GeoDial: A Multimodal Conversational Tutoring Dataset for Geometry Problem-Solving with Visual Tutor Turns
Pith reviewed 2026-06-30 23:17 UTC · model grok-4.3
The pith
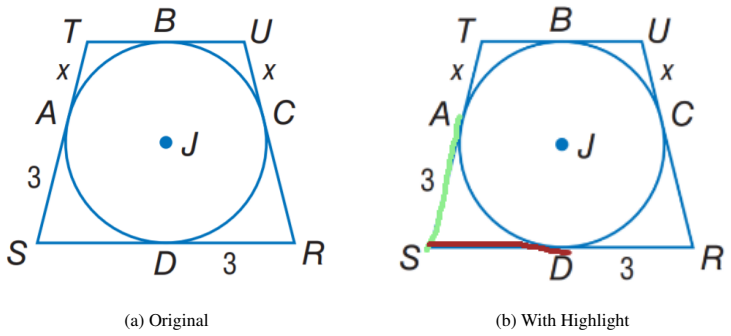
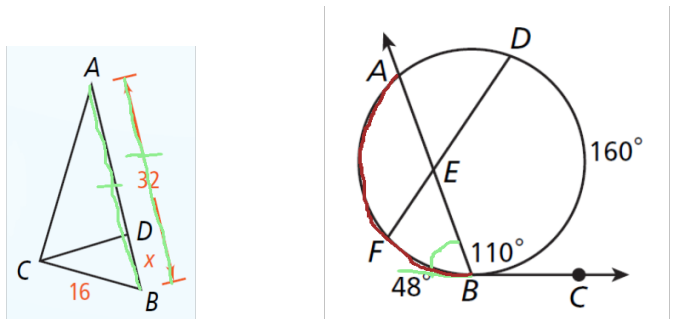
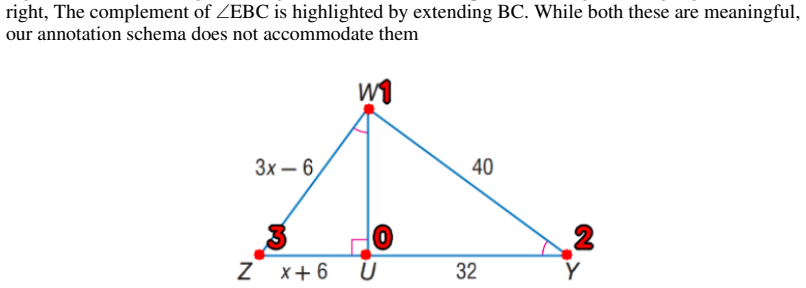
GeoDial supplies 1.3K geometry tutoring dialogs where each teacher turn is paired with explicit diagram highlights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GeoDial is a dataset of more than 1,300 teacher-student dialogs in geometry in which instructional turns are grounded in diagram highlights; a scalable annotation protocol records dialog acts, visual highlights, and feedback together, and supervised fine-tuning of vision-language models improves generated utterances but not the accuracy of the highlights.
What carries the argument
The annotation protocol that jointly labels dialog acts, diagram highlight regions, and feedback to supervise both language and visual tutoring actions.
If this is right
- Supervised fine-tuning on GeoDial raises the quality of generated tutoring utterances.
- The same fine-tuned models still produce inaccurate diagram highlights.
- Current vision-language methods do not yet integrate visual reasoning with pedagogical interaction at the level needed for tutoring.
- New techniques that couple visual grounding more tightly with dialog generation are required.
Where Pith is reading between the lines
- The dataset could support tutors that generate live diagram annotations during explanations rather than after-the-fact text.
- The same annotation style could be applied to tutoring in other diagram-rich subjects such as mechanics or organic chemistry.
- Separate pre-training on visual grounding tasks before dialog fine-tuning might close the observed highlight gap.
- Controlled classroom trials could test whether students using models trained on GeoDial solve geometry problems faster than those using text-only tutors.
Load-bearing premise
Dialogs collected from experienced math teachers with this annotation protocol capture effective visual tutoring strategies that transfer to training AI tutors.
What would settle it
If vision-language models fine-tuned on GeoDial produce no measurable gain in highlight accuracy or student understanding on a new set of geometry problems compared with text-only baselines, the dataset's claimed training value would be refuted.
