CADET: Physics-Grounded Causal Auditing and Training-Free Deconfounding of End-to-End Driving Planners
Pith reviewed 2026-06-27 04:53 UTC · model grok-4.3
The pith
CADET audits and repairs spurious correlations in pretrained driving planners without any retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CADET is a training-free framework that audits, benchmarks, and repairs spurious reliance in pretrained E2E planners without any parameter update.
What carries the argument
Physics-grounded causal auditing that performs interventions on scene variables according to physical constraints to isolate and deconfound non-causal cues in the planner's output.
If this is right
- Deployed planners can be audited for causal confusion without retraining or new data collection.
- Spurious reliance can be repaired in models that are already in operation.
- Causal benchmarks can supplement existing open-loop metrics to expose hidden shortcuts.
- Long-tail scenario robustness improves once non-causal co-occurrences are removed from the decision process.
Where Pith is reading between the lines
- The same auditing approach could be tested on imitation-learned policies in other domains such as robotics manipulation.
- Regulators could require causal-audit scores as part of safety certification for autonomous systems.
- Online versions of the audit might enable continuous monitoring during real-world operation.
Load-bearing premise
Physics-grounded causal auditing can reliably identify and repair spurious correlations in pretrained models without access to training data or model updates.
What would settle it
A controlled test in which known spurious cues are independently manipulated while causal factors remain fixed; if CADET does not reduce the planner's dependence on the spurious cues or improve decision accuracy, the central claim fails.
Figures


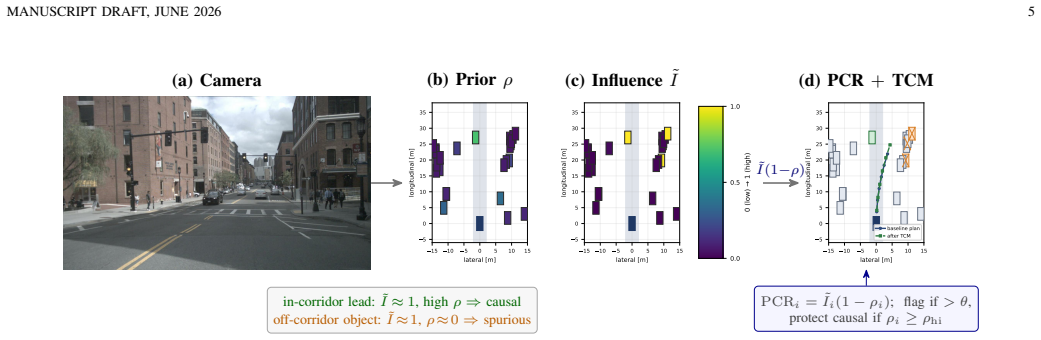



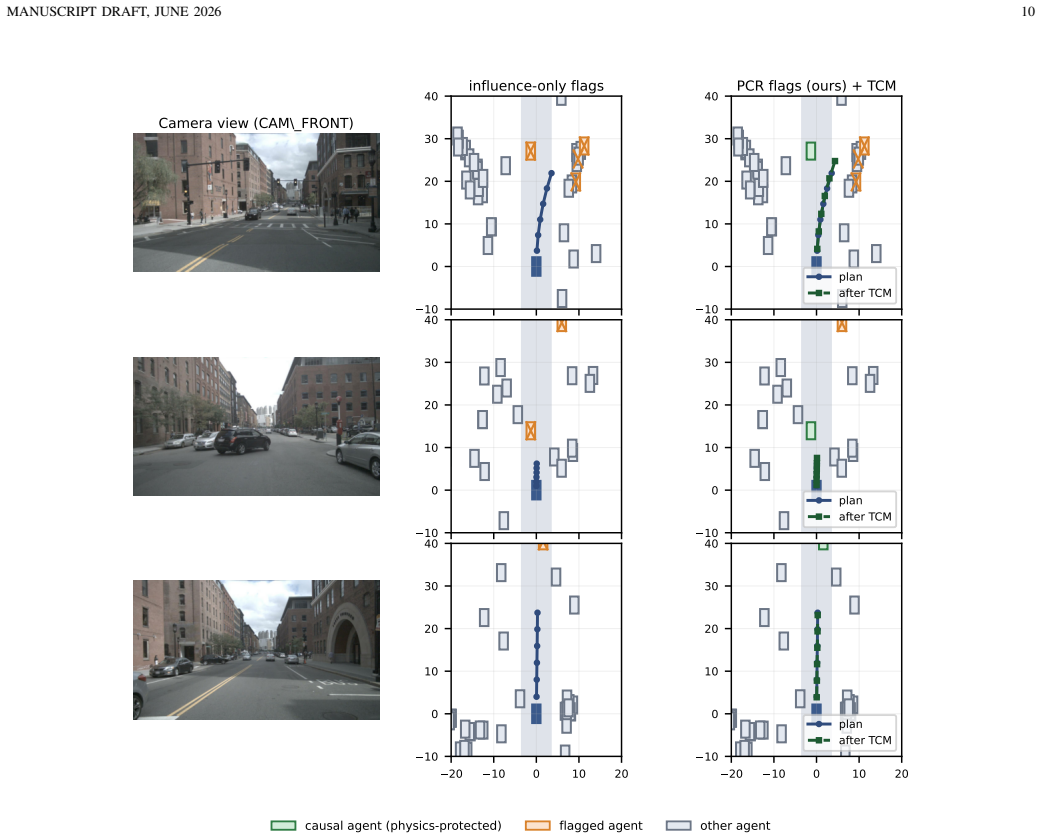


read the original abstract
End-to-end (E2E) autonomous-driving planners trained by imitation are prone to statistical shortcuts: they associate scene elements that merely co-occur with expert actions (a roadside object, a building facade) with driving decisions, rather than the variables that causally determine them. Such causal confusion silently compromises reliability in long-tail scenarios, and it is difficult to detect, because prevailing open-loop metrics (L2 displacement and collision rate) are dominated by ego status and do not indicate whether a planner depends on spurious cues. Existing remedies based on causal-intervention training require retraining large models and cannot audit a planner that is already deployed. We present CADET, a training-free framework that audits, benchmarks, and repairs spurious reliance in pretrained E2E planners without any parameter update.