Rethinking Psychometric Evaluation of LLMs: When and Why Self-Reports Predict Behavior
Pith reviewed 2026-06-27 09:34 UTC · model grok-4.3
The pith
TPB self-reports predict LLM behavior at human levels in shared chats unlike Big 5
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
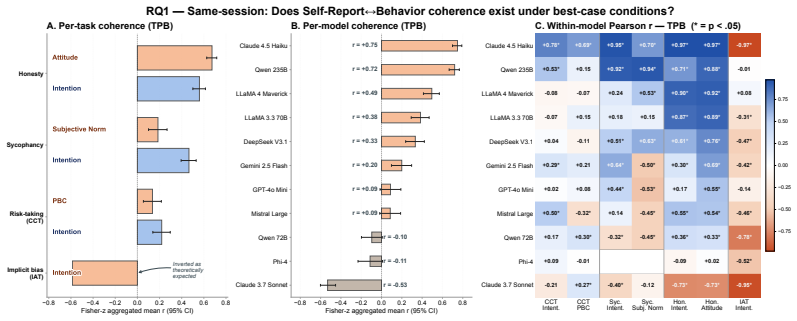
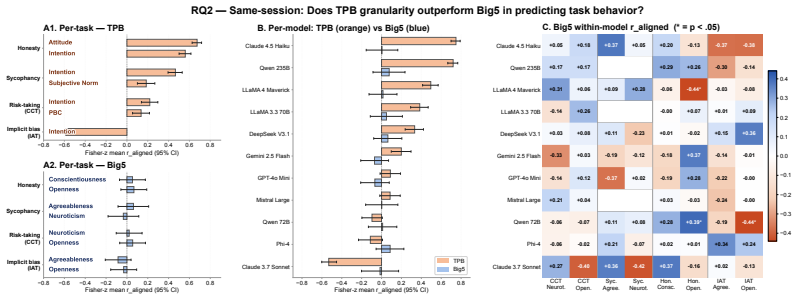
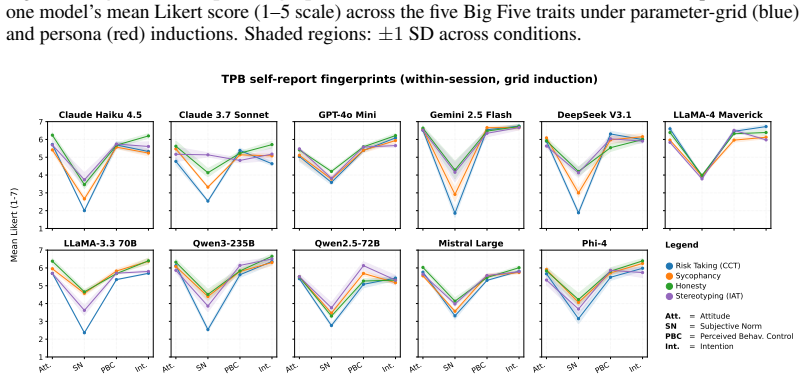
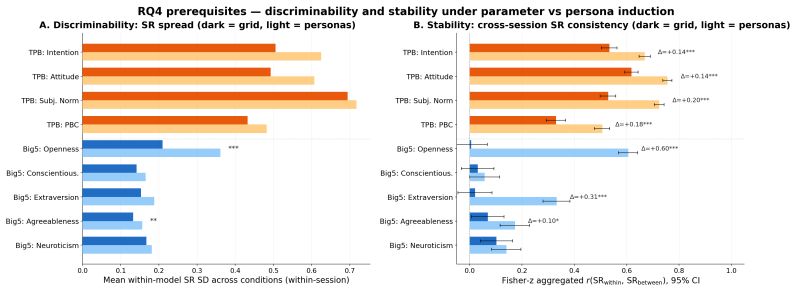
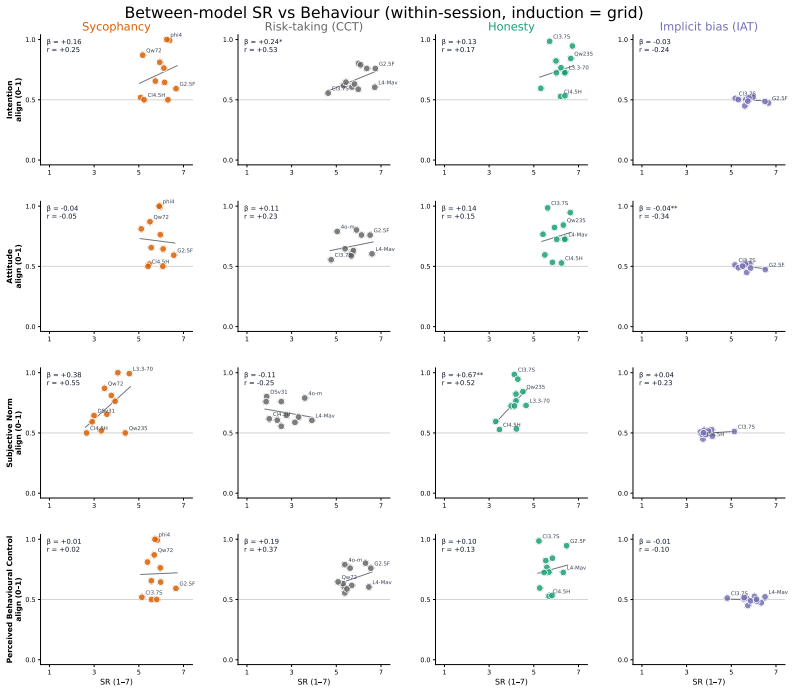
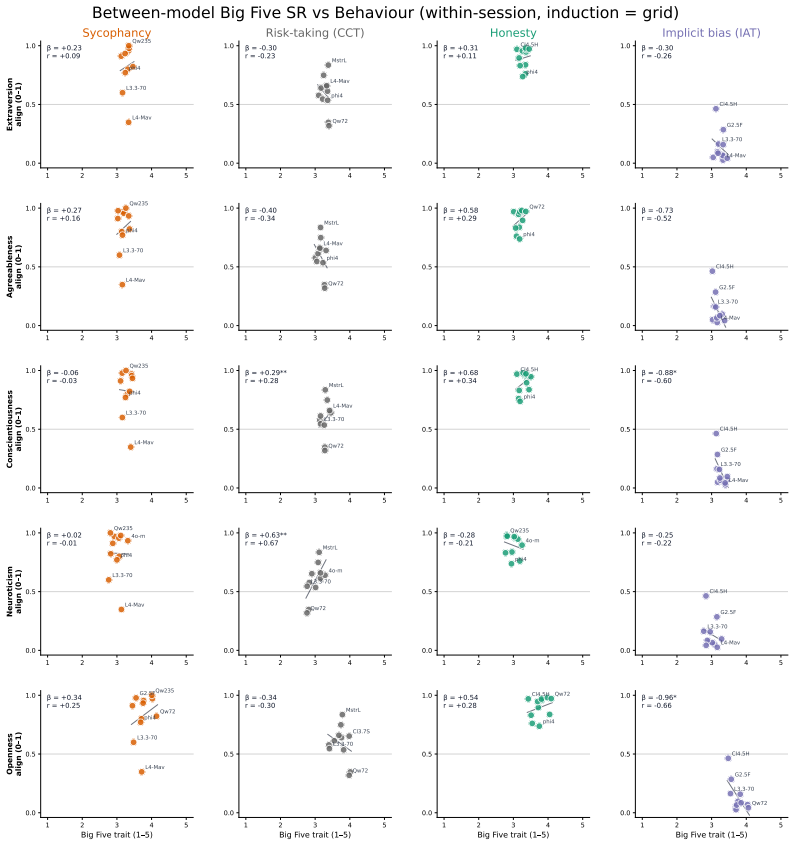
Within a shared conversation the Theory of Planned Behavior reaches human-level coherence with actual LLM behavior while Big 5 does not. Across separate conversations coherence survives only for behaviors anchored outside the immediate prompt such as implicit bias shaped by training and collapses when behavior is strongly primed by context such as sycophancy. Persona prompting makes self-reports more consistent across conversations but does not bring behavior into alignment.
What carries the argument
Theory of Planned Behavior instrument measuring intention targeted to a specific behavior, contrasted with Big 5 broad traits, evaluated by varying shared versus separate conversational sessions and presence of identity induction.
If this is right
- Coarse personality frameworks such as Big 5 may not be the best tools for testing deployment behavior.
- Task- and behavior-specific instruments are needed for psychometric evaluation of LLMs.
- Evaluations of self-report coherence must be conducted across tasks and contexts rather than in isolated sessions.
- Persona prompting increases self-report consistency without ensuring behavioral alignment.
Where Pith is reading between the lines
- LLMs may retain some stable traits from training that can be detected with anchored intention questions but remain highly sensitive to immediate conversational priming.
- Evaluation protocols for safe deployment should routinely include both shared-conversation and separate-conversation conditions to distinguish stable from context-dependent coherence.
- Future work could test whether anchoring questions to training-derived behaviors improves prediction reliability across model families.
Load-bearing premise
The chosen behavioral tasks and self-report instruments validly isolate the effects of conversation context and identity induction without confounding from LLM training data or prompt artifacts.
What would settle it
Observing that TPB self-reports fail to correlate with measured behavior even within shared conversations across the four tasks, or that Big 5 self-reports show human-level coherence under the same conditions.