Figures













read the original abstract
Several educational domains rely heavily on diagrams and visual cues, yet most existing tutoring datasets are limited to text-only interactions. This limits the development of AI tutors that can teach in visually grounded ways used by human instructors. Thus, we introduce GeoDial, a multimodal tutoring dataset of over 1.3K teacher-student dialogs in the domain of geometry collected from experienced math teachers, where instructional turns are explicitly grounded in diagram highlights. We propose a scalable annotation protocol that integrates dialog acts, visual highlighting, and feedback, enabling fine-grained supervision of both language and visual tutoring behavior. To illustrate the challenges posed by this setting, we fine-tune several vision-language models on GeoDial and evaluate their ability to generate tutoring utterances and diagram highlights. While supervised fine-tuning substantially improves the quality of generated dialog, it struggles to produce accurate diagram highlights, revealing a key limitation of current methods and highlighting the need for approaches that more effectively integrate visual reasoning with pedagogical interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeoDial, a multimodal tutoring dataset of over 1.3K teacher-student dialogs in geometry collected from experienced math teachers, with instructional turns explicitly grounded in diagram highlights. It proposes a scalable annotation protocol integrating dialog acts, visual highlighting, and feedback. Experiments fine-tune several vision-language models on the dataset and report that supervised fine-tuning substantially improves generated dialog quality but struggles to produce accurate diagram highlights.
Significance. If the collected dialogs and annotation protocol prove reliable, the dataset could meaningfully advance research on visually grounded AI tutors by addressing the gap in text-only educational datasets and providing explicit supervision for both language and visual actions. The release of such grounded multimodal data is a clear strength for the field.
minor comments (1)
- [Abstract] Abstract: no quantitative details on inter-annotator agreement, dataset statistics beyond the total count, evaluation metrics, or baseline comparisons are provided, which would allow readers to assess the robustness of the VLM limitation claims.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of GeoDial, the accurate summary of our contributions, and the recommendation for minor revision. We are pleased that the potential impact of releasing this visually grounded tutoring dataset is recognized.
Circularity Check
No significant circularity
full rationale
The paper introduces a multimodal dataset (GeoDial) collected from teachers, proposes an annotation protocol integrating dialog acts/visual highlights/feedback, and reports illustrative SFT experiments on vision-language models. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described content. The central claims rest on the external collection process and model evaluations rather than any internal reduction to inputs by construction. This is a standard dataset paper whose contribution is self-contained and falsifiable via the released data and replication of the reported metrics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dialogs collected from experienced math teachers constitute high-quality examples of visually grounded tutoring suitable for training AI systems.
Reference graph
Works this paper leans on
-
[1]
1969 , publisher=
Audiovisual methods in teaching , author=. 1969 , publisher=
1969
-
[2]
Monographs on statistics and applied probability , volume=
An introduction to the bootstrap , author=. Monographs on statistics and applied probability , volume=
-
[3]
Statistical Significance Tests for Machine Translation Evaluation
Koehn, Philipp. Statistical Significance Tests for Machine Translation Evaluation. Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing. 2004
2004
-
[4]
I nter- GPS : Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning
Lu, Pan and Gong, Ran and Jiang, Shibiao and Qiu, Liang and Huang, Siyuan and Liang, Xiaodan and Zhu, Song-Chun. I nter- GPS : Interpretable Geometry Problem Solving with Formal Language and Symbolic Reasoning. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Lan...
