Test-Time Trajectory Optimization for Autonomous Driving
Pith reviewed 2026-06-27 21:51 UTC · model grok-4.3
The pith
Treating a planner's scorer as a reward and maximizing it at test time with the Cross-Entropy Method improves driving performance without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating the base planner's scorer as a learned trajectory-level reward function and applying the Cross-Entropy Method at test time, trajectories that better maximize the reward can be found, warm-started from the planner's proposals, yielding higher performance on NAVSIM-v1 (94.7 PDMS), NAVSIM-v2 (56.3 EPDMS), and closed-loop HUGSIM across six base planners without any retraining or additional supervision.
What carries the argument
The Cross-Entropy Method run at test time to maximize the base planner's trajectory scorer treated as a reward function.
If this is right
- TOAD works as a plug-and-play addition to any existing end-to-end planner.
- No retraining or extra supervision is needed to obtain the reported gains.
- Performance rises on NAVSIM-v1 to 94.7 PDMS when TOAD is applied.
- Performance rises on NAVSIM-v2 to 56.3 EPDMS when TOAD is applied.
- Performance rises on the closed-loop HUGSIM benchmark when TOAD is applied.
Where Pith is reading between the lines
- Many current planners may leave substantial headroom on the table by not optimizing against their own scoring functions after proposal generation.
- Similar test-time search could be tried in other sequential decision domains where a learned scorer exists but proposal quality is limited.
- Faster or more sample-efficient optimizers than the Cross-Entropy Method might be substituted while preserving the same plug-and-play property.
- Pairing the method with stronger initial proposal generators could produce additive rather than redundant gains.
Load-bearing premise
The scorer already produced by the base planner is smooth and informative enough for the Cross-Entropy Method to maximize it effectively at test time.
What would settle it
A controlled test in which running the Cross-Entropy Method on a planner's proposals produces trajectories that receive lower scores from the same scorer or worse closed-loop performance than the original proposals.
Figures


read the original abstract
End-to-end planners for autonomous driving typically generate a set of candidate trajectories, score each one, and return the highest-scoring candidate. However, the scorer is applied only after the proposals are generated and cannot influence the set of trajectories: a weak set of candidates limits planning performance regardless of the scorer's quality. We instead treat the scorer as a learned trajectory-level reward function and search for trajectories that maximize it. Our method, TOAD, runs the Cross-Entropy Method at test time, warm-started from the planner's proposals. It requires no retraining and is plug-and-play for existing planners. Across six base planners, TOAD improves results on NAVSIM-v1 (94.7 PDMS), NAVSIM-v2 (56.3 EPDMS), and the closed-loop HUGSIM benchmark. The code will be made publicly available via the project page: https://valeoai.github.io/TOAD/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TOAD, which treats the scorer of existing end-to-end autonomous driving planners as a learned trajectory-level reward and applies the Cross-Entropy Method (CEM) at test time, warm-started from the planner's proposals, to search for higher-scoring trajectories. The method requires no retraining and is presented as plug-and-play. It reports numerical improvements across six base planners on NAVSIM-v1 (94.7 PDMS), NAVSIM-v2 (56.3 EPDMS), and the closed-loop HUGSIM benchmark, with code to be released publicly.
Significance. If the central assumption holds, the approach provides a practical test-time enhancement to existing planners without additional training. The public code release is a clear strength supporting reproducibility and adoption.