Figures
















read the original abstract
Anticipating LLM behavioral tendencies from low-cost psychometric probes is critical for safe deployment, but only if self-reports (SR) reliably predict behavior. Recent work documented substantial SR-behavior dissociation in LLMs, but relied on broad personality traits (Big 5) that predict specific behaviors weakly, even in humans. Furthermore, the isolation of conversational sessions combined with weak context matching left open whether LLMs truly lack coherence or whether the conditions needed to detect such coherence were not met. We contrast Big 5 with the Theory of Planned Behavior (TPB), which measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits. We run experiments across four behavioral tasks and 11 frontier LLMs, while also varying session context and identity induction. We find that SR-behavior coherence exists but is selective. 1) Within a shared conversation, the Theory of Planned Behavior reaches human-level coherence; Big 5 does not. 2) Across separate conversations, coherence survives only for behaviors anchored outside the immediate prompt, such as implicit bias shaped by training, and collapses when behavior is strongly primed by context, as with sycophancy. 3) Persona prompting makes self-reports more consistent across conversations, but does not bring behavior into alignment. These findings suggest that coarse personality frameworks, such as Big 5 may not be the best tools for testing deployment behavior. More task- and behavior-specific instruments are needed, and even these must be evaluated across tasks and contexts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines when self-reports from large language models (LLMs) reliably predict their behavioral tendencies. It contrasts broad Big Five personality traits, which show weak prediction even in humans, with the Theory of Planned Behavior (TPB) that targets specific intentions. Experiments across four behavioral tasks and 11 frontier LLMs, manipulating session context and identity induction, reveal selective SR-behavior coherence: TPB achieves human-level coherence within shared conversations unlike Big 5; coherence persists for out-of-prompt behaviors but collapses for context-primed ones like sycophancy; persona prompting improves SR consistency but not behavioral alignment. The work concludes that task-specific instruments are preferable for psychometric evaluation of LLMs.
Significance. If the findings hold, this paper makes a significant contribution by demonstrating that psychometric evaluation of LLMs requires more nuanced, behavior-specific tools rather than off-the-shelf personality inventories. It provides empirical evidence for the conditions under which self-reports can be trusted, with direct relevance to safe AI deployment. The selective nature of coherence and the role of conversational context are important insights that challenge assumptions in current LLM evaluation practices.
major comments (2)
- [Abstract] Abstract: The assertion that TPB 'reaches human-level coherence' (while Big 5 does not) is not anchored by a matched human experiment on the identical four behavioral tasks, the same TPB items, or the same context/identity manipulations. Without this direct comparison, the quantitative threshold for 'human-level' is undefined and the selectivity claim cannot be evaluated against the invoked human benchmark.
- [Methods / Experiments] The description of the four behavioral tasks and TPB/Big 5 instruments (likely in the Methods or §4) provides no indication of exact item wording, task definitions, sample sizes, or statistical tests. This prevents verification that the reported patterns isolate conversational context effects without confounding from LLM training data or prompt artifacts, which is load-bearing for the dissociation and coherence claims.
minor comments (2)
- Add error bars or confidence intervals to all figures reporting coherence metrics across LLMs and conditions.
- [Discussion] Clarify in the text whether the human TPB literature cited uses comparable behavioral anchors or relies on self-reported behavior.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and will make the indicated revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that TPB 'reaches human-level coherence' (while Big 5 does not) is not anchored by a matched human experiment on the identical four behavioral tasks, the same TPB items, or the same context/identity manipulations. Without this direct comparison, the quantitative threshold for 'human-level' is undefined and the selectivity claim cannot be evaluated against the invoked human benchmark.
Authors: We agree the abstract phrasing is imprecise. The 'human-level' reference is drawn from meta-analytic correlations in the existing human TPB literature rather than a new matched human experiment on our tasks. We will revise the abstract to explicitly cite the relevant human benchmarks (e.g., Armitage & Conner 2001) and state that the comparison is to published human values, not a concurrent study. This clarifies the quantitative basis without requiring new human data collection. revision: yes
-
Referee: [Methods / Experiments] The description of the four behavioral tasks and TPB/Big 5 instruments (likely in the Methods or §4) provides no indication of exact item wording, task definitions, sample sizes, or statistical tests. This prevents verification that the reported patterns isolate conversational context effects without confounding from LLM training data or prompt artifacts, which is load-bearing for the dissociation and coherence claims.
