PhantomBench: Benchmarking the Non-existential Threat of Language Models
Pith reviewed 2026-06-27 12:55 UTC · model grok-4.3
The pith
Language models hallucinate on non-existent concepts at rates as high as 86.7 percent instead of abstaining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
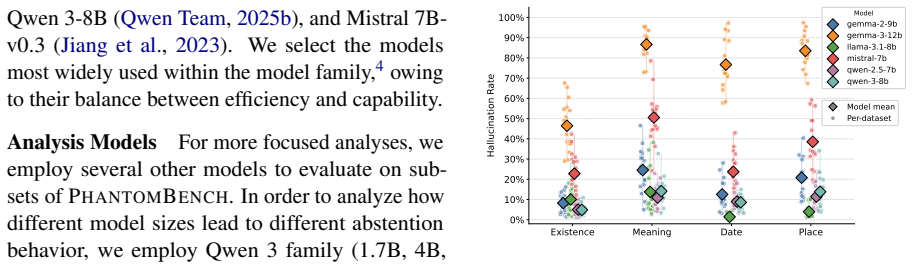
PhantomBench shows that language models of various types and sizes produce factually ungrounded responses about non-existent terms and entities at high rates, averaging as high as 86.7 percent, and that even frontier models fail to abstain reliably when the input presumes the concept is real.
What carries the argument
PhantomBench, a benchmark of over 60K non-existent terms and entities derived from real concepts to test hallucination versus abstention.
Load-bearing premise
The constructed non-existent terms are verifiably non-existent and the evaluation protocol correctly distinguishes hallucination from legitimate responses without systematic bias.
What would settle it
A model that abstains correctly on the majority of PhantomBench queries while still answering accurately on comparable real concepts would challenge the reported hallucination rates.
Figures






read the original abstract
Hallucinations, where language models (LMs) generate factually ungrounded responses, pose serious risks, as users tend to blindly rely on them. This is particularly concerning in high-stakes domains, where consequences of such model behavior can lead to significant harms. Despite notable progress in understanding hallucinations, it remains unclear how reliably these models can recognize the limits of their knowledge. We introduce PhantomBench, the first large-scale benchmark of its kind, comprising more than 60K non-existent terms and entities derived from real concepts across diverse domains. Using our benchmark, we evaluate a total of 21 models of various types and sizes. We show staggering hallucination rates across the board (with average rates as high as 86.7% in some cases), and note that even frontier models surprisingly fail to abstain on non-existent concepts, especially when the input presumes their existence. We then show that PhantomBench can serve as a proxy for studying model behavior on rare concepts for which models are more prone to hallucinate. We also provide a pipeline to construct PhantomBench, enabling scalable generation of non-existent concepts tailored to the specific needs of researchers and practitioners.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PhantomBench, a benchmark of more than 60K non-existent terms and entities derived from real concepts across domains. It evaluates 21 models of varying types and sizes, reporting average hallucination rates as high as 86.7%, with frontier models failing to abstain especially when inputs presume existence. PhantomBench is also positioned as a proxy for rare-concept behavior, and a construction pipeline is supplied to enable scalable generation of such terms.
Significance. If the non-existence of all terms is rigorously verified and the evaluation protocol is free of systematic bias in phrasing or scoring, the benchmark would provide a useful large-scale resource for quantifying and mitigating models' inability to recognize knowledge boundaries, with direct relevance to hallucination risks in high-stakes settings.
major comments (2)
- [Benchmark construction] Benchmark construction section: the pipeline derives terms from real concepts but supplies no description of an exhaustive, automated existence-verification procedure (e.g., multi-source KB lookup, web search, or human audit) that would confirm none of the 60K+ items have obscure real-world referents. This verification is load-bearing for the headline 86.7% hallucination rates; any non-negligible fraction of real entities would cause legitimate model responses to be scored as hallucinations, inflating the reported figures.
- [Evaluation and results] Evaluation and results sections: quantitative claims on 21 models are presented without accompanying details on prompting templates, exact criteria distinguishing hallucination from abstention or partial knowledge, inter-annotator agreement (if human scoring is used), or controls for phrasing bias that presumes existence. These omissions prevent assessment of whether the protocol systematically overestimates non-abstention.
minor comments (2)
- [Abstract] Abstract states results on 21 models but omits any methods summary, error bars, or validation statistics; the full paper should include a concise methods paragraph in the abstract for readability.