major comments (3)
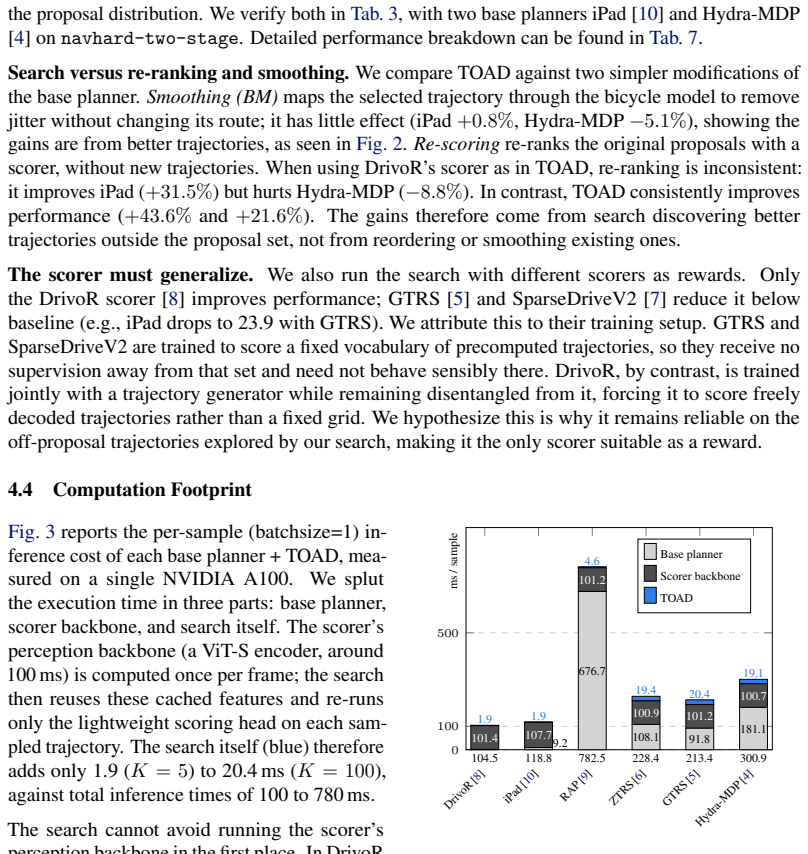
- [Section 3] Section 3 (Method): The description of CEM application provides no analysis of the scorer's properties (smoothness, variance, or flat regions) as a trajectory-level reward, which is load-bearing for the claim that CEM will reliably locate improved trajectories over the initial proposals.
- [Section 4] Section 4 (Experiments): Aggregate benchmark improvements are reported without per-scene score deltas between base proposals and CEM outputs, ablations on CEM hyperparameters (elite fraction, iterations, sampling variance), or statistical significance tests, preventing verification that gains stem from the optimization rather than confounding factors.
- [Table 1] Table 1 (or equivalent results table): The cross-planner gains on NAVSIM-v1/v2 and HUGSIM are presented without controls for CEM convergence criteria or multiple random seeds, undermining assessment of robustness.
minor comments (1)
- [Abstract and Section 3] The abstract and method section use 'parameter-free' phrasing for the overall approach, but CEM hyperparameters are introduced without explicit discussion of their selection or sensitivity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and indicate where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Section 3] Section 3 (Method): The description of CEM application provides no analysis of the scorer's properties (smoothness, variance, or flat regions) as a trajectory-level reward, which is load-bearing for the claim that CEM will reliably locate improved trajectories over the initial proposals.
Authors: We agree that analyzing the scorer's properties would strengthen the justification for applying CEM. Our empirical results show consistent gains across six planners, indicating the scorers are amenable to optimization in practice. In the revised manuscript, we will add a brief discussion in Section 3 on observed scorer characteristics (e.g., empirical smoothness from sampling) while noting that a full theoretical analysis lies outside the paper's scope. revision: partial
-
Referee: [Section 4] Section 4 (Experiments): Aggregate benchmark improvements are reported without per-scene score deltas between base proposals and CEM outputs, ablations on CEM hyperparameters (elite fraction, iterations, sampling variance), or statistical significance tests, preventing verification that gains stem from the optimization rather than confounding factors.
Authors: We will revise Section 4 to include ablations on CEM hyperparameters (elite fraction, iterations, sampling variance). We will also report average per-scene score deltas and apply statistical significance tests (e.g., paired t-tests) on the improvements to confirm they arise from the optimization. revision: yes
-
Referee: [Table 1] Table 1 (or equivalent results table): The cross-planner gains on NAVSIM-v1/v2 and HUGSIM are presented without controls for CEM convergence criteria or multiple random seeds, undermining assessment of robustness.
