Every Eval Ever: A Unifying Schema and Community Repository for AI Evaluation Results
Pith reviewed 2026-06-27 04:43 UTC · model grok-4.3
The pith
A single source-agnostic JSON schema turns scattered AI evaluation results into one comparable repository.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Every Eval Ever supplies the first community-governed schema that represents any AI evaluation result as one unified JSON document; the schema is deliberately source-agnostic so that outputs from harnesses, leaderboards, and papers can be ingested without format-specific loss, optionally preserves instance-level scores, and is accompanied by automatic converters plus a growing public database.
What carries the argument
The unifying JSON schema that ingests results from evaluation harnesses and papers alike while optionally storing per-instance outputs.
If this is right
- Results produced by different frameworks become directly comparable once converted to the shared document.
- Per-instance outputs can be retained alongside aggregate scores for finer analysis.
- Automatic converters reduce the manual work of moving data from existing harnesses and leaderboards.
- A single community database grows through contributions and already tracks thousands of models and benchmarks.
Where Pith is reading between the lines
- Labs could stop re-running the same evaluations on the same models simply to match their own format.
- Meta-studies of how different frameworks agree or diverge on the same task become feasible at scale.
- Evaluation authors might begin designing new benchmarks with the schema fields in mind from the outset.
Load-bearing premise
One fixed schema can capture the full variety of evaluation outputs, metadata, and scoring rules from current and future frameworks without substantial information loss or repeated extensions.
What would settle it
An evaluation framework appears whose scores or metadata cannot be recorded in the current schema without either dropping key details or forcing a structural change to the JSON definition.
Figures


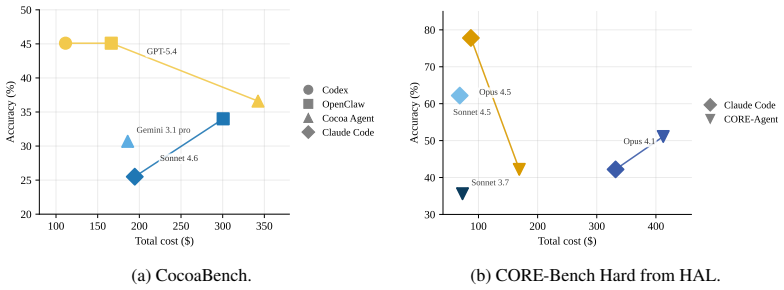

read the original abstract
AI evaluations are widely used for testing and understanding progress. However, the diverse evaluators bring with them inconsistencies that challenge analysis and comparison. First, results are saved in incompatible formats, scattered across leaderboards, papers, blog posts, evaluation harness logs, and custom repositories. Second, results are created by different evaluation frameworks, which produce divergent scores for nominally identical evaluations and record metadata inconsistently, hindering comparison, cross-community evaluation science, cost reduction, and reuse. We introduce Every Eval Ever, the first shared schema and community-crowdsourced repository for AI evaluation results. The schema standardizes how evaluations are represented in a unified, single JSON document. It is source-agnostic by design, ingesting results from evaluation harnesses and papers alike, and optionally stores per-instance outputs for fine-grained analysis. We contribute: (i) a community-governed metadata schema with a companion instance-level schema, the first standardization effort of its kind; (ii) automatic converters from popular formats, evaluation harnesses, and leaderboards to the unified schema; and (iii) a crowdsourced community database hosted on Hugging Face, currently spanning to date 22,235 models, 2,273 unique benchmarks, and 31 evaluation formats.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Every Eval Ever as the first shared schema and community-crowdsourced repository for AI evaluation results. The schema standardizes evaluations into a single source-agnostic JSON document (with an optional instance-level companion), supported by automatic converters from 31 formats and a Hugging Face database covering 22,235 models and 2,273 benchmarks.
Significance. If the schema and converters achieve the claimed source-agnostic standardization without substantial information loss, the work would enable more reliable cross-framework comparisons, reduce redundant evaluations, and support reusable community analysis of AI progress. The concrete coverage numbers and provision of converters represent a practical infrastructure contribution.
major comments (2)
- [Abstract] Abstract: the claim that converters exist and produce a unified schema is supported only by coverage statistics (22,235 models, 31 formats); no details are given on how divergences in scores or metadata between sources are resolved during ingestion.
