Phi-Actor-Critic: Steering General-Sum Games to Pareto-Efficient Correlated Equilibria
Pith reviewed 2026-06-27 10:40 UTC · model grok-4.3
The pith
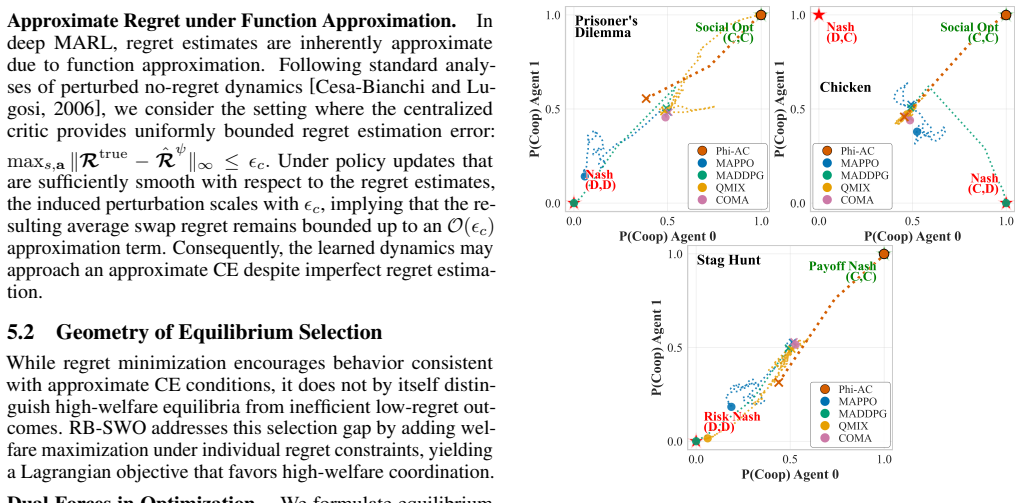
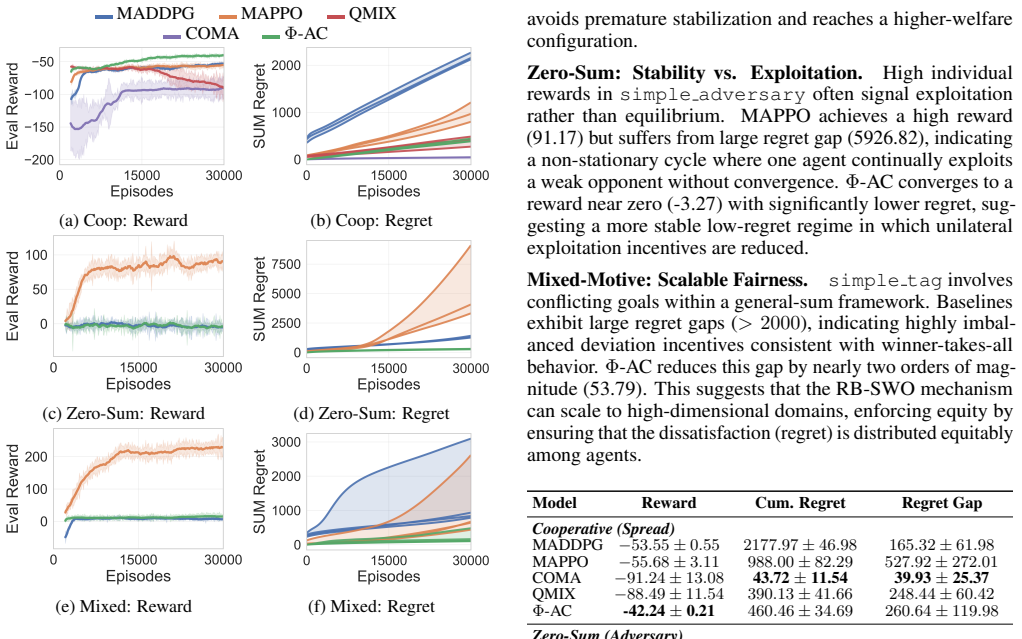
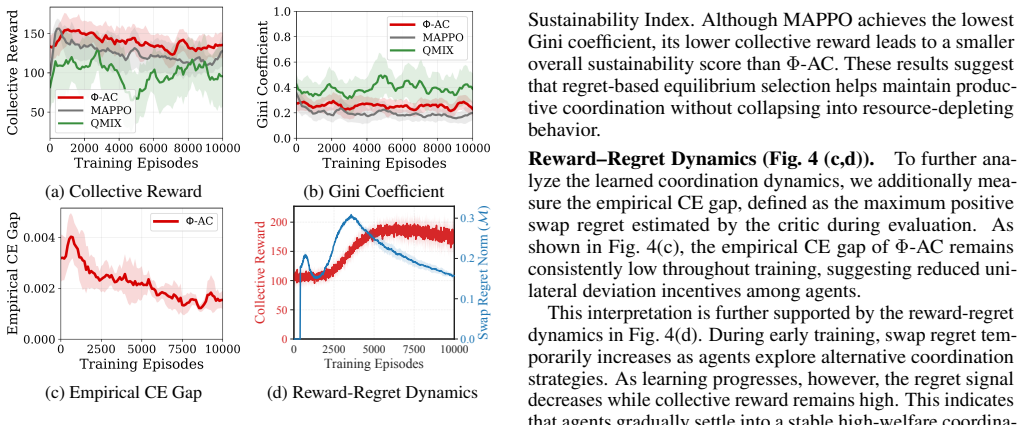
Φ-Actor-Critic uses swap regret minimization and a centralized critic to guide agents toward high-welfare correlated equilibria in general-sum games.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By minimizing swap regret through a centralized attention critic that outputs vector regrets directly and applying Lagrangian equilibrium selection, Φ-Actor-Critic enables deep MARL agents to reach Pareto-efficient correlated equilibria that balance individual incentives with collective welfare in mixed-motive settings.