Authors: We will update the experimental description and results tables to explicitly state the CEM convergence criteria and report performance averaged over multiple random seeds with standard deviations to better demonstrate robustness. revision: yes
Circularity Check
No circularity: empirical test-time optimization with no self-referential derivations
full rationale
The paper describes a plug-and-play method that applies the Cross-Entropy Method at test time to maximize an existing base planner's scorer treated as a reward. No equations, parameter fits, or derivations are present that reduce the claimed benchmark improvements to quantities defined by the paper itself. The approach relies on an external optimizer (CEM) applied to pre-existing components without retraining. No self-citations are load-bearing for any uniqueness theorem or ansatz. The central claim is an empirical performance gain on external benchmarks (NAVSIM, HUGSIM), which does not reduce to a fitted input renamed as prediction or any of the enumerated circular patterns. This is the common case of a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
CADET: Physics-Grounded Causal Auditing and Training-Free Deconfounding of End-to-End Driving Planners
CADET is a training-free framework for auditing, benchmarking, and repairing spurious correlations in pretrained end-to-end autonomous driving planners using physics-grounded causal methods.
Reference graph
Works this paper leans on
-
[1]
M. Bojarski, D. Del Testa, D. Dworakowski, B. Firner, B. Flepp, P. Goyal, L. D. Jackel, M. Monfort, U. Muller, J. Zhang, et al. End to end learning for self-driving cars.arXiv preprint arXiv:1604.07316, 2016
Pith/arXiv arXiv 2016
-
[2]
Y . Hu, J. Yang, L. Chen, K. Li, C. Sima, X. Zhu, S. Chai, S. Du, T. Lin, W. Wang, L. Lu, X. Jia, Q. Liu, J. Dai, Y . Qiao, and H. Li. Planning-oriented autonomous driving. InCVPR, 2023
2023
-
[3]
K. Renz, L. Chen, E. Arani, and O. Sinavski. Simlingo: Vision-only closed-loop autonomous driving with language-action alignment. InCVPR, 2025
2025
-
[4]
Z. Li, K. Li, S. Wang, S. Lan, Z. Yu, Y . Ji, Z. Li, Z. Zhu, J. Kautz, Z. Wu, et al. Hydra- mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
Pith/arXiv arXiv 2024
-
[5]
Z. Li, W. Yao, Z. Wang, X. Sun, J. Chen, N. Chang, M. Shen, Z. Wu, S. Lan, and J. M. Alvarez. Generalized trajectory scoring for end-to-end multimodal planning.arXiv preprint arXiv:2506.06664, 2025
arXiv 2025
-
[6]
Z. Li, W. Yao, Z. Wang, X. Sun, J. Chen, N. Chang, M. Shen, J. Song, Z. Wu, S. Lan, et al. Ztrs: Zero-imitation end-to-end autonomous driving with trajectory scoring.arXiv preprint arXiv:2510.24108, 2025
arXiv 2025
-
[7]
W. Sun, X. Lin, K. Chen, Z. Pei, X. Li, Y . Shi, and S. Zheng. Sparsedrivev2: Scoring is all you need for end-to-end autonomous driving.arXiv preprint arXiv:2603.29163, 2026
arXiv 2026
-
[8]
Kirby, A
E. Kirby, A. Boulch, Y . Xu, Y . Yin, G. Puy, E. Zablocki, A. Bursuc, S. Gidaris, R. Marlet, F. Bartoccioni, A.-Q. Cao, N. Samet, T.-H. Vu, and M. Cord. Driving on registers. InCVPR, 2026
2026
-
[9]