- [Proxy analysis] The claim that PhantomBench serves as a 'proxy for studying model behavior on rare concepts' requires explicit correlation analysis or ablation showing that performance on phantom items predicts performance on verified rare real items; this link is asserted but not demonstrated in the provided summary.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major comment below and will revise the manuscript to address the identified gaps in documentation.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the pipeline derives terms from real concepts but supplies no description of an exhaustive, automated existence-verification procedure (e.g., multi-source KB lookup, web search, or human audit) that would confirm none of the 60K+ items have obscure real-world referents. This verification is load-bearing for the headline 86.7% hallucination rates; any non-negligible fraction of real entities would cause legitimate model responses to be scored as hallucinations, inflating the reported figures.
Authors: We agree that the manuscript does not currently describe the existence-verification procedure in sufficient detail. We will expand the Benchmark construction section to document the full verification pipeline, including the specific multi-source KB lookups, web searches, and any human audit steps used to confirm non-existence of all terms. revision: yes
-
Referee: [Evaluation and results] Evaluation and results sections: quantitative claims on 21 models are presented without accompanying details on prompting templates, exact criteria distinguishing hallucination from abstention or partial knowledge, inter-annotator agreement (if human scoring is used), or controls for phrasing bias that presumes existence. These omissions prevent assessment of whether the protocol systematically overestimates non-abstention.
Authors: We concur that the evaluation protocol requires additional documentation for reproducibility and bias assessment. In the revision we will include the complete prompting templates, precise classification criteria for hallucination versus abstention or partial knowledge, inter-annotator agreement statistics where human scoring was involved, and any controls applied for phrasing bias. revision: yes
Circularity Check
No circularity: empirical benchmark construction and direct model evaluation
full rationale
The paper introduces a benchmark of >60K non-existent terms and reports hallucination rates from evaluating 21 models. No equations, fitted parameters, or derivations are present. The headline rates are direct empirical measurements on the constructed dataset rather than quantities that reduce to prior fits or self-citations by construction. The pipeline for term generation is described as a construction method, not a self-referential prediction. This is a standard empirical benchmark paper with no load-bearing self-citation chains or definitional loops.
Axiom & Free-Parameter Ledger
invented entities (1)
-
non-existent terms and entities
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2605.01428 , year=
Hallucinations undermine trust; metacognition is a way forward , author=. arXiv preprint arXiv:2605.01428 , year=
-
[2]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[3]
Soldaini, Luca and Kinney, Rodney and Bhagia, Akshita and Schwenk, Dustin and Atkinson, David and Authur, Russell and Bogin, Ben and Chandu, Khyathi and Dumas, Jennifer and Elazar, Yanai and Hofmann, Valentin and Jha, Ananya and Kumar, Sachin and Lucy, Li and Lyu, Xinxi and Lambert, Nathan and Magnusson, Ian and Morrison, Jacob and Muennighoff, Niklas and...
-
[4]
First Conference on Language Modeling , year=
Infini-gram: Scaling Unbounded n-gram Language Models to a Trillion Tokens , author=. First Conference on Language Modeling , year=
-
[5]
Mallen, Alex and Asai, Akari and Zhong, Victor and Das, Rajarshi and Khashabi, Daniel and Hajishirzi, Hannaneh. When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi:10.18653/v1/2023...