- [Section 3] Section 3 (schema definition): the assertion that the schema is source-agnostic via fixed fields plus optional extensions is load-bearing for the central claim, yet the manuscript contains no systematic audit demonstrating that non-standard elements (custom metrics, hierarchical scores, provenance chains, or non-numeric outputs) are preserved without approximation or omission.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below. We agree that the manuscript would be strengthened by adding explicit details on divergence resolution during ingestion and by including a systematic audit of schema coverage for non-standard elements. Both will be incorporated in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that converters exist and produce a unified schema is supported only by coverage statistics (22,235 models, 31 formats); no details are given on how divergences in scores or metadata between sources are resolved during ingestion.
Authors: We acknowledge that the current text relies primarily on aggregate coverage numbers without describing the resolution logic. Section 4 outlines the converter architecture and the schema's optional fields, but does not specify conflict-handling rules (e.g., source-priority ordering, discrepancy logging, or retention of original values). In the revision we will add a concise subsection under Section 4 that documents these mechanisms, thereby directly supporting the claim that the unified schema is produced without substantial information loss. revision: yes
-
Referee: [Section 3] Section 3 (schema definition): the assertion that the schema is source-agnostic via fixed fields plus optional extensions is load-bearing for the central claim, yet the manuscript contains no systematic audit demonstrating that non-standard elements (custom metrics, hierarchical scores, provenance chains, or non-numeric outputs) are preserved without approximation or omission.
Authors: The referee is correct that no systematic audit appears in the manuscript. Section 3 defines the core-plus-extensions structure and the instance-level companion schema, while the converter descriptions claim preservation; however, concrete validation across the listed element types is absent. We will add an appendix containing a targeted audit (case studies drawn from at least five distinct source formats) that demonstrates retention of custom metrics, hierarchical scores, provenance chains, and non-numeric outputs. This will supply the missing empirical support for the source-agnostic claim. revision: yes
Circularity Check
No circularity; schema and repository contribution is self-contained infrastructure work
full rationale
The paper presents a unifying JSON schema, converters, and crowdsourced repository with no derivations, equations, predictions, or fitted parameters. Central claims concern standardization and coverage (22k models, 31 formats) but rest on explicit construction of the schema and reported ingestion counts rather than any reduction to self-defined quantities or self-citation chains. No load-bearing uniqueness theorems, ansatzes, or renamings appear. The contribution is therefore independent of the circularity patterns enumerated.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alexandra Abbas, Celia Waggoner, and Justin Olive. 2025. Developing and maintaining an open-source repository of AI evaluations: Challenges and insights. InChampioning Open-source DEvelopment in ML Workshop @ ICML25
2025
-
[2]
UK AI Security Institute. 2024. Inspect AI: Framework for Large Language Model Evaluations
2024
-
[3]
Mubashara Akhtar, Omar Benjelloun, Costanza Conforti, Luca Foschini, Pieter Gijsbers, Joan Giner-Miguelez, Sujata Goswami, Nitisha Jain, Michalis Karamousadakis, Satyapriya Krishna, Michael Kuchnik, Sylvain Lesage, Quentin Lhoest, Pierre Marcenac, Manil Maskey, Peter Mattson, Luis Oala, Hamidah Oderinwale, Pierre Ruyssen, and 12 others. 2024. Croissant: A...
2024
-
[4]
Rahmani, Christina Knight, and 18 others
Mubashara Akhtar, Anka Reuel, Prajna Soni, Sanchit Ahuja, Pawan Sasanka Ammanamanchi, Ruchit Rawal, Vilém Zouhar, Srishti Yadav, Chenxi Whitehouse, Dayeon Ki, Jennifer Mickel, Leshem Choshen, Marek Šuppa, Jan Batzner, Jenny Chim, Jeba Sania, Yanan Long, Hossein A. Rahmani, Christina Knight, and 18 others. 2026. When ai benchmarks plateau: A systematic stu...
Pith/arXiv arXiv 2026
-
[5]
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, Daniele Mazzotta, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo
-
[6]
The falcon series of open language models.Preprint, arXiv:2311.16867
-
[7]
Artificial Analysis. 2026. Independent analysis of ai models and hosting providers. https: //artificialanalysis.ai/. Accessed: 2026-05-01
2026
-
[8]
Elron Bandel, Yotam Perlitz, Elad Venezian, Roni Friedman, Ofir Arviv, Matan Orbach, Shachar Don-Yehiya, Dafna Sheinwald, Ariel Gera, Leshem Choshen, and 1 others. 2024. Unitxt: Flexible, shareable and reusable data preparation and evaluation for generative ai. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Com-...