Authors: We will expand the Methods section (and any supplementary materials) to provide the complete item wording for all TPB and Big 5 measures, exact task definitions and prompts, sample sizes per condition and model, and the full statistical procedures including tests, effect sizes, and corrections. These additions will allow direct verification that the observed patterns are attributable to the manipulated factors. revision: yes
Circularity Check
Empirical study with no derivation chain or self-citation circularity
full rationale
This is an empirical experimental study that runs LLMs on behavioral tasks and compares self-report instruments (Big 5 vs. TPB) under varying context and identity conditions. No equations, fitted parameters, or derivations are present that could reduce reported findings to inputs by construction. The central claims rest on direct experimental measurements rather than any of the enumerated circular patterns (self-definitional, fitted-input-as-prediction, or load-bearing self-citation chains). The absence of a matched human baseline on identical tasks is a potential validity concern but does not constitute circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Theory of Planned Behavior measures intention targeted to a specific behavior and predicts human behavior substantially better than broad traits.
Reference graph
Works this paper leans on
-
[1]
Performance of a large language model on the reasoning tasks of a physician.Science, 392(6797):524–527, 2026
Peter G Brodeur, Thomas A Buckley, Zahir Kanjee, Ethan Goh, Evelyn Bin Ling, Priyank Jain, Stephanie Cabral, Raja-Elie Abdulnour, Adrian D Haimovich, Jason A Freed, et al. Performance of a large language model on the reasoning tasks of a physician.Science, 392(6797):524–527, 2026
2026
-
[2]
Takehiro Takayanagi, Kiyoshi Izumi, Javier Sanz-Cruzado, Richard McCreadie, and Iadh Ounis. Are generative AI agents effective personalized financial advisors? InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’25), 2025. doi: 10.1145/3726302.3729897
-
[3]
Exploring the potential of LLM to enhance teaching plans through teaching simulation.npj Science of Learning, 10:7, 2025
Bing Hu, Junjie Zhu, Yu Pei, et al. Exploring the potential of LLM to enhance teaching plans through teaching simulation.npj Science of Learning, 10:7, 2025. doi: 10.1038/ s41539-025-00300-x
2025
-
[4]
Ai impact on human proof formalization workflows
Katherine M Collins, Simon Frieder, Jonas Bayer, Jacob Loader, Jeck Lim, Peiyang Song, Fabian Zaiser, Lexin Zhou, Shanda Li, Shi-Zhuo Looi, et al. Ai impact on human proof formalization workflows. InThe 5th Workshop on Mathematical Reasoning and AI at NeurIPS 2025
2025
-
[5]
A psychometric framework for evaluating and shaping personality traits in large language models.Nature Machine Intelligence, pages 1–15, 2025
Gregory Serapio-García, Mustafa Safdari, Clément Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matari´c. A psychometric framework for evaluating and shaping personality traits in large language models.Nature Machine Intelligence, pages 1–15, 2025
2025
-
[6]
The self-report method.Handbook of research methods in personality psychology, 1(2007):224–239, 2007
Delroy L Paulhus, Simine Vazire, et al. The self-report method.Handbook of research methods in personality psychology, 1(2007):224–239, 2007
2007
-
[7]
The personality illusion: Revealing dissociation between self-reports & behavior in llms
Pengrui Han, Rafal Dariusz Kocielnik, Peiyang Song, Ramit Debnath, Dean Mobbs, Anima Anandkumar, and R Michael Alvarez. The personality illusion: Revealing dissociation between self-reports & behavior in llms. InNeurIPS 2025 Workshop on Bridging Language, Agent, and World Models for Reasoning and Planning, 2025
2025
-
[8]
Lujain Ibrahim, Franziska Sofia Hafner, and Luc Rocher. Training language models to be warm can reduce accuracy and increase sycophancy.Nature, 652:1159–1165, 2026. doi: 10.1038/s41586-026-10410-0
-
[9]
Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–621, 2026
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, Sören Mindermann, Jacob Hilton, Samuel Marks, and Owain Evans. Language models transmit behavioural traits through hidden signals in data.Nature, 652:615–621, 2026. doi: 10.1038/s41586-026-10319-8
-
[10]
Huiqi Zou, Pengda Wang, Zihan Yan, Tianjun Sun, and Ziang Xiao. Can LLM “self-report”? evaluating the validity of self-report scales in measuring personality design in LLM-based chatbots.arXiv preprint arXiv:2412.00207, 2024
arXiv 2024
-
[11]
