UniReason-Med: A Shared Grounded Reasoning Interface for 2D-to-3D Transfer in Medical VQA
Pith reviewed 2026-06-27 10:18 UTC · model grok-4.3
The pith
A shared grounded reasoning interface transfers reasoning structure from 2D medical images to 3D volumes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
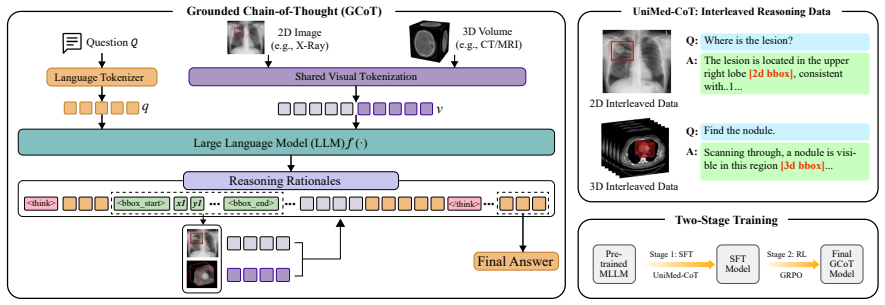
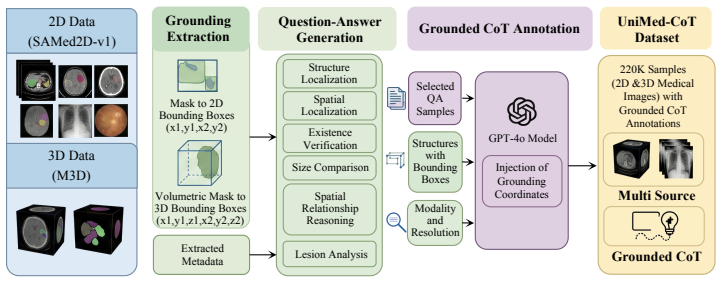
UniReason-Med processes either 2D images or slice-serialized 3D volumes at inference time through shared box syntax, region-token injection, and a common grounded reasoning policy, generating interleaved textual reasoning and localized visual evidence; it is trained on the 220K UniMed-CoT dataset via supervised fine-tuning and outcome-level reinforcement learning without IoU or Dice localization rewards, and joint 2D+3D supervision is shown to improve 3D reasoning relative to 3D-only training while grounding elements benefit both tasks.
What carries the argument
shared grounded reasoning interface that aligns 2D and 3D inputs via common box syntax for localization, region-token injection, and a single grounded reasoning policy
If this is right
- Joint 2D+3D grounded supervision substantially improves 3D reasoning over 3D-only training.
- Grounding and region-token injection consistently benefit performance on both 2D and 3D tasks.
- The model generates grounded reasoning traces using only outcome-level reinforcement learning without explicit localization rewards.
- A single checkpoint can process either 2D images or slice-serialized 3D volumes at inference time.
Where Pith is reading between the lines
- The approach may allow 3D medical reasoning systems to draw on larger existing 2D datasets rather than requiring equally large 3D annotations.
- Similar shared interfaces could be tested for transferring reasoning between other pairs of input dimensions or imaging modalities.
- The method raises the question of whether outcome-only reinforcement learning remains sufficient when the number of 3D samples grows much larger.
Load-bearing premise
Aligning 2D images and 3D volumes through a common box syntax, region-token injection, and grounded reasoning policy enables effective knowledge transfer without requiring dimension-specific adaptations or suffering from information loss in slice serialization.
What would settle it
A controlled experiment in which adding the 170K 2D grounded samples to the 50K 3D samples produces no gain in 3D VQA accuracy compared with 3D-only training, or in which the single shared model underperforms two separately trained dimension-specific models on their respective tasks.
