Valid Inference with Synthetic Data via Task Exchangeability
Pith reviewed 2026-06-27 05:38 UTC · model grok-4.3
The pith
Task exchangeability enables valid statistical inference from synthetic data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When a current task is exchangeable with historical tasks that possess real data, valid inference procedures exist for synthetic data generated for the current task; these procedures extend to settings that depart from exact exchangeability while still supplying coverage guarantees.
What carries the argument
Task exchangeability, the requirement that the target task is exchangeable with historical tasks having real data, which transfers validity from the historical real-data inferences to the synthetic-data inferences on the target task.
If this is right
- Synthetic data from LLMs can be used for pilot studies in public-opinion research while preserving frequentist validity.
- Autorater outputs in AI evaluation can support valid inference when the evaluation tasks satisfy the exchangeability condition.
- Extensions of the methods continue to give coverage guarantees even when exchangeability holds only approximately.
- The same principle applies to other generative models that produce synthetic structures once suitable historical tasks are identified.
Where Pith is reading between the lines
- The framework could be applied to any domain that already maintains archives of past experiments with real measurements, not only surveys and AI benchmarks.
- In settings where multiple historical tasks exist, one could test which subset yields the strongest exchangeability match before applying the inference procedure.
- If exchangeability can be verified empirically on a subset of variables, the remaining variables might still be analyzed under the same validity guarantee.
Load-bearing premise
The researcher can identify historical tasks with real data such that the current task is exchangeable with those historical tasks.
What would settle it
