VISTA: Scale-Aware Visual Navigation via Action History Conditioning
Pith reviewed 2026-06-27 02:51 UTC · model grok-4.3
The pith
Conditioning visual navigation models on normalized action histories resolves physical geometry mismatches caused by different scaling factors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VISTA shows that conditioning navigation policies on sequences of normalized past actions resolves the geometry mismatch that arises when different scaling factors are applied to the same normalized trajectory. Pairing this conditioning with a DINOv3 encoder supplies richer representations that capture spatial and geometric relations between observations. The approach yields robust zero-shot generalization, with full goal prediction accuracy and consistent path following across diverse unseen real-world settings.
What carries the argument
Conditioning the policy on normalized action history sequences together with current image observations, using a DINOv3 visual encoder.
If this is right
- Navigation performance remains consistent when the same model is deployed on robots with different speeds or sizes.
- Collision risk drops because predicted trajectories preserve their physical geometry under scaling.
- The model follows paths reliably through visually repetitive environments without distinct landmarks.
- Zero-shot transfer succeeds across outdoor, forest, and office settings without retraining.
Where Pith is reading between the lines
- The same conditioning pattern could be tested on other normalized output tasks such as manipulation or locomotion.
- A single trained model might control multiple robot embodiments by relying on action history to infer scale.
- Adding histories from additional sensors could further strengthen context in ambiguous environments.
Load-bearing premise
That sequences of normalized past actions supply enough explicit context to correct for changes in physical geometry from different scaling factors.
What would settle it
A zero-shot deployment test with a new scaling factor where the model produces collisions or misses goals despite receiving action history conditioning would show the approach fails to resolve the geometry mismatch.
Figures

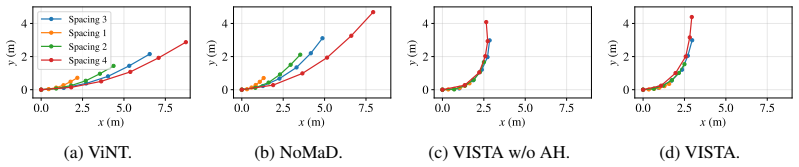
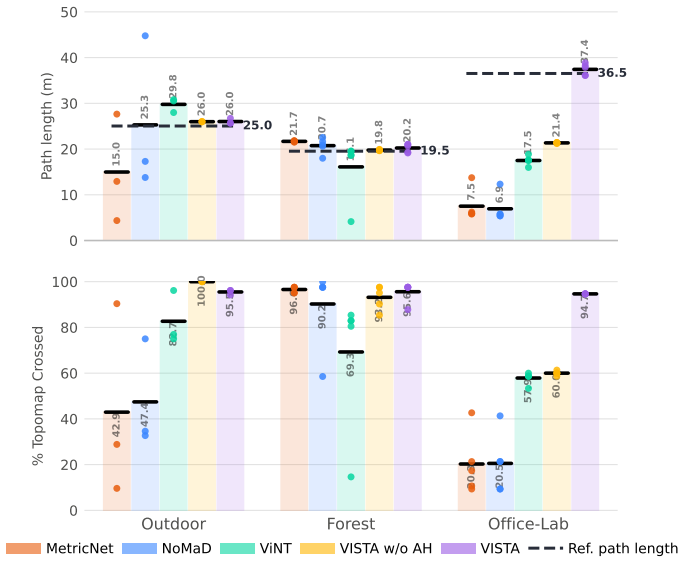














read the original abstract
Vision Navigation Foundation Models (VNMs) promise end-to-end learned navigation policies capable of zero-shot deployment across diverse embodiments and environments. To maintain generality, many vision-based navigation models predict normalized actions. However, this normalization introduces a critical deployment vulnerability: applying different scaling factors to the same normalized trajectory alters its physical geometry, which degrades navigation performance and increases collision risks. We address this vulnerability by conditioning the model on normalized action histories alongside image observations, providing explicit context on the relationship between the model's predictions and the robot's actual physical displacement. Furthermore, current VNMs often struggle in visually repetitive environments that lack distinct features. To resolve this issue, we integrate a DINOv3 encoder, whose richer representations enable our model to capture both spatial and geometric dimensions between observations. VISTA generalizes robustly to out-of-distribution environments, achieving 100% goal prediction accuracy in zero-shot, real-world deployment in Outdoor, Forest and Office settings, and an average of 95% checkpoints crossed, demonstrating consistent path following in unseen environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VISTA, a vision-based navigation model that conditions policies on normalized action histories (in addition to image observations) to mitigate geometry distortion from action scaling, and integrates a DINOv3 encoder to improve feature richness in repetitive scenes. It reports 100% goal-prediction accuracy and 95% average checkpoint success in zero-shot real-world tests across Outdoor, Forest, and Office environments, claiming robust generalization to out-of-distribution settings.
