Dual-Granularity Orthogonal Disentanglement for Generalizable Audio Deepfake Detection
Pith reviewed 2026-06-27 03:08 UTC · model grok-4.3
The pith
Enforcing sample-level and batch-level orthogonality disentangles speaker identity from synthesis artifacts in audio deepfake detectors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a dual-granularity orthogonal disentanglement framework, consisting of sample-level cosine orthogonality and batch-level cross-covariance regularization applied under a progressive curriculum schedule, removes implicit speaker-identity leakage from the learned embeddings while preserving synthesis-artifact cues, thereby improving cross-dataset generalization in audio deepfake detection without auxiliary networks or adversarial training dynamics.
What carries the argument
Dual-granularity orthogonal disentanglement, which combines per-sample cosine orthogonality for directional decorrelation with per-batch cross-covariance regularization to eliminate linear correlations, scheduled by a curriculum that gradually strengthens the constraints.
If this is right
- The method reports equal error rates of 1.35 percent on ASVspoof 2019 LA, 7.88 percent on ASVspoof 2021 DF, and 21.58 percent on In-the-Wild data.
- It improves absolute cross-dataset transfer by 2.60 percent over gradient reversal disentanglement baselines.
- No auxiliary networks or adversarial losses are required to achieve the reported separation of identity and artifact features.
- The curriculum schedule allows the orthogonality constraints to be introduced without destabilizing early training.
Where Pith is reading between the lines
- The same two-level orthogonality pattern could be tested on image or video deepfake detectors where identity leakage is also observed.
- If the batch-level covariance term proves critical, it suggests that linear decorrelation across dimensions is a practical surrogate for full statistical independence in embedding spaces.
- The curriculum mechanism might transfer to other regularization tasks that need to avoid early over-constraining of the model.
Load-bearing premise
Enforcing orthogonality between embeddings will separate speaker identity information from synthesis artifact cues without discarding information needed for accurate detection.
What would settle it
Train the model on data where speaker identity is deliberately made predictive of the fake label, then measure whether equal error rate rises sharply on a test set where speaker identity and label are uncorrelated.
Figures

read the original abstract
Audio deepfake detectors often fail to generalize across speakers, as they learn speaker-identity features rather than synthesis artifacts, known as implicit identity leakage. Existing methods address this but incur architectural complexity or training instability. This paper proposes a dual-granularity orthogonal disentanglement framework enforcing feature independence at two levels: sample-level cosine orthogonality captures directional decorrelation, while batch-level cross-covariance regularization eliminates linear correlations across embedding dimensions. A curriculum disentanglement schedule progressively strengthens the orthogonality constraint without auxiliary networks or adversarial dynamics. Experiments on ASVspoof 2019 LA, ASVspoof 2021 DF, and In-the-Wild datasets demonstrate that the proposed method achieves 1.35%, 7.88%, and 21.58% equal error rates (EER), respectively, surpassing gradient reversal disentanglement by 2.60% absolute on cross-dataset transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a dual-granularity orthogonal disentanglement framework for audio deepfake detection to address implicit identity leakage. It enforces feature independence via sample-level cosine orthogonality and batch-level cross-covariance regularization, combined with a curriculum disentanglement schedule that progressively strengthens the constraint without auxiliary networks or adversarial training. Experiments report EERs of 1.35% on ASVspoof 2019 LA, 7.88% on ASVspoof 2021 DF, and 21.58% on In-the-Wild, with a 2.60% absolute improvement over gradient reversal disentanglement on cross-dataset transfer.
Significance. If the orthogonality terms demonstrably separate speaker identity from synthesis artifacts, the approach would provide a simpler, more stable alternative to adversarial disentanglement methods for improving generalization in audio deepfake detection. The curriculum schedule is a constructive design element that may aid training stability, and the multi-dataset EER reporting supplies concrete benchmarks.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments: The central claim that sample-level cosine orthogonality plus batch-level cross-covariance regularization removes speaker-identity information while retaining synthesis-artifact cues is load-bearing for the reported EER gains, yet the manuscript supplies only downstream EER numbers and the 2.60% cross-dataset improvement. No auxiliary metrics (speaker-ID accuracy on embeddings, mutual information estimates, or controlled ablations isolating the orthogonality terms) are presented to confirm the intended separation occurred rather than generic regularization effects.
