DuoBench: A Reproducible Benchmark for Bimanual Manipulation in Simulation and the Real World
Pith reviewed 2026-06-27 09:40 UTC · model grok-4.3
The pith
DuoBench reveals that current bimanual policies struggle with early interactions, parallel arm execution, and simulation-to-reality transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
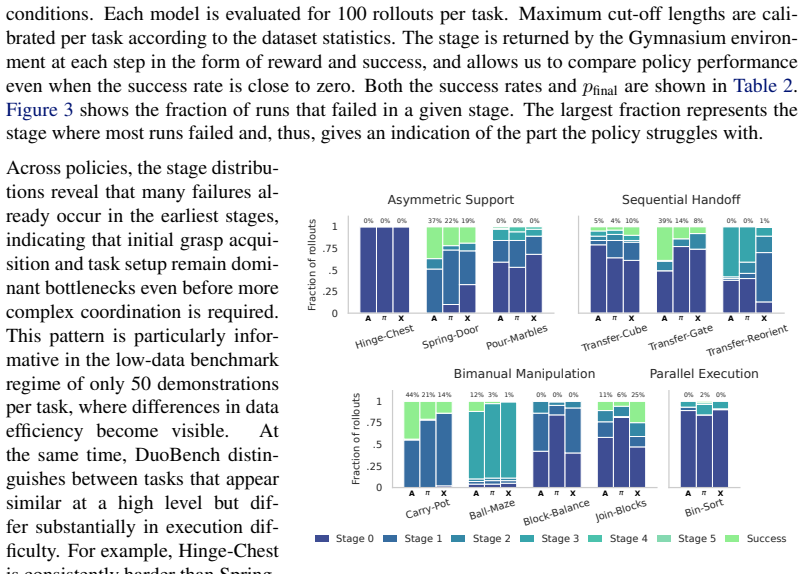
DuoBench comprises eleven tasks spanning four coordination categories, implemented in simulation and partially reproduced in the real world through reproducible task recipes with 3D-printable assets. It includes a stage-based evaluation scheme for fine-grained semantic failure analysis and provides human-teleoperated datasets for all tasks. Benchmarking of dual-arm imitation-learning and vision-language-action policies demonstrates that current methods remain challenged by bimanual manipulation, particularly in early interaction stages, parallel arm execution, and transfer between simulation and real-world settings.
What carries the argument
The stage-based evaluation scheme that decomposes each task into ordered phases to enable semantic diagnosis of coordination failures.
If this is right
- Dual-arm policies require targeted improvements for the initial phases of object contact.
- Simultaneous control of both arms must be addressed as a distinct capability.
- Methods that reduce the performance gap between simulation and physical execution become necessary.
- Reproducible task definitions allow consistent comparison of new algorithms across different laboratories.
- Human teleoperation datasets can serve as direct supervision for learning coordinated behaviors.
Where Pith is reading between the lines
- The stage-based scheme could be applied to single-arm or multi-robot benchmarks to expose analogous phase-specific weaknesses.
- Failure patterns identified here may point toward policy architectures that explicitly model inter-arm dependencies.
- Adding tasks with higher degrees of object complexity or environmental variation would test whether the observed challenges scale.
- Combining the provided datasets with existing single-arm collections could create mixed training regimes for dual-arm learning.
Load-bearing premise
The eleven tasks and four coordination categories together capture the coordination challenges and failure modes that existing benchmarks miss.
What would settle it
A single policy that reaches high success rates in every stage of all eleven tasks in both simulation and the real world without additional coordination-specific training would indicate that the reported challenges are not general.