-
[5]
2020 , eprint=
Scaling Laws for Neural Language Models , author=. 2020 , eprint=
2020
-
[6]
2025 , eprint=
LearnLM: Improving Gemini for Learning , author=. 2025 , eprint=
2025
-
[7]
BLEU : a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =. 2002 , publisher =. doi:10.3115/1073083.1073135 , abstract =
-
[8]
Learning and instruction , volume=
Teacher emotions are linked with teaching quality: Cross-sectional and longitudinal evidence from two field studies , author=. Learning and instruction , volume=. 2023 , publisher=
2023
-
[9]
Memory , volume=
How much is remembered as a function of presentation modality? , author=. Memory , volume=. 2019 , publisher=
2019
-
[10]
History of Education Quarterly , volume=
An officer and a scholar: Nineteenth-century West Point and the invention of the blackboard , author=. History of Education Quarterly , volume=. 2015 , publisher=
2015
-
[11]
Psychonomic bulletin & review , volume=
Cognitive tutor: Applied research in mathematics education , author=. Psychonomic bulletin & review , volume=. 2007 , publisher=
2007
-
[12]
, author=
Explanation feedback is better than correct answer feedback for promoting transfer of learning. , author=. Journal of Educational Psychology , volume=. 2013 , publisher=
2013
-
[13]
Brian J. Reiser , title =. Journal of the Learning Sciences , volume =. 2004 , publisher =. doi:10.1207/s15327809jls1303\_2 , URL =
-
[14]
and Sumner, Tamara
Suresh, Abhijit and Jacobs, Jennifer and Harty, Charis and Perkoff, Margaret and Martin, James H. and Sumner, Tamara. The T alk M oves Dataset: K-12 Mathematics Lesson Transcripts Annotated for Teacher and Student Discursive Moves. Proceedings of the Thirteenth Language Resources and Evaluation Conference. 2022
2022
-
[15]
and Aleven, Vincent and Heffernan, Neil and McLaren, Bruce and Hockenberry, Matthew , editor=
Koedinger, Kenneth R. and Aleven, Vincent and Heffernan, Neil and McLaren, Bruce and Hockenberry, Matthew , editor=. Opening the Door to Non-programmers:. Intelligent Tutoring Systems , year=
-
[16]
Can LLM s Effectively Simulate Human Learners? Teachers' Insights from Tutoring LLM Students
Martynova, Daria and Macina, Jakub and Daheim, Nico and Yalcin, Nilay and Zhang, Xiaoyu and Sachan, Mrinmaya. Can LLM s Effectively Simulate Human Learners? Teachers' Insights from Tutoring LLM Students. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.8
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Swift: a scalable lightweight infrastructure for fine-tuning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[18]
and Demszky, Dorottya and Koedinger, Kenneth R
Thomas, Danielle R. and Demszky, Dorottya and Koedinger, Kenneth R. and Marland, Joshua and Pietrzak, Doug and Reich, Justin and Slama, Rachel and Toutziaridi, Amalia and Kizilcec, Ren\'. Advancing the Science of Teaching with Tutoring Data: A Collaborative Workshop with the National Tutoring Observatory , year =. Proceedings of the Twelfth ACM Conference...
-
[19]
Wang, Rose and Zhang, Qingyang and Robinson, Carly and Loeb, Susanna and Demszky, Dorottya. Bridging the Novice-Expert Gap via Models of Decision-Making: A Case Study on Remediating Math Mistakes. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long P...
-
[20]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
-
[21]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , author=
Diagram Understanding in Geometry Questions , volume=. Proceedings of the AAAI Conference on Artificial Intelligence , author=. 2014 , month=. doi:10.1609/aaai.v28i1.9146 , abstractNote=
-
[23]
Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications , year=
Fine-tuning transformers with additional context to classify discursive moves in mathematics classrooms , author=. Proceedings of the 17th Workshop on Innovative Use of NLP for Building Educational Applications , year=
-
[24]
Proceedings of the 9th Workshop on NLP for Computer Assisted Language Learning , pages=
The teacher-student chatroom corpus , author=. Proceedings of the 9th Workshop on NLP for Computer Assisted Language Learning , pages=
-
[25]
Macina, Jakub and Daheim, Nico and Chowdhury, Sankalan and Sinha, Tanmay and Kapur, Manu and Gurevych, Iryna and Sachan, Mrinmaya. M ath D ial: A Dialogue Tutoring Dataset with Rich Pedagogical Properties Grounded in Math Reasoning Problems. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.372
-
[26]
CIMA : A Large Open Access Dialogue Dataset for Tutoring