2024
-
[9]
Elron Bandel, Asaf Yehudai, Lilach Eden, Yehoshua Sagron, Yotam Perlitz, Elad Venezian, Natalia Razinkov, Natan Ergas, Shlomit Shachor Ifergan, Segev Shlomov, Michal Jacovi, Leshem Choshen, Liat Ein-Dor, Yoav Katz, and Michal Shmueli-Scheuer. 2026. General agent evaluation.Preprint, arXiv:2602.22953
Pith/arXiv arXiv 2026
-
[10]
Elron Bandel, Asaf Yehudai, Alexandre Lacoste, Avijit Ghosh, Graham Neubig, Margaret Mitchell, Michal Shmueli-Scheuer, and Leshem Choshen. 2026. Agentic systems should be general.SSRN Electronic Journal
2026
-
[11]
Elron Bandel, Asaf Yehudai, and Michal Shmueli-Scheuer. 2026. Ready for general agents? let’s test it. InICLR Blogposts 2026. Https://iclr-blogposts.github.io/2026/blog/2026/general- agent-evaluation/
2026
-
[12]
Jan Batzner, Leshem Choshen, Sree Harsha Nelaturu, Damian Stachura, Anastassia Kornilova, Yanan Long, Usman Gohar, Andrew Tran, and Avijit Ghosh. 2026. Shared task of every eval ever: Building a unifying, standardized database of llm evaluations. Preprint
2026
-
[13]
Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Younes Belkada, and Thomas Wolf. 2023. Open LLM leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
2023
-
[14]
Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, Usvsn Sai Prashanth, Edward Raff, Aviya Skowron, Lintang Sutawika, and Oskar Van Der Wal. 2023. Pythia: A suite for analyzing large language models across training and scaling. InProceedings of the 40th Internat...
2023
-
[15]
Stella Biderman, Hailey Schoelkopf, Lintang Sutawika, Leo Gao, Jonathan Tow, Baber Abbasi, Alham Fikri Aji, Pawan Sasanka Ammanamanchi, Sidney Black, Jordan Clive, Anthony DiPofi, Julen Etxaniz, Benjamin Fattori, Jessica Zosa Forde, Charles Foster, Jeffrey Hsu, Mimansa Jaiswal, Wilson Y . Lee, Haonan Li, and 11 others. 2024. Lessons from the trenches on r...
Pith/arXiv arXiv 2024
-
[16]
Kathrin Blagec, Georg Dorffner, Milad Moradi, Mehrdad Alam, and Matthias Samwald. 2021. Are NLP benchmarks saturating?Preprint, arXiv:2105.13977
arXiv 2021
-
[17]
Florian Bordes, Candace Ross, Justine T Kao, Evangelia Spiliopoulou, and Adina Williams
-
[18]
Eval factsheets: A structured framework for documenting ai evaluations.Preprint, arXiv:2512.04062
-
[19]
Daniel Borkan, Lucas Dixon, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. 2019. Nuanced metrics for measuring unintended bias with real data for text classification.arXiv preprint arXiv:1903.04561
Pith/arXiv arXiv 2019
-
[20]
Bowman and George E
Samuel R. Bowman and George E. Dahl. 2021. What will it take to fix benchmarking in natural language understanding? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4843–4855, Online. Association for Computational Linguistics
2021
-
[21]
Ullman, Fernando Martinez-Plumed, Joshua B
Ryan Burnell, Wout Schellaert, John Burden, Tomer D. Ullman, Fernando Martinez-Plumed, Joshua B. Tenenbaum, Danaja Rutar, Lucy G. Cheke, Jascha Sohl-Dickstein, Melanie Mitchell, Douwe Kiela, Murray Shanahan, Ellen M. V oorhees, Anthony G. Cohn, Joel Z. Leibo, and Jose Hernandez-Orallo. 2023. Rethink reporting of evaluation results in AI.Science, 380(6641)...