Figures




read the original abstract
Bimanual robot systems substantially expand manipulation capabilities, but coordinating two arms introduces additional control complexity and failure modes that are not well captured by existing benchmarks. We introduce DuoBench, an extensible benchmarking framework for bimanual manipulation policies on the FR3 Duo platform. DuoBench comprises eleven tasks spanning four coordination categories, implemented in simulation and partially reproduced in the real world through reproducible task recipes with 3D-printable assets. In addition, we propose a stage-based evaluation scheme that supports fine-grained semantic failure analysis beyond binary success and provide human-teleoperated datasets for all benchmark tasks. We benchmark several dual-arm imitation-learning and vision-language-action policies in simulation and on real hardware. Our results show that current policies remain challenged by bimanual manipulation, particularly in early interaction stages, parallel arm execution, and transfer between simulation and real-world settings. DuoBench provides a reproducible testbed for diagnosing these failure modes and studying future methods for dual-arm policy learning. Code, datasets, and videos are available at https://duobench.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DuoBench, an extensible benchmarking framework for bimanual manipulation policies on the FR3 Duo platform. It comprises eleven tasks spanning four coordination categories, implemented in simulation with partial real-world reproduction via reproducible recipes and 3D-printable assets. A stage-based evaluation scheme is proposed for fine-grained semantic failure analysis beyond binary success, human-teleoperated datasets are provided for all tasks, and several dual-arm imitation-learning and vision-language-action policies are benchmarked. The central claim is that current policies remain challenged by bimanual manipulation (particularly early interaction stages, parallel arm execution, and sim-to-real transfer) and that DuoBench supplies a reproducible testbed for diagnosing these issues.
Significance. If the tasks and stage-based scheme prove effective at exposing coordination and transfer failure modes not captured by prior benchmarks, and if the reproducibility elements (public code, datasets, and assets) function as described, the work could provide a useful standardized testbed for dual-arm policy research. The inclusion of human datasets and partial real-world validation are positive elements that support imitation learning and sim-to-real studies.
major comments (2)
- [Abstract] Abstract: the claim that 'our results show that current policies remain challenged' is asserted without reference to specific quantitative outcomes (e.g., success rates per task or stage, number of trials, or statistical measures), which is load-bearing for the diagnostic value of the benchmark.
- [Task and evaluation design] Task and evaluation design (Abstract and § on benchmark tasks): the assertion that the eleven tasks and stage-based scheme capture coordination challenges and failure modes missed by existing benchmarks is central to the contribution but lacks explicit comparative analysis or evidence demonstrating unique diagnostic power relative to prior work.
minor comments (1)
- [Reproducibility] Reproducibility section: confirm that all linked assets (code, datasets, 3D models) include complete setup instructions matching the claimed partial real-world reproduction to avoid ambiguity for users.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'our results show that current policies remain challenged' is asserted without reference to specific quantitative outcomes (e.g., success rates per task or stage, number of trials, or statistical measures), which is load-bearing for the diagnostic value of the benchmark.
Authors: We agree that the abstract would benefit from explicit quantitative support for the central claim. The full manuscript contains the relevant experimental results (success rates by task, stage, and policy type, along with trial counts), but these are not summarized in the abstract. In the revised version we will add concise references to key outcomes, such as aggregate success rates for the evaluated imitation-learning and VLA policies and the number of trials per task, while preserving the abstract's length and focus. revision: yes
-
Referee: [Task and evaluation design] Task and evaluation design (Abstract and § on benchmark tasks): the assertion that the eleven tasks and stage-based scheme capture coordination challenges and failure modes missed by existing benchmarks is central to the contribution but lacks explicit comparative analysis or evidence demonstrating unique diagnostic power relative to prior work.