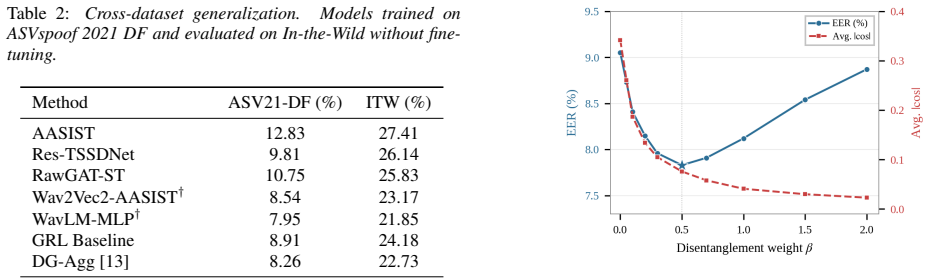
- [Method] Method (curriculum disentanglement schedule): The progressive strengthening of the orthogonality constraint is described as key to avoiding training instability, but no sensitivity analysis, ablation on schedule hyperparameters, or examination of the resulting identity-artifact trade-off is provided. This directly affects interpretability of the cross-dataset EER results.
minor comments (1)
- [Method] Notation in the batch-level cross-covariance term should be expanded with an explicit equation to support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will incorporate revisions to strengthen the evidence for our claims.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments: The central claim that sample-level cosine orthogonality plus batch-level cross-covariance regularization removes speaker-identity information while retaining synthesis-artifact cues is load-bearing for the reported EER gains, yet the manuscript supplies only downstream EER numbers and the 2.60% cross-dataset improvement. No auxiliary metrics (speaker-ID accuracy on embeddings, mutual information estimates, or controlled ablations isolating the orthogonality terms) are presented to confirm the intended separation occurred rather than generic regularization effects.
Authors: We agree that auxiliary metrics would provide more direct confirmation that the orthogonality terms achieve the intended separation rather than acting as generic regularization. The 2.60% cross-dataset gain over gradient reversal (which uses a comparable adversarial mechanism) offers indirect support, but this does not fully isolate the contribution of our dual-granularity terms. In the revised manuscript we will add speaker identification accuracy on the learned embeddings and controlled ablations that isolate the sample-level cosine and batch-level cross-covariance terms. revision: yes
-
Referee: [Method] Method (curriculum disentanglement schedule): The progressive strengthening of the orthogonality constraint is described as key to avoiding training instability, but no sensitivity analysis, ablation on schedule hyperparameters, or examination of the resulting identity-artifact trade-off is provided. This directly affects interpretability of the cross-dataset EER results.
Authors: The curriculum schedule was introduced to gradually ramp up the orthogonality constraint and thereby improve training stability without auxiliary networks. We acknowledge that the original submission lacks sensitivity analysis on its hyperparameters and does not quantify any identity-artifact trade-off. In revision we will add ablations varying the starting epoch and ramp rate, together with the resulting EERs and any observed changes in embedding properties. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks are independent of internal definitions
full rationale
The paper introduces a dual-granularity orthogonal disentanglement method with sample-level cosine orthogonality and batch-level cross-covariance regularization, trained via a curriculum schedule, then reports EER numbers on the external ASVspoof 2019 LA, ASVspoof 2021 DF, and In-the-Wild datasets. These performance figures are obtained by standard supervised training and evaluation on public benchmarks; they do not reduce to any fitted parameter that is later renamed as a prediction, nor to any self-citation chain that supplies the uniqueness or correctness of the orthogonality constraints. No equations or claims in the provided text equate the target separation of speaker identity from synthesis artifacts to the orthogonality terms by construction. The derivation chain therefore remains self-contained against external data rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Advances in voice conversion [1, 2] and text-to-speech [3, 4] have enabled highly realistic synthetic speech, threatening speaker verification systems and enabling fraud and misinfor- mation. While state-of-the-art detectors achieve below 2% equal error rates (EER) on ASVspoof 2019 LA [5, 6, 7], per- formance degrades to over 20% EER on real-...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Problem Formulation LetX∈R F×T denote the log-mel spectrogram of an input utterance withFmel frequency bins andTtime frames
Proposed Method 2.1. Problem Formulation LetX∈R F×T denote the log-mel spectrogram of an input utterance withFmel frequency bins andTtime frames. Given a labeled training setD={(X i, yi, si)}N i=1, wherey i ∈ {0,1} indicates spoofed or bonafide ands i ∈ {1, . . . , K}denotes speaker identity, the goal of this paper is to learn a detector that generalizes ...