What carries the argument
The centralized attention critic that predicts vector-valued regrets in a single forward pass, which enables tractable swap regret minimization for equilibrium selection.
If this is right
- Agents reach correlated equilibria that improve collective return without sacrificing stability.
- The method works across matrix games, continuous control environments, and resource-harvest scenarios.
- It avoids the monotonicity restrictions that limit value-decomposition approaches.
- Equilibrium selection can be tuned via the Lagrangian to trade off welfare against individual rationality.
Where Pith is reading between the lines
- The single-pass regret critic could reduce training cost enough to allow deployment in larger populations where repeated counterfactual rollouts become prohibitive.
- If the attention mechanism generalizes across environment sizes, the same trained critic might support transfer to new but structurally similar games.
- Real-world systems such as traffic signal control or shared-resource allocation could adopt the regret constraint as an online safety layer.
Load-bearing premise
The centralized attention critic can accurately estimate the vector of counterfactual regrets for every agent without running separate simulations for each possible action.
What would settle it
A controlled experiment on a new general-sum game in which Φ-Actor-Critic policies produce lower total welfare than standard policy-gradient baselines while satisfying the same regret bounds would falsify the central claim.
Figures

read the original abstract
Real-world multi-agent systems, from traffic coordination to resource allocation, are often modeled as general-sum games where individual incentives conflict with collective welfare. In these settings, the central challenge is not merely finding an equilibrium, but selecting socially desirable outcomes among many suboptimal Nash equilibria. Standard deep multi-agent reinforcement learning (MARL) methods struggle with this problem, as value-decomposition approaches are constrained by monotonicity assumptions and policy-gradient methods often converge to stable but socially inefficient equilibria. To address this limitation, we propose $\Phi$-Actor-Critic ($\Phi$-AC), a framework that leverages swap regret minimization to steer learning toward high-welfare correlated equilibria (CE). To make counterfactual regret estimation tractable in deep MARL, $\Phi$-AC employs a centralized attention critic that predicts vector-valued regrets in a single forward pass, avoiding computationally expensive counterfactual simulations. We further introduce a Lagrangian-based equilibrium selection mechanism that optimizes social welfare while enforcing stability through regret constraints. Experiments on matrix games, Multi-Agent Particle Environments (MPE), and the Melting Pot Harvest scenario demonstrate that $\Phi$-AC learns efficient and stable coordination strategies across diverse mixed-motive settings while maintaining high collective return and competitive fairness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Φ-Actor-Critic (Φ-AC), a deep MARL method for general-sum games that uses swap regret minimization to steer agents toward Pareto-efficient correlated equilibria rather than inefficient Nash equilibria. It introduces a centralized attention critic to predict vector-valued regrets in a single forward pass, avoiding expensive counterfactual simulations, and a Lagrangian-based mechanism to optimize social welfare subject to regret constraints for stability. Experiments are reported on matrix games, Multi-Agent Particle Environments (MPE), and the Melting Pot Harvest scenario, claiming improved collective return, coordination efficiency, and fairness.
Significance. If the technical claims hold, the work would address a central limitation of existing MARL methods in mixed-motive settings by providing a tractable route to high-welfare correlated equilibria without relying on value-decomposition monotonicity assumptions. The combination of regret minimization with attention-based critics and Lagrangian selection could be impactful for applications such as traffic coordination and resource allocation.
minor comments (2)
- The abstract refers to 'swap regret minimization' and 'vector-valued regrets' without defining the precise regret vector or the swap operator used; this notation should be clarified early in the manuscript.
- The claim that the attention critic 'avoids computationally expensive counterfactual simulations' would benefit from a brief complexity comparison (e.g., forward-pass cost versus explicit counterfactual rollouts) even in the introduction.