Authors: The manuscript introduces novel tasks spanning four coordination categories and a stage-based evaluation that enables finer-grained failure analysis than binary success metrics common in prior benchmarks. Our benchmarking results highlight specific issues (early-stage interaction, parallel execution, sim-to-real gaps) that arise under these tasks. However, we acknowledge that an explicit side-by-side comparison of diagnostic power versus representative prior benchmarks is not currently present. We will add a short comparative paragraph in the benchmark tasks section that directly contrasts the failure modes surfaced by DuoBench with those reported in existing single-arm or less-coordinated benchmarks, using concrete examples from our data. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper with no mathematical derivations, equations, fitted parameters, or predictions. The eleven tasks, four coordination categories, stage-based evaluation, and policy benchmarks are defined directly from task requirements and external policy implementations; reproducibility rests on linked code, datasets, and 3D assets rather than any self-referential construction. No self-citation load-bearing steps, ansatzes, or renamings appear. The central claims rest on external comparisons to prior benchmarks and observed policy failures, making the work self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In Proc. of the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS), 2012
2012
-
[2]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[3]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su. SAPIEN: A simulated part-based interactive environ- ment. InProc. of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[4]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. RLBench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2), 2020
2020
-
[5]
T. Yu, D. Quillen, Z. He, R. Julian, K. Hausman, C. Finn, and S. Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. InProc. of the Conf. on Robot Learning (CoRL), 2020
2020
-
[6]
T. Mu, Z. Ling, F. Xiang, D. C. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, and H. Su. ManiSkill: Generalizable Manipulation Skill Benchmark with Large-Scale Demonstrations. InNeural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[7]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. ManiSkill2: A unified benchmark for generalizable manipulation skills. InProc. of the Int. Conf. on Learning Representations (ICLR), 2023
2023
-
[8]
Stone, F
T. Stone, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T.-K. Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N., Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Demonstrating gpu parallelized robot simulation and rendering for generalizable embodied ai with ManiSkill3. InProc. of Robotics:...
2025
-
[9]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning. InAdvances in Neural Information Processing Sys- tems, 2023
2023
-
[10]
Y . Zhu, J. Wong, A. Mandlekar, R. Mart´ın-Mart´ın, A. Joshi, K. Lin, A. Maddukuri, S. Nasiri- any, and Y . Zhu. robosuite: A modular simulation framework and benchmark for robot learn- ing.https://arxiv.org/abs/2009.12293, 2025
Pith/arXiv arXiv 2009
-
[11]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, J. Fu, J. Gong, and X. Qiu. LIBERO-Plus: In-depth Robustness Analysis of Vision-Language-Action Models. https://arxiv.org/abs/2510.13626, 2025
Pith/arXiv arXiv 2025
-
[12]
X. Zhou, Y . Xu, G. Tie, Y . Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: To- wards Robust and Fair Evaluation of Vision-Language-Action Models Beyond Memorization. https://arxiv.org/abs/2510.03827, 2025. 9
Pith/arXiv arXiv 2025
-
[13]
G. Wang, C. Zhang, Q. Liu, J. Zhang, J. Cai, J. Liu, and X. Liu. LIBERO-X: Robustness Litmus for Vision-Language-Action Models.https://arxiv.org/abs/2602.06556, 2026
arXiv 2026
-
[14]
Nasiriany, A
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu. RoboCasa: Large-scale simulation of household tasks for generalist robots. InProc. of Robotics: Science and Systems (RSS), 2024
2024
-
[15]
Nasiriany, S
S. Nasiriany, S. Nasiriany, A. Maddukuri, and Y . Zhu. RoboCasa365: A large-scale simulation framework for training and benchmarking generalist robots. InProc. of the Int. Conf. on Learning Representations (ICLR), 2026
2026
-
[16]
Y . Lee, E. S. Hu, and J. J. Lim. IKEA Furniture Assembly Environment for Long-Horizon Complex Manipulation Tasks. InProc. of the IEEE Int. Conf. on Robotics & Automation (ICRA), 2021
2021
-
[17]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3), 2022
2022
-
[18]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, and X. Qiu. VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipu- lation with Long-Horizon Reasoning Tasks. InProc. of Int. Conf. on Computer Vision (ICCV), 2025
2025
-
[19]
Jiang, A
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei-Fei, A. Anandkumar, Y . Zhu, and L. Fan. VIMA: Robot Manipulation with Multimodal Prompts. InProc. of the Int. Conf. on Machine Learning (ICML), 2023
2023
-
[20]
Kumar, R
V . Kumar, R. Shah, G. Zhou, V . Moens, V . Caggiano, A. Gupta, and A. Rajeswaran. RoboHive: A Unified Framework for Robot Learning. InAdvances in Neural Information Processing Systems, 2023
2023
-
[21]
H. Geng, F. Wang, S. Wei, Y . Li, B. Wang, B. An, H. Lou, C. T. Cheng, P. Li, H. Chen, Y . Liang, Y . Qian, J. Mao, W. Wan, Y . Geng, M. Zhang, J. Lyu, S. Zhao, J. Zhang, C. Xu, J. Zhang, C. Zhao, H. Lu, Y . Ding, R. Gong, Y . Wang, Y . Kuang, R. Wu, B. Jia, H. Dong, S. Huang, Y . Wang, J. Malik, and P. Abbeel. RoboVerse: A unified platform, benchmark and...