-
[3]
The training set contains 22,617 bonafide and 22,296 spoofed utterances from 107 speakers
Experimental Setup We evaluate on ASVspoof 2021 DF [34], which contains bonafide speech and spoofed samples from over 100 differ- ent synthesis systems including VCC2018 and VCC2020 voice conversion submissions. The training set contains 22,617 bonafide and 22,296 spoofed utterances from 107 speakers. For cross-dataset evaluation, we test models trained o...
2021
-
[4]
In-Domain Detection Table 1 presents detection performance on ASVspoof 2019 LA and 2021 DF
Results and Discussion 4.1. In-Domain Detection Table 1 presents detection performance on ASVspoof 2019 LA and 2021 DF. On ASVspoof 2019 LA, the proposed method achieves 1.35% EER, ranking second among non-pretrained methods behind AASIST (0.83%), which benefits from graph- based spectro-temporal modeling optimized for in-domain con- ditions. The proposed...
2019
-
[5]
Conclusion This paper presented a dual-granularity orthogonal disentangle- ment framework combining sample-level cosine orthogonality with batch-level cross-covariance regularization under a cur- riculum schedule, enforcing speaker-artifact separation with- out auxiliary networks or adversarial training. This lightweight approach (2.1M parameters) achieve...
-
[6]
All scientific content, experimental design, implementa- tion, analysis, and conclusions are the sole work of the authors
Generative AI Use Disclosure Generative AI tools were used for English language polish- ing and LATEX formatting assistance during manuscript prepa- ration. All scientific content, experimental design, implementa- tion, analysis, and conclusions are the sole work of the authors
-
[7]
An overview of voice conversion and its challenges: From statistical modeling to deep learning,
B. Sisman, J. Yamagishi, S. King, and H. Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 132–157, Nov. 2021
2021
-
[8]
Any- to-many voice conversion with location-relative sequence-to- sequence modeling,
S. Liu, Y . Cao, D. Wang, X. Wu, X. Liu, and H. Meng, “Any- to-many voice conversion with location-relative sequence-to- sequence modeling,”IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 29, pp. 1717–1728, Apr. 2021
2021
-
[9]
Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,
E. Casanovaet al., “Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone,” inInternational Conference on Machine Learning, Baltimore, MD, USA, 2022, pp. 2709–2720
2022
-
[10]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Y . Renet al., “Fastspeech 2: Fast and high-quality end-to-end text to speech,” inInternational Conference on Learning Representa- tions, Virtual, May 2021
2021
-
[11]
Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,
J.-w. Junget al., “Aasist: Audio anti-spoofing using integrated spectro-temporal graph attention networks,” inIEEE Interna- tional Conference on Acoustics, Speech and Signal Processing, Singapore, 2022, pp. 6367–6371
2022
-
[12]
End-to-end anti-spoofing with rawnet2,
H. Tak, J. Patino, M. Todisco, A. Nautsch, N. Evans, and A. Larcher, “End-to-end anti-spoofing with rawnet2,” inIEEE In- ternational Conference on Acoustics, Speech and Signal Process- ing, Toronto, ON, Canada, 2021, pp. 6369–6373
2021
-
[13]
Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,
X. Wanget al., “Asvspoof 2019: A large-scale public database of synthesized, converted and replayed speech,”Computer Speech & Language, vol. 64, p. 101114, Nov. 2020
2019
-
[14]
Does audio deepfake detection generalize?