A controlled simulation in which synthetic data are generated from a task known to violate exchangeability with the historical tasks, after which the proposed inference procedure is applied and its coverage rate is measured.
Figures
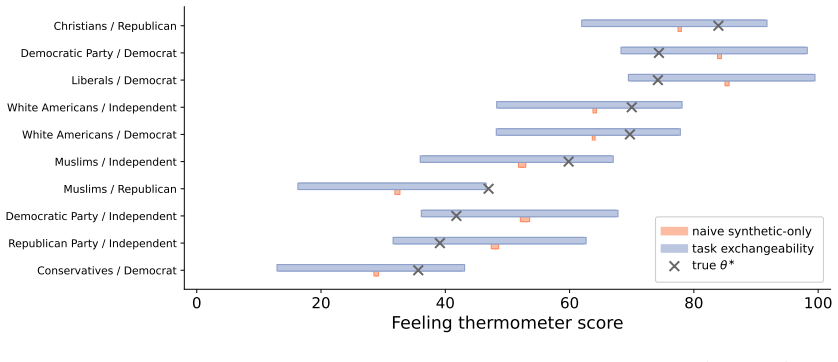
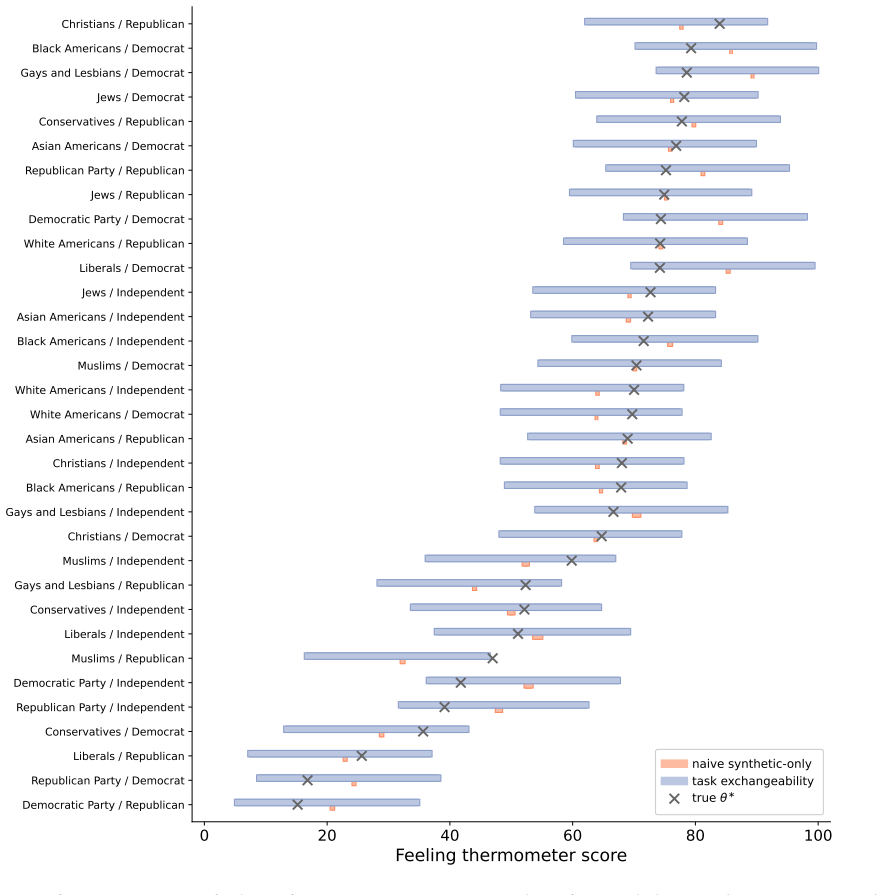
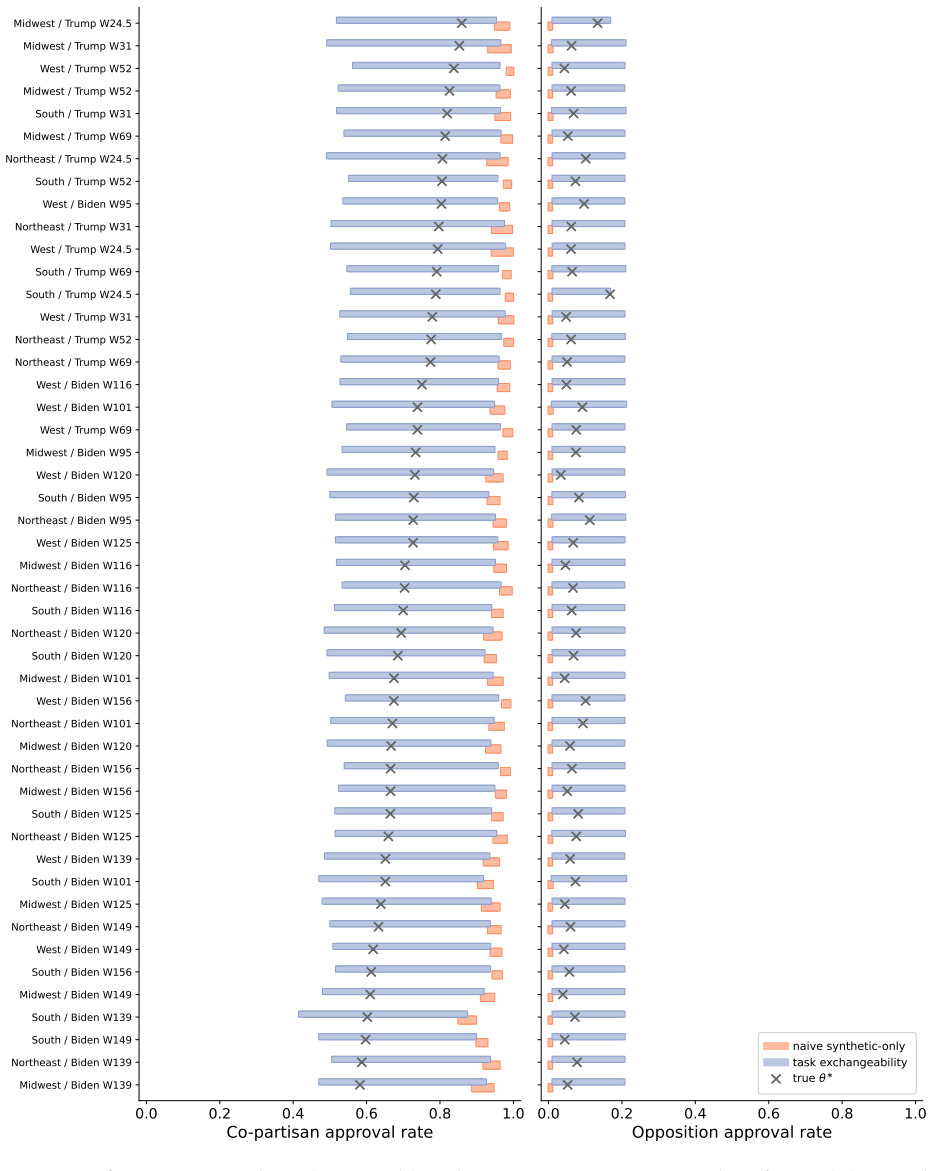
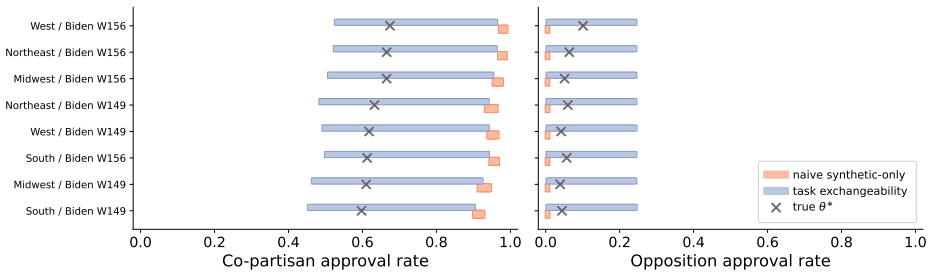

read the original abstract
There is a proliferation of work arguing for the use of synthetic data in scientific research. For example, social scientists are arguing for the use of LLM-generated "silicon samples" in pilot studies; AI evaluations increasingly rely on "LLM-as-a-judge" outputs; and proteomics research is accelerated by generative models that produce synthetic protein structures. These developments raise an intriguing possibility: synthetic data may help researchers ask more questions, run more studies, and accelerate discovery. But they also raise a fundamental concern: synthetic data can be biased, noisy, and misspecified. In this work, we propose statistical principles for using synthetic data in scientific research with provable validity guarantees. The key insight is a new technical condition that we call task exchangeability. Informally, this is a requirement that the researcher can identify historical tasks, for which real data is available, such that their current task of interest is exchangeable with the historical tasks in an appropriate mathematical sense. We develop methods for valid inference under task exchangeability, together with extensions that provide guarantees even beyond exchangeability. We demonstrate the framework on public opinion surveys with silicon samples and AI evaluation with autoraters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces task exchangeability as a condition under which synthetic data can be used for valid statistical inference: researchers identify historical tasks with real data such that the target task is exchangeable with them in an appropriate sense. It develops inference methods under this condition, plus extensions providing guarantees even when exchangeability fails, and demonstrates the approach on public opinion surveys using LLM silicon samples and AI evaluations using autoraters.