Figures



read the original abstract
We study whether grounded reasoning supervision from abundant 2D medical images can improve 3D medical VQA when both input types are aligned through a common reasoning interface. We introduce UniReason-Med, a single-checkpoint framework that processes either a 2D image or a slice-serialized 3D volume at inference time, generating interleaved textual reasoning and localized visual evidence through shared box syntax, region-token injection, and a common grounded reasoning policy. To train this interface, we construct UniMed-CoT, a 220K instruction-tuning dataset with interleaved textual reasoning and grounded visual evidence, including 170K 2D and 50K 3D samples. Through supervised fine-tuning followed by outcome-level reinforcement learning, UniReason-Med learns to generate grounded reasoning traces without IoU/Dice-based localization rewards during RL. Data-mixture and component ablations show that joint 2D+3D grounded supervision substantially improves 3D reasoning over 3D-only training, while grounding and region-token injection consistently benefit both 2D and 3D tasks. These results suggest that a shared grounded reasoning interface can transfer reasoning structure from 2D images to slice-serialized volumetric medical understanding. The code and data are publicly available at https://github.com/IQuestLab/unireason-med.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniReason-Med, a single-checkpoint model for medical VQA that processes either 2D images or slice-serialized 3D volumes using a shared grounded reasoning interface (box syntax, region-token injection, and common policy). It constructs the UniMed-CoT dataset (220K samples) and trains via SFT followed by outcome-level RL without localization rewards. Data-mixture and component ablations indicate that joint 2D+3D grounded supervision improves 3D reasoning over 3D-only training, supporting the claim that the shared interface transfers reasoning structure from 2D to volumetric understanding. Code and data are released publicly.
Significance. If the transfer claim holds under rigorous 3D geometry tests, the work could meaningfully advance medical VQA by leveraging abundant 2D supervision for scarcer 3D tasks without dimension-specific models. The public release of code, data, and the explicit ablation design are strengths that support reproducibility and further investigation.
major comments (2)
- [Method (architecture and input processing)] The central transfer claim rests on the assumption that a shared box syntax and region-token injection recover volumetric structure from slice serialization. However, the architecture description does not specify any mechanism (e.g., 3D positional encodings or cross-slice attention) for modeling inter-slice spatial continuity; if boxes and tokens are applied independently per slice, the model reduces to per-slice 2D reasoning and the transfer benefit cannot be attributed to 3D structure recovery.
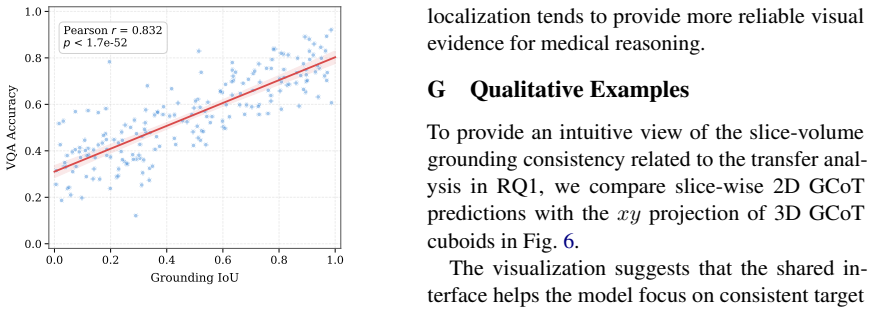
- [Experiments (ablations)] Data-mixture ablations show joint 2D+3D training improves 3D VQA metrics over 3D-only, but the reported experiments do not include a controlled test set of questions that require explicit cross-slice geometric reasoning (e.g., relative depth, 3D bounding-box consistency across slices). Without such a test, the ablation results are consistent with improved 2D reasoning per slice rather than genuine 3D transfer.
minor comments (2)
- [Training procedure] The abstract states that RL uses outcome-level rewards without IoU/Dice localization terms, but the exact reward formulation, value model, and KL regularization details are not provided in the main text; these should be expanded for reproducibility.
- [Dataset] Dataset construction details for the 50K 3D samples (source volumes, question generation, grounding annotation protocol) are referenced but lack sufficient statistics on slice count distribution and inter-slice overlap to assess potential information loss from serialization.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications on the architecture and experiments, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method (architecture and input processing)] The central transfer claim rests on the assumption that a shared box syntax and region-token injection recover volumetric structure from slice serialization. However, the architecture description does not specify any mechanism (e.g., 3D positional encodings or cross-slice attention) for modeling inter-slice spatial continuity; if boxes and tokens are applied independently per slice, the model reduces to per-slice 2D reasoning and the transfer benefit cannot be attributed to 3D structure recovery.