N. M. M ¨ulleret al., “Does audio deepfake detection generalize?” inInterspeech, Incheon, Korea, 2022, pp. 2783–2787
2022
-
[15]
Towards generalisable and calibrated audio deepfake detection with self- supervised representations,
O. Pascu, A. Stan, D. Oneat ¸˘a, E. Oneata, and H. Cucu, “Towards generalisable and calibrated audio deepfake detection with self- supervised representations,” inInterspeech, Kos Island, Greece, 2024, pp. 4828–4832
2024
-
[16]
Beyond identity: A generalizable approach for deepfake audio detection,
Y . Ahmadiadli, X.-P. Zhang, and N. M. Khan, “Beyond identity: A generalizable approach for deepfake audio detection,” 2025, [Online]. Available: https://arxiv.org/abs/2505.06766
-
[17]
Audio deepfake detection: A survey,
J. Yi, C. Wang, J. Tao, X. Zhang, C. Y . Zhang, and Y . Zhao, “Audio deepfake detection: A survey,” 2023, [Online]. Available: https://arxiv.org/abs/2308.14970
-
[18]
Spoofing-aware speaker verification with un- supervised domain adaptation,
X. Wanget al., “Spoofing-aware speaker verification with un- supervised domain adaptation,” inIEEE International Confer- ence on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 2023, pp. 1–5
2023
-
[19]
Domain generalization via aggregation and separation for audio deepfake detection,
Y . Xie, H. Cheng, Y . Wang, and L. Ye, “Domain generalization via aggregation and separation for audio deepfake detection,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 344–358, 2024
2024
-
[20]
ASVspoof 5: Design, collection and validation of resources for spoofing, deepfake, and adversarial attack detec- tion using crowdsourced speech,
X. Wanget al., “ASVspoof 5: Design, collection and validation of resources for spoofing, deepfake, and adversarial attack detec- tion using crowdsourced speech,”Computer Speech & Language, vol. 95, p. 101825, Jan. 2026
2026
-
[21]
A comparison of features for synthetic speech detection,
M. Sahidullah, T. Kinnunen, and C. Hanilci, “A comparison of features for synthetic speech detection,” inInterspeech, Dresden, Germany, 2015, pp. 2087–2091
2015
-
[22]
wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representa- tions,” inAdvances in Neural Information Processing Systems, vol. 33, Virtual, Dec. 2020, pp. 12 449–12 460
2020
-
[23]
Vicomtech audio deepfake detection system based on wav2vec 2.0 for the 2022 add chal- lenge,
J. M. Martin-Donas and A. Alvarez, “Vicomtech audio deepfake detection system based on wav2vec 2.0 for the 2022 add chal- lenge,” inIEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 2022, pp. 9241–9245
2022
-
[24]
Automatic speaker verification spoofing and deep- fake detection using wav2vec 2.0 and data augmentation,
H. Taket al., “Automatic speaker verification spoofing and deep- fake detection using wav2vec 2.0 and data augmentation,” inThe Speaker and Language Recognition Workshop (Odyssey), Beijing, China, 2022, pp. 112–119
2022
-
[25]
Attentive merging of hidden embeddings from pre- trained speech model for anti-spoofing detection,
Z. Panet al., “Attentive merging of hidden embeddings from pre- trained speech model for anti-spoofing detection,” inInterspeech, Kos Island, Greece, 2024, pp. 2090–2094
2024
-
[26]
Nes2net: A lightweight nested architecture for foundation model driven speech anti-spoofing,
T. Liu, D.-T. Truong, R. K. Das, K. A. Lee, and H. Li, “Nes2net: A lightweight nested architecture for foundation model driven speech anti-spoofing,”IEEE Transactions on Information Foren- sics and Security, vol. 20, pp. 12 005–12 018, Oct. 2025
2025
-
[27]
X-vectors: Robust dnn embeddings for speaker recognition,
D. Snyder, D. Garcia-Romero, G. Sell, D. Povey, and S. Khudan- pur, “X-vectors: Robust dnn embeddings for speaker recognition,” inIEEE International Conference on Acoustics, Speech and Sig- nal Processing, Calgary, AB, Canada, 2018, pp. 5329–5333
2018
-
[28]
Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “Ecapa-tdnn: Emphasized channel attention, propagation and aggregation in tdnn based speaker verification,” inInterspeech, Shanghai, China, 2020, pp. 3830–3834