Significance. If the central construction holds, the framework supplies a principled statistical route for incorporating synthetic data into empirical work while retaining coverage guarantees, extending classical exchangeability ideas to a timely setting. The two empirical illustrations indicate potential applicability in survey research and automated evaluation, provided the exchangeability identification step can be made operational.
major comments (2)
- [§2–3] §2–3 (and abstract): All validity guarantees, including the extensions beyond exchangeability, are conditional on task exchangeability. The manuscript defines this condition but supplies no statistical test, bound, sensitivity analysis, or falsification procedure for verifying it; identification is left entirely to the researcher. This assumption is load-bearing for the central claim yet receives no diagnostic support.
- [§3] §3: The extensions that relax exact exchangeability are presented as providing guarantees, but the manuscript does not quantify the degree of violation that can be tolerated before coverage fails or supply simulation evidence isolating the effect of partial violations.
minor comments (1)
- The abstract and introduction would benefit from a concise statement of the precise inferential target (e.g., coverage of a confidence interval or p-value validity) under task exchangeability.
Simulated Author's Rebuttal
Thank you for the constructive referee report. We address each major comment below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [§2–3] §2–3 (and abstract): All validity guarantees, including the extensions beyond exchangeability, are conditional on task exchangeability. The manuscript defines this condition but supplies no statistical test, bound, sensitivity analysis, or falsification procedure for verifying it; identification is left entirely to the researcher. This assumption is load-bearing for the central claim yet receives no diagnostic support.