2023
-
[22]
Gonzalez, Ion Stoica, and Eric P
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality
2023
-
[23]
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. 2018. QuAC: Question answering in context. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2174–2184. Association for Computational Linguistics. 11
2018
-
[24]
Leshem Choshen, Yang Zhang, and Jacob Andreas. 2025. A hitchhiker’s guide to scaling law estimation. InInternational Conference on Machine Learning, pages 10683–10699. PMLR
2025
-
[25]
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. 2019. BoolQ: Exploring the surprising difficulty of natural yes/no ques- tions. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short P...
2019
-
[26]
Peter Clark, Oyvind Tafjord, and Kyle Richardson. 2020. Transformers as soft reasoners over language. InProceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, pages 3882–3890
2020
-
[27]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems.Preprint, arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[28]
Epoch AI. 2026. About us: Making sense of ai. https://epoch.ai/about. Accessed: 2026-05-01
2026
-
[29]
Kawin Ethayarajh and Dan Jurafsky. 2020. Utility is in the eye of the user: A critique of NLP leaderboards. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 4846–4853, Online. Association for Computational Linguistics
2020
-
[30]
European Parliament and Council of the European Union. 2024. Regulation (EU) 2024/1689 of the European Parliament and of the Council: Artificial intelligence act.https://eur-lex. europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689
2024
-
[31]
Clémentine Fourrier, Nathan Habib, Julien Launay, and Thomas Wolf. 2023. What’s going on with the open LLM leaderboard? Hugging Face Blog
2023
-
[32]
Elias Frantar and Dan Alistarh. 2023. Sparsegpt: massive language models can be accurately pruned in one-shot. InProceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org
2023
-
[33]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2023. OPTQ: Accurate quantization for generative pre-trained transformers. InThe Eleventh International Conference on Learning Representations
2023
-
[34]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, and 5 others. 2023. A framework for few-shot language model evaluation
2023
-
[35]
Timnit Gebru, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé III, and Kate Crawford. 2021. Datasheets for datasets.Communications of the ACM, 64(12):86–92
2021
-
[36]
Avijit Ghosh, Yifan Mai, Georgia Channing, and Leshem Choshen. 2026. AI evals are becoming the new compute bottleneck. EvalEval Coalition Blog
2026
-
[37]
Eliya Habba, Ofir Arviv, Itay Itzhak, Yotam Perlitz, Elron Bandel, Leshem Choshen, Michal Shmueli-Scheuer, and Gabriel Stanovsky. 2025. Dove: A large-scale multi-dimensional predictions dataset towards meaningful llm evaluation. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11744–11763
2025
-
[38]
Eliya Habba, Itay Itzhak, Asaf Yehudai, Yotam Perlitz, Elron Bandel, Michal Shmueli-Scheuer, Leshem Choshen, and Gabriel Stanovsky. 2026. Growing pains: Extensible and efficient llm benchmarking via fixed parameter calibration.arXiv preprint arXiv:2604.12843
Pith/arXiv arXiv 2026
-
[39]
Shibo Hao, Zhining Zhang, Zhiqi Liang, Tianyang Liu, Yuheng Zha, Qiyue Gao, Jixuan Chen, Zilong Wang, Zhoujun Cheng, Haoxiang Zhang, Junli Wang, Hexi Jin, Boyuan Zheng, Kun Zhou, Yu Wang, Feng Yao, Licheng Liu, Yijiang Li, Zhifei Li, and 12 others. 2026. Cocoabench: Evaluating unified digital agents in the wild.Preprint, arXiv:2604.11201. 12
Pith/arXiv arXiv 2026
-
[40]
Harbor Framework Team. 2026. Harbor: A framework for evaluating and optimizing agents and models in container environments
2026
-
[41]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. InInternational Conference on Learning Representations
2021
-
[42]
Aris Hofmann, Inge Vejsbjerg, Dhaval Salwala, and Elizabeth M. Daly. 2025. Auto-benchmarkcard: Automated synthesis of benchmark documentation.Preprint, arXiv:2512.09577
arXiv 2025
-
[43]
Han Jiang, Susu Zhang, Xiaoyuan Yi, Xing Xie, and Ziang Xiao. 2026. Position: Science of ai evaluation requires item-level benchmark data.Preprint, arXiv:2604.03244
Pith/arXiv arXiv 2026
-
[44]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can language models resolve real-world github issues?Preprint, arXiv:2310.06770
Pith/arXiv arXiv 2024
-
[45]
Sayash Kapoor, Benedikt Stroebl, Peter Kirgis, Nitya Nadgir, Zachary S Siegel, Boyi Wei, Tianci Xue, Ziru Chen, Felix Chen, Saiteja Utpala, Franck Ndzomga, Dheeraj Oruganty, Sophie Luskin, Kangheng Liu, Botao Yu, Amit Arora, Dongyoon Hahm, Harsh Trivedi, Huan Sun, and 12 others. 2025. Holistic agent leaderboard: The missing infrastructure for ai agent eva...