-
[6]
Calderon, Nitay and Reichart, Roi and Dror, Rotem. The Alternative Annotator Test for LLM -as-a-Judge: How to Statistically Justify Replacing Human Annotators with LLM s. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.782
-
[7]
M ed INST : Meta Dataset of Biomedical Instructions
Han, Wenhan and Fang, Meng and Zhang, Zihan and Yin, Yu and Song, Zirui and Chen, Ling and Pechenizkiy, Mykola and Chen, Qingyu. M ed INST : Meta Dataset of Biomedical Instructions. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.482
-
[8]
Miao Xiong and Zhiyuan Hu and Xinyang Lu and YIFEI LI and Jie Fu and Junxian He and Bryan Hooi , booktitle=. Can. 2024 , url=
2024
-
[9]
2025 , eprint=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. 2025 , eprint=
2025
-
[10]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[11]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[12]
2024 , eprint=
Gemma 2: Improving Open Language Models at a Practical Size , author=. 2024 , eprint=
2024
-
[13]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[14]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[15]
B io M istral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains
Labrak, Yanis and Bazoge, Adrien and Morin, Emmanuel and Gourraud, Pierre-Antoine and Rouvier, Mickael and Dufour, Richard. B io M istral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.348
-
[16]
2025 , eprint=
MedGemma Technical Report , author=. 2025 , eprint=
2025
-
[17]
2023 , eprint=
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models , author=. 2023 , eprint=
2023
-
[18]
2024 , eprint=
SaulLM-7B: A pioneering Large Language Model for Law , author=. 2024 , eprint=
2024
-
[19]
2024 , eprint=
SaulLM-54B & SaulLM-141B: Scaling Up Domain Adaptation for the Legal Domain , author=. 2024 , eprint=
2024
-
[20]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[21]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[22]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[23]
R. XST est: A Test Suite for Identifying Exaggerated Safety Behaviours in Large Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 2024. doi:10.18653/v1/2024.naacl-long.301
-
[24]
Wen, Bingbing and Yao, Jihan and Feng, Shangbin and Xu, Chenjun and Tsvetkov, Yulia and Howe, Bill and Wang, Lucy Lu. Know Your Limits: A Survey of Abstention in Large Language Models. Transactions of the Association for Computational Linguistics. 2025. doi:10.1162/tacl_a_00754
-
[25]
2026 , eprint=
Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs , author=. 2026 , eprint=
2026
-
[26]
Groeneveld, Dirk and Beltagy, Iz and Walsh, Evan and Bhagia, Akshita and Kinney, Rodney and Tafjord, Oyvind and Jha, Ananya and Ivison, Hamish and Magnusson, Ian and Wang, Yizhong and Arora, Shane and Atkinson, David and Authur, Russell and Chandu, Khyathi and Cohan, Arman and Dumas, Jennifer and Elazar, Yanai and Gu, Yuling and Hessel, Jack and Khot, Tus...
-
[27]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Reasoning Models Hallucinate More: Factuality-Aware Reinforcement Learning for Large Reasoning Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[28]
2025 , eprint=
Are Reasoning Models More Prone to Hallucination? , author=. 2025 , eprint=
2025
-
[29]
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , title =. ACM Trans. Inf. Syst. , month = jan, articleno =. 2025 , issue_date =. doi:10.1145/3703155 , abstract =
-
[30]
2026 , eprint=
A Unified Definition of Hallucination: It's The World Model, Stupid! , author=. 2026 , eprint=
2026
-
[31]
2025 , eprint=
Why Language Models Hallucinate , author=. 2025 , eprint=
2025
-
[32]
Why and How
Yiyou Sun and Yu Gai and Lijie Chen and Abhilasha Ravichander and Yejin Choi and Nouha Dziri and Dawn Song , booktitle=. Why and How. 2026 , url=
2026
-
[33]
Proceedings of the 40th International Conference on Machine Learning , pages =
Large Language Models Struggle to Learn Long-Tail Knowledge , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[34]
TruthfulQA: Measuring how models mimic human false- hoods
Lin, Stephanie and Hilton, Jacob and Evans, Owain. T ruthful QA : Measuring How Models Mimic Human Falsehoods. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.229
-
[35]
Halueval: A large-scale hallucination evaluation benchmark for large language models
Li, Junyi and Cheng, Xiaoxue and Zhao, Xin and Nie, Jian-Yun and Wen, Ji-Rong. H alu E val: A Large-Scale Hallucination Evaluation Benchmark for Large Language Models. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.397
-
[36]
doi: 10.18653/v1/2023.emnlp-main.741
Min, Sewon and Krishna, Kalpesh and Lyu, Xinxi and Lewis, Mike and Yih, Wen-tau and Koh, Pang and Iyyer, Mohit and Zettlemoyer, Luke and Hajishirzi, Hannaneh. FA ct S core: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.1...
-
[37]
Bang, Yejin and Ji, Ziwei and Schelten, Alan and Hartshorn, Anthony and Fowler, Tara and Zhang, Cheng and Cancedda, Nicola and Fung, Pascale. H allu L ens: LLM Hallucination Benchmark. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1176
-
[38]
Smith, Yejin Choi, and Hannaneh Hajishirzi
Brahman, Faeze and Kumar, Sachin and Balachandran, Vidhisha and Dasigi, Pradeep and Pyatkin, Valentina and Ravichander, Abhilasha and Wiegreffe, Sarah and Dziri, Nouha and Chandu, Khyathi and Hessel, Jack and Tsvetkov, Yulia and Smith, Noah A. and Choi, Yejin and Hajishirzi, Hannaneh , editor=. The Art of Saying No: Contextual Noncompliance in Language Mo...