2025
-
[22]
M. Grotz, M. Shridhar, Y .-W. Chao, T. Asfour, and D. Fox. Twin: Two-handed intelligent benchmark for bimanual manipulation. InProc. of the IEEE Int. Conf. on Robotics & Automa- tion (ICRA), 2025. doi:10.1109/ICRA55743.2025.11128527
-
[23]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y . Liu, Z. Li, Q. Liang, X. Lin, Y . Ge, Z. Gu, W. Deng, Y . Guo, T. Nian, X. Xie, Q. Chen, K. Su, T. Xu, G. Liu, M. Hu, H. ang Gao, K. Wang, Z. Liang, Y . Qin, X. Yang, P. Luo, and Y . Mu. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation. ht...
Pith/arXiv arXiv 2025
-
[24]
X. Peng, C. Gao, L. Jin, A. Li, and S. Liu. Bicoord: A bimanual manipulation benchmark to- wards long-horizon spatial-temporal coordination.https://arxiv.org/abs/2604.05831, 2026
Pith/arXiv arXiv 2026
-
[25]
Srivastava, C
S. Srivastava, C. Li, M. Lingelbach, R. Mart ´ın-Mart´ın, F. Xia, K. E. Vainio, Z. Lian, C. Gok- men, S. Buch, K. Liu, S. Savarese, H. Gweon, J. Wu, and L. Fei-Fei. BEHA VIOR: Benchmark for Everyday Household Activities in Virtual, Interactive, and Ecological Environments. In Proc. of the Conf. on Robot Learning (CoRL), 2022. 10
2022
-
[26]
Y . Chen, Y . Geng, F. Zhong, J. Ji, J. Jiang, Z. Lu, H. Dong, and Y . Yang. Bi-DexHands: To- wards human-level bimanual dexterous manipulation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5), 2024
2024
-
[27]
X. Wu, Z. Liang, Y . Ma, M. Hu, Z. Qin, and X. Li. ST-BiBench: Benchmarking Multi-Stream Multimodal Coordination in Bimanual Embodied Tasks for MLLMs.https://arxiv.org/ abs/2602.08392, 2026
Pith/arXiv arXiv 2026
-
[28]
Sferrazza, D.-M
C. Sferrazza, D.-M. Huang, X. Lin, Y . Lee, and P. Abbeel. HumanoidBench: Simulated hu- manoid benchmark for whole-body locomotion and manipulation. InProc. of Robotics: Sci- ence and Systems (RSS), 2024
2024
-
[29]
Chernyadev, N
N. Chernyadev, N. Backshall, X. Ma, Y . Lu, Y . Seo, and S. James. BiGym: A Demo-Driven Mobile Bi-Manual Manipulation Benchmark. InProc. of the Conf. on Robot Learning (CoRL), 2025
2025
-
[30]
J. Luo, C. Xu, F. Liu, L. Tan, Z. Lin, J. Wu, P. Abbeel, and S. Levine. FMB: A functional manipulation benchmark for generalizable robotic learning.Int. Journal of Robotics Research (IJRR), 44(4), 2025
2025
-
[31]
M. Heo, Y . Lee, D. Lee, and J. J. Lim. Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation.Int. Journal of Robotics Research (IJRR), 2023
2023
-
[32]
K. Wu, C. Hou, J. Liu, Z. Che, X. Ju, Z. Yang, M. Li, Y . Zhao, Z. Xu, G. Yang, S. Fan, X. Wang, F. Liao, Z. Zhao, G. Li, Z. Jin, L. Wang, J. Mao, N. Liu, P. Ren, Q. Zhang, Y . Lyu, M. Liu, H. Jingyang, Y . Luo, Z. Gao, C. Li, C. Gu, Y . Fu, D. Wu, X. Wang, S. Chen, Z. Wang, P. An, S. Qian, S. Zhang, and J. Tang. RoboMIND: Benchmark on multi-embodiment in...