L. Feng, Y . Gao, E. Zablocki, Q. Li, W. Li, S. Liu, M. Cord, and A. Alahi. Rap: 3d rasterization augmented end-to-end planning. InICLR, 2026
2026
-
[10]
K. Guo, H. Liu, X. Wu, J. Pan, and C. Lv. ipad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
arXiv 2025
-
[11]
R. Y . Rubinstein and D. P. Kroese.The cross-entropy method: a unified approach to combinato- rial optimization, Monte-Carlo simulation, and machine learning. Springer, 2004
2004
-
[12]
Dauner, M
D. Dauner, M. Hallgarten, T. Li, X. Weng, Z. Huang, Z. Yang, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking. InNeurIPS, 2024
2024
-
[13]
W. Cao, M. Hallgarten, T. Li, D. Dauner, X. Gu, C. Wang, Y . Miron, M. Aiello, H. Li, I. Gilitschenski, B. Ivanovic, M. Pavone, A. Geiger, and K. Chitta. Pseudo-simulation for autonomous driving. InCoRL, 2025
2025
-
[14]
Dauner, M
D. Dauner, M. Hallgarten, A. Geiger, and K. Chitta. Parting with misconceptions about learning-based vehicle motion planning. InCoRL, 2023. 9
2023
-
[15]
H. Zhou, L. Lin, J. Wang, Y . Lu, D. Bai, B. Liu, Y . Wang, A. Geiger, and Y . Liao. HUGSIM: A real-time, photo-realistic and closed-loop simulator for autonomous driving.IEEE Trans. Pattern Anal. Mach. Intell., 2026
2026
-
[16]
W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun. End-to-end interpretable neural motion planner. InCVPR, 2019
2019
-
[17]
Yurtsever, J
E. Yurtsever, J. Lambert, A. Carballo, and K. Takeda. A survey of autonomous driving: Common practices and emerging technologies.IEEE Access, 2020
2020
-
[18]
Jiang, S
B. Jiang, S. Chen, Q. Xu, B. Liao, J. Chen, H. Zhou, Q. Zhang, W. Liu, C. Huang, and X. Wang. Vad: Vectorized scene representation for efficient autonomous driving. InICCV, 2023
2023
-
[19]
X. Weng, B. Ivanovic, Y . Wang, Y . Wang, and M. Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. InCVPR, 2024
2024
-
[20]
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InCVPR, 2025
2025
-
[21]
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin. Goalflow: Goal- driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InCVPR, 2025
2025
-
[22]
W. Yao, Z. Li, S. Lan, Z. Wang, X. Sun, J. M. ´Alvarez, and Z. Wu. Drivesuprim: Towards precise trajectory selection for end-to-end planning. InAAAI, 2026
2026
-
[23]
Kobilarov
M. Kobilarov. Cross-entropy motion planning.Int. J. Robotics Res., 2012
2012
-
[24]
Pinneri, S
C. Pinneri, S. Sawant, S. Blaes, J. Achterhold, J. Stueckler, M. Rol ´ınek, and G. Martius. Sample-efficient cross-entropy method for real-time planning. InCoRL, 2020
2020
-
[25]
Williams, N
G. Williams, N. Wagener, B. Goldfain, P. Drews, J. M. Rehg, B. Boots, and E. A. Theodorou. Information theoretic MPC for model-based reinforcement learning. InICRA, 2017
2017
-
[26]
Drews, G
P. Drews, G. Williams, B. Goldfain, E. A. Theodorou, and J. M. Rehg. Aggressive deep driving: Combining convolutional neural networks and model predictive control. InCoRL, 2017
2017
-
[27]
Huang, H
Z. Huang, H. Liu, J. Wu, and C. Lv. Differentiable integrated motion prediction and planning with learnable cost function for autonomous driving.IEEE Trans. Neural Networks Learn. Syst., 2024
2024
-
[28]