Authors: We appreciate the referee's focus on this architectural detail. The 3D input is processed as an ordered sequence of slices passed to the multimodal LLM; the transformer's self-attention operates over this serialized sequence, enabling cross-slice interactions during reasoning. Region tokens are generated per slice but referenced within the shared textual reasoning trace that spans the full sequence. We acknowledge that the original manuscript does not explicitly describe this cross-slice attention flow or contrast it with 3D positional encodings. In the revision we will expand the method section to detail the serialization process and clarify that inter-slice modeling occurs via LLM attention over the sequence rather than dimension-specific modules, consistent with the goal of a shared interface. revision: partial
-
Referee: [Experiments (ablations)] Data-mixture ablations show joint 2D+3D training improves 3D VQA metrics over 3D-only, but the reported experiments do not include a controlled test set of questions that require explicit cross-slice geometric reasoning (e.g., relative depth, 3D bounding-box consistency across slices). Without such a test, the ablation results are consistent with improved 2D reasoning per slice rather than genuine 3D transfer.
Authors: We agree that a dedicated test set isolating cross-slice geometric reasoning would provide more direct evidence. The current ablations evaluate on standard 3D medical VQA benchmarks whose questions involve volumetric understanding, and the consistent gains from joint 2D+3D training support transfer of the grounded reasoning policy. However, we do not currently possess a specialized cross-slice test set. In the revised manuscript we will explicitly discuss this limitation, note that the observed improvements are on existing benchmarks, and identify construction of such a test set as valuable future work. revision: partial
Circularity Check
No significant circularity; empirical claims rest on independent ablations
full rationale
The paper's central claim rests on constructing UniMed-CoT (220K samples), supervised fine-tuning plus outcome-level RL, and data-mixture/component ablations comparing joint 2D+3D training against 3D-only baselines. These results are externally falsifiable via the reported metrics and public code/data; no equations, fitted parameters renamed as predictions, or self-citation chains reduce the transfer claim to its inputs by construction. The architecture description (shared box syntax, region-token injection) is presented as an implementation choice whose effectiveness is tested rather than assumed.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
2023 , eprint=
SA-Med2D-20M Dataset: Segment Anything in 2D Medical Imaging with 20 Million masks , author=. 2023 , eprint=
2023
-
[9]
Computer Vision -- ECCV 2022 , year =
2022
-
[10]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[11]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[12]
M. J. Kearns , title =
-
[13]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[14]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[15]
Suppressed for Anonymity , author=
-
[16]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[17]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[18]
FirstName LastName , title =
-
[19]
FirstName Alpher , title =
-
[20]
Journal of Foo , volume = 13, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe , title =. Journal of Foo , volume = 13, number = 1, pages =
-
[21]
Journal of Foo , volume = 14, number = 1, pages =
FirstName Alpher and FirstName Fotheringham-Smythe and FirstName Gamow , title =. Journal of Foo , volume = 14, number = 1, pages =
-
[22]
FirstName Alpher and FirstName Gamow , title =
-
[23]
Scaling Learning Algorithms Towards
Bengio, Yoshua and LeCun, Yann , booktitle =. Scaling Learning Algorithms Towards
-
[24]
and Osindero, Simon and Teh, Yee Whye , journal =
Hinton, Geoffrey E. and Osindero, Simon and Teh, Yee Whye , journal =. A Fast Learning Algorithm for Deep Belief Nets , volume =
-
[25]
2016 , publisher=
Deep learning , author=. 2016 , publisher=
2016
-
[26]
2025 , eprint=
Grounded Chain-of-Thought for Multimodal Large Language Models , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
MedGround-R1: Advancing Medical Image Grounding via Spatial-Semantic Rewarded Group Relative Policy Optimization , author=. 2025 , eprint=
2025
-
[28]
2024 , eprint=
MAIRA-2: Grounded Radiology Report Generation , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