2025
-
[33]
Atreya, K
P. Atreya, K. Pertsch, T. Lee, M. J. Kim, A. Jain, A. Kuramshin, C. Neary, E. S. Hu, K. Arora, K. Ellis, L. Macesanu, M. Leonard, M. Cho, O. Aslan, S. Dass, T. Wang, X. Yuan, A. Gupta, D. Jayaraman, G. Berseth, K. Daniilidis, R. Mart ´ın-Mart´ın, Y . Lee, P. Liang, C. Finn, and S. Levine. RoboArena: Distributed Real-World Evaluation of Generalist Robot Po...
2025
-
[34]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
- [35]
-
[36]
R. S. Sutton, A. G. Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[37]
Franka documentation portal.https://www.franka.de/ documents, 2026
Franka Robotics GmbH. Franka documentation portal.https://www.franka.de/ documents, 2026. 11
2026
-
[38]
Zakka, Y
K. Zakka, Y . Tassa, and MuJoCo Menagerie Contributors. MuJoCo Menagerie: A col- lection of high-quality simulation models for MuJoCo, 2022. URLhttp://github.com/ google-deepmind/mujoco_menagerie
2022
-
[39]
F. Krebs and T. Asfour. A bimanual manipulation taxonomy.IEEE Robotics and Automation Letters, 7(4), 2022. doi:10.1109/LRA.2022.3196158
-
[40]
Towers, A
M. Towers, A. Kwiatkowski, J. Terry, J. U. Balis, G. D. Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, A. KG, R. Perez-Vicente, A. Pierr´e, S. Schulhoff, J. J. Tai, H. Tan, and O. G. Younis. Gymnasium: A standard interface for reinforcement learning environments. InAdvances in Neural Information Processing Systems, 2025
2025
-
[41]
Jiang, Q
X. Jiang, Q. Yuan, E. U. Dincer, H. Zhou, G. Li, X. Li, X. Jia, T. Schnizer, N. Schreiber, W. Liao, J. Haag, K. Li, G. Neumann, and R. Lioutikov. IRIS: An immersive robot interaction system. InProc. of the Conf. on Robot Learning (CoRL), volume 305, 2025
2025
-
[42]
J ¨ulg, K
T. J ¨ulg, K. Gamal, N. Nilavadi, P. Krack, S. Bien, M. Krawez, F. Walter, and W. Burgard. VLAgents: A Policy Server for Efficient VLA Inference.https://arxiv.org/abs/2601. 11250, 2026
2026
-
[43]
T. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware. InProc. of Robotics: Science and Systems (RSS), 2023
2023
-
[44]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
2025
-
[45]
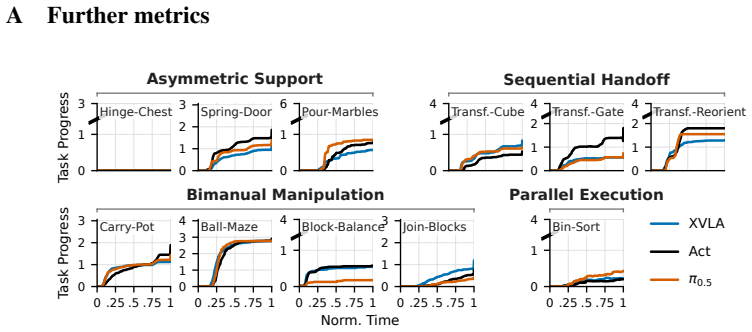
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y . Feng, Y . Zheng, J. Zou, Y . Chen, J. Zeng, Y .-Q. Zhang, J. Pang, J. Liu, T. Wang, and X. Zhan. X-VLA: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.https://arxiv.org/abs/2510.10274, 2025. 12 A Further metrics 0 1 3 T ask Progress Hinge-Chest 0 1 2 3 Spring-Door 0 1 6 Po...
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.