Simulated Author's Rebuttal
We thank the referee for their review and for acknowledging the potential significance of Φ-AC in addressing a central limitation of MARL in mixed-motive settings. The recommendation is listed as uncertain, yet the report contains no specific major comments or criticisms to address point by point. We remain available to provide further clarifications, additional experiments, or revisions should any concerns arise.
Circularity Check
No significant circularity
full rationale
The provided abstract contains no equations, derivations, or explicit self-citations that could form a load-bearing chain. Claims about swap regret minimization, the centralized attention critic, and Lagrangian equilibrium selection are described at a conceptual level without any reduction of a 'prediction' or result to fitted inputs or prior self-work by construction. This is the common case of a self-contained high-level proposal whose technical details (if present in the full manuscript) show no visible circularity from the given text.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2006 9th international conference on control, automation, robotics and vision , pages=
Multi-agent reinforcement learning: A survey , author=. 2006 9th international conference on control, automation, robotics and vision , pages=. 2006 , organization=
2006
-
[2]
Advances in neural information processing systems , volume=
The surprising effectiveness of ppo in cooperative multi-agent games , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Multi-agent actor-critic for mixed cooperative-competitive environments , author=. Advances in neural information processing systems , volume=
-
[4]
Journal of Machine Learning Research , volume=
Monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[5]
Advances in neural information processing systems , volume=
Regret minimization in games with incomplete information , author=. Advances in neural information processing systems , volume=
-
[6]
International conference on machine learning , pages=
Deep counterfactual regret minimization , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[7]
2008 , publisher=
Multiagent systems: Algorithmic, game-theoretic, and logical foundations , author=. 2008 , publisher=
2008
-
[8]
Journal of mathematical Economics , volume=
Subjectivity and correlation in randomized strategies , author=. Journal of mathematical Economics , volume=. 1974 , publisher=
1974
-
[9]
Econometrica: Journal of the Econometric Society , pages=
Correlated equilibrium as an expression of Bayesian rationality , author=. Econometrica: Journal of the Econometric Society , pages=. 1987 , publisher=
1987
-
[10]
Advances in Neural Information Processing Systems , volume=
On Tractable -Equilibria in Non-Concave Games , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003
A general class of no-regret learning algorithms and game-theoretic equilibria , author=. Learning Theory and Kernel Machines: 16th Annual Conference on Learning Theory and 7th Kernel Workshop, COLT/Kernel 2003, Washington, DC, USA, August 24-27, 2003. Proceedings , pages=. 2003 , organization=
2003
-
[12]
2007 , publisher=
Learning, regret minimization, and equilibria , author=. 2007 , publisher=
2007
-
[13]
Econometrica , volume=
A simple adaptive procedure leading to correlated equilibrium , author=. Econometrica , volume=. 2000 , publisher=
2000
-
[14]
Journal of Artificial Intelligence Research , volume=
Optimal and approximate Q-value functions for decentralized POMDPs , author=. Journal of Artificial Intelligence Research , volume=
-
[15]
International conference on machine learning , pages=
Actor-attention-critic for multi-agent reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Film: Visual reasoning with a general conditioning layer , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
The hadamard product , author=. Proc. symp. appl. math , volume=
-
[18]
International conference on machine learning , pages=
Deterministic policy gradient algorithms , author=. International conference on machine learning , pages=. 2014 , organization=
2014
-
[19]
Categorical Reparameterization with Gumbel-Softmax
Categorical reparameterization with gumbel-softmax , author=. arXiv preprint arXiv:1611.01144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Advances in Neural Information Processing Systems , volume=
Learning fairness in multi-agent systems , author=. Advances in Neural Information Processing Systems , volume=
-
[21]
Proceedings of the AAAI conference on artificial intelligence , volume=
Counterfactual multi-agent policy gradients , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[22]
The starcraft multi-agent challenge , author=. arXiv preprint arXiv:1902.04043 , year=
-
[23]
Proceedings of the AAAI conference on artificial intelligence , volume=
Google research football: A novel reinforcement learning environment , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[24]
arXiv preprint arXiv:2008.01062 , year=
Qplex: Duplex dueling multi-agent q-learning , author=. arXiv preprint arXiv:2008.01062 , year=
-
[25]
Advances in neural information processing systems , volume=
Weighted qmix: Expanding monotonic value function factorisation for deep multi-agent reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Shapley Q-value: A local reward approach to solve global reward games , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Advances in Neural Information Processing Systems , volume=
Shaq: Incorporating shapley value theory into multi-agent q-learning , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
R3DM: Enabling Role Discovery and Diversity Through Dynamics Models in Multi-agent Reinforcement Learning , author=
-