C. Sima, K. Chitta, Z. Yu, S. Lan, P. Luo, A. Geiger, H. Li, and J. M. Alvarez. Centaur: Robust end-to-end autonomous driving with test-time training.arXiv preprint arXiv:2503.11650, 2025
arXiv 2025
-
[29]
A. Jaech, A. Kalai, A. Lerer, A. Richardson, A. El-Kishky, A. Low, A. Helyar, A. Madry, A. Beutel, A. Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
Pith/arXiv arXiv 2024
-
[30]
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
Pith/arXiv arXiv 2025
-
[31]
B. Brown, J. Juravsky, R. Ehrlich, R. Clark, Q. V . Le, C. R´e, and A. Mirhoseini. Large language monkeys: Scaling inference compute with repeated sampling.arXiv preprint arXiv:2407.21787, 2024
Pith/arXiv arXiv 2024
- [32]
-
[33]
Y . Li, Y . Wang, Y . Liu, J. He, L. Fan, and Z. Zhang. End-to-end driving with online trajectory evaluation via BEV world model. InICCV, 2025. 10
2025
-
[34]
J. Sun, F. Xue, T. Long, C. Liu, J.-F. Hu, W.-S. Zheng, and N. Sebe. Risk-aware world model predictive control for generalizable end-to-end autonomous driving.arXiv preprint arXiv:2602.23259, 2026
arXiv 2026
-
[35]
Y . Li, K. Xiong, X. Guo, F. Li, S. Yan, G. Xu, L. Zhou, L. Chen, H. Sun, B. Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving. InICLR, 2026
2026
-
[36]
Z. Song, L. Liu, H. Pan, B. Liao, M. Guo, L. Yang, Y . Zhang, S. Xu, C. Jia, and Y . Luo. Diver: Reinforced diffusion breaks imitation bottlenecks in end-to-end autonomous driving.arXiv preprint arXiv:2507.04049, 2025
Pith/arXiv arXiv 2025
-
[37]
D. Li, C. Li, Y . Wang, J. Ren, X. Wen, P. Li, L. Xu, K. Zhan, P. Jia, X. Lang, et al. Learning personalized driving styles via reinforcement learning from human feedback.arXiv preprint arXiv:2503.10434, 2025
arXiv 2025
-
[38]
Hanselmann, K
N. Hanselmann, K. Renz, K. Chitta, A. Bhattacharyya, and A. Geiger. KING: generating safety-critical driving scenarios for robust imitation via kinematics gradients. InECCV, 2022
2022
-
[39]
Y . Yin, P. Khayatan,´E. Zablocki, A. Boulch, and M. Cord. Regents: Real-world safety-critical driving scenario generation made stable. InECCV Workshops, 2024
2024
-
[40]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 2023
2023
-
[41]
Y . Hong, X. Zhou, Y . Li, X. Zhou, L. Liu, Y . Luo, S. Xu, L. Yang, and Z. Song. Drivefuture: Future-aware latent world models for autonomous driving.arXiv preprint arXiv:2605.09701, 2026
Pith/arXiv arXiv 2026
-
[42]
Y . Liao, J. Xie, and A. Geiger. KITTI-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.TPAMI, 2023
2023
-
[43]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Liong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, and O. Beijbom. nuscenes: A multimodal dataset for autonomous driving. InCVPR, 2020
2020
-
[44]
P. Xiao, Z. Shao, S. Hao, Z. Zhang, X. Chai, J. Jiao, Z. Li, J. Wu, K. Sun, K. Jiang, Y . Wang, and D. Yang. Pandaset: Advanced sensor suite dataset for autonomous driving. InITSC, 2021
2021
-
[45]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. InCVPR, 2020
2020
-
[46]
Chitta, A
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.TPAMI, 2022
2022
-
[47]
Y . Wang, X. Li, W. Wang, J. Zhang, Y . Li, Y . Chen, X. Wang, and Z. Zhang. Unified vision- language-action model.arXiv preprint arXiv:2506.19850, 2025