Stasaski, Katherine and Kao, Kimberly and Hearst, Marti A. CIMA : A Large Open Access Dialogue Dataset for Tutoring. Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications. 2020. doi:10.18653/v1/2020.bea-1.5
-
[27]
2025 , month =
Claude 4 System Card: Claude Opus 4 & Claude Sonnet 4 , author =. 2025 , month =
2025
-
[28]
2024 , eprint=
GPT-4o System Card , author=. 2024 , eprint=
2024
-
[29]
2025 , eprint=
Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Generation Agentic Capabilities , author=. 2025 , eprint=
2025
-
[30]
Educational Practices Series; 5 , year=
Tutoring , author=. Educational Practices Series; 5 , year=
-
[31]
Handbook of research on educational communications and technology , pages=
Multimedia instruction , author=. Handbook of research on educational communications and technology , pages=. 2013 , publisher=
2013
-
[32]
, author=
A meta-analysis of the efficacy of teaching mathematics with concrete manipulatives. , author=. Journal of educational psychology , volume=. 2013 , publisher=
2013
-
[33]
Psychological science , volume=
From action to abstraction: Using the hands to learn math , author=. Psychological science , volume=. 2014 , publisher=
2014
-
[34]
Behavior Research Methods, Instruments, & Computers , volume=
AutoTutor: A tutor with dialogue in natural language , author=. Behavior Research Methods, Instruments, & Computers , volume=. 2004 , publisher=
2004
-
[35]
Educational researcher , volume=
The 2 sigma problem: The search for methods of group instruction as effective as one-to-one tutoring , author=. Educational researcher , volume=. 1984 , publisher=
1984
-
[36]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[38]
Proceedings of the ACL-08: HLT Student Research Workshop , pages=
The role of positive feedback in intelligent tutoring systems , author=. Proceedings of the ACL-08: HLT Student Research Workshop , pages=
-
[39]
Edward J Hu and Yelong Shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=. Lo. 2022 , url=
2022
-
[40]
nature , volume=
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
2017
-
[41]
Learning and Motivation , volume=
Positive feedback enhances motivation and skill learning in adolescents , author=. Learning and Motivation , volume=. 2024 , publisher=
2024
-
[42]
G eo QA : A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning
Chen, Jiaqi and Tang, Jianheng and Qin, Jinghui and Liang, Xiaodan and Liu, Lingbo and Xing, Eric and Lin, Liang. G eo QA : A Geometric Question Answering Benchmark Towards Multimodal Numerical Reasoning. Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2021. doi:10.18653/v1/2021.findings-acl.46
-
[43]
G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model , url =
Gao, Jiahui and Pi, Renjie and Zhang, Jipeng and Ye, Jiacheng and Zhong, Wanjun and Wang, Yufei and HONG, Lanqing and Han, Jianhua and Xu, Hang and Li, Zhenguo and Kong, Lingpeng , booktitle =. G-LLaVA: Solving Geometric Problem with Multi-Modal Large Language Model , url =
-
[44]
arXiv preprint arXiv:2504.12597 , year=
Geosense: Evaluating identification and application of geometric principles in multimodal reasoning , author=. arXiv preprint arXiv:2504.12597 , year=
-
[45]
U ni G eo: Unifying Geometry Logical Reasoning via Reformulating Mathematical Expression
Chen, Jiaqi and Li, Tong and Qin, Jinghui and Lu, Pan and Lin, Liang and Chen, Chongyu and Liang, Xiaodan. U ni G eo: Unifying Geometry Logical Reasoning via Reformulating Mathematical Expression. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 2022. doi:10.18653/v1/2022.emnlp-main.218
-
[46]
Zhang, Ming-Liang and Yin, Fei and Liu, Cheng-Lin , title =. Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence , articleno =. 2023 , isbn =. doi:10.24963/ijcai.2023/376 , abstract =
-
[47]
Educational Psychology Review , volume=
The impact of visual displays on learning across the disciplines: A systematic review , author=. Educational Psychology Review , volume=. 2020 , publisher=
2020
-
[48]
STEM education in the junior secondary: The state of play , pages=
The importance of diagrams, graphics and other visual representations in STEM teaching , author=. STEM education in the junior secondary: The state of play , pages=. 2017 , publisher=
2017
-
[49]
DeepSeek-OCR: Contexts Optical Compression
DeepSeek-OCR: Contexts Optical Compression , author=. arXiv preprint arXiv:2510.18234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
2025 , note =
Google , title =. 2025 , note =
2025
-
[51]
Solving Geometry Problems: Combining Text and Diagram Interpretation