Authors: Task exchangeability is a substantive modeling assumption whose justification relies on domain knowledge to identify suitable historical tasks, analogous to exchangeability assumptions in classical statistics or ignorability conditions in causal inference. We do not supply a formal statistical test because the condition is not identifiable from data on the target task alone without additional structure or modeling choices. To address the concern, we will add a dedicated subsection outlining practical assessment strategies, including qualitative diagnostics and sensitivity checks based on observable task features. This constitutes a partial revision. revision: partial
-
Referee: [§3] §3: The extensions that relax exact exchangeability are presented as providing guarantees, but the manuscript does not quantify the degree of violation that can be tolerated before coverage fails or supply simulation evidence isolating the effect of partial violations.
Authors: Section 3 presents extensions that deliver coverage under specific relaxations of exact exchangeability (via discrepancy bounds). We agree that explicit quantification of tolerable violation magnitude and isolating simulation evidence would improve clarity. We will incorporate additional simulation studies in the revision that vary the degree of exchangeability violation and report resulting coverage behavior. This constitutes a partial revision. revision: partial
Circularity Check
No significant circularity; derivation conditional on externally stated assumption
full rationale
The paper defines task exchangeability as a new technical condition requiring identification of historical tasks with real data such that the target task is exchangeable with them, then develops inference procedures valid under that condition (plus extensions). No quoted step reduces a claimed prediction or guarantee to a fitted parameter, self-citation chain, or definitional renaming; the validity statements remain conditional on an assumption presented as researcher-identified rather than internally forced. Standard exchangeability ideas are invoked externally without load-bearing self-citation for the core result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Researchers can identify historical tasks with real data such that the current task is exchangeable with them in a mathematical sense.
Reference graph
Works this paper leans on
-
[1]
The transfer perfor- mance of economic models
Isaiah Andrews, Drew Fudenberg, Lihua Lei, Annie Liang, and Chaofeng Wu. The transfer perfor- mance of economic models. InProceedings of the 26th ACM Conference on Economics and Computation, pages 668–669, 2025
2025
-
[2]
Prediction-powered inference.Science, 382(6671):669–674, 2023
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. Prediction-powered inference.Science, 382(6671):669–674, 2023
2023
-
[3]
PPI++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023
Anastasios N Angelopoulos, John C Duchi, and Tijana Zrnic. PPI++: Efficient prediction-powered inference.arXiv preprint arXiv:2311.01453, 2023
Pith/arXiv arXiv 2023
-
[4]
Theoretical foundations of con- formal prediction.arXiv preprint arXiv:2411.11824, 2024
Anastasios N Angelopoulos, Rina Foygel Barber, and Stephen Bates. Theoretical foundations of con- formal prediction.arXiv preprint arXiv:2411.11824, 2024
Pith/arXiv arXiv 2024
-
[5]
Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337– 351, 2023
Lisa P Argyle, Ethan C Busby, Nancy Fulda, Joshua R Gubler, Christopher Rytting, and David Wingate. Out of one, many: Using language models to simulate human samples.Political Analysis, 31(3):337– 351, 2023
2023
-
[6]
Conformal predic- tion beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
Rina Foygel Barber, Emmanuel J Candes, Aaditya Ramdas, and Ryan J Tibshirani. Conformal predic- tion beyond exchangeability.The Annals of Statistics, 51(2):816–845, 2023
2023
-
[7]
Meshi Bashari, Yonghoon Lee, Roy Maor Lotan, Edgar Dobriban, and Yaniv Romano. Statistical in- ference leveraging synthetic data with distribution-free guarantees.arXiv preprint arXiv:2509.20345, 2025
Pith/arXiv arXiv 2025
-
[8]
Synthetic re- placements for human survey data? the perils of large language models.Political Analysis, 32(4): 401–416, 2024
James Bisbee, Joshua D Clinton, Cassy Dorff, Brenton Kenkel, and Jennifer M Larson. Synthetic re- placements for human survey data? the perils of large language models.Political Analysis, 32(4): 401–416, 2024
2024
-
[9]
Valid inference with imperfect synthetic data.Advances in Neural Information Processing Systems, 38:162430–162469, 2025
Yewon Byun, Shantanu Gupta, Zachary Lipton, Rachel Childers, and Bryan Wilder. Valid inference with imperfect synthetic data.Advances in Neural Information Processing Systems, 38:162430–162469, 2025
2025
-
[10]
Power analysis for prediction-powered inference.arXiv preprint arXiv:2603.16041, 2026
Yiqun T Chen, Moran Guo, and Shengy Li. Power analysis for prediction-powered inference.arXiv preprint arXiv:2603.16041, 2026
arXiv 2026
-
[11]
Gonzalez, and Ion Stoica
Wei-Lin Chiang, Lianmin Zheng, Ying Sheng, Anastasios Nikolas Angelopoulos, Tianle Li, Dacheng Li, Hao Zhang, Banghua Zhu, Michael Jordan, Joseph E. Gonzalez, and Ion Stoica. Chatbot arena: An open platform for evaluating LLMs by human preference. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine L...