Significance. If the empirical claims are substantiated with proper controls, the work would address a concrete deployment vulnerability in normalized-action VNMs and demonstrate a practical way to inject scale context without sacrificing end-to-end learning. The combination of action-history conditioning and DINOv3 representations is a targeted, testable idea that could influence subsequent foundation-model navigation work.
major comments (3)
- [Abstract / Results] Abstract and results sections: the central performance numbers (100% goal accuracy, 95% checkpoints crossed) are stated without any baseline comparisons, ablation studies, error bars, or environment/dataset statistics. This directly undermines evaluation of whether action-history conditioning actually resolves the claimed scale mismatch, as required by the soundness criterion.
- [Methods] Methods: no explicit description or equation is given for how the normalized action history is encoded and fused with visual features, nor any analysis showing that this conditioning supplies sufficient geometric context to counteract different scaling factors. The claim that this resolves the physical-geometry vulnerability therefore rests on an unverified assumption.
- [Experiments] Experiments: the zero-shot real-world deployments are presented without details on robot embodiment, exact scaling factors tested, number of trials, or failure modes, making it impossible to assess whether the reported success rates generalize or are environment-specific.
minor comments (2)
- [Notation] Notation for normalized actions and history length should be defined consistently in the main text and any equations.
- [Figures] Figure captions for deployment trajectories should include scale bars or metric overlays to illustrate the claimed geometry preservation.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us identify areas for improvement in the manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: Abstract and results sections: the central performance numbers (100% goal accuracy, 95% checkpoints crossed) are stated without any baseline comparisons, ablation studies, error bars, or environment/dataset statistics. This directly undermines evaluation of whether action-history conditioning actually resolves the claimed scale mismatch, as required by the soundness criterion.
Authors: We agree with this observation. The current presentation of results in the abstract and main text lacks these elements. We will revise the manuscript to include baseline comparisons (e.g., against models without action history conditioning), ablation studies on the contribution of each component, error bars from repeated trials, and statistics on the environments and datasets used. This will better demonstrate the effectiveness of the proposed approach. revision: yes
-
Referee: Methods: no explicit description or equation is given for how the normalized action history is encoded and fused with visual features, nor any analysis showing that this conditioning supplies sufficient geometric context to counteract different scaling factors. The claim that this resolves the physical-geometry vulnerability therefore rests on an unverified assumption.
Authors: We acknowledge that the methods section would be strengthened by a more formal description. We will add a detailed explanation, including mathematical formulations for the encoding of the normalized action history and its fusion mechanism with the visual features from DINOv3. We will also include an analysis or additional experiments showing how this provides the necessary geometric context for different scaling factors. revision: yes
-
Referee: Experiments: the zero-shot real-world deployments are presented without details on robot embodiment, exact scaling factors tested, number of trials, or failure modes, making it impossible to assess whether the reported success rates generalize or are environment-specific.
Authors: We agree that these details are important for evaluating the claims. In the revised version, we will provide comprehensive information on the robot embodiment used, the specific scaling factors tested in the experiments, the number of trials performed in each environment, and a breakdown of failure modes observed during the deployments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present an empirical method for visual navigation (conditioning on action histories and using a DINOv3 encoder) followed by zero-shot deployment results. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems are referenced that would reduce any claim to its inputs by construction. Performance metrics (100% goal accuracy, 95% checkpoints) are external empirical outcomes, not derived quantities. The paper is self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Walke, K
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V . Myers, K. Fang, C. Finn, and S. Levine. BridgeData V2: A Dataset for Robot Learning at Scale. InConf. on Robot Learning (CoRL), 2023
2023
-
[2]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
Pith/arXiv arXiv 2025
-
[3]
D. Shah, A. Sridhar, N. Dashora, K. Stachowicz, K. Black, N. Hirose, and S. Levine. ViNT: A Foundation Model for Visual Navigation. InConf. on Robot Learning (CoRL), 2023