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CADET, a training-free framework that audits, benchmarks, and repairs spurious reliance on non-causal scene elements in pretrained end-to-end driving planners by performing physics-grounded causal interventions, without requiring access to training data or any parameter updates to the model.
Significance. If the central claims hold, the work would be significant for practical deployment of imitation-learned planners, as it offers a post-training auditing and repair mechanism that avoids the computational cost of retraining large models. The training-free property and emphasis on causal auditing over open-loop metrics are clear strengths.
major comments (1)
- [Abstract and method description (likely §3–4)] The central claim that physics-grounded causal auditing suffices to detect and deconfound spurious reliance (Abstract) is load-bearing, yet the manuscript provides no discussion or experiments addressing whether the simulator-based interventions can capture non-physical cues (e.g., façade textures, signage styles, or lane-marking colors) that imitation-trained planners are documented to exploit. If such cues lie outside the intervenable variables, the audit step will under-report spurious dependence and the repair step will be ineffective.
minor comments (1)
- [Abstract] The abstract would benefit from one sentence summarizing the concrete causal variables and intervention types used in the physics model.
Simulated Author's Rebuttal
We thank the referee for highlighting the scope of the physics-grounded interventions. We address the concern point-by-point below.
read point-by-point responses
-
Referee: [Abstract and method description (likely §3–4)] The central claim that physics-grounded causal auditing suffices to detect and deconfound spurious reliance (Abstract) is load-bearing, yet the manuscript provides no discussion or experiments addressing whether the simulator-based interventions can capture non-physical cues (e.g., façade textures, signage styles, or lane-marking colors) that imitation-trained planners are documented to exploit. If such cues lie outside the intervenable variables, the audit step will under-report spurious dependence and the repair step will be ineffective.