Seo, Minjoon and Hajishirzi, Hannaneh and Farhadi, Ali and Etzioni, Oren and Malcolm, Clint. Solving Geometry Problems: Combining Text and Diagram Interpretation. Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. doi:10.18653/v1/D15-1171
-
[52]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Scaling Inference Time Compute for Diffusion Models , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[53]
, author=
Developing Mathematical Problem-Solving Skills in Primary School by Using Visual Representations on Heuristics. , author=. LUMAT: International Journal on Math, Science and Technology Education , volume=. 2022 , publisher=
2022
-
[54]
International journal of Stem education , volume=
The role of visual representations in scientific practices: from conceptual understanding and knowledge generation to ‘seeing’how science works , author=. International journal of Stem education , volume=. 2015 , publisher=
2015
-
[55]
Educational studies in mathematics , volume=
The role of visual representations in the learning of mathematics , author=. Educational studies in mathematics , volume=. 2003 , publisher=
2003
-
[56]
Applied Cognitive Psychology , volume=
Who benefits from diagrams and illustrations in math problems? Ability and attitudes matter , author=. Applied Cognitive Psychology , volume=. 2018 , publisher=
2018
-
[57]
Richard E. Mayer , abstract =. Multimedia learning , series =. 2002 , issn =. doi:https://doi.org/10.1016/S0079-7421(02)80005-6 , url =
-
[58]
2025 , publisher=
Eyes on math: A visual approach to teaching math concepts , author=. 2025 , publisher=
2025
-
[59]
, author=
It's Not a Math Lesson--We're Learning to Draw! Teachers' Use of Visual Representations in Instructing Word Problem Solving in Sixth Grade of Elementary School. , author=. Frontline Learning Research , volume=. 2016 , publisher=
2016
-
[60]
Proceedings of the British Society for research into Learning Mathematics , volume=
Diagrams in the teaching and learning of geometry: some results and ideas for future research , author=. Proceedings of the British Society for research into Learning Mathematics , volume=
-
[61]
Strohmaier and Stanislaw Schukajlow , keywords =
Johanna Schoenherr and Anselm R. Strohmaier and Stanislaw Schukajlow , keywords =. Learning with visualizations helps: A meta-analysis of visualization interventions in mathematics education , journal =. 2024 , issn =. doi:https://doi.org/10.1016/j.edurev.2024.100639 , url =
-
[62]
Wang, Junling and Macina, Jakub and Daheim, Nico and Pal Chowdhury, Sankalan and Sachan, Mrinmaya. B ook2 D ial: Generating Teacher Student Interactions from Textbooks for Cost-Effective Development of Educational Chatbots. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.578
-
[63]
Soviet physics-doklady , volume=
Binary coors capable or ‘correcting deletions, insertions, and reversals , author=. Soviet physics-doklady , volume=
-
[64]
and Kolter, J
Aithal, Sumukh K and Maini, Pratyush and Lipton, Zachary C. and Kolter, J. Zico , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[65]
Wang, Junling and Rutkiewicz, Anna and Wang, April and Sachan, Mrinmaya. Generating Pedagogically Meaningful Visuals for Math Word Problems: A New Benchmark and Analysis of Text-to-Image Models. Findings of the Association for Computational Linguistics: ACL 2025. 2025. doi:10.18653/v1/2025.findings-acl.586
-
[66]
The NCTE Transcripts: A Dataset of Elementary Math Classroom Transcripts
Demszky, Dorottya and Hill, Heather. The NCTE Transcripts: A Dataset of Elementary Math Classroom Transcripts. Proceedings of the 18th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2023). 2023. doi:10.18653/v1/2023.bea-1.44
-
[67]
Pal Chowdhury, Sankalan and Zhang, Terry Jingchen and Rooein, Donya and Hovy, Dirk and K. Educators' Perceptions of Large Language Models as Tutors: Comparing Human and AI Tutors in a Blind Text-only Setting. Proceedings of the 20th Workshop on Innovative Use of NLP for Building Educational Applications (BEA 2025). 2025. doi:10.18653/v1/2025.bea-1.28
-
[68]
arXiv preprint arXiv:2505.04736 , year=
The Promise and Limits of LLMs in Constructing Proofs and Hints for Logic Problems in Intelligent Tutoring Systems , author=. arXiv preprint arXiv:2505.04736 , year=
-
[69]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[70]
Publications Manual , year = "1983", publisher =
1983
-
[71]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[72]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[73]
Dan Gusfield , title =. 1997
1997
-
[74]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[75]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.