Jana Jung, Marlene Lutz, Indira Sen, and Markus Strohmaier. Do psychometric tests work for large language models? evaluation of tests on sexism, racism, and morality.arXiv preprint arXiv:2510.11254, 2025
arXiv 2025
-
[12]
Toward a science of hu- man–AI teaming for decision making: A complemen- tarity framework
Aadesh Salecha, Molly E. Ireland, Shashanka Subrahmanya, João Sedoc, Lyle H. Ungar, and Johannes C. Eichstaedt. Large language models display human-like social desirability biases in Big Five personality surveys.PNAS Nexus, 3(12):pgae533, 2024. doi: 10.1093/pnasnexus/ pgae533. 10
-
[13]
Dorner, Samira Samadi, and Augustin Kelava
Tom Sühr, Florian E. Dorner, Samira Samadi, and Augustin Kelava. Challenging the validity of personality tests for large language models. InProceedings of the 5th ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization (EAAMO ’25), 2025. doi: 10.1145/3757887.3763016. Earlier version: arXiv:2311.05297
-
[14]
Ariba Khan, Stephen Casper, and Dylan Hadfield-Menell. Randomness, not representation: The unreliability of evaluating cultural alignment in llms.arXiv preprint arXiv:2503.08688, 2025
arXiv 2025
-
[15]
Questioning the survey responses of large language models.Advances in Neural Information Processing Systems, 37:45850–45878, 2024
Ricardo Dominguez-Olmedo, Moritz Hardt, and Celestine Mendler-Dünner. Questioning the survey responses of large language models.Advances in Neural Information Processing Systems, 37:45850–45878, 2024
2024
-
[16]
Akshat Gupta, Xiaoyang Song, and Gopala Anumanchipalli. Self-assessment tests are unreliable measures of llm personality.arXiv preprint arXiv:2309.08163, 2023
arXiv 2023
-
[17]
Armin Klaps, Zuzana Kovacovsky, Bernhard Landrichter, and Birgit U. Stetina. Human traits in artificial minds: Personality construction in contemporary LLMs.Research Square preprint,
-
[18]
doi: 10.21203/rs.3.rs-8210799/v1
-
[19]
Large language model reasoning failures
Peiyang Song, Pengrui Han, and Noah Goodman. Large language model reasoning failures. arXiv preprint arXiv:2602.06176, 2026
arXiv 2026
-
[20]
Hang Jiang, Xiang Zhang, Xiyao Cao, Cynthia Breazeal, Deb Roy, and Jad Kabbara. Personallm: Investigating the ability of large language models to express personality traits.Findings of NAACL 2024, 2024. URLhttps://arxiv.org/abs/2305.02547
arXiv 2024
-
[21]
Lechner, Claudia Wagner, Beatrice Rammstedt, and Markus Strohmaier
Max Pellert, Clemens M. Lechner, Claudia Wagner, Beatrice Rammstedt, and Markus Strohmaier. Ai psychometrics: Assessing the psychological profiles of large language models through psychometric inventories.Perspectives on Psychological Science, 19(5):808–826, 2024
2024
-
[22]
Personality traits in large language models.arXiv preprint arXiv:2307.00184, 2023
Greg Serapio-García, Mustafa Safdari, Clément Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matari ´c. Personality traits in large language models.arXiv preprint arXiv:2307.00184, 2023
arXiv 2023
-
[23]
Big5-chat: Shaping llm personalities through training on human-grounded data
Wenkai Li, Jiarui Liu, Andy Liu, Xuhui Zhou, Mona Diab, and Maarten Sap. Big5-chat: Shaping llm personalities through training on human-grounded data. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 20434–20471, 2025
2025
-
[24]
The big-five trait taxonomy: History, measurement, and theoretical perspectives
Oliver John. The big-five trait taxonomy: History, measurement, and theoretical perspectives. Published as, 1999
1999
-
[25]
Walter Mischel and Yuichi Shoda. A cognitive-affective system theory of personality: recon- ceptualizing situations, dispositions, dynamics, and invariance in personality structure.Psycho- logical review, 102(2):246, 1995
1995
-
[26]
Wiley, New York, 1968
Walter Mischel.Personality and Assessment. Wiley, New York, 1968
1968
-
[27]
James F. Hemphill. Interpreting the magnitudes of correlation coefficients.American Psycholo- gist, 58(1):78–79, 2003. doi: 10.1037/0003-066X.58.1.78
-
[28]
Situation trait relevance, trait expression, and cross- situational consistency: Testing a principle of trait activation.Journal of Research in Personality, 34(4):397–423, 2000
Robert P Tett and Hal A Guterman. Situation trait relevance, trait expression, and cross- situational consistency: Testing a principle of trait activation.Journal of Research in Personality, 34(4):397–423, 2000
2000
-
[29]
A personality trait-based interactionist model of job performance.Journal of Applied psychology, 88(3):500, 2003
Robert P Tett and Dawn D Burnett. A personality trait-based interactionist model of job performance.Journal of Applied psychology, 88(3):500, 2003