-
[12]
Multiple-prediction-powered inference.arXiv preprint arXiv:2603.27414, 2026
Charlie Cowen-Breen, Alekh Agarwal, Stephen Bates, William W Cohen, Jacob Eisenstein, Amir Globerson, and Adam Fisch. Multiple-prediction-powered inference.arXiv preprint arXiv:2603.27414, 2026
arXiv 2026
-
[13]
The real deal behind the artificial appeal: inferential utility of tabular synthetic data
Alexander Decruyenaere, Heidelinde Dehaene, Paloma Rabaey, Christiaan Polet, Johan Decruyenaere, Stijn Vansteelandt, and Thomas Demeester. The real deal behind the artificial appeal: inferential utility of tabular synthetic data. InProceedings of the Fortieth Conference on Uncertainty in Artificial Intelligence, pages 966–996, 2024
2024
-
[14]
Nicolas Emmenegger, Ellery Stahler, and Chara Podimata. Prediction-powered inference across many tasks for ai evaluation & social science research.arXiv preprint arXiv:2605.29249, 2026
Pith/arXiv arXiv 2026
-
[15]
Conformal prediction under feedback covariate shift for biomolecular design.Proceedings of the National Academy of Sciences, 119(43):e2204569119, 2022
Clara Fannjiang, Stephen Bates, Anastasios N Angelopoulos, Jennifer Listgarten, and Michael I Jor- dan. Conformal prediction under feedback covariate shift for biomolecular design.Proceedings of the National Academy of Sciences, 119(43):e2204569119, 2022. 21
2022
-
[16]
Stratified prediction-powered inference for effective hybrid evaluation of language models.Advances in Neural Information Processing Systems, 37:111489–111514, 2024
Adam Fisch, Joshua Maynez, R Alex Hofer, Bhuwan Dhingra, Amir Globerson, and William W Cohen. Stratified prediction-powered inference for effective hybrid evaluation of language models.Advances in Neural Information Processing Systems, 37:111489–111514, 2024
2024
-
[17]
Localized conformal prediction: A generalized inference framework for conformal prediction.Biometrika, 110(1):33–50, 2023
Leying Guan. Localized conformal prediction: A generalized inference framework for conformal prediction.Biometrika, 110(1):33–50, 2023
2023
-
[18]
Large language models as simulated economic agents: What can we learn from homo silicus? Technical report, National Bureau of Economic Research, 2023
John J Horton. Large language models as simulated economic agents: What can we learn from homo silicus? Technical report, National Bureau of Economic Research, 2023
2023
-
[19]
Wenlong Ji, Lihua Lei, and Tijana Zrnic. Predictions as surrogates: Revisiting surrogate outcomes in the age of ai.arXiv preprint arXiv:2501.09731, 2025
Pith/arXiv arXiv 2025
-
[20]
Highly accurate pro- tein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin ˇZ´ıdek, Anna Potapenko, et al. Highly accurate pro- tein structure prediction with alphafold.Nature, 596(7873):583–589, 2021
2021
-
[21]
Nir Keret and Ali Shojaie. GLM inference with AI-generated synthetic data using misspecified linear regression.arXiv preprint arXiv:2503.21968, 2025
arXiv 2025
-
[22]
Dan M Kluger, Kerri Lu, Tijana Zrnic, Sherrie Wang, and Stephen Bates. Prediction-powered inference with imputed covariates and nonuniform sampling.arXiv preprint arXiv:2501.18577, 2025
arXiv 2025
-
[23]
Prediction-powered adaptive shrinkage estimation
Sida Li and Nikolaos Ignatiadis. Prediction-powered adaptive shrinkage estimation. InInternational Conference on Machine Learning, pages 34836–34875. PMLR, 2025