2023
-
[4]
Sridhar, D
A. Sridhar, D. Shah, C. Glossop, and S. Levine. NoMaD: Goal Masked Diffusion Policies for Navigation and Exploration. InInt. Conf. on Robotics and Automation (ICRA), 2024
2024
- [5]
-
[6]
M. Guerrier, K. Soma, J. Pavlasek, and G. Beltrame. Can vision foundation models navigate? zero-shot real-world evaluation and lessons learned, 2026. URLhttps://arxiv.org/abs/ 2603.25937
Pith/arXiv arXiv 2026
-
[7]
D. Shah, A. Sridhar, A. Bhorkar, N. Hirose, and S. Levine. GNM: A General Navigation Model to Drive Any Robot. InInt. Conf. on Robotics and Automation (ICRA), 2023
2023
-
[8]
Y . Qiao, W. Lyu, H. Wang, Z. Wang, Z. Li, Y . Zhang, M. Tan, and Q. Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. In 2025 IEEE International Conference on Robotics and Automation (ICRA), pages 6710–6717,
2025
-
[9]
doi:10.1109/ICRA55743.2025.11127584
-
[10]
C. Wen, Y . Huang, H. Huang, Y . Huang, S. Yuan, Y . Hao, H. Lin, Y .-S. Liu, and Y . Fang. Zero-shot object navigation with vision-language models reasoning. In A. Antonacopoulos, S. Chaudhuri, R. Chellappa, C.-L. Liu, S. Bhattacharya, and U. Pal, editors,Pattern Recogni- tion, pages 389–404, Cham, 2025. Springer Nature Switzerland. ISBN 978-3-031-78456-9
2025
-
[11]
H. Yin, X. Xu, L. Zhao, Z. Wang, J. Zhou, and J. Lu. Unigoal: Towards universal zero-shot goal-oriented navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 19057–19066, June 2025
2025
-
[12]
Z. Wang, J. Hu, Q. Tang, and W. Gao. COAL: Robust Contrastive Learning-Based Visual Navigation Framework.Journal of Field Robotics, 42(5):2028–2041, 2025. doi:https://doi. org/10.1002/rob.22508. URLhttps://onlinelibrary.wiley.com/doi/abs/10.1002/ rob.22508
-
[13]
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y . LeCun. Navigation World Models. InConf. on Comp. Vision and Pattern Rec. (CVPR), 2025. 9
2025
-
[14]
H. Wang, A. H. Tan, and G. Nejat. NavFormer: A transformer architecture for robot target- driven navigation in unknown and dynamic environments.Robotics and Automation Letters,
-
[15]
doi:10.1109/LRA.2024.3412638
-
[16]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine. Octo: An Open-Source Generalist Robot Policy. InRobotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[17]
Bharadhwaj, J
H. Bharadhwaj, J. Vakil, M. Sharma, A. Gupta, S. Tulsiani, and V . Kumar. RoboAgent: Gener- alization and efficiency in robot manipulation via semantic augmentations and action chunking. InInt. Conf. on Robotics and Automation (ICRA), 2024
2024
-
[18]
Tan and Q
M. Tan and Q. Le. Efficientnet: Rethinking model scaling for convolutional neural networks. InInt. Conf. on Machine Learning (ICML), 2019
2019
-
[19]
J. Kim, J. Sim, W. Kim, K. P. Sycara, and C. Nam. CARE: Enhancing Safety of Visual Navigation through Collision Avoidance via Repulsive Estimation. InConf. on Robot Learning (CoRL), 2025
2025
-
[20]
Y . Zeng, H. Ren, S. Wang, J. Huang, and H. Cheng. Navidiffusor: Cost-guided diffusion model for visual navigation. InInt. Conf. on Robotics and Automation (ICRA), 2025
2025
-
[21]
W. Cai, J. Peng, Y . Yang, Y . Zhang, M. Wei, H. Wang, Y . Chen, T. Wang, and J. Pang. Navdp: Learning sim-to-real navigation diffusion policy with privileged information guidance, 2025. URLhttps://arxiv.org/abs/2505.08712
arXiv 2025
-
[22]
O. Sim ´eoni, H. V . V o, M. Seitzer, F. Baldassarre, M. Oquab, C. Jose, V . Khalidov, M. Szafraniec, S. Yi, M. Ramamonjisoa, F. Massa, D. Haziza, L. Wehrstedt, J. Wang, T. Darcet, T. Moutakanni, L. Sentana, C. Roberts, A. Vedaldi, J. Tolan, J. Brandt, C. Cou- prie, J. Mairal, H. J ´egou, P. Labatut, and P. Bojanowski. Dinov3, 2025. URLhttps: //arxiv.org/...
Pith/arXiv arXiv 2025
-
[23]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[24]
Hirose, F
N. Hirose, F. Xia, R. Mart´ın-Mart´ın, A. Sadeghian, and S. Savarese. Deep Visual MPC-Policy Learning for Navigation.Robotics and Automation Letters, 2019
2019
-
[25]
D. Shah, B. Eysenbach, N. Rhinehart, and S. Levine. Rapid Exploration for Open-World Navigation with Latent Goal Models. InConf. on Robot Learning (CoRL), 2021
2021
-
[26]
N. Hirose, D. Shah, A. Sridhar, and S. Levine. SACSoN: Scalable Autonomous Control for Social Navigation.Robotics and Automation Letters, 2024. doi:10.1109/LRA.2023.3329626
-
[27]
Karnan, A
H. Karnan, A. Nair, X. Xiao, G. Warnell, S. Pirk, A. Toshev, J. Hart, J. Biswas, and P. Stone. Socially CompliAnt Navigation Dataset (SCAND): A Large-Scale Dataset of Demonstrations For Social Navigation.IEEE Robotics and Automation Letters, 2022
2022
-
[28]
Urmson, J
C. Urmson, J. A. Bagnell, C. Baker, M. Hebert, A. Kelly, R. Rajkumar, P. E. Rybski, S. Scherer, R. Simmons, S. Singh, et al. Tartan racing: A multi-modal approach to the DARPA urban challenge. 2007
2007
-
[29]
S. Zhao, H. Zhang, P. Wang, L. Nogueira, and S. Scherer. Super odometry: IMU-centric LiDAR-visual-inertial estimator for challenging environments. InInt. Conf. on Intel. Robots and Sys. (IROS), 2021. 10 9 Supplementary materials 9.1 Method Details 9.1.1 Goal-conditioned waypoint prediction and target normalization Throughout this section, index ranges are...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.