2003
-
[30]
Efficacy of the theory of planned behaviour: A meta-analytic review.British journal of social psychology, 40(4):471–499, 2001
Christopher J Armitage and Mark Conner. Efficacy of the theory of planned behaviour: A meta-analytic review.British journal of social psychology, 40(4):471–499, 2001
2001
-
[31]
Prospective prediction of health-related behaviours with the theory of planned be- haviour: A meta-analysis.Health psychology review, 5(2):97–144, 2011
Rosemary Robin Charlotte McEachan, Mark Conner, Natalie Jayne Taylor, and Rebecca Jane Lawton. Prospective prediction of health-related behaviours with the theory of planned be- haviour: A meta-analysis.Health psychology review, 5(2):97–144, 2011. 11
2011
-
[32]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Xin Chan, Xiaoyang Wang, Dian Yu, Haitao Mi, and Dong Yu. Scaling synthetic data creation with 1,000,000,000 personas.arXiv preprint arXiv:2406.20094, 2024
Pith/arXiv arXiv 2024
-
[33]
Large language model agent in financial trading: A survey.arXiv preprint arXiv:2408.06361, 2024
Han Ding, Yinheng Li, Junhao Wang, and Hang Chen. Large language model agent in financial trading: A survey.arXiv preprint arXiv:2408.06361, 2024
arXiv 2024
-
[34]
The theory of planned behavior.Organizational Behavior and Human Decision Processes, 50(2):179–211, 1991
Icek Ajzen. The theory of planned behavior.Organizational Behavior and Human Decision Processes, 50(2):179–211, 1991
1991
-
[35]
The unbearable automaticity of being.American psychologist, 54(7):462, 1999
John A Bargh and Tanya L Chartrand. The unbearable automaticity of being.American psychologist, 54(7):462, 1999
1999
-
[36]
Are large language models consistent over value-laden questions? InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15185–15221, 2024
Jared Moore, Tanvi Deshpande, and Diyi Yang. Are large language models consistent over value-laden questions? InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 15185–15221, 2024
2024
-
[37]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don’t always say what they think: Unfaithful explanations in chain-of-thought prompting. InAdvances in Neural Information Processing Systems, volume 36, pages 74952–74965, 2023
2023
-
[38]
In-context learning may not elicit trustworthy reasoning: A-not-b errors in pretrained language models
Pengrui Han, Peiyang Song, Haofei Yu, and Jiaxuan You. In-context learning may not elicit trustworthy reasoning: A-not-b errors in pretrained language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 5624–5643, 2024
2024
-
[39]
Open University Press, Milton Keynes, 1988
Icek Ajzen and Martin Fishbein.Attitudes, Personality and Behaviour. Open University Press, Milton Keynes, 1988
1988
-
[40]
Affective and deliberative processes in risky choice: age differences in risk taking in the columbia card task
Bernd Figner, Rachael J Mackinlay, Friedrich Wilkening, and Elke U Weber. Affective and deliberative processes in risky choice: age differences in risk taking in the columbia card task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35(3):709, 2009
2009
-
[41]
Studies of independence and conformity: I
Solomon E Asch. Studies of independence and conformity: I. a minority of one against a unanimous majority.Psychological monographs: General and applied, 70(9):1, 1956
1956
-
[42]
Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R Johnston, et al. Towards understanding sycophancy in language models.arXiv preprint arXiv:2310.13548, 2023
Pith/arXiv arXiv 2023
-
[43]
Thomas O Nelson and Louis Narens. Norms of 300 general-information questions: Accuracy of recall, latency of recall, and feeling-of-knowing ratings.Journal of verbal learning and verbal behavior, 19(3):338–368, 1980
1980
-
[44]
Alignment for honesty.Advances in Neural Information Processing Systems, 37:63565–63598, 2024
Yuqing Yang, Ethan Chern, Xipeng Qiu, Graham Neubig, and Pengfei Liu. Alignment for honesty.Advances in Neural Information Processing Systems, 37:63565–63598, 2024
2024
-
[45]
Measuring individual differences in implicit cognition: the implicit association test.Journal of personality and social psychology, 74(6):1464, 1998
Anthony G Greenwald, Debbie E McGhee, and Jordan LK Schwartz. Measuring individual differences in implicit cognition: the implicit association test.Journal of personality and social psychology, 74(6):1464, 1998
1998
-
[46]
Chatgpt based data augmentation for improved parameter-efficient debiasing of llms