2025
-
[24]
Synthetic surrogates improve power for genome-wide association studies of partially missing phenotypes in population biobanks
Zachary R McCaw, Jianhui Gao, Xihong Lin, and Jessica Gronsbell. Synthetic surrogates improve power for genome-wide association studies of partially missing phenotypes in population biobanks. Nature genetics, 56(7):1527–1536, 2024
2024
-
[25]
Assumption-lean and data- adaptive post-prediction inference.Journal of Machine Learning Research, 26(179):1–31, 2025
Jiacheng Miao, Xinran Miao, Yixuan Wu, Jiwei Zhao, and Qiongshi Lu. Assumption-lean and data- adaptive post-prediction inference.Journal of Machine Learning Research, 26(179):1–31, 2025
2025
-
[26]
Generative agents: Interactive simulacra of human behavior
Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023
2023
-
[27]
The empirical Bayes approach to statistical decision problems.The Annals of Math- ematical Statistics, 35(1):1–20, 1964
Herbert Robbins. The empirical Bayes approach to statistical decision problems.The Annals of Math- ematical Statistics, 35(1):1–20, 1964
1964
-
[28]
An empirical Bayes approach to statistics
Herbert E Robbins. An empirical Bayes approach to statistics. InBreakthroughs in Statistics: Founda- tions and basic theory, pages 388–394. Springer, 1992
1992
-
[29]
Whose opinions do language models reflect? InInternational Conference on Machine Learning, pages 29971–30004
Shibani Santurkar, Esin Durmus, Faisal Ladhak, Cinoo Lee, Percy Liang, and Tatsunori Hashimoto. Whose opinions do language models reflect? InInternational Conference on Machine Learning, pages 29971–30004. PMLR, 2023
2023
-
[30]
Demystifying prediction powered inference
Yilin Song, Dan M Kluger, Harsh Parikh, and Tian Gu. Demystifying prediction powered inference. arXiv preprint arXiv:2601.20819, 2026
arXiv 2026
-
[31]
Conformal prediction under covariate shift.Advances in neural information processing systems, 32, 2019
Ryan J Tibshirani, Rina Foygel Barber, Emmanuel Candes, and Aaditya Ramdas. Conformal prediction under covariate shift.Advances in neural information processing systems, 32, 2019
2019
-
[32]
Springer, 2005
Vladimir Vovk, Alexander Gammerman, and Glenn Shafer.Algorithmic learning in a random world. Springer, 2005
2005
-
[33]
Justice or prejudice? quantifying biases in llm-as-a-judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in llm-as-a-judge. In International Conference on Learning Representations, volume 2025, pages 102351–102390, 2025. 22
2025
-
[34]
Imputation-powered inference.arXiv preprint arXiv:2509.13778, 2025
Sarah Zhao and Emmanuel Cand `es. Imputation-powered inference.arXiv preprint arXiv:2509.13778, 2025
arXiv 2025
-
[35]
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, and Eric Xing. Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems, 36:46595–46623, 2023
2023
-
[36]
Cross-prediction-powered inference.Proceedings of the National Academy of Sciences, 121(15):e2322083121, 2024
Tijana Zrnic and Emmanuel J Cand`es. Cross-prediction-powered inference.Proceedings of the National Academy of Sciences, 121(15):e2322083121, 2024. 23 A Deferred proofs A.1 Proof of Theorem 2 We first show that the calibrated upper endpoint satisfies P ˆ∆U T+1 ≤ ˆ∆U ≥1− α3 2 −ε U . For any vectorv= (v 1, . . . , vT+1 )∈R T+1 , define SU (v) = i∈...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.