[29]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Bridging training and execution via dynamic directed graph-based communication in cooperative multi-agent systems , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[30]
Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages=
Leveraging Large Language Models for Effective and Explainable Multi-Agent Credit Assignment , author=. Proceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[31]
MACCA: Offline Multi-agent Reinforcement Learning with Causal Credit Assignment
Macca: Offline multi-agent reinforcement learning with causal credit assignment , author=. arXiv preprint arXiv:2312.03644 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
International Conference on Artificial Intelligence and Statistics , pages=
Multi-level Advantage Credit Assignment for Cooperative Multi-Agent Reinforcement Learning , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2025 , organization=
2025
-
[33]
IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , volume=
A comprehensive survey of multiagent reinforcement learning , author=. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews) , volume=. 2008 , publisher=
2008
-
[34]
Handbook of reinforcement learning and control , pages=
Multi-agent reinforcement learning: A selective overview of theories and algorithms , author=. Handbook of reinforcement learning and control , pages=. 2021 , publisher=
2021
-
[35]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Value-decomposition networks for cooperative multi-agent learning , author=. arXiv preprint arXiv:1706.05296 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
International conference on machine learning , pages=
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[37]
arXiv preprint arXiv:2002.03939 , year=
Qatten: A general framework for cooperative multiagent reinforcement learning , author=. arXiv preprint arXiv:2002.03939 , year=
-
[38]
Games and Economic Behavior , volume=
Calibrated learning and correlated equilibrium , author=. Games and Economic Behavior , volume=
-
[39]
International conference on machine learning , pages=
Social influence as intrinsic motivation for multi-agent deep reinforcement learning , author=. International conference on machine learning , pages=. 2019 , organization=
2019
-
[40]
arXiv preprint arXiv:2109.11251 , year=
Trust region policy optimisation in multi-agent reinforcement learning , author=. arXiv preprint arXiv:2109.11251 , year=
-
[41]
International conference on machine learning , pages=
Scalable evaluation of multi-agent reinforcement learning with melting pot , author=. International conference on machine learning , pages=. 2021 , organization=
2021
-
[42]
Proceedings of the 19th international conference on autonomous agents and multiagent systems , pages=
Neural replicator dynamics: Multiagent learning via hedging policy gradients , author=. Proceedings of the 19th international conference on autonomous agents and multiagent systems , pages=
-
[43]
International conference on machine learning , pages=
Regret minimization for partially observable deep reinforcement learning , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[44]
arXiv preprint arXiv:2006.10410 , year=
Dream: Deep regret minimization with advantage baselines and model-free learning , author=. arXiv preprint arXiv:2006.10410 , year=
-
[45]
, author=
An Analysis of Connections Between Regret Minimization and Actor Critic Methods in Cooperative Settings. , author=. AAMAS , pages=
-
[46]
Communications of the ACM , volume=
The complexity of computing a Nash equilibrium , author=. Communications of the ACM , volume=. 2009 , publisher=
2009
-
[47]
Proceedings of the AAAI conference on artificial intelligence , volume=
Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[48]
1991 , publisher=
Game theory , author=. 1991 , publisher=
1991
-
[49]
Games and Economic Behavior , volume=
The one-shot-deviation principle for sequential rationality , author=. Games and Economic Behavior , volume=. 1996 , publisher=
1996
-
[50]
Advances in Neural Information Processing Systems , volume=
Pettingzoo: Gym for multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[51]
arXiv preprint arXiv:2503.14576 , year=
SocialJax: An Evaluation Suite for Multi-agent Reinforcement Learning in Sequential Social Dilemmas , author=. arXiv preprint arXiv:2503.14576 , year=
-
[52]
Proceedings of the 24th Annual Conference on Learning Theory , pages=
Blackwell approachability and no-regret learning are equivalent , author=. Proceedings of the 24th Annual Conference on Learning Theory , pages=. 2011 , organization=
2011
-
[53]
CSC 665: Online convex optimization , author=
-
[54]
International Conference on Machine Learning , pages=
Constrained phi-equilibria , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[55]
, author=
From external to internal regret. , author=. Journal of Machine Learning Research , volume=
-
[56]
2006 , publisher=
Prediction, learning, and games , author=. 2006 , publisher=
2006
-
[57]
Journal of computer and system sciences , volume=
A decision-theoretic generalization of on-line learning and an application to boosting , author=. Journal of computer and system sciences , volume=. 1997 , publisher=
1997
-
[58]
Artificial Intelligence and Statistics , pages=
Maximum entropy correlated equilibria , author=. Artificial Intelligence and Statistics , pages=. 2007 , organization=
2007
-
[59]
International conference on machine learning , pages=
Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[60]
2021 , publisher=
Constrained Markov decision processes , author=. 2021 , publisher=
2021
- [61]
-
[62]
Machine learning proceedings 1994 , pages=
Markov games as a framework for multi-agent reinforcement learning , author=. Machine learning proceedings 1994 , pages=. 1994 , publisher=
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.