S-Chain: Structured Visual Chain-of-Thought For Medicine , author=. 2025 , eprint=
2025
-
[30]
2025 , eprint=
Argus: Vision-Centric Reasoning with Grounded Chain-of-Thought , author=. 2025 , eprint=
2025
-
[31]
2025 , eprint=
VILA-M3: Enhancing Vision-Language Models with Medical Expert Knowledge , author=. 2025 , eprint=
2025
-
[32]
2025 , eprint=
OmniV-Med: Scaling Medical Vision-Language Model for Universal Visual Understanding , author=. 2025 , eprint=
2025
-
[33]
Nature Communications , volume=
Towards generalist foundation model for radiology by leveraging web-scale 2d&3d medical data , author=. Nature Communications , volume=. 2025 , publisher=
2025
-
[34]
ISPRS Journal of Photogrammetry and Remote Sensing, , volume=
Rsgpt: A remote sensing vision language model and benchmark , author=. ISPRS Journal of Photogrammetry and Remote Sensing, , volume=. 2025 , publisher=
2025
-
[35]
2025 , howpublished =
Standards for interpretation and reporting of imaging investigations , author =. 2025 , howpublished =
2025
-
[36]
2023 , eprint=
GPT-4 Technical Report , author=. 2023 , eprint=
2023
-
[37]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[38]
IEEE Geoscience and Remote Sensing Magazine , volume=
BigEarthNet-MM: A large-scale, multimodal, multilabel benchmark archive for remote sensing image classification and retrieval [software and data sets] , author=. IEEE Geoscience and Remote Sensing Magazine , volume=. 2021 , publisher=
2021
-
[39]
ICML , pages=
Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models , author=. ICML , pages=. 2023 , organization=
2023
-
[40]
NeurIPS , volume=
Visual instruction tuning , author=. NeurIPS , volume=
-
[41]
TGRS , volume=
RSVQA: Visual question answering for remote sensing data , author=. TGRS , volume=. 2020 , publisher=
2020
-
[42]
TGRS , volume=
Rsvg: Exploring data and models for visual grounding on remote sensing data , author=. TGRS , volume=. 2023 , publisher=
2023
-
[43]
arXiv preprint arXiv:2410.18792 , year=
An llm agent for automatic geospatial data analysis , author=. arXiv preprint arXiv:2410.18792 , year=
-
[44]
TGRS , volume=
Exploring models and data for remote sensing image caption generation , author=. TGRS , volume=. 2017 , publisher=
2017
-
[45]
CVPR , pages=
Glamm: Pixel grounding large multimodal model , author=. CVPR , pages=
-
[46]
arXiv preprint arXiv:2501.04001 , year=
Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos , author=. arXiv preprint arXiv:2501.04001 , year=
-
[47]
Remote Sensing , volume=
Rs-llava: A large vision-language model for joint captioning and question answering in remote sensing imagery , author=. Remote Sensing , volume=. 2024 , publisher=
2024
-
[48]
IEEE Geoscience and Remote Sensing Magazine , volume=
2023 ieee grss data fusion contest: Large-scale fine-grained building classification for semantic urban reconstruction [technical committees] , author=. IEEE Geoscience and Remote Sensing Magazine , volume=. 2023 , publisher=
2023
-
[49]
arXiv preprint arXiv:2501.10891 , year=
OpenEarthMap-SAR: A Benchmark Synthetic Aperture Radar Dataset for Global High-Resolution Land Cover Mapping , author=. arXiv preprint arXiv:2501.10891 , year=
-
[50]
arXiv preprint arXiv:2502.01002 , year=
Multi-Resolution SAR and Optical Remote Sensing Image Registration Methods: A Review, Datasets, and Future Perspectives , author=. arXiv preprint arXiv:2502.01002 , year=
-
[51]
CVPR Workshops , pages=
SpaceNet 6: Multi-sensor all weather mapping dataset , author=. CVPR Workshops , pages=
-
[52]
International Journal of Applied Earth Observation and Geoinformation , volume=
MCANet: A joint semantic segmentation framework of optical and SAR images for land use classification , author=. International Journal of Applied Earth Observation and Geoinformation , volume=. 2022 , publisher=
2022
-
[53]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[54]
ECCV , pages=
Sharegpt4v: Improving large multi-modal models with better captions , author=. ECCV , pages=. 2024 , organization=
2024
-
[55]
IEEE Geoscience and Remote Sensing Magazine , volume=
Language Integration in Remote Sensing: Tasks, datasets, and future directions , author=. IEEE Geoscience and Remote Sensing Magazine , volume=. 2023 , publisher=
2023
-
[56]
Nature , volume=
Using machine learning to assess the livelihood impact of electricity access , author=. Nature , volume=. 2022 , publisher=
2022
-
[57]
Nature climate change , volume=