arXiv 2025
-
[48]
Y . Chen, Y . Wang, and Z. Zhang. Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. InICCV, 2025
2025
-
[49]
C. Shi, S. Shi, K. Sheng, B. Zhang, and L. Jiang. Drivex: Omni scene modeling for learning generalizable world knowledge in autonomous driving. InICCV, 2025
2025
-
[50]
Zheng, P
Y . Zheng, P. Yang, Z. Xing, Q. Zhang, Y . Zheng, Y . Gao, P. Li, T. Zhang, Z. Xia, P. Jia, et al. World4drive: End-to-end autonomous driving via intention-aware physical latent world model. InICCV, 2025. 11
2025
-
[51]
C. Yuan, Z. Zhang, J. Sun, S. Sun, Z. Huang, C. D. W. Lee, D. Li, Y . Han, A. Wong, K. P. Tee, et al. Drama: An efficient end-to-end motion planner for autonomous driving with mamba. In ISRR, 2024
2024
-
[52]
S. Chen, B. Jiang, H. Gao, B. Liao, Q. Xu, Q. Zhang, C. Huang, W. Liu, and X. Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
Pith/arXiv arXiv 2024
-
[53]
Wozniak, L
M. Wozniak, L. Liu, Y . Cai, and P. Jensfelt. PRIX: learning to plan from raw pixels for end-to-end autonomous driving.IEEE Robotics Autom. Lett., 2026
2026
-
[54]
Z. Zhou, T. Cai, S. Z. Zhao, Y . Zhang, Z. Huang, B. Zhou, and J. Ma. Autovla: A vision- language-action model for end-to-end autonomous driving with adaptive reasoning and rein- forcement fine-tuning.NeurIPS, 2025
2025
-
[55]
Y . Li, S. Shang, W. Liu, B. Zhan, H. Wang, Y . Wang, Y . Chen, X. Wang, Y . An, C. Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025
Pith/arXiv arXiv 2025
-
[56]
K. Li, Z. Li, S. Lan, Y . Xie, Z. Zhang, J. Liu, Z. Wu, Z. Yu, and J. M. Alvarez. Hydra- mdp++: Advancing end-to-end driving via expert-guided hydra-distillation.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[57]
L. Liu, C. Jia, G. Yu, Z. Song, J. Li, F. Jia, P. Wu, X. Hao, and Y . Luo. Guideflow: Constraint-guided flow matching for planning in end-to-end autonomous driving.arXiv preprint arXiv:2511.18729, 2025
arXiv 2025
-
[58]
B. Jiang, S. Chen, B. Liao, X. Zhang, W. Yin, Q. Zhang, C. Huang, W. Liu, and X. Wang. Senna: Bridging large vision-language models and end-to-end autonomous driving.arXiv preprint arXiv:2410.22313, 2024
Pith/arXiv arXiv 2024
-
[59]
B. Sun, Y . Cao, Y . Wang, R. Wang, J. Shang, X. Feng, J. Lu, J. Shi, S. Yang, X. Yan, et al. Minddrive: An all-in-one framework bridging world models and vision-language model for end-to-end autonomous driving.arXiv preprint arXiv:2512.04441, 2025
arXiv 2025
-
[60]
Z. Zhou, R. Yang, Y . Guo, S. X. Chen, T. Feng, K. Pistunova, Y . Shen, L. Su, J. Ma, et al. Spanvla: Efficient action bridging and learning from negative-recovery samples for vision- language-action model.arXiv preprint arXiv:2604.19710, 2026
Pith/arXiv arXiv 2026
- [61]
-
[62]
H. Tian, T. Li, H. Liu, J. Yang, Y . Qiu, G. Li, J. Wang, Y . Gao, Z. Zhang, L. Wang, H. Ye, T. Tan, L. Chen, and H. Li. Simscale: Learning to drive via real-world simulation at scale. InCVPR, 2026. 12 A Driving Metrics In the study, we use the official metrics as defined by their original benchmarks. NA VSIM-v1 [12].We use the Predictive Driver Model Sco...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.