2020
-
[29]
Un- masking real-world audio deepfakes: A data-centric approach,
D. Combei, A. Stan, D. Oneat ¸ ˘a, N. M ¨uller, and H. Cucu, “Un- masking real-world audio deepfakes: A data-centric approach,” in Interspeech, Rotterdam, Netherlands, Aug. 2025, pp. 5343–5347
2025
-
[30]
Domain- adversarial training of neural networks,
Y . Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, and V . Lempitsky, “Domain- adversarial training of neural networks,”Journal of Machine Learning Research, vol. 17, no. 59, pp. 1–35, 2016
2016
-
[31]
Representation learning: A review and new perspectives,
Y . Bengio, A. Courville, and P. Vincent, “Representation learning: A review and new perspectives,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 8, pp. 1798–1828, Aug. 2013
2013
-
[32]
Alden: Dual-level disentanglement with meta- learning for generalizable audio deepfake detection,
Y . Xuet al., “Alden: Dual-level disentanglement with meta- learning for generalizable audio deepfake detection,” inProceed- ings of the 33rd ACM International Conference on Multimedia, ser. MM ’25. New York, NY , USA: Association for Computing Machinery, oct 2025, pp. 7277–7286
2025
-
[33]
Safeear: Con- tent privacy-preserving audio deepfake detection,
X. Li, K. Li, Y . Zheng, C. Yan, X. Ji, and W. Xu, “Safeear: Con- tent privacy-preserving audio deepfake detection,” inACM Con- ference on Computer and Communications Security, Salt Lake City, UT, USA, 2024, pp. 3585–3599
2024
-
[34]
Towards the next frontier in speech representation learning using disentanglement,
V . Krishna and S. Ganapathy, “Towards the next frontier in speech representation learning using disentanglement,” 2024, [Online]. Available: https://arxiv.org/abs/2407.02543
-
[35]
ContentVec: An improved self-supervised speech representation by disentangling speakers,
K. Qianet al., “ContentVec: An improved self-supervised speech representation by disentangling speakers,” inInternational Con- ference on Machine Learning, Baltimore, MD, USA, 2022, pp. 18 003–18 017
2022
-
[36]
Speaker anonymization using orthogonal Householder neural network,
X. Miao, X. Wang, E. Cooper, J. Yamagishi, and N. Tomashenko, “Speaker anonymization using orthogonal Householder neural network,”IEEE/ACM Transactions on Audio, Speech, and Lan- guage Processing, vol. 31, pp. 3681–3695, Sep. 2023
2023
-
[37]
Speech emo- tion recognition with co-attention based multi-level acoustic infor- mation,
H. Zou, Y . Si, C. Chen, D. Rajan, and E. S. Chng, “Speech emo- tion recognition with co-attention based multi-level acoustic infor- mation,” inIEEE International Conference on Acoustics, Speech and Signal Processing, Singapore, 2022, pp. 7367–7371
2022
-
[38]
Disentangling spoof trace for generic face anti-spoofing,
Y . Liu, J. Stehouwer, A. Jourabloo, and X. Liu, “Disentangling spoof trace for generic face anti-spoofing,” inIEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, Seattle, W A, USA, 2020, pp. 8765–8775
2020
-
[39]
Barlow twins: Self-supervised learning via redundancy reduction,
J. Zbontar, L. Jing, I. Misra, Y . LeCun, and S. Deny, “Barlow twins: Self-supervised learning via redundancy reduction,” inIn- ternational Conference on Machine Learning, Virtual, Jul. 2021, pp. 12 310–12 320
2021
-
[40]
ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,
J. Yamagishiet al., “ASVspoof 2021: accelerating progress in spoofed and deepfake speech detection,” inProc. 2021 Edition of the Automatic Speaker Verification and Spoofing Countermea- sures Challenge, 2021, pp. 47–54
2021
-
[41]
Arcface: Additive angular margin loss for deep face recognition,
J. Deng, J. Guo, N. Xue, and S. Zafeiriou, “Arcface: Additive angular margin loss for deep face recognition,” inIEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 2019, pp. 4690–4699
2019
-
[42]
Stc antispoofing systems for the asvspoof 2019 challenge,
G. Lavrentyevaet al., “Stc antispoofing systems for the asvspoof 2019 challenge,” inInterspeech, Graz, Austria, 2019, pp. 1033– 1037
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.