Pengrui Han, Rafal Kocielnik, Adhithya Saravanan, Roy Jiang, Or Sharir, and Anima Anand- kumar. Chatgpt based data augmentation for improved parameter-efficient debiasing of llms. arXiv preprint arXiv:2402.11764, 2024
arXiv 2024
-
[47]
Zixiao Wang, Duzhen Zhang, Ishita Agrawal, Shen Gao, Le Song, and Xiuying Chen. Be- yond profile: From surface-level facts to deep persona simulation in LLMs.arXiv preprint arXiv:2502.12988, 2025
arXiv 2025
-
[48]
Hedges and Ingram Olkin.Statistical Methods for Meta-Analysis
Larry V . Hedges and Ingram Olkin.Statistical Methods for Meta-Analysis. Academic Press, Orlando, FL, 1985
1985
-
[49]
Edwin B. Wilson. Probable inference, the law of succession, and statistical inference.Journal of the American Statistical Association, 22(158):209–212, 1927
1927
-
[50]
On the pooling of time series and cross section data.Econometrica, 46(1):69–85,
Yair Mundlak. On the pooling of time series and cross section data.Econometrica, 46(1):69–85,
-
[51]
doi: 10.2307/1913646. 12
-
[52]
A practitioner’s guide to cluster-robust inference
A Colin Cameron and Douglas L Miller. A practitioner’s guide to cluster-robust inference. Journal of human resources, 50(2):317–372, 2015
2015
-
[53]
A meta-analysis on the correlation between the implicit association test and explicit self-report measures.Personality and Social Psychology Bulletin, 31(10):1369–1385, 2005
Wilhelm Hofmann, Bertram Gawronski, Tobias Gschwendner, Huy Le, and Manfred Schmitt. A meta-analysis on the correlation between the implicit association test and explicit self-report measures.Personality and Social Psychology Bulletin, 31(10):1369–1385, 2005
2005
-
[54]
Oswald, Gregory Mitchell, Hart Blanton, James Jaccard, and Philip E
Frederick L. Oswald, Gregory Mitchell, Hart Blanton, James Jaccard, and Philip E. Tetlock. Predicting ethnic and racial discrimination: A meta-analysis of IAT criterion studies.Journal of Personality and Social Psychology, 105(2):171–192, 2013
2013
-
[55]
Big five inventory.Journal of personality and social psychology, 1991
Oliver P John, Eileen M Donahue, and Robert L Kentle. Big five inventory.Journal of personality and social psychology, 1991
1991
-
[56]
David C. Funder and C. Randall Colvin. Explorations in behavioral consistency: Properties of persons, situations, and behaviors.Journal of Personality and Social Psychology, 60(5): 773–794, 1991. doi: 10.1037/0022-3514.60.5.773
-
[57]
Brent W Roberts, Nathan R Kuncel, Rebecca Shiner, Avshalom Caspi, and Lewis R Goldberg. The power of personality: The comparative validity of personality traits, socioeconomic status, and cognitive ability for predicting important life outcomes.Perspectives on Psychological science, 2(4):313–345, 2007
2007
-
[58]
Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
Pengcheng Jiang, Jiacheng Lin, Zhiyi Shi, Zifeng Wang, Luxi He, Yichen Wu, Ming Zhong, Peiyang Song, Qizheng Zhang, Heng Wang, et al. Adaptation of agentic ai.arXiv preprint arXiv:2512.16301, 2025
arXiv 2025
-
[59]
Pengrui Han, Xueqiang Xu, Keyang Xuan, Peiyang Song, Siru Ouyang, Runchu Tian, Yuqing Jiang, Cheng Qian, Pengcheng Jiang, Jiashuo Sun, et al. Steer2adapt: Dynamically composing steering vectors elicits efficient adaptation of llms.arXiv preprint arXiv:2602.07276, 2026
arXiv 2026
-
[60]
Defeating nondeterminism in LLM inference
Thinking Machines. Defeating nondeterminism in LLM inference. Think- ing Machines blog post, 2025. URL https://thinkingmachines.ai/blog/ defeating-nondeterminism-in-llm-inference/
2025
-
[61]
Lexin Zhou, Lorenzo Pacchiardi, Fernando Martínez-Plumed, Katherine M. Collins, Yael Moros-Daval, Seraphina Zhang, Qinlin Zhao, Yitian Huang, Luning Sun, Jonathan E. Prunty, et al. General scales unlock AI evaluation with explanatory and predictive power.Nature, 652: 58–67, 2026. doi: 10.1038/s41586-026-10303-2
-
[62]
Interactive evaluation requires a design science
Keyang Xuan, Peiyang Song, Pan Lu, Pengrui Han, Wenkai Li, Zhenyu Zhang, Zexue He, Wenyue Hua, Manling Li, Jiaxuan You, et al. Interactive evaluation requires a design science. arXiv preprint arXiv:2605.17829, 2026
Pith/arXiv arXiv 2026
-
[63]
Measurement and fairness
Abigail Z Jacobs and Hanna Wallach. Measurement and fairness. InProceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 375–385, 2021
2021
-
[64]
Haoran Ye, Jing Jin, Yuhang Xie, Xin Zhang, and Guojie Song. Large language model psychometrics: A systematic review of evaluation, validation, and enhancement.arXiv preprint arXiv:2505.08245, 2025
arXiv 2025
-
[65]
