiv:2508.21375, 2025
-
[45]
X. Guo, G. He, J. Xu, M. Mousaei, J. Geng, S. Scherer, and G. Shi. Flying calligrapher: Contact-aware motion and force planning and control for aerial manipulation.IEEE Robotics and Automation Letters, 2024
2024
- [46]
- [47]
- [48]
- [49]
- [50]
-
[51]
Mart ´ın-Mart´ın, M
R. Mart ´ın-Mart´ın, M. A. Lee, R. Gardner, S. Savarese, J. Bohg, and A. Garg. Variable impedance control in end-effector space: An action space for reinforcement learning in contact-rich tasks. In2019 IEEE/RSJ international conference on intelligent robots and sys- tems (IROS), pages 1010–1017. IEEE, 2019. 11
2019
-
[52]
F. J. Abu-Dakka, L. Rozo, and D. G. Caldwell. Force-based learning of variable impedance skills for robotic manipulation. In2018 IEEE-RAS 18th International Conference on Hu- manoid Robots (Humanoids), pages 1–9. IEEE, 2018
2018
-
[53]
E. Aljalbout, F. Frank, P. van der Smagt, and A. Paraschos. The shortcomings of force-from- motion in robot learning.arXiv preprint arXiv:2407.02904, 2024
-
[54]
E. R. Kandel. Principles of neural science, 2000
2000
-
[55]
J. S. Albus. A theory of cerebellar function.Mathematical biosciences, 10(1-2):25–61, 1971
1971
-
[56]
J. C. Eccles.The cerebellum as a neuronal machine. Springer Science & Business Media, 2013
2013
-
[57]
S. Tolu, M. C. Capolei, L. Vannucci, C. Laschi, E. Falotico, and M. V . Hernandez. A cerebellum-inspired learning approach for adaptive and anticipatory control.International journal of neural systems, 30(01):1950028, 2020
2020
- [58]
- [59]
-
[60]
J. Long, J. Ren, M. Shi, Z. Wang, T. Huang, P. Luo, and J. Pang. Learning humanoid locomo- tion with perceptive internal model. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 9997–10003. IEEE, 2025
2025
-
[61]
J. Gao, Z. Wang, Z. Xiao, J. Wang, T. Wang, J. Cao, X. Hu, S. Liu, J. Dai, and J. Pang. Coohoi: Learning cooperative human-object interaction with manipulated object dynamics.Advances in Neural Information Processing Systems, 37:79741–79763, 2024
2024
- [62]
-
[63]
C. E. Garcia and M. Morari. Internal model control. a unifying review and some new results. Industrial & Engineering Chemistry Process Design and Development, 21(2):308–323, 1982
1982
-
[64]
M. Kawato. Internal models for motor control and trajectory planning.Current opinion in neurobiology, 9(6):718–727, 1999
1999
-
[65]
Ganesh, A
G. Ganesh, A. Albu-Sch ¨affer, M. Haruno, M. Kawato, and E. Burdet. Biomimetic motor behavior for simultaneous adaptation of force, impedance and trajectory in interaction tasks. In2010 IEEE International Conference on Robotics and Automation, pages 2705–2711. IEEE, 2010
2010
-
[66]
C. Yang, G. Ganesh, S. Haddadin, S. Parusel, A. Albu-Schaeffer, and E. Burdet. Human-like adaptation of force and impedance in stable and unstable interactions.IEEE transactions on robotics, 27(5):918–930, 2011. 12 A Appendix We provide a detailed description of theIMPACTframework, including the algorithmic implemen- tation, hyper-parameters, and visualiz...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.