The role of satellite remote sensing in climate change studies , author=. Nature climate change , volume=. 2013 , publisher=
2013
-
[58]
Proceedings of the IEEE , volume=
Remote sensing image scene classification: Benchmark and state of the art , author=. Proceedings of the IEEE , volume=. 2017 , publisher=
2017
-
[59]
IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=
Remote sensing image scene classification meets deep learning: Challenges, methods, benchmarks, and opportunities , author=. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing , volume=. 2020 , publisher=
2020
-
[60]
IEEE Geoscience and Remote Sensing Letters , volume=
Region-of-interest extraction based on frequency domain analysis and salient region detection for remote sensing image , author=. IEEE Geoscience and Remote Sensing Letters , volume=. 2013 , publisher=
2013
-
[61]
Computers, Environment and Urban Systems , volume=
Knowledge-based region labeling for remote sensing image interpretation , author=. Computers, Environment and Urban Systems , volume=. 2012 , publisher=
2012
-
[62]
ISPRS Journal of Photogrammetry and Remote Sensing, , volume=
Remote sensing image segmentation advances: A meta-analysis , author=. ISPRS Journal of Photogrammetry and Remote Sensing, , volume=. 2021 , publisher=
2021
-
[63]
ISPRS Journal of Photogrammetry and Remote Sensing, , volume=
Segmentation for Object-Based Image Analysis (OBIA): A review of algorithms and challenges from remote sensing perspective , author=. ISPRS Journal of Photogrammetry and Remote Sensing, , volume=. 2019 , publisher=
2019
-
[64]
Remote Sensing of Environment , volume=
Improving the impervious surface estimation with combined use of optical and SAR remote sensing images , author=. Remote Sensing of Environment , volume=. 2014 , publisher=
2014
-
[65]
Qwen2. 5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
-
[66]
arXiv preprint arXiv:2503.18478 , year=
Video-xl-pro: Reconstructive token compression for extremely long video understanding , author=. arXiv preprint arXiv:2503.18478 , year=
-
[67]
arXiv preprint arXiv:2406.04264 , year=
Mlvu: A comprehensive benchmark for multi-task long video understanding , author=. arXiv preprint arXiv:2406.04264 , year=
-
[68]
arXiv preprint arXiv:2406.12384 , year=
Vrsbench: A versatile vision-language benchmark dataset for remote sensing image understanding , author=. arXiv preprint arXiv:2406.12384 , year=
-
[69]
arXiv preprint arXiv:2406.10100 , year=
Skysensegpt: A fine-grained instruction tuning dataset and model for remote sensing vision-language understanding , author=. arXiv preprint arXiv:2406.10100 , year=
-
[70]
AAAI , volume=
Urbench: A comprehensive benchmark for evaluating large multimodal models in multi-view urban scenarios , author=. AAAI , volume=
-
[71]
ICML , year=
GeoPixel: Pixel Grounding Large Multimodal Model in Remote Sensing , author=. ICML , year=
-
[72]
arXiv preprint arXiv:2411.19325 , year=
GEOBench-VLM: Benchmarking Vision-Language Models for Geospatial Tasks , author=. arXiv preprint arXiv:2411.19325 , year=
-
[73]
arXiv preprint arXiv:2503.23771 , year=
XLRS-Bench: Could Your Multimodal LLMs Understand Extremely Large Ultra-High-Resolution Remote Sensing Imagery? , author=. arXiv preprint arXiv:2503.23771 , year=
-
[74]
CVPR , pages=
Good at captioning bad at counting: Benchmarking gpt-4v on earth observation data , author=. CVPR , pages=
-
[75]
AAAI , volume=
Vhm: Versatile and honest vision language model for remote sensing image analysis , author=. AAAI , volume=
-
[76]
IGARSS , pages=
Fusion of SAR and optical remote sensing data—Challenges and recent trends , author=. IGARSS , pages=. 2017 , organization=
2017
-
[77]
arXiv preprint arXiv:2406.19280 , year=
Huatuogpt-vision, towards injecting medical visual knowledge into multimodal llms at scale , author=. arXiv preprint arXiv:2406.19280 , year=
-
[78]
arXiv preprint arXiv:2502.09838 , year=
Healthgpt: A medical large vision-language model for unifying comprehension and generation via heterogeneous knowledge adaptation , author=. arXiv preprint arXiv:2502.09838 , year=
-
[79]
arXiv preprint arXiv:2412.07769 , year=
Bimedix2: Bio-medical expert lmm for diverse medical modalities , author=. arXiv preprint arXiv:2412.07769 , year=
-
[80]
arXiv preprint arXiv:2404.16994 , year=
Pllava: Parameter-free llava extension from images to videos for video dense captioning , author=. arXiv preprint arXiv:2404.16994 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.