Authors: We agree that the manuscript would benefit from an explicit discussion of the scope of the intervenable variables. CADET is deliberately scoped to physics-grounded interventions (object positions, velocities, road geometry, etc.) because these are the variables that can be reliably manipulated via the simulator's physics engine without model access or retraining. Non-physical cues such as textures, signage styles, or lane-marking colors are documented spurious factors in some imitation-learning settings, but they lie outside the current intervention mechanism. The central claim therefore applies specifically to physical causal factors; we do not assert coverage of all visual shortcuts. We will add a clarifying paragraph in §3 (and a short note in the abstract) stating this limitation and outlining possible future extensions that would require appearance-editing capabilities in the simulator. revision: yes
Circularity Check
No circularity; claims rest on external causal auditing without self-referential reductions
full rationale
The provided abstract and text introduce CADET as a training-free auditing framework relying on physics-grounded causal interventions to detect spurious correlations in pretrained E2E planners. No equations, parameter fits, derivations, or self-citations are present that would reduce any 'prediction' or result to the inputs by construction. The description contrasts with retraining methods but does not invoke uniqueness theorems, ansatzes from prior work, or fitted inputs renamed as outputs. This matches the default expectation of no significant circularity when the paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Planning- oriented autonomous driving,
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li, “Planning- oriented autonomous driving,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 17 853–17 862
2023
-
[2]
V AD: Vectorized scene representation for efficient autonomous driving,
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang, “V AD: Vectorized scene representation for efficient autonomous driving,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023, pp. 8340– 8350
2023
-
[3]
SparseDrive: End-to-end autonomous driving via sparse scene representation,
W. Sun, X. Lin, Y . Shi, C. Zhang, H. Wu, and S. Zheng, “SparseDrive: End-to-end autonomous driving via sparse scene representation,”arXiv preprint arXiv:2405.19620, 2024
arXiv 2024
-
[4]
PARA- Drive: Parallelized architecture for real-time autonomous driving,
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone, “PARA- Drive: Parallelized architecture for real-time autonomous driving,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 15 449–15 458
2024
-
[5]
Causal confusion in imita- tion learning,
P. de Haan, D. Jayaraman, and S. Levine, “Causal confusion in imita- tion learning,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 32, 2019
2019
-
[6]
Is ego status all you need for open-loop end-to-end autonomous driving?
Z. Li, Z. Yu, S. Lan, J. Li, J. Kautz, T. Lu, and J. M. Alvarez, “Is ego status all you need for open-loop end-to-end autonomous driving?” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024, pp. 14 864–14 873
2024
-
[7]
CausalV AD: De-confounding end-to-end autonomous driving via causal intervention,
J. Tang, Z. Zhou, Z. He, J. Zhang, K. Zhang, and J. Pu, “CausalV AD: De-confounding end-to-end autonomous driving via causal intervention,” arXiv preprint arXiv:2603.18561, 2026
Pith/arXiv arXiv 2026
-
[8]
M. Arjovsky, L. Bottou, I. Gulrajani, and D. Lopez-Paz, “Invariant risk minimization,”arXiv preprint arXiv:1907.02893, 2019
Pith/arXiv arXiv 1907
-
[9]
Beyond patterns: Harnessing causal logic for autonomous driving trajectory prediction,
B. Wang, H. Liao, C. Wang, B. Rao, Y . Guan, G. Yu, J. Zhang, S. Lai, C. Xu, and Z. Li, “Beyond patterns: Harnessing causal logic for autonomous driving trajectory prediction,” inProceedings of the Thirty- Fourth International Joint Conference on Artificial Intelligence (IJCAI), 2025
2025
-
[10]
Cluster-aggregated trans- former: Enhancing lightweight parameter models,
Z. Guo, A. P. Adedigba, and R. Mallipeddi, “Cluster-aggregated trans- former: Enhancing lightweight parameter models,”Engineering Appli- cations of Artificial Intelligence, vol. 159, p. 111468, 2025
2025
-
[11]
IDS-Extract: Downsizing deep learning model for question and answering,
Z. Guo, S. Kavuri, J. Lee, and M. Lee, “IDS-Extract: Downsizing deep learning model for question and answering,” in2023 International Conference on Electronics, Information, and Communication (ICEIC). IEEE, 2023, pp. 1–5
2023
-
[12]
Cluster aggregated GAN (CAG): A cluster-based hybrid model for appliance pattern generation,
Z. Guo, A. P. Adedigba, and R. Mallipeddi, “Cluster aggregated GAN (CAG): A cluster-based hybrid model for appliance pattern generation,” arXiv preprint arXiv:2512.22287, 2025
Pith/arXiv arXiv 2025
-
[13]