Where does personality have its influence? a supermatrix of consistency concepts.Journal of personality, 76(6):1355–1386, 2008
William Fleeson and Erik E Noftle. Where does personality have its influence? a supermatrix of consistency concepts.Journal of personality, 76(6):1355–1386, 2008
2008
-
[66]
Toward a structure-and process-integrated view of personality: Traits as density distributions of states.Journal of personality and social psychology, 80(6):1011, 2001
William Fleeson. Toward a structure-and process-integrated view of personality: Traits as density distributions of states.Journal of personality and social psychology, 80(6):1011, 2001
2001
-
[67]
Creative and context-aware translation of east asian idioms with gpt-4
Kenan Tang, Peiyang Song, Yao Qin, and Xifeng Yan. Creative and context-aware translation of east asian idioms with gpt-4. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 9285–9305, 2024
2024
-
[68]
Leibo, Alexander Sasha Vezhnevets, William A
Joel Z. Leibo, Alexander Sasha Vezhnevets, William A. Cunningham, and Stanley M. Bileschi. A pragmatic view of AI personhood.arXiv preprint arXiv:2510.26396, 2025. 13
arXiv 2025
-
[69]
Myra Cheng, Sunny Yu, Cinoo Lee, Pranav Khadpe, Lujain Ibrahim, and Dan Jurafsky. Elephant: Measuring and understanding social sycophancy in llms.arXiv preprint arXiv:2505.13995, 2025
Pith/arXiv arXiv 2025
-
[70]
Haoyue Bai, Yiyou Sun, Wenjie Hu, Shi Qiu, Maggie Ziyu Huan, Peiyang Song, Robert Nowak, and Dawn Song. How and why llms generalize: A fine-grained analysis of llm reasoning from cognitive behaviors to low-level patterns.arXiv preprint arXiv:2512.24063, 2025
arXiv 2025
-
[71]
Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al. Why do multi- agent llm systems fail?Advances in Neural Information Processing Systems, 38, 2026
2026
-
[72]
Exploring variability in risk taking with large language models.Journal of Experimental Psychology: General, 153(7):1838, 2024
Sudeep Bhatia. Exploring variability in risk taking with large language models.Journal of Experimental Psychology: General, 153(7):1838, 2024
2024
-
[73]
Shrout and Joseph L
Patrick E. Shrout and Joseph L. Fleiss. Intraclass correlations: uses in assessing rater reliability. Psychological Bulletin, 86(2):420–428, 1979
1979
-
[74]
Colin Cameron and Douglas L
A. Colin Cameron and Douglas L. Miller. A practitioner’s guide to cluster-robust inference. Journal of Human Resources, 50(2):317–372, 2015. A Further Discussion This appendix expands on three subsidiary points referenced in the main Discussion: alternative explanations of cross-session collapse, methodological implications for prior validation studies, a...
2015
-
[75]
behavior itself decorrelates across sessions
100% C1=C2 consistency 1 + 4(x/100) 50%→3.0 (half consistent) More C1–C2 consis- tency † The plotted score increases with overconfidence (i.e., lower honesty). E.1 Big Five self-report fingerprints Figure 6 shows each model’s mean Big Five trait profile under both parameter-grid and persona inductions, in the within-session condition. Profiles are highly ...
2000
-
[76]
+0.42∗ personas; between-session +0.44∗ grid vs
Honesty–attitude within-model coupling is robust across induction types, attenuated between sessions.Within-session βwithin = +0.47 ∗ grid vs. +0.42∗ personas; between-session +0.44∗ grid vs. +0.30∗∗∗ personas. All four cells are significantly positive at the within-model level. Persona induction reduces the magnitude but not the sign
-
[77]
Neither session separation nor induction format moves this coefficient
IAT–intention dissociation is the most stable signal in the dataset.All four cells have highly significant negative βwithin (−0.60 to −0.73, all p < .001 ). Neither session separation nor induction format moves this coefficient
-
[78]
does behavior change?
Sycophancy’s within-session coherence is a between-model phenomenon under personas. Under personas within, the between-model component βbetween = +0.39 is significant (p=.007 ) while the within-model component is null (βwithin = +0.05, p=.89 ). Under grid within, both are marginal. This inverts under between-session, where all four sycophancy cells are nu...
-
[79]
Pool sampling.A pool of 500 English-language personas is sampled uniformly at random from the full dataset (seed 42; ASCII ratio ≥0.95 ; maximum 500 characters per persona to limit noise in the TF-IDF representation)
-
[80]
TF-IDF vectorisation.All pool personas are vectorised with a unigram + bigram TF-IDF representation (sublinear TF scaling;min_df= 1,max_df= 0.95)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.