arXiv 2025
-
[46]
Siegel, Nitya Nadgir, and Arvind Narayanan
Sayash Kapoor, Benedikt Stroebl, Zachary S. Siegel, Nitya Nadgir, and Arvind Narayanan
-
[47]
Ai agents that matter.Preprint, arXiv:2407.01502
-
[48]
Alex Kipnis, Konstantinos V oudouris, Luca M Schulze Buschoff, and Eric Schulz. 2024. metabench–a sparse benchmark of reasoning and knowledge in large language models.arXiv preprint arXiv:2407.12844
arXiv 2024
-
[49]
Tomáš Koˇciský, Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, Gábor Melis, and Edward Grefenstette. 2018. The NarrativeQA reading comprehension challenge. Transactions of the Association for Computational Linguistics, 6:317–328
2018
-
[50]
Hanna Köpcke, Andreas Thor, and Erhard Rahm. 2010. Evaluation of entity resolution approaches on real-world match problems.Proceedings of the VLDB Endowment, 3(1–2):484– 493
2010
-
[51]
give me bf16 or give me death
Eldar Kurtic, Alexandre Noll Marques, Shubhra Pandit, Mark Kurtz, and Dan Alistarh. 2025. “give me bf16 or give me death”? accuracy-performance trade-offs in llm quantization. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26872–26886
2025
-
[52]
Alexandre Lacoste, Nicolas Gontier, Oleh Shliazhko, Aman Jaiswal, Kusha Sareen, Shailesh Nanisetty, Joan Cabezas, Manuel Del Verme, Omar G. Younis, Simone Baratta, Matteo Avalle, Imene Kerboua, Xing Han Lù, Elron Bandel, Michal Shmueli-Scheuer, Asaf Yehudai, Leshem Choshen, Jonathan Lebensold, Sean Hughes, and 7 others. 2026. Cube: A standard for unifying...
arXiv 2026
-
[53]
John Patrick Lalor and Pedro Rodriguez. 2023. py-irt: A scalable item response theory library for python.INFORMS Journal on Computing, 35(1):5–13
2023
-
[54]
Peiyu Li, Xiuxiu Tang, Si Chen, Ying Cheng, Ronald Metoyer, Ting Hua, and Nitesh V . Chawla
-
[55]
Adaptive testing for llm evaluation: A psychometric alternative to static benchmarks. Preprint, arXiv:2511.04689
-
[56]
Hashimoto
Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. AlpacaEval: An automatic evaluator of instruction-following models. 13
2023
-
[57]
Manning, Christopher Ré, Diana Acosta-Navas, Drew Hudson, and 31 others
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, Benjamin Newman, Binhang Yuan, Bobby Yan, Ce Zhang, Christian Cosgrove, Christopher D. Manning, Christopher Ré, Diana Acosta-Navas, Drew Hudson, and 31 others. 2023. Holistic evaluation of language models.Trans...
2023
-
[58]
Thomas Liao, Rohan Taori, Inioluwa Deborah Raji, and Ludwig Schmidt. 2021. Are we learning yet? A meta review of evaluation failures across machine learning. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
-
[59]
Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. TruthfulQA: Measuring how models mimic human falsehoods. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252. Association for Computational Linguistics
2022
-
[60]
Jiarui Liu, Wenkai Li, Zhijing Jin, and Mona Diab. 2024. Automatic generation of model and data cards: A step towards responsible AI. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1975–1997, Mexico City, Mexico. Association for...