-
[39]
2024 , eprint=
Rejection Improves Reliability: Training LLMs to Refuse Unknown Questions Using RL from Knowledge Feedback , author=. 2024 , eprint=
2024
-
[40]
AbstentionBench: Reasoning
Polina Kirichenko and Mark Ibrahim and Kamalika Chaudhuri and Samuel Bell , booktitle=. AbstentionBench: Reasoning. 2026 , url=
2026
-
[41]
Findings of the Association for Computational Linguistics: ACL 2023 , pages =
Yin, Zhangyue and Sun, Qiushi and Guo, Qipeng and Wu, Jiawen and Qiu, Xipeng and Huang, Xuanjing. Do Large Language Models Know What They Don ' t Know?. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.551
-
[42]
Knowledge of knowledge: Exploring known-unknowns uncertainty with large language models
Amayuelas, Alfonso and Wong, Kyle and Pan, Liangming and Chen, Wenhu and Wang, William Yang. Knowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.383
-
[43]
Knowledge Boundary of Large Language Models: A Survey
Li, Moxin and Zhao, Yong and Zhang, Wenxuan and Li, Shuaiyi and Xie, Wenya and Ng, See-Kiong and Chua, Tat-Seng and Deng, Yang. Knowledge Boundary of Large Language Models: A Survey. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.256
-
[44]
2024 , eprint=
Examining LLMs' Uncertainty Expression Towards Questions Outside Parametric Knowledge , author=. 2024 , eprint=
2024
-
[45]
ALCUNA : Large Language Models Meet New Knowledge
Yin, Xunjian and Huang, Baizhou and Wan, Xiaojun. ALCUNA : Large Language Models Meet New Knowledge. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.87
-
[46]
H ypo T erm QA : Hypothetical Terms Dataset for Benchmarking Hallucination Tendency of LLM s
Uluoglakci, Cem and Temizel, Tugba. H ypo T erm QA : Hypothetical Terms Dataset for Benchmarking Hallucination Tendency of LLM s. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics: Student Research Workshop. 2024. doi:10.18653/v1/2024.eacl-srw.9
-
[47]
, biburl =
Zipf, George K. , biburl =
-
[48]
Piantadosi , doi=
Steven T. Piantadosi , doi=. Zipf’s word frequency law in natural language: A critical review and future directions , publisher=. 2014 , issn=
2014
-
[49]
Language, Usage and Cognition , publisher=
Bybee, Joan , year=. Language, Usage and Cognition , publisher=
-
[50]
Retrieval-augmented generation for knowledge-intensive NLP tasks , year =
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K\". Retrieval-augmented generation for knowledge-intensive NLP tasks , year =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
-
[51]
Advances in Neural Information Processing Systems , editor=
Chain of Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , editor=. 2022 , url=
2022
-
[52]
R -Tuning: Instructing Large Language Models to Say ` I Don ' t Know'
Zhang, Hanning and Diao, Shizhe and Lin, Yong and Fung, Yi and Lian, Qing and Wang, Xingyao and Chen, Yangyi and Ji, Heng and Zhang, Tong. R -Tuning: Instructing Large Language Models to Say ` I Don ' t Know'. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Vol...
-
[53]
The Thirteenth International Conference on Learning Representations , year=
Do I Know This Entity? Knowledge Awareness and Hallucinations in Language Models , author=. The Thirteenth International Conference on Learning Representations , year=
-
[54]
2024 , eprint=
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries , author=. 2024 , eprint=
2024
-
[55]
Journal of Legal Analysis , volume =
Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models , volume=. Journal of Legal Analysis , author=. 2024 , month=jan, pages=. doi:10.1093/jla/laae003 , abstractNote=
-
[56]
Weidinger, Laura and Uesato, Jonathan and Rauh, Maribeth and Griffin, Conor and Huang, Po-Sen and Mellor, John and Glaese, Amelia and Cheng, Myra and Balle, Borja and Kasirzadeh, Atoosa and Biles, Courtney and Brown, Sasha and Kenton, Zac and Hawkins, Will and Stepleton, Tom and Birhane, Abeba and Hendricks, Lisa Anne and Rimell, Laura and Isaac, William ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.