TSDCA-BA: An ultra-lightweight speech enhancement model for real-time hearing aids with multi-scale STFT fusion,
Z. Fan, Z. Guo, Y . Lai, and J. Kim, “TSDCA-BA: An ultra-lightweight speech enhancement model for real-time hearing aids with multi-scale STFT fusion,”Applied Sciences, vol. 15, no. 15, p. 8183, 2025
2025
-
[14]
Visual recognition of crop composite planting based on vision transformer,
Z. Guo, X. Yu, S. Wang, and R. Mallipeddi, “Visual recognition of crop composite planting based on vision transformer,” inInternational Conference on Machine Learning, IoT and Big Data. Springer, 2025, pp. 296–306
2025
-
[15]
Dynamic tanh reinforcement learning: A normalization-free transformer for open trav- eling salesman problem optimization,
Z. Guo, A. P. Adedigba, R. Mallipeddi, and H. Lee, “Dynamic tanh reinforcement learning: A normalization-free transformer for open trav- eling salesman problem optimization,” inProceedings of the Annual Conference of the Institute of Control, Robotics and Systems (ICROS), 2025, pp. 845–846
2025
-
[16]
Cooperative coevolutionary genetic algorithm for multirobot task scheduling in Antarctica region,
Z. Guo, R. Mallipeddi, and H. Lee, “Cooperative coevolutionary genetic algorithm for multirobot task scheduling in Antarctica region,”Swarm and Evolutionary Computation, p. 102199, 2025
2025
-
[17]
iVec clustering: A new task allocation algorithm for multirobot task scheduling in antarctic environment,
A. Adedigba, Z. Guo, R. Mallipeddi, and H. Lee, “iVec clustering: A new task allocation algorithm for multirobot task scheduling in antarctic environment,” inProceedings of the Annual Conference of the Institute of Control, Robotics and Systems (ICROS), 2025, pp. 853–854
2025
-
[18]
Pluto: Pushing the limit of imita- tion learning-based planning for autonomous driving,
J. Cheng, Y . Chen, and Q. Chen, “Pluto: Pushing the limit of imita- tion learning-based planning for autonomous driving,”arXiv preprint arXiv:2404.14327, 2024
arXiv 2024
-
[19]
Rethinking imitation-based planners for autonomous driving,
J. Cheng, Y . Chen, X. Mei, B. Yang, B. Li, and M. Liu, “Rethinking imitation-based planners for autonomous driving,” inIEEE International Conference on Robotics and Automation (ICRA), 2024
2024
-
[20]
Causal inference by using invariant prediction: Identification and confidence intervals,
J. Peters, P. Bühlmann, and N. Meinshausen, “Causal inference by using invariant prediction: Identification and confidence intervals,”Journal of the Royal Statistical Society: Series B, vol. 78, no. 5, pp. 947–1012, 2016
2016
-
[21]
Visualizing and understanding convolu- tional networks,
M. D. Zeiler and R. Fergus, “Visualizing and understanding convolu- tional networks,” inEuropean Conference on Computer Vision (ECCV), 2014, pp. 818–833
2014
-
[22]
Bench2Drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driv- ing,
X. Jia, Z. Yang, Q. Li, Z. Zhang, and J. Yan, “Bench2Drive: Towards multi-ability benchmarking of closed-loop end-to-end autonomous driv- ing,” inAdvances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2024
2024
-
[23]
NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking,
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta, “NA VSIM: Data-driven non-reactive autonomous vehicle simulation and benchmarking,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[24]
Test-time trajectory optimization for autonomous driving,
Y . Xu, E. Zablocki, Y . Yin, E. Ramzi, E. Kirby, A. Boulch, and M. Cord, “Test-time trajectory optimization for autonomous driving,” arXiv preprint arXiv:2606.07170, 2026
Pith/arXiv arXiv 2026
-
[25]
Centaur: Robust end-to-end autonomous driving with test-time training,
C. Sima, K. Chitta, Z. Yu, S. Lan, P. Luo, A. Geiger, H. Li, and J. M. Alvarez, “Centaur: Robust end-to-end autonomous driving with test-time training,”arXiv preprint arXiv:2503.11650, 2025
arXiv 2025
-
[26]
Enhancing the understanding of urban street perception with LLMs and street view imagery,
X. Han, Y . Zhu, L. Wang, and Z. Guo, “Enhancing the understanding of urban street perception with LLMs and street view imagery,”Trans- actions in GIS, vol. 30, no. 3, p. e70280, 2026
2026
-
[27]
Structural induced exploration for balanced and scalable multi-robot path planning,
Z. Guo, A. P. Adedigba, R. Mallipeddi, and H. Lee, “Structural induced exploration for balanced and scalable multi-robot path planning,”arXiv preprint arXiv:2512.21654, 2025
arXiv 2025
-
[28]
Flattery in motion: Benchmarking and analyzing sycophancy in video-LLMs,
W. Zhou, S. Yang, Q. Yang, Z. Guo, L. Hu, and D. Wang, “Flattery in motion: Benchmarking and analyzing sycophancy in video-LLMs,” arXiv preprint arXiv:2506.07180, 2025
Pith/arXiv arXiv 2025
-
[29]
Benchmarking and mitigating sycophancy in medical vision language models,
J. Xu, Z. Guo, J. Lv, H. Lin, S. Yang, J. Wen, D. Wang, and L. Hu, “Benchmarking and mitigating sycophancy in medical vision language models,”arXiv preprint arXiv:2509.21979, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.