2024
-
[61]
Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoorthi, Vikas Chandra, Yuandong Tian, and Tijmen Blankevoort. 2025. Spinquant: Llm quantization with learned rotations.Preprint, arXiv:2405.16406
Pith/arXiv arXiv 2025
-
[62]
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantasti- cally ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098. Association for Computational Linguistics
2022
-
[63]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y . Ng, and Christo- pher Potts. 2011. Learning word vectors for sentiment analysis. InProceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pages 142–150. Association for Computational Linguistics
2011
-
[64]
Inbal Magar and Roy Schwartz. 2022. Data contamination: From memorization to exploitation. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 157–165. Association for Computational Linguistics
2022
-
[65]
Yinan Mei, Shaoxu Song, Chenguang Fang, Haifeng Yang, Jingyun Fang, and Jiang Long
-
[66]
In2021 IEEE 37th International Conference on Data Engineering (ICDE), pages 61–72
Capturing semantics for imputation with pre-trained language models. In2021 IEEE 37th International Conference on Data Engineering (ICDE), pages 61–72. IEEE
-
[67]
Guangyu Meng, Qinkai Zeng, John P Lalor, and Hong Yu. 2025. A psychology-based unified dynamic framework for curriculum learning.Computational Linguistics, pages 1–49
2025
-
[68]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer sentinel mixture models.Preprint, arXiv:1609.07843
Pith/arXiv arXiv 2016
-
[69]
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, and 66 others. 2026. Terminal-bench: Benchmarking agents on hard, re...
Pith/arXiv arXiv 2026
-
[70]
METR. 2026. Time horizon 1.1. https://metr.org/blog/ 2026-1-29-time-horizon-1-1/
2026
-
[71]
James A Michaelov, Catherine Arnett, Tyler A Chang, Pamela D Rivière, Samuel M Taylor, Cameron R Jones, Sean Trott, Roger P Levy, Benjamin K Bergen, and Micah Altman. 2026. How open must language models be to enable reliable scientific inference?arXiv preprint arXiv:2603.26539. 14
Pith/arXiv arXiv 2026
-
[72]
Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model cards for model reporting. InProceedings of the Conference on Fairness, Accountability, and Transparency, pages 220–229. Association for Computing Machinery
2019
-
[73]
Colin Murphy and Chang Liu. 2025. Ai-assisted wordle demo: Combining llms and rule-based solvers for enhanced gameplay. In2025 IEEE Conference on Games (CoG), pages 1–2. IEEE
2025
-
[74]
Sree Harsha Nelaturu, Nishaanth Kanna Ravichandran, Cuong Tran, Sara Hooker, and Fer- dinando Fioretto. 2024. On the fairness impacts of hardware selection in machine learning. Proceedings of the 41st International Conference on Machine Learning (ICML)
2024
-
[75]
Yotam Perlitz, Elron Bandel, Ariel Gera, Ofir Arviv, Liat Ein-Dor, Eyal Shnarch, Noam Slonim, Michal Shmueli-Scheuer, and Leshem Choshen. 2024. Efficient benchmarking (of language models). InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)...
2024
-
[76]
Fabio Petroni, Tim Rocktäschel, Sebastian Riedel, Patrick Lewis, Anton Bakhtin, Yuxiang Wu, and Alexander Miller. 2019. Language models as knowledge bases? InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th Interna- tional Joint Conference on Natural Language Processing, pages 2463–2473. Association for Co...
2019
-
[77]
Felipe M Polo, Ronald Xu, Lucas Weber, Mírian Silva, Onkar Bhardwaj, Leshem Choshen, Allysson F de Oliveira, Yuekai Sun, and Mikhail Yurochkin. 2024. Efficient multi-prompt evaluation of llms.Advances in Neural Information Processing Systems, 37:22483–22512
2024
-
[78]
Felipe Maia Polo, Leshem Choshen, Yuekai Sun, and Kristjan Greenewald. 2025. A statistical framework for game-based ai evaluation. InNeurIPS 2025 Workshop on Evaluating the Evolving LLM Lifecycle: Benchmarks, Emergent Abilities, and Scaling
2025
-
[79]
Felipe Maia Polo, Lucas Weber, Leshem Choshen, Yuekai Sun, Gongjun Xu, and Mikhail Yurochkin. 2024. tinybenchmarks: evaluating llms with fewer examples.Preprint, arXiv:2402.14992
arXiv 2024
-
[80]
Bender, Alex Hanna, and Amandalynne Paullada
Inioluwa Deborah Raji, Emily Denton, Emily M. Bender, Alex Hanna, and Amandalynne Paullada. 2021. AI and the everything in the